-
创建HTML动态数据报告;论文投稿技巧大全(中文版);『高效Pandas指南』随书代码;oneDNN深度神经网络库;前沿论文 | ShowMeAI资讯日报

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
工具&框架
🚧 『Pretty Jupyter』从 Jupyter Notebook 创建漂亮的动态 HTML 报告
https://github.com/JanPalasek/pretty-jupyter
Pretty Jupyter 从 Jupyter Notebook 创建样式精美的动态 html 网页,可以自动生成目录、折叠代码块等,并且这些功能直接集成在输出的 html 页面中,不需要在后端运行解释器。项目提供了在线 demo,感兴趣可以试一下!

🚧 『SynapseML』基于 Apache Spark & SparkML 的分布式机器学习库
https://github.com/microsoft/SynapseML
https://microsoft.github.io/SynapseML/
SynapseML 是一个开源库,基于 Apache Spark 和 SparkML 构建,支持机器学习、分析和模型部署工作流。SynapseML 为 Spark 生态系统添加了许多深度学习和数据科学工具,包括 Spark 机器学习管道、开放神经网络交换 (ONNX)、 LightGBM、 认知服务、 Vowpal Wabbit 和 OpenCV 的无缝集成等,为各种数据源提供强大且高度可扩展的预测和分析模型。


