-
散列表的查找
散列表的基本概念
什么是散列表?顾名思义就是这个表中的数据元素是分散排列的。前面基于线性表、树表结构的查找方法都是以关键字的比较进行的,而我们查找一般都是查找出关键字在表中的位置,但数据元素在表中的位置与它的关键字并没有直接联系,它的查找时间与表的长度有关。(一个数据元素就相当于是一个结点,关键字只是这个结点的一部分)
而散列查找法就是元素的位置和它的关键字之间建立某种直接联系。其主要思想是:通过对元素的关键字值进行某种运算,直接求出元素的地址,即使用关键字到地址的直接转换方法,而不需要反复比较。
- 散列函数和散列地址:在记录的存储位置 p p p和其关键字 k e y key key之间建立一个确定的对应关系 H H H,使 p = H ( k e y ) p=H(key) p=H(key),称这个对应关系 H H H为散列函数, p p p为散列地址。
- 散列表:一个有限连续的地址空间。通常是一个一维数组,散列地址就是数组的下标。
- 冲突、同义词:对不同的关键字有相同的散列地址,即 k e y 1 ≠ k e y 2 , H ( k e y 1 ) = H ( k e y 2 ) key_{1}\neq key_{2},H(key_{1})=H(key_{2}) key1=key2,H(key1)=H(key2),这种现象称为冲突。 k e y 1 key_{1} key1、 k e y 2 key_{2} key2就互为同义词。
例如,为下列数字集合建立一个散列表,每一个数字都是一个关键字: S 1 = { 2 , 5 , 3 , 11 , 8 } S_{1}=\{2,5,3,11,8\} S1={2,5,3,11,8}
散列函数为: H ( k e y ) = k e y % 7 H(key)=key\%7 H(key)=key%7
散列表可以定义为一个一维数组,长度为6,如下表:散列地址 0 1 2 3 4 5 关键字 ~ 8 2 3 11 5 由于该散列表中没有散列地址相同的不同关键字,所以这个散列表中没有冲突,若将该数字集合改为: S 2 = { 2 , 5 , 3 , 11 , 8 , 9 , 16 , 10 } S_{2}=\{2,5,3,11,8,9,16,10\} S2={2,5,3,11,8,9,16,10}
经计算,有: H ( 2 ) = H ( 9 ) = H ( 16 ) H(2)=H(9)=H(16) H(2)=H(9)=H(16), H ( 3 ) = H ( 10 ) H(3)=H(10) H(3)=H(10)。 2 、 9 、 16 2、9、16 2、9、16互为同义词, 3 、 10 3、10 3、10也互为同义词。通常,散列函数是一个多对一的映射,即多个关键字经过相应的计算后可能会得到相同的散列地址,所以冲突是不可避免的,只能通过选择一个“好”的散列函数在一定程度上减少冲突,而一旦发生了冲突,也应有相应的措施及时予以解决。
所以,散列查找法主要研究一下两个方面的问题:
- 如何构造散列函数
- 如何处理冲突
散列函数的构造方法
构造一个好的散列函数应遵循以下两条原则:
- 函数计算要简单,每一关键字只能有一个散列地址与之对应
- 函数的值域在表长的范围内,计算出的散列地址应分布均匀,尽可能减少冲突
下面学习一下构造散列函数的几种常用方法。
1. 数字分析法
如果事先知道关键字集合,且每个关键字的位数比散列表的地址码位数多,就可以从关键字中选取数字分布均匀的若干位作为散列地址。
例如,对于下列三个关键字:
124832 534721 201390 124832\\ 534721\\ 201390 124832534721201390
我们可以选取它们的第一位和最后一位拼凑起来的两位数作为地址,即分别为 12 、 51 、 20 12、51、20 12、51、20,也可以按照其它运算规则来选取。2. 平方取中法
通常在选定散列函数时不一定能知道关键字的全部情况,取其中哪几位也不一定合适。如果取关键字平方后的中间几位或其组合作为散列地址,则使随机分布的关键字得到的散列地址也是随机的,具体所取位数由表长决定。
