-
从-99打造Sentinel高可用集群限流中间件
这一次需要更进一步,基于 Sentinel 实现内嵌式集群限流的高可用方案,并且包装成一个中间件 starter 提供给三方使用。
对于高可用,我们主要需要解决两个问题,这无论是使用内嵌或者独立模式都需要解决的问题,相比而言,内嵌式模式更简单一点。
- 集群 server 自动选举
- 自动故障转移
- Sentinel-Dashboard持久化到Apollo
集群限流
首先,考虑到大部分的服务可能都不需要集群限流这个功能,因此实现一个注解用于手动开启集群限流模式,只有开启注解的情况下,才去实例化集群限流的 Bean 和限流数据。
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Import({EnableClusterImportSelector.class}) @Documented public @interface SentinelCluster { } public class EnableClusterImportSelector implements DeferredImportSelector { @Override public String[] selectImports(AnnotationMetadata annotationMetadata) { return new String[]{ClusterConfiguration.class.getName()}; } }这样写好之后,当扫描到有我们的
SentinelCluster注解的时候,就会去实例化ClusterConfiguration。@Slf4j public class ClusterConfiguration implements BeanDefinitionRegistryPostProcessor, EnvironmentAware { private Environment environment; @Override public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException { BeanDefinitionBuilder beanDefinitionBuilder = BeanDefinitionBuilder.genericBeanDefinition(ClusterManager.class); beanDefinitionBuilder.addConstructorArgValue(this.environment); registry.registerBeanDefinition("clusterManager", beanDefinitionBuilder.getBeanDefinition()); } @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { } @Override public void setEnvironment(Environment environment) { this.environment = environment; } }在配置中去实例化用于管理集群限流的
ClusterManager,这段逻辑和我们之前文章中使用到的一般无二,注册到ApolloDataSource之后自动监听Apollo的变化达到动态生效的效果。@Slf4j public class ClusterManager { private Environment environment; private String namespace; private static final String CLUSTER_SERVER_KEY = "sentinel.cluster.server"; //服务集群配置 private static final String DEFAULT_RULE_VALUE = "[]"; //集群默认规则 private static final String FLOW_RULE_KEY = "sentinel.flow.rules"; //限流规则 private static final String DEGRADE_RULE_KEY = "sentinel.degrade.rules"; //降级规则 private static final String PARAM_FLOW_RULE_KEY = "sentinel.param.rules"; //热点限流规则 private static final String CLUSTER_CLIENT_CONFIG_KEY = "sentinel.client.config"; //客户端配置 public ClusterManager(Environment environment) { this.environment = environment; this.namespace = "YourNamespace"; init(); } private void init() { initClientConfig(); initClientServerAssign(); registerRuleSupplier(); initServerTransportConfig(); initState(); } private void initClientConfig() { ReadableDataSource这样的话,一个集群限流的基本功能已经差不多是OK了,上述步骤都比较简单,按照官方文档基本都能跑起来,接下来要实现文章开头提及到的核心的几个功能了。
自动选举&故障转移
自动选举怎么实现?简单点,不用考虑那么多,每台机器启动成功之后直接写入到 Apollo 当中,第一个写入成功的就是 Server 节点。
这个过程为了保证并发带来的问题,我们需要加锁确保只有一台机器成功写入自己的本机信息。
由于我使用 Eureka 作为注册中心,Eureka 又有
CacheRefreshedEvent本地缓存刷新的事件,基于此每当本地缓存刷新,我们就去检测当前 Server 节点是否存在,然后根据实际情况去实现选举。
首先在 spring.factories 中添加我们的监听器。
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.test.config.SentinelEurekaEventListener
监听器只有当开启了集群限流注解
SentinelCluster之后才会生效。@Configuration @Slf4j @ConditionalOnBean(annotation = SentinelCluster.class) public class SentinelEurekaEventListener implements ApplicationListener
{ @Resource private DiscoveryClient discoveryClient; @Resource private Environment environment; @Resource private ApolloManager apolloManager; @Override public void onApplicationEvent(EurekaClientLocalCacheRefreshedEvent event) { if (!leaderAlive(loadEureka(), loadApollo())) { boolean tryLockResult = redis.lock; //redis或者其他加分布式锁 if (tryLockResult) { try { flush(); } catch (Exception e) { } finally { unlock(); } } } } private boolean leaderAlive(List eurekaList, ClusterGroup server) { if (Objects.isNull(server)) { return false; } for (ClusterGroup clusterGroup : eurekaList) { if (clusterGroup.getMachineId().equals(server.getMachineId())) { return true; } } return false; } } OK,其实看到代码已经知道我们把故障转移的逻辑也实现了,其实道理是一样的。
第一次启动的时候 Apollo 中的 server 信息是空的,所以第一台加锁写入的机器就是 server 节点,后续如果 server 宕机下线,本地注册表缓存刷新,对比 Eureka 的实例信息和 Apollo 中的 server,如果 server 不存在,那么就重新执行选举的逻辑。
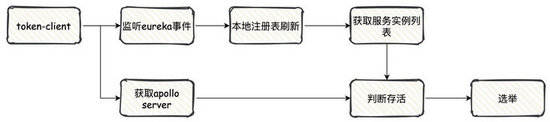
