-
使用java解析hashMap
使用java解析hashMap
1 含义
HashMap的底层数据结构就是哈希表,哈希表就是数组+单向链表(Node数组里面存放的是链表)
2 怎么用
2.1 哈希表数据结构优缺点
优点:哈希表的增删检索效率都相对较高,他是数组和单向链表的结合体
缺点:在检索方面没有数组的效率高,在增加和删除的方面没有单向链表效率高
2.2 哈希表的原理图
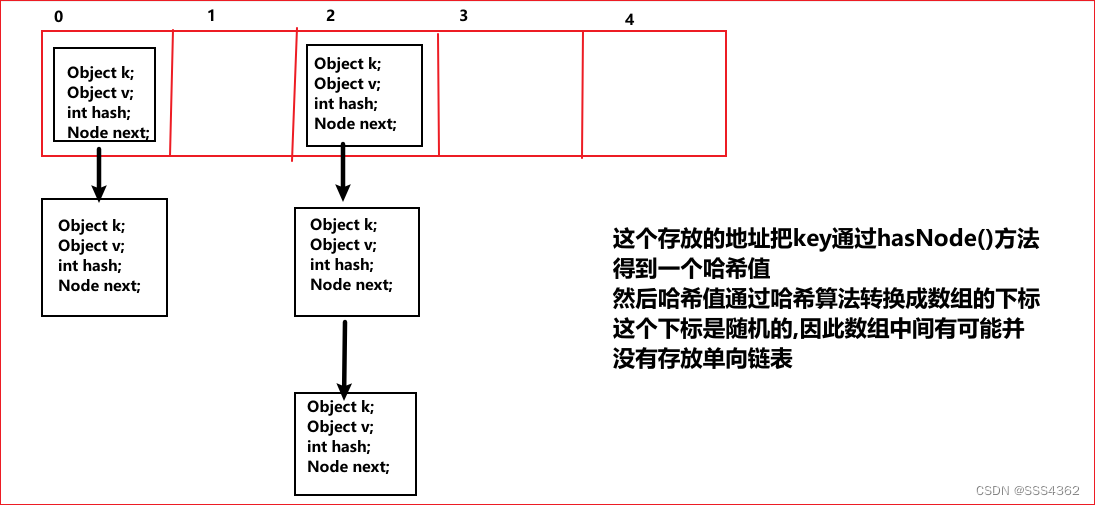
2.3 通过map.put(k,v)存放键值对的实现原理
第一步,先将key值和value值存放到Node对象中
第二步,底层会调用key.hasCode()方法得到一个哈希值(这个值是唯一的)
第三步,把得到的哈希值通过哈希算法转换成数组的下标
第四步,若得到的数组的下标位置上并没有元素(单向链表),就吧Node节点添加到该位置上
第五步,若得到的数组下标位置上有元素,则将Node对象的key值与单向链表的每一个元素进行equals比较,若遍历到了末尾,所有的元素都返回是false,则将Node对象挂载到链表的最后一个元素的下一个位置(链表的尾部)
第六步,若其中有某次equals方法得到的结果是true,则将Node对象里面对应的value值覆盖原来链表key位置上的value值
2.4 通过map.get(k)拿到key所对应的内容的原理
第一步 key调用hasCode()方法得到哈希值,通过哈希算法可以得到唯一的一个数组的下标
第二步 通过数组的下标可以定位到具体的位置
第三步 若该位置没有单向链表,则返回false
第四步 若该位置有单向链表,则会拿key值与单向链表上的所有节点的key值去进行比较
第五步 若比较完的结果都是false,就返回null
第六步 若比较的过程中的有一个结果为true,则返回该节点对象的value值
2.5 示例代码
Student类
package Work03; import java.util.Objects; public class Student{ private String name; private int age; private float degree; //分数 public Student() { } public Student(String name, int age, float degree) { this.name = name; this.age = age; this.degree = degree; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public float getDegree() { return degree; } public void setDegree(float degree) { this.degree = degree; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", degree=" + degree + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Float.compare(student.degree, degree) == 0 && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, age, degree); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
TestStudent02类
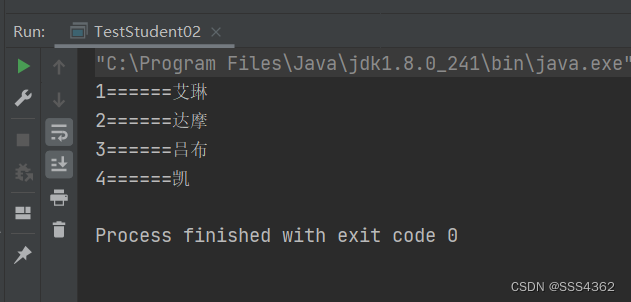
package Work03; import java.util.*; public class TestStudent02 { public static void main(String[] args) { //使用hashSet和hashMap都需要重写equals方法和hashCode方法 Map<Integer,String> map=new HashMap(); map.put(1,"鲁班七号"); map.put(2,"达摩"); map.put(3,"吕布"); map.put(4,"凯"); //这里相当于会把之前的key为1的单向链表的里面的值替换成艾琳 map.put(1,"艾琳"); //通过entrySet去获取里面的值 Set<Map.Entry<Integer, String>> entries = map.entrySet(); Iterator<Map.Entry<Integer, String>> iterator=entries.iterator(); while(iterator.hasNext()){ Map.Entry<Integer,String> next = iterator.next(); System.out.println(next.getKey()+"======"+next.getValue()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.6 示例代码运行截图
3 结论
3.1 使用hashSet集合和hashMap集合一定要重写equals方法和hasCode方法,因为底层的map.put(k,v)调用了这两个方法
3.2 hashMap的不可重复指的是最终得到的集合里面的结果是键单一的情况,如果前后插入相同的键名和不同的value值,那么以最后的那个value值为准,因为后面的会覆盖掉前面的内容
3.3 键只能唯一,值可以重复,因此插入时候允许插入相同键值的键值对,但实际结果却是只显示最后插入的那个键值对,这样一来岂不意味着你用做了很多无用功
3.4 hashMap的左半边(key集合)是存放在hashSet集合中
3.5 哈希表中,同一个单向链表上所有的节点的hash值一定相同,因为本质是hash值通过哈希算法得到的一个地址,数组下标(地址)相同,就意味着hash值是相同的
3.6 数组同一位置下的单向链表节点进行key值的相互比较结果必然是false,因为是false才能挂载上去,如果不为false,那就把传入的key值对应的values覆盖之前链表key值所对应的value值
-
相关阅读:
Tomcat-8.5_Apr-1.7构建
智能合约经典漏洞案例,xSurge 重入漏洞+套利 综合运用
JavaScript进阶(二十三):立即执行函数(匿名函数)( ( ) { } ( ) )含义解析
违约金过高”的认定依据
git stash 暂存当前修改
MKS SERVO28C 闭环步进电机 使用说明
Python 绘制玫瑰花
华为机试真题 C++ 实现【无向图染色】【2022.11 Q4新题】
Python每日一练(牛客数据分析篇新题库)——第39天:排序、函数
面试软件测试工程师时可能会遇到的几个常见问题
- 原文地址:https://blog.csdn.net/SSS4362/article/details/126149199