例如,为一些标识符建立一个散列表,假设标识符为字母开头的字母数字串。人为约定每个标识符的内部编码规则如下:把字母在字母表中的位置序号作为该字母的内部编码,如 I I I的内部编码为09, A A A的内部编码为01。数字直接利用其自身作为内部编码,如1的内部编码为01。求得标识符的编码后再对其编码进行平方运算,取第7位到底9位作为相应标识符的散列地址,如下表:
标识符 内部编码 内部编码的平方 散列地址 IDA1 09040101 081723426090201 426 IDB2 09040202 081725252200804 252 XID3 24090403 580347516702409 516 YID4 25090404 629528372883216 372 3. 折叠法
将关键字分割称位数相同的几部分,最后一部分的位数可以不同(如12345分割成12,34,5),然后取这几部分的叠加和舍去进位后作为散列地址(例如59+82=141,然后就取41),这种方法称为折叠法。
折叠法又可以分为两种:
- 移位叠加:将分割后每一部分的最低位对齐,然后相加
- 边界叠加:将两个相邻的部分沿边界来回折叠,然后对齐相加
例如当散列表长为1000时,关键字 k e y = 45387765213 key=45387765213 key=45387765213,可将其分为4个部分:453、877、652、13。移位叠加如下图所示: 453 877 652 + 13 ———— [ 1 ] 995 ~~453\\ ~~877\\ ~~652\\ +~13\\ ————\\ ~[1]995 453 877 652+ 13———— [1]995
边界叠加为: 453 778 652 + 31 ———— [ 1 ] 914 ~~453\\ ~~778\\ ~~652\\ +~31\\ ————\\ ~[1]914 453 778 652+ 31———— [1]9144. 除留余数法
假设散列表长为 m m m,选择一个不大于 m m m的数 p p p(一般是小于 m m m的最大质数),用 p p p去除关键字,除后所得余数为散列地址,即 H ( k e y ) = k e y % p H(key)=key\%p H(key)=key%p
处理冲突的方法
虽然说选择一个好的散列函数可以在很大程度上减少冲突,但在实际应用中,很难完全避免发生冲突,这时我们就需要找到一个方法处理冲突问题。
处理冲突的方法与散列表本身的组织形式有关。按组织形式的不同,通常分两大类:开放地址法和链地址法。
1. 开放地址法
该方法的基本思想是:把记录都存储在散列表数据中,当某一记录关键字 k e y key key的初始散列地址 H 0 = H ( k e y ) H_{0}=H(key) H0=H(key)发生冲突时,以 H 0 H_{0} H0为基础,采取合适方法计算得到另一个地址 H 1 H_{1} H1,如果 H 1 H_{1} H1仍然发生冲突,以 H 1 H_{1} H1为基础再求下一个地址 H 2 H_{2} H2。依次类推,直至 H k H_{k} Hk不发生冲突为止,则 H k H_{k} Hk就是该记录在表中的散列地址。
通常把寻找空位(空的散列地址)的过程称为探测,上述方法可用下面的公式来表示: H 0 = H ( k e y ) H i = ( H ( k e y ) + d i ) % m H_{0}=H(key)\\H_{i}=(H(key)+d_{i})\%m H0=H(key)Hi=(H(key)+di)%m
其中, H ( k e y ) H(key) H(key)为散列函数, m m m为表长, d i d_{i} di是一个递增序列。根据 d i d_{i} di取值的不同,可以分为以下3种探测方法
-
线性探测法 d i = 1 , 2 , 3 , . . . , m − 1 d_{i}=1,2,3,...,m-1 di=1,2,3,...,m−1
该方法将散列表假想成一个循环表,发生冲突时,从冲突地址的下一单元顺序寻找空单元,如果到最后一个位置也没找到空单元,则回到表头开始继续查找,直到找到一个空位,就把此元素放入此空位中。如果找不到空位,则说明散列表已满,需要进行溢出处理。 -
