-
ELECTRA:Pre-training Text Encoders as Discriminators Rather Than Generators
模型概述
ELECTRA提出了一个新的预训练任务Replaced Token Detection(RTD),它的目标是学习区分输入的词。这个方法不采用mask,而是通过使用生成网络来生成一些合理替换字符来达到破坏输入的目的。然后,训练一个判别器模型,该模型可以预测当前字符是否被语言模型替换过。判别任务的一个好处是模型从输入的所有词中学习,而不是MLM中那样仅使用掩盖的词,因此计算更加有效。
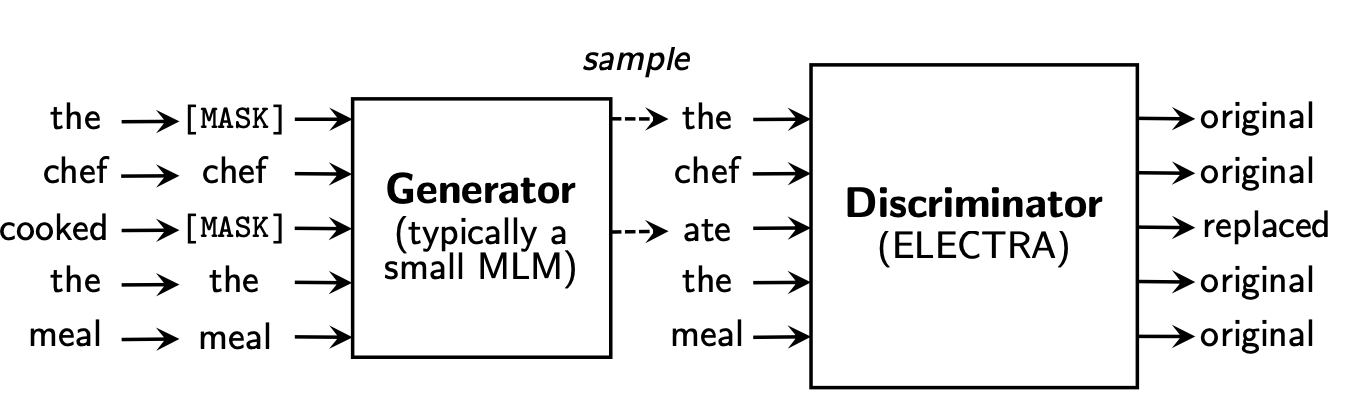
ELECTRA模型结构类似于GAN,包括两个神经网络:一个生成器G和一个判别器D,两者都采用形如Transformer的编码网络来获取输入序列x的向量表示h(x)。生成器的目标是训练成掩码语言模型,即给定输入序列x,首先按照一定的比例(通常15%)将输入中的词替换成[MASK]得到,然后通过网络得到向量表示hG(x),接着采用softmax层来为输入序列中掩盖的位置预测一个词,训练的目标函数为最大化掩盖词的似然。判别器的目标是判断输入序列每个位置的词是否被生成器替换过,如果与原始输入序列对应位置的词不相同就认为替换过。
ELECTRA与GAN的区别,作者列出了以下几点:
模型 ELECTRA GAN 输入 真实文本 随机噪声 目标 生成器学习语言模型,判别器学习区分真假文本 生成器尽可能欺骗判别器,判别器尽量区分真假图片 反向传播 梯度无法从D传到G 梯度可以从D传到G 特殊情况 生成出了真实文本,则标记为正例 生成的都是负例(假图片) 模型结构
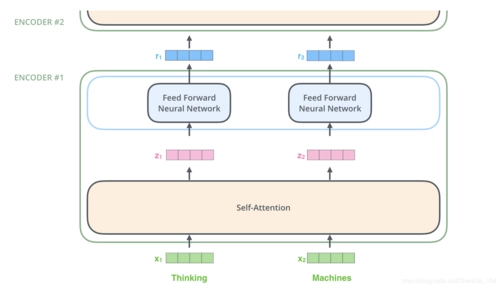
ELECTRA的生成器和判别器都是基于BERT的encoder模型,encoder模型结构如下:
因为ELECTRA模型输入的句子的字词是离散的,所以梯度无法反向传播,判别器的梯度无法传给生成器,于是生成器的目标还是MLM,判别器的目标是序列标注(判断每个字符是真是假),两者同时训练,但是判别器的梯度不会传给生成器。因此,预训练任务整个模型的目标函数为: m i n θ G , θ D ∑ x ∈ X L M L M ( x , θ G ) + λ L D i s c ( x , θ D ) minθ_G,θ_D\sum_{x∈X
}L_{MLM}(x,θ_G)+λL_{Disc}(x,θ_D) minθG,θD∑x∈XLMLM(x,θG)+λLDisc(x,θD)。因为判别器的任务相对来说简单些,RTD损失相对MLM损失会很小,因此加上一个系数,论文中使用了50。经过预训练,在下游任务的使用中,直接给出生成器,在判别器进行微调。另外,在优化判别器时计算了所有token上的损失,而以往计算BERT的MLM loss时会忽略没被mask的token。
在生成器和判别器权重共享方面,设置了同样大小的生成器和判别器。在不共享权重下的效果为83.6,只共享token embedding层的效果是84.3,共享所有权重的效果是84.4。因为生成器对embedding 有更好的学习能力,这是由于判别器只更新由生成器采样生成的token,而softmax是建立在所有vocab上的,之后反向传播时生成器会更新所有的embedding,最后作者只使用了embedding sharing。
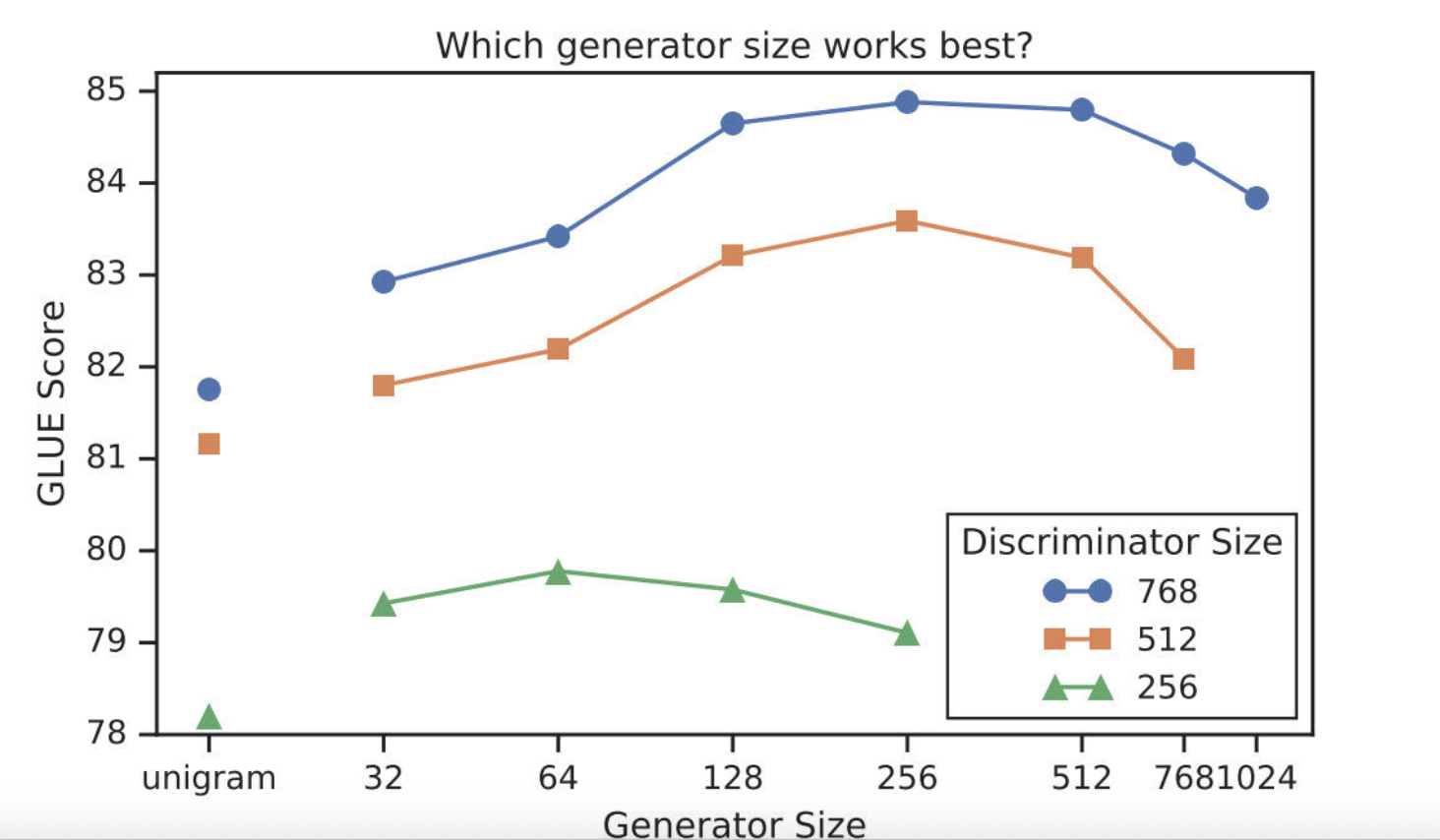
在模型大小方面,因为从权重共享的实验中看到,生成器和判别器只需要共享embedding 的权重就足够了。那这样的话是否可以缩小生成器的尺寸进行训练效率的提升呢?作者在保持原有的hidden size的设置下减少了层数,得到了下图所示的关系图:从图中可以看出生成器的大小在判别器的1/4到1/2之间的效果是最好的。原因是过强的生成器会增加判别器的难度。
在训练策略方面,作者也尝试了另外两种训练策略:
1、Adversarial Contrastive Estimation:ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM损失换成了最大化判别器在被替换token上RTD损失。但还有一个问题,就是新的生成器无法用梯度上升更新生成器,于是作者使用强化学习Policy Gradient思想,最终优化下来生成器在MLM 任务上可以达到54%的准确率,而之前MLE优化下可达到65%。
2、Two-stage training:即先训练生成器,然后freeze掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。
对比三种训练策略,得到下图:
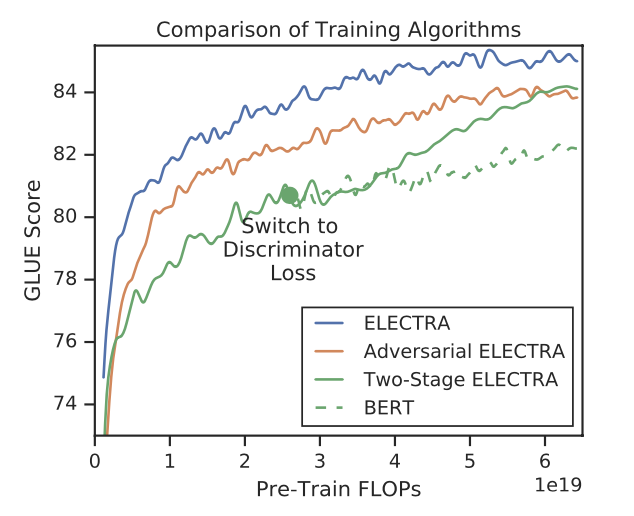
可见“隔离式”的训练策略效果还是最好的,而两段式的训练弱一些,作者猜测是生成器太强了导致判别任务难度增大。不过两段式最终效果也比BERT本身要强,进一步证明了判别式预训练的效果。ELECTRA模型代码,可以和BERT代码对比一下,基本上没有什么差别,不同的就是预训练任务时一些参数的不同:
import math from dataclasses import dataclass from typing import Optional, List, Tuple import tensorflow as tf from tensorflow.keras import layers from transformers import shape_list from transformers.activations_tf import get_tf_activation from transformers.modeling_tf_utils import get_initializer from transformers.tf_utils import stable_softmax from transformers.utils import ModelOutput class TFElectraModel(tf.keras.Model): def __init__(self, config, *inputs, **kwargs): super().