-
Pandas数据分析13——数据框合并(实现excel的Vlookup功能)
参考书目:《深入浅出Pandas:利用Python进行数据处理与分析》
pandas数据框有时候我们需要合并,对多个数据框一起操作。pandas里面有很多用法,了解一下
导入包
- import numpy as np
- import pandas as pd
append()
append和列表的用法一样,直接在数据框后面追加
- df.append(self,other,ignore_index=False,#重置索引
- verify_integrity=False,sort=False)
- df1=pd.DataFrame({'x':[1,2],'y':[3,4]})
- df2=pd.DataFrame({'x':[5,6],'y':[7,8]})
- df3=pd.DataFrame({'z':[1,2],'y':[3,4]})
- df1.append(df3,ignore_index=True)
- #追加一条数据
- df1.append({'x':31,'y':90},ignore_index=True)

数据连接 pd.concat()
concat用法会多一些,下面是他的参数
- pd.concat(obj ,axis=0,join='outer',#inner交集,outer并集
- ignore_index=False,keys=None,#连接关系
- levels=None,names=None,#索引名称
- sort=False,verify_integrity=False,copy=True)
基本用法
- #行连接
- pd.concat([df1,df2])
- pd.concat([df1,df2],axis=0)
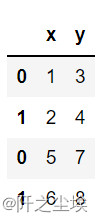
- #列连接
- df2=pd.DataFrame({'x':[5,6,0],'y':[7,8,80]})
- pd.concat([df1,df2],axis=1)
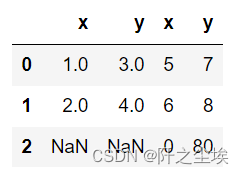
取交集
pd.concat([df1,df2],axis=1,join='inner') #默认并集outer
- #指定索引
- pd.concat([df1,df2],keys=['a','b'])
- pd.concat({'a':df1,'b':df2})
- pd.concat([df1,df2],axis=1,keys=['a','b'])
多个文件合并
- ### 多文件合并 process_your_file处理文件为df
- frames=[process_your_file(f) for f in files ]
- result = pd.concat(frames)
- #一个包含多个 Sheet 的 Excel 合并成一个 DataFrame
- dfm = pd.read_excel('team.xlsx', sheet_name=None)
- pd.concat(dfm.values())
- pd.concat(dfm) # 保留 Sheet 名作为一级索引
文件目录合并
- #文件目录合并
- import glob # 取出目录下所有 xlsx 格式文件
- files = glob.glob("data/*.xlsx")
- cols = ['记录ID', '开始时间', '名称'] # 只取这些列
- # 列表推导出对象
- dflist = [pd.read_excel(i, usecols=cols) for i in files]
- df = pd.concat(dflist) # 合并
map操作
- #map操作 # 逐一读取多个文件,合并
- pd.concat(map(pd.read_csv, ['data/d1.csv','data/d2.csv','data/d3.csv']))
- pd.concat(map(pd.read_excel, ['data/d1.xlsx','data/d2.xlsx','data/d3.xlsx']))
- # 目录下所有文件
- from os import listdir
- filepaths = [f for f in listdir("./data") if f.endswith('.csv')]
- df = pd.concat(map(pd.read_csv, filepaths))
- # 方法 2
- import glob
- df = pd.concat(map(pd.read_csv, glob.glob('data/*.csv')))
- df = pd.concat(map(pd.read_excel, glob.glob('data/*.xlsx')))
数据合并pd.merge()
merge用法更多了,可以根据关键词来进行合并,并且可以实现excel表的VLOOKUP函数的功能。
基本参数说明
- pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
- left_index=False, right_index=False, sort=True,
- suffixes=('_x', '_y'), copy=True, indicator=False,
- validate=None)
'''how:连接方式,默认为inner,可设为inner/outer/left/right
on:根据某个字段进行连接,必须存在于两个DateFrame中(若未同时存在,则需要分别使用left_on 和 right_on 来设置)
left_on:左连接,以DataFrame1中用作连接键的列
right_on:右连接,以DataFrame2中用作连接键的列
left_index:bool, default False,将DataFrame1行索引用作连接键
right_index:bool, default False,将DataFrame2行索引用作连接键
sort:根据连接键对合并后的数据进行排列,默认为True
suffixes:对两个数据集中出现的重复列,新数据集中加上后缀 _x, _y 进行区别'''
基本用法
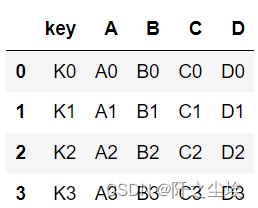
- left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
- 'A': ['A0', 'A1', 'A2', 'A3'],
- 'B': ['B0', 'B1', 'B2', 'B3']})
- right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
- 'C': ['C0', 'C1', 'C2', 'C3'],
- 'D': ['D0', 'D1', 'D2', 'D3']})
- pd.merge(left, right, on='key')
索引连接
- #索引连接
- pd.merge(left.set_index('key'), right.set_index('key'), left_index=True,right_index=True)

多键连接
- #多键连接
- left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
- 'key2': ['K0', 'K1', 'K0', 'K1'],
- 'A': ['A0', 'A1', 'A2', 'A3'],
- 'B': ['B0', 'B1', 'B2', 'B3']})
- right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
- 'key2': ['K0', 'K0', 'K0', 'K0'],
- 'C': ['C0', 'C1', 'C2', 'C3'],
- 'D': ['D0', 'D1', 'D2', 'D3']})
- pd.merge(left, right, on=['key1', 'key2'])