二次探测法 d i = 1 2 , − 1 2 , 2 2 , − 2 2 , . . . , k 2 , − k 2 ( k ≤ m / 2 ) d_{i}=1^2,-1^2,2^2,-2^2,...,k^2,-k^2(k \leq m/2) di=12,−12,22,−22,...,k2,−k2(k≤m/2)
-
伪随机探测法 d i = 伪随机数序列 d_{i}=伪随机数序列 di=伪随机数序列
通过下面的例子,来理解上面的3种探测法。
若有一个散列表的长度为11,散列函数为 H ( k e y ) = H 0 = k e y % 11 H(key)=H_{0}=key\%11 H(key)=H0=key%11,假设表中已填有关键字分别为17、60、29的记录,如下标所示。现在要加入第4个记录,其关键字为38,由散列函数得到散列地址为5,产生冲突。
0 1 2 3 4 5 6 7 8 9 10 60 17 29 - 若用线性探测法处理, H 1 = ( H ( k e y ) + 1 ) % m = 6 H_{1}=(H(key)+1)\%m=6 H1=(H(key)+1)%m=6,冲突; H 2 = ( H ( k e y ) + 2 ) % m = 7 H_{2}=(H(key)+2)\%m=7 H2=(H(key)+2)%m=7,冲突; H 3 = ( H ( k e y ) + 3 ) % m = 8 H_{3}=(H(key)+3)\%m=8 H3=(H(key)+3)%m=8,此时上表中下标为8的位置是空的,就可以填入了
0 1 2 3 4 5 6 7 8 9 10 60 17 29 38 - 若用二次探测法处理, H 1 = ( H ( k e y ) + 1 ) % m = 6 H_{1}=(H(key)+1)\%m=6 H1=(H(key)+1)%m=6,冲突; H 2 = ( H ( k e y ) − 1 ) % m = 4 H_{2}=(H(key)-1)\%m=4 H2=(H(key)−1)%m=4,此时下标为4的位置是空的,就可以填入了
0 1 2 3 4 5 6 7 8 9 10 38 60 17 29 - 若用伪随机探测法,假设产生的伪随机数为9,则计算下一个散列地址为 H 1 = ( H ( k e y ) + 9 ) % m = 3 H_{1}=(H(key)+9)\%m=3 H1=(H(key)+9)%m=3,此时下标为3的位置是空的,就可以填入了
0 1 2 3 4 5 6 7 8 9 10 38 60 17 29 从线性探测法处理的过程中可以看到一个现象:当表中 i , i + 1 , i + 2 i,i+1,i+2 i,i+1,i+2位置上都已填有记录时,下一个散列地址为 i , i + 1 , i + 2 , i + 3 i,i+1,i+2,i+3 i,i+1,i+2,i+3的任意一个记录都将填入 i + 3 i+3 i+3的位置。假如有2个(或更多)记录的散列地址分别为 i , i + 2 i,i+2 i,i+2(第一个散列地址),按线性探测法处理,它们都将可以被填入 i + 3 i+3 i+3,这种第一个散列地址不同的记录争夺同一个后继散列地址的现象称为二次聚集。
2. 链地址法
链地址法的基本思想是:把具有相同散列地址的记录放在同一个单链表中,称为同义词链表。有m个散列地址就有m个单链表,并用一个数组来存放各个链表的头指针。
例如,已知一组关键字为 { 19 , 14 , 23 , 1 , 68 , 20 , 84 , 27 , 55 , 11 , 10 , 79 } \{19,14,23,1,68,20,84,27,55,11,10,79\} {19,14,23,1,68,20,84,27,55,11,10,79}
设散列函数为 H ( k e y ) = k e y % 13 H(key)=key\%13 H(key)=key%13,则由链地址法表示的散列表如下图: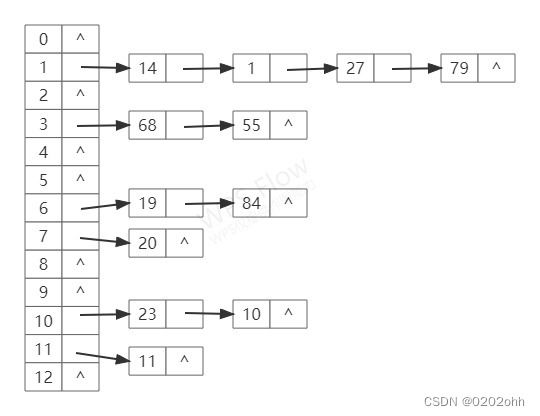
散列表的查找