需要注意的是,本地缓存刷新的时间极端情况下可能会达到几分钟级别,那么也就是说在服务下线的可能几分钟内没有重新选举出新的 server 节点整个集群限流是不可用的状态,对于业务要求非常严格的情况这个方案就不太适用了。
对于 Eureka 缓存时间同步的问题,可以参考之前的文章
Dashboard持久化改造
到这儿为止,我们已经把高可用方案实现好了,接下来最后一步,只要通过 Sentinel 自带的控制台能够把配置写入到 Apollo 中,那么应用就自然会监听到配置的变化,达到动态生效的效果。
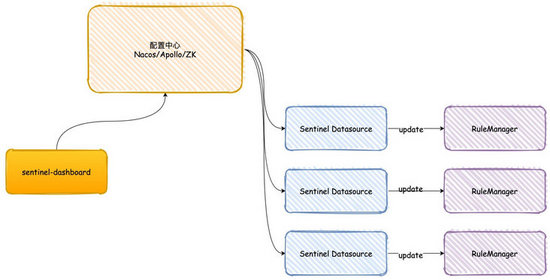
根据官方的描述,官方已经实现了
FlowControllerV2用于集群限流,同时在测试目录下有简单的案例帮助我们快速实现控制台的持久化的逻辑。我们只要实现
DynamicRuleProvider,同时注入到Controller中使用即可,这里我们实现flowRuleApolloProvider用于提供从Apollo查询数据,flowRuleApolloPublisher用于写入限流配置到Apollo。@RestController @RequestMapping(value = "/v2/flow") public class FlowControllerV2 { private final Logger logger = LoggerFactory.getLogger(FlowControllerV2.class); @Autowired private InMemoryRuleRepositoryAdapterrepository; @Autowired @Qualifier("flowRuleApolloProvider") private DynamicRuleProvider 实现方式很简单,provider 通过 Apollo 的 open-api 从 namespace 中读取配置,publisher 则是通过 open-api 写入规则。
@Component("flowRuleApolloProvider") public class FlowRuleApolloProvider implements DynamicRuleProvidergetRules(String appName) { String rules = apolloManager.loadNamespaceRuleList(appName, ApolloManager.FLOW_RULES_KEY); if (StringUtil.isEmpty(rules)) { return new ArrayList<>(); } return converter.convert(rules); } } @Component("flowRuleApolloPublisher") public class FlowRuleApolloPublisher implements DynamicRulePublisher rules) { AssertUtil.notEmpty(app, "app name cannot be empty"); if (rules == null) { return; } apolloManager.writeAndPublish(app, ApolloManager.FLOW_RULES_KEY, converter.convert(rules)); } } ApolloManager实现了通过open-api查询和写入配置的能力,使用需要自行配置 Apollo Portal 地址和 token,这里不赘述,可以自行查看 Apollo 的官方文档。@Component public class ApolloManager { private static final String APOLLO_USERNAME = "apollo"; public static final String FLOW_RULES_KEY = "sentinel.flow.rules"; public static final String DEGRADE_RULES_KEY = "sentinel.degrade.rules"; public static final String PARAM_FLOW_RULES_KEY = "sentinel.param.rules"; public static final String APP_NAME = "YourAppName"; @Value("${apollo.portal.url}") private String portalUrl; @Value("${apollo.portal.token}") private String portalToken; private String apolloEnv; private String apolloCluster = "default"; private ApolloOpenApiClient client; @PostConstruct public void init() { this.client = ApolloOpenApiClient.newBuilder() .withPortalUrl(portalUrl) .withToken(portalToken) .build(); this.apolloEnv = "default"; } public String loadNamespaceRuleList(String appName, String ruleKey) { OpenNamespaceDTO openNamespaceDTO = client.getNamespace(APP_NAME, apolloEnv, apolloCluster, "default"); return openNamespaceDTO .getItems() .stream() .filter(p -> p.getKey().equals(ruleKey)) .map(OpenItemDTO::getValue) .findFirst() .orElse(""); } public void writeAndPublish(String appName, String ruleKey, String value) { OpenItemDTO openItemDTO = new OpenItemDTO(); openItemDTO.setKey(ruleKey); openItemDTO.setValue(value); openItemDTO.setComment("Add Sentinel Config"); openItemDTO.setDataChangeCreatedBy(APOLLO_USERNAME); openItemDTO.setDataChangeLastModifiedBy(APOLLO_USERNAME); client.createOrUpdateItem(APP_NAME, apolloEnv, apolloCluster, "default", openItemDTO); NamespaceReleaseDTO namespaceReleaseDTO = new NamespaceReleaseDTO(); namespaceReleaseDTO.setEmergencyPublish(true); namespaceReleaseDTO.setReleasedBy(APOLLO_USERNAME); namespaceReleaseDTO.setReleaseTitle("Add Sentinel Config Release"); client.publishNamespace(APP_NAME, apolloEnv, apolloCluster, "default", namespaceReleaseDTO); } }对于其他规则,比如降级、热点限流都可以参考此方式去修改,当然控制台要做的修改肯定不是这一点点,比如集群的
flowId默认使用的单机自增,这个肯定需要修改,还有页面的传参、查询路由的修改等等,比较繁琐,就不在此赘述了,总归也就是工作量的问题。 -
相关阅读:
DIcom调试Planar configuration
【UOJ 454】打雪仗(通信题)(分块)
C++学习:类与对象
事件委托代理
放大招,百度文心大模型4.0正在加紧训练,即将发布
20221129今天的世界发生了什么
无尘手套在无尘车间的应用
Spring Security进行权限控制
(免费领源码)Java#springboot#MySQL书法社团管理系统36200-计算机毕业设计项目选题推荐
【完美世界】石昊偷渡出境四人组产生分歧,云曦和石昊牵手,二人世界要开始了
- 原文地址:https://blog.csdn.net/JHIII/article/details/126160887