__init__(config, *inputs, **kwargs) self.electra = TFElectraMainLayer(config, name="electra") def call( self, inputs_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None, use_cache=None, output_attentions=None, output_hidden_states=None, return_dict=None, training=False ): outputs = self.electra( inputs_ids=inputs_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, past_key_values=past_key_values, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, training=training ) return outputs class TFElectraMainLayer(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.config = config self.is_decoder = config.is_decoder self.embeddings = TFElectraEmbeddings(config, name="embeddings") if config.embedding_size != config.hidden_size: self.embeddings_project = layers.Dense(config.hidden_size, name="embeddings_project") self.encoder = TFElectraEncoder(config, name="encoder") def call( self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None, use_cache=None, output_attentions=None, output_hidden_states=None, return_dict=None, training=False ): # input_ids表示输入的单词序列,shape: (batch_size, seq_length) # inputs_embeds表示单词序列对应的词向量,shape(batch_size, seq_length, embed_size) # 这两个参数只能够指定一个,如果指定input_ids,则需要通过嵌入层生成inputs_embeds if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") elif input_ids is not None: input_shape = shape_list(input_ids) elif inputs_embeds is not None: input_shape = shape_list(inputs_embeds)[: 2] else: raise ValueError("You have to specify either input_ids or inputs_embeds") batch_size, seq_length = input_shape # past_key_values用于decoder并且用于加速推理过程的计算 # 缓存着训练过程中key、value两个向量,由于推理过程或者叫预测过程会重复的计算这两个向量 # 因此,通过使用缓存的key、value向量,就不需要重复计算,从而加速了推理的过程 # shape: (n_layers, 4, batch_size, num_heads, seq_length - 1, head_dim) # 另外,如果指定了past_key_values,那么decoder_input_ids的形状应为(batch_size, 1) # 而不是(batch_size, seq_length),也就是用每一个batch的最后一个单词来代替所有的单词 if past_key_values is None: past_key_value_length = 0 past_key_values = [None] * len(self.encoder.layer) else: past_key_value_length = shape_list(past_key_values[0][0])[2] if attention_mask is None: attention_mask = tf.fill((batch_size, seq_length + past_key_value_length), value=1) if token_type_ids is None: token_type_ids = tf.fill(input_shape, value=0) # hidden_states = word_embeds + token_type_embeds + position_embeds # shape: (batch_size, seq_length, embed_size) hidden_states = self.embeddings( input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds, past_key_value_length=past_key_value_length, training=training ) # attention_mask -> extended_attention_mask # shape: (batch_size, seq_length) -> (batch_size, 1, 1, mask_seq_length) # 考虑几种情况 # 1、如果是decoder的self-attention的attention_mask,需要变成causal attention mask。 # 再扩展维度变成extended_attention_mask,形状为一个4维张量(batch_size, 1, 1, seq_length), # 通过python广播机制变成(batch_size, num_heads, mask_seq_length, mask_seq_length)以适应多头注意力的计算。 # 2、如果是decoder并且使用past_key_values,那么seq_length = 1 # 计算decoder的self-attention时,需要将形状转换成(batch_size, num_heads, 1, mask_seq_length) # 3、如果是encoder,直接转换成(batch_size, 1, 1, mask_seq_length) attention_mask_shape = shape_list(attention_mask) mask_seq_length = seq_length + past_key_value_length if self.is_decoder: seq_ids = tf.range(mask_seq_length) causal_mask = tf.less_equal( tf.tile(seq_ids[None, None, :], (batch_size, mask_seq_length, 1)), seq_ids[None, :, None] ) causal_mask = tf.cast(causal_mask, dtype=attention_mask.dtype) # 这里的causal_mask * attention_mask[:, None, :]表示考虑到attention_mask的pad信息 extended_attention_mask = causal_mask * attention_mask[:, None, :] attention_mask_shape = shape_list(extended_attention_mask) extended_attention_mask = tf.reshape( extended_attention_mask, (attention_mask_shape[0], 1, attention_mask_shape[1], attention_mask_shape[2]) ) if past_key_value_length > 0: extended_attention_mask = extended_attention_mask[:, :, -seq_length, :] else: extended_attention_mask = tf.reshape( attention_mask, (attention_mask_shape[0], 1, 1, attention_mask_shape[1]) ) extended_attention_mask = tf.cast(extended_attention_mask, dtype=attention_mask.dtype) # 与下面代码等价 # extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0 one_cst = tf.constant(1.0, dtype=hidden_states.dtype) ten_thousand_cst = tf.constant(-10000.0, dtype=hidden_states.dtype) extended_attention_mask = tf.multiply(tf.subtract(one_cst, extended_attention_mask), ten_thousand_cst) # encoder_attention_mask # 用于参与计算decoder的cross_attention if self.is_decoder and encoder_attention_mask is not None: encoder_attention_mask = tf.cast(encoder_attention_mask, dtype=extended_attention_mask.dtype) num_dims_encoder_attention_mask = len(shape_list(encoder_attention_mask)) if num_dims_encoder_attention_mask == 3: encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :] if num_dims_encoder_attention_mask == 2: encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :] encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0 else: encoder_extended_attention_mask = None if head_mask is not None: raise NotImplementedError else: head_mask = [None] * self.config.num_hidden_layers if hasattr(self, "embeddings_project"): hidden_states = self.embeddings_project(hidden_states, training=training) hidden_states = self.encoder( hidden_states=hidden_states, attention_mask=extended_attention_mask, head_mask=head_mask, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_extended_attention_mask, past_key_values=past_key_values, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, training=training ) return hidden_states class TFElectraEmbeddings(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.config = config self.vocab_size = config.vocab_size self.type_vocab_size = config.type_vocab_size self.embedding_size = config.embedding_size self.max_position_embeddings = config.max_position_embeddings self.initializer_range = config.initializer_range self.layer_norm = layers.LayerNormalization(epsilon=config.layer_norm_eps, name="layer_norm") self.dropout = layers.Dropout(rate=config.hidden_dropout) def build(self, input_shape): with tf.name_scope("word_embeddings"): self.word_mebeddings = self.add_weight( name="embeddings", shape=[self.vocab_size, self.embedding_size], initializer=get_initializer(self.initializer_range) ) with tf.name_scope("token_type_embeddings"): self.token_type_embeddings = self.add_weight( name="embeddings", shape=[self.type_vocab_size, self.embedding_size], initializer=get_initializer(self.initializer_range) ) with tf.name_scope("position_embeddings"): self.position_embeddings = self.add_weight( name="embeddings", shape=[self.max_position_embeddings, self.embedding_size], initializer=get_initializer(self.initializer_range) ) super().build(input_shape) def call( self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_value_length=0, training=False ): if input_ids is None and inputs_embeds is None: raise ValueError("Need to provide