在散列表上进行查找的过程和创建散列表的过程基本一致。下面以开放地址法为例,给出散列表的存储表示。
#define m 20 typedef struct { int key; char otherinfo; }HashTable;- 1
- 2
- 3
- 4
- 5
- 6
算法分析:
- 首先根据要查找的关键字 k e y key key,计算出 H 0 = H ( k e y ) H_{0}=H(key) H0=H(key)
- 因为0号单元不使用,其值为初值0,所以若单元 H 0 H_{0} H0为空,则所查找的元素不存在
- 若单元 H 0 H_{0} H0中元素的关键字与 k e y key key相等,则查找成功
- 若在 H 0 H_{0} H0单元中查找失败,则计算 H 1 , H 2 . . . H_{1},H_{2}... H1,H2...直到查找成功为止
具体代码:
int SearchHash(HashTable HT,int key) { H0=H(key); if(HT[H0].key==0) return -1; else if(HT[H0].key==key) return H0; else { for(int i=1;i<m;i++) { Hi=(H0+i)%m; if(HT[Hi].key==0) return -1; else if(HT[Hi].key==key) return Hi; } return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结
散列表也成为哈希表,它也属于一种线性结构。我们在查询的时候总是要得到被查找数据的位置,而线性表、树表等是通过不断地比较来确定位置的,而散列表是根据关键字值来确定的位置。由此,数据元素的位置就是一个关于关键字值的函数。在查找的过程中,我们也许会发现查找不同关键字时,会出现相同散列地址的情况,这就叫做冲突。因为每个数据元素的散列地址必须唯一,所以我们要做到尽量减少冲突。
于是,对于散列表,我们需要构造一个合适的散列函数,并且有合适解决冲突的方法。
首先是构造散列函数,有数字分析法、平方取中法、折叠法和除留余数法。其中数字分析法局限性很大,它要求事先必须明确知道所有的关键字每一位上各数字的分布情况;平方取中法相当于是数字分析法的升级版,它不需要事先知道关键字的所有情况,同时也能适用于难于直接从关键字中找到取值较分散的几位;而折叠法,适用于散列地址的位数较少,而关键字的位数较多,且难于从直接从关键字中找到取值较分散的几位;最后就是除留余数法,它计算简单,适用范围广,它不仅可以对关键字直接取模,也可以在折叠、平方取中等运算之后取模,这样能够保证散列地址一定落在散列表的地址空间中。
然后是解决冲突的方法,有开放地址法和链地址法。开放地址法主要是进行探测操作,也就是若发生了冲突,就去寻找下一个空的位置。探测操作有3种,分别是线性、二次、伪随机探测法。其中,线性探测法最全面,只要散列表未填满,总能找到一个不发生冲突的地址,但是会产生二次聚集现象。而二次探测法和伪随机探测法则可以避免二次聚集现象,但不能保证一定找到不发生冲突的地址;那么关于链地址法,含有相同地址的数据元素会被链接到一个链表上,所以根本不存在冲突的问题。
选择一个合适的散列函数和解决冲突的方法是一个好的散列表的前提。
-
相关阅读:
软考中级软件设计师--下午题
docker安装开发常用软件MySQL,Redis,rabbitMQ
一种加权变异的粒子群算法-附代码
Java多线程4种拒绝策略
一张图看懂微服务架构路线
传智健康_第3章 预约管理-检查组管理
《A Novel Table-to-Graph Generation Approach for Document-Level Joint Entity and Relation Extraction》阅读笔记
推荐一个免费的相亲工具
在阿里做前端程序员,我是这样规划的
uniapp微信小程序局部刷新,无感刷新,修改哪条数据刷新哪条
- 原文地址:https://blog.csdn.net/weixin_62917800/article/details/126155622