连接方法——可以以一个文件夹的键为基准,也可以取交集或者并集
- #连接方法
- pd.merge(left, right, how='left', on=['key1', 'key2'])# 以左为表基表
- pd.merge(left, right, how='right', on=['key1', 'key2'])# 以右为表基表
- pd.merge(left, right, how='outer', on=['key1', 'key2'])# 取两个表的并集
- pd.merge(left, right, how='inner', on=['key1', 'key2'])# 取两个表的交集
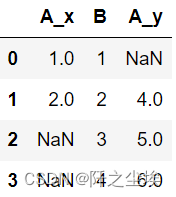
- #下边是一个有重复连接键的例子:
- left = pd.DataFrame({'A': [1, 2], 'B': [1, 2]})
- right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 3, 4]})
- pd.merge(left, right, on='B', how='outer')
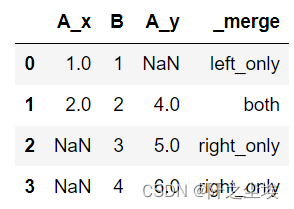
#连接指示 indicator
- #连接指示 indicator
- #如果设置 indicator 为 True, 则会增加名为 _merge 的一列,显示这列是多何而来
- pd.merge(left, right, on='B', how='outer', indicator=True)
案例
实现excel的vlookup功能,对售卖记录进行不同售卖产品的售卖价格查询合并,并计算总销售额
首先随机生成订单表格和价格表格- import random
- sale=np.random.randint(2,20,size=(100))
- sale_kind=[]
- for i in range(100):
- sale_kind.append(random.choice(['香蕉','苹果','橘子','西瓜','葡萄','草莓','芒果','西柚']))
- data=pd.DataFrame({'售卖种类':sale_kind,'售卖数量':sale})
- data
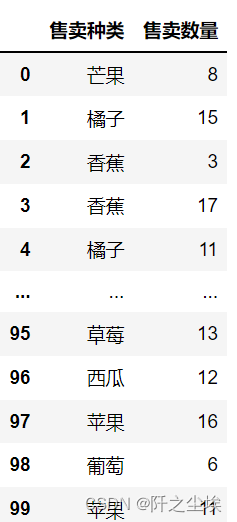
整了8个水果,随机生成了他们的100条销售记录
- #随机生成价格表
- price=pd.DataFrame(['香蕉','苹果','橘子','西瓜','葡萄','草莓','芒果','西柚'],columns=['水果种类'])
- price['水果价格']=abs(np.random.randn((len(price)),1))*10
- price
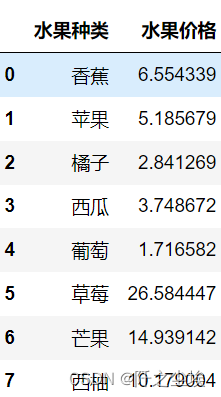
随机生成的价格,,,我也不知道现在水果多少钱一斤。
计算每条记录的销售额,左边是销售记录,因此合并时,以左边的数据为基准。将右边的价格都一一加入数据框。然后对应的价格乘上售卖数量,生成新的一列销售额。
pd.merge(data, price ,how='left',left_on='售卖种类',right_on='水果种类').assign(销售额=lambda d:d.售卖数量*d.水果价格)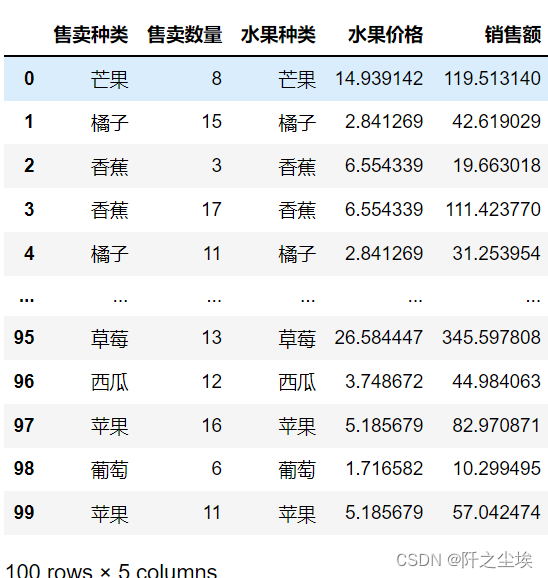
拿出销售额这一列,求和。
- #计算销售额
- pd.merge(data, price ,how='left',left_on='售卖种类',right_on='水果种类').assign(销售额=lambda d:d.售卖数量*d.水果价格)['销售额'].sum(0)
还是很方便的。merge()数据合并规则还是很复杂的,要根据具体情况使用
-
相关阅读:
使用python setup.py报错:Upload failed (403) / Upload failed (400)
mysql之 Redis配置与优化
反射机制(Reflection)
快解析结合千方百剂
数字音频矩阵
Windows 安装docker(详细图解)
oracle开启归档日志并修改归档日志路径
关于HM NISEDIT在新版系统下编译并运行提示权限不足问题的解决方案
【C/C++】结构体内存分配问题
Oracle-美团外卖
- 原文地址:https://blog.csdn.net/weixin_46277779/article/details/126156903