either `input_ids` or `input_embeds`.") if input_ids is not None: inputs_embeds = tf.gather(self.word_mebeddings, input_ids) input_shape = shape_list(inputs_embeds)[: -1] if token_type_ids is None: token_type_ids = tf.fill(input_shape, value=0) if position_ids is None: position_ids = tf.expand_dims( tf.range(past_key_value_length, input_shape[1] + past_key_value_length), axis=0 ) position_embeds = tf.gather(self.position_embeddings, position_ids) token_type_embeds = tf.gather(self.token_type_embeddings, token_type_ids) final_embeddings = inputs_embeds + token_type_embeds + position_embeds final_embeddings = self.layer_norm(final_embeddings) final_embeddings = self.dropout(final_embeddings) return final_embeddings class TFElectraEncoder(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.config = config self.layer = [TFElectraLayer(config, name=f"layer_._{i}") for i in range(config.num_hidden_layers)] def call( self, hidden_states=None, attention_mask=None, head_mask=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None, use_cache=None, output_attentions=None, output_hidden_states=None, return_dict=None, training=False ): all_hidden_states = () if output_hidden_states else None all_attentions = () if output_attentions else None all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None next_decoder_cache = () if use_cache else None for i, layer_module in enumerate(self.layer): if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states, ) past_key_value = past_key_values[i] if past_key_values is not None else None # 如果是decoder,且 # 如果output_attentions=True,则layer_outputs是一个四元组 # (hidden_states, self-attention, cross_attention, past_key_value) # 如果output_attentions=False,则layer_outputs是一个二元组 # (hidden_states, past_key_value) # 其中past_key_value又是一个四元组 # (self_attn_key_layer, self_attn_value_layer, cross_attn_key_layer, cross_attn_value_layer) # 如果是encoder,且 # 如果output_attentions=True,则layer_outputs是一个二元组 # (hidden_states, attention) # 如果output_attentions=False,则layer_outputs是一个一元组 # (hidden_states) layer_outputs = layer_module( hidden_states=hidden_states, attention_mask=attention_mask, head_mask=head_mask[i], encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, past_key_value=past_key_value, output_attentions=output_attentions, training=training ) hidden_states = layer_outputs[0] if use_cache: next_decoder_cache += (layer_outputs[-1], ) if output_attentions: all_attentions = all_attentions + (layer_outputs[1], ) if self.config.add_cross_attention and encoder_hidden_states is not None: all_cross_attentions = all_cross_attentions + (layer_outputs[2], ) if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states, ) if not return_dict: return tuple( v for v in [hidden_states, all_hidden_states, all_attentions, all_cross_attentions] if v is not None ) return TFBaseModelOutputWithPastAndCrossAttentions( last_hidden_state=hidden_states, past_key_values=next_decoder_cache, hidden_states=all_hidden_states, attentions=all_attentions, cross_attentions=all_cross_attentions, ) class TFElectraLayer(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.attention = TFElectraAttention(config, name="attention") self.is_decoder = config.is_decoder self.add_cross_attention = config.add_cross_attention if self.add_cross_attention: if not self.is_decoder: raise ValueError(f"{self} should be used as a decoder model if cross attention is added") self.cross_attention = TFElectraAttention(config, name="cross_attention") self.intermediate = TFElectraIntermediate(config, name="intermediate") self.bert_output = TFElectraOutput(config, name="output") def call( self, hidden_states=None, attention_mask=None, head_mask=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_value=None, output_attentions=None, training=False ): self_attn_past_key_value = past_key_value[: 2] if past_key_value is not None else None self_attention_outputs = self.attention( input_tensor=hidden_states, attention_mask=attention_mask, head_mask=head_mask, encoder_hidden_states=None, encoder_attention_mask=None, past_key_value=self_attn_past_key_value, output_attentions=output_attentions, training=training ) attention_output = self_attention_outputs[0] if self.is_decoder: outputs = self_attention_outputs[1: -1] present_key_value = self_attention_outputs[-1] else: outputs = self_attention_outputs[-1] if self.is_decoder and encoder_hidden_states is not None: cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None cross_attention_outputs = self.cross_attention( input_tensor=attention_output, attention_mask=attention_mask, head_mask=head_mask, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, past_key_value=cross_attn_past_key_value, output_attentions=output_attentions, training=training ) attention_output = cross_attention_outputs[0] outputs = outputs + cross_attention_outputs[1: -1] cross_attn_present_key_value = cross_attention_outputs[-1] present_key_value = present_key_value + cross_attn_present_key_value intermediate_output = self.intermediate(hidden_states=attention_output) layer_output = self.bert_output( hidden_states=intermediate_output, input_tensor=attention_output, training=training ) outputs = (layer_output,) + outputs if self.is_decoder: outputs = outputs + (present_key_value,) return outputs class TFElectraAttention(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.self_attention = TFElectraSelfAttention(config, name="self_attention") self.dense_output = TFElectraSelfOutput(config, name="dense_output") def call( self, input_tensor=None, attention_mask=None, head_mask=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_value=None, output_attentions=None, training=False ): self_outputs = self.self_attention( hidden_states=input_tensor, attention_mask=attention_mask, head_mask=head_mask, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, past_key_value=past_key_value, output_attentions=output_attentions, training=training ) attention_output = self.dense_output( hidden_states=self_outputs[0], input_tensor=input_tensor, training=training ) outputs = (attention_output,) + self_outputs[1:] return outputs class TFElectraIntermediate(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.dense = tf.keras.layers.Dense( units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="dense" ) if isinstance(config.hidden_act, str): self.intermediate_act_fn = get_tf_activation(config.hidden_act) else: self.intermediate_act_fn = config.hidden_act def call(self, hidden_states) -> tf.Tensor: hidden_states = self.dense(inputs=hidden_states) hidden_states = self.intermediate_act_fn(hidden_states) return hidden_states class TFElectraOutput(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.dense = tf.keras.layers.Dense( units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense" ) self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm") self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob) def call(self, hidden_states, input_tensor, training=False): hidden_states = self.dense(inputs=hidden_states) hidden_states = self.dropout(inputs=hidden_states, training=training) hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor) return hidden_states class TFElectraSelfAttention(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) if config.hidden_size % config.num_attention_heads != 0: raise ValueError( f"The hidden size ({config.hidden_size}) is not a multiple of the number " f"of attention heads ({config.num_attention_heads})" ) self.num_attention_heads = config.num_attention_heads self.attention_head_size = int(config.hidden_size / config.num_attention_heads) self.all_head_size = self.num_attention_heads * self.attention_head_size self.sqrt_att_head_size = math.sqrt(self.attention_head_size) self.query = tf.keras.layers.Dense( units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query" ) self.key = tf.keras.layers.Dense( units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key" ) self.value = tf.keras.layers.Dense( units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value" ) self.dropout = tf.keras.layers.Dropout(rate=config.attention_probs_dropout_prob) self.is_decoder = config.is_decoder def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor: tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size)) return tf.transpose(tensor, perm=[0, 2, 1, 3]) def call( self, hidden_states=None, attention_mask=None, head_mask=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_value=None, output_attentions=None, training=False, ): batch_size = shape_list(hidden_states)[0] mixed_query_layer = self.query(inputs=hidden_states) # If this is instantiated as a cross-attention module, the keys # and values come from an encoder; the attention mask needs to be # such that the encoder's padding tokens are not attended to. is_cross_attention = encoder_hidden_states is not None if is_cross_attention and past_key_value is not None: # reuse k,v, cross_attentions key_layer = past_key_value[0] value_layer = past_key_value[1] attention_mask = encoder_attention_mask elif is_cross_attention: key_layer = self.transpose_for_scores(self.key(inputs=encoder_hidden_states), batch_size) value_layer = self.transpose_for_scores(self.value(inputs=encoder_hidden_states), batch_size) attention_mask = encoder_attention_mask elif past_key_value is not None: key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size) value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size) key_layer = tf.concat([past_key_value[0], key_layer], axis=2) value_layer = tf.concat([past_key_value[1], value_layer], axis=2) else: key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size) value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size) query_layer = self.transpose_for_scores(mixed_query_layer, batch_size) if self.is_decoder: # if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states. # Further calls to cross_attention layer can then reuse all cross-attention # key/value_states (first "if" case) # if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of # all previous decoder key/value_states. Further calls to uni-directional self-attention # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case) # if encoder bi-directional self-attention `past_key_value` is always `None` past_key_value = (key_layer, value_layer) # Take the dot product between "query" and "key" to get the raw attention scores. # (batch size, num_heads, seq_len_q, seq_len_k) attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype) attention_scores = tf.divide(attention_scores, dk) if attention_mask is not None: # Apply the attention mask is (precomputed for all layers in TFElectraModel call() function) attention_scores = tf.add(attention_scores, attention_mask) # Normalize the attention scores to probabilities. attention_probs = stable_softmax(logits=attention_scores, axis=-1) # This is actually dropping out entire tokens to attend to, which might # seem a bit unusual, but is taken from the original Transformer paper. attention_probs = self.dropout(inputs=attention_probs, training=training) # Mask heads if we want to if head_mask is not None: attention_probs = tf.multiply(attention_probs, head_mask) attention_output = tf.matmul(attention_probs, value_layer) attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, all_head_size) attention_output = tf.reshape(tensor=attention_output, shape=(batch_size, -1, self.all_head_size)) outputs = (attention_output, attention_probs) if output_attentions else (attention_output,) if self.is_decoder: outputs = outputs + (past_key_value,) return outputs class TFElectraSelfOutput(layers.Layer): def __init__(self, config, **kwargs): super().__init__(**kwargs) self.dense = tf.keras.layers.Dense( units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense" ) self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm") self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob) def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor: hidden_states = self.dense(inputs=hidden_states) hidden_states = self.dropout(inputs=hidden_states, training=training) hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor) return hidden_states @dataclass class TFBaseModelOutputWithPastAndCrossAttentions(ModelOutput): last_hidden_state: tf.Tensor = None past_key_values: Optional[List[tf.Tensor]] = None hidden_states: Optional[Tuple[tf.Tensor]] = None attentions: Optional[Tuple[tf.Tensor]] = None cross_attentions: Optional[Tuple[tf.Tensor]] = None- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
-
相关阅读:
Java实现简易版的【图书管理系统】
JSP总结
java lombok
c语言:用迭代法解决递归问题
看DevExpress丰富图表样式,如何为基金公司业务创新赋能
Java Story
从根上理解Cglib与JDK动态代理
ansible 使用
2023-06-17:说一说redis中渐进式rehash?
Java 加载、编辑和保存WPS表格文件(.et/.ett)
- 原文地址:https://blog.csdn.net/weixin_49346755/article/details/126154495