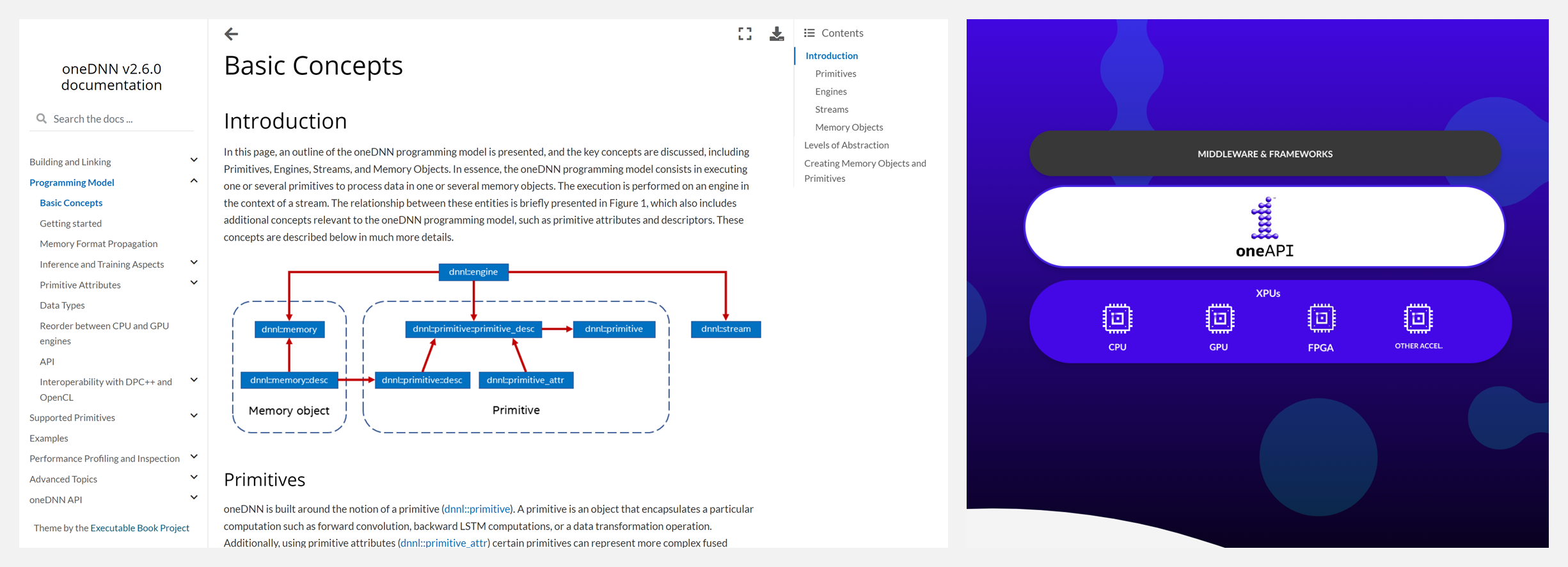
🚧 『oneDNN』oneAPI Deep Neural Network Library / 深度神经网络库
https://github.com/oneapi-src/oneDNN
oneDNN 是面向深度学习应用的开源跨平台性能库,之前被称作 Intel® MKL-DNN、DNNL,是 oneAPI 的一部分。oneDNN 针对英特尔® 架构处理器、英特尔处理器显卡和 Xe 架构显卡进行了优化,提高了英特尔 CPU 和 GPU 上的应用程序性能。对此感兴趣的深度学习开发人员不要错过~
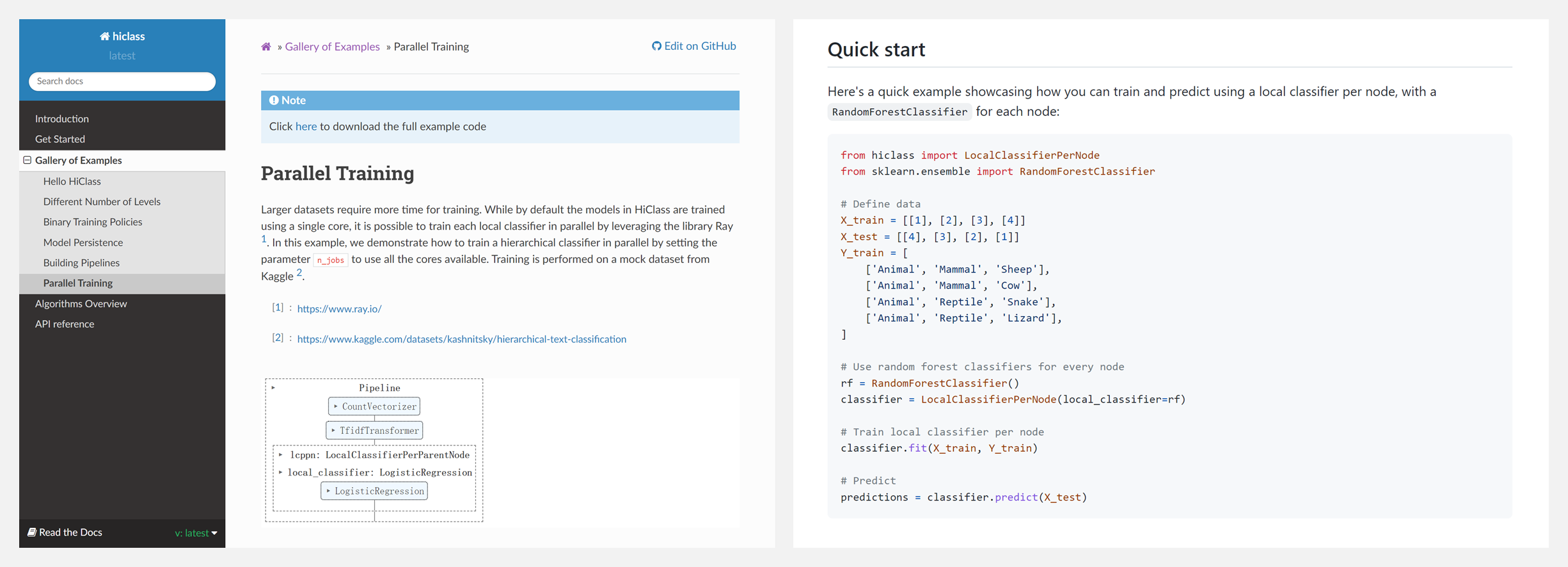
🚧 『HiClass』与 Scikit-Learn 兼容的层次化分类工具库
https://github.com/mirand863/hiclass
HiClass 是一个开源的 Python 库,用于与 Scikit-Learn 兼容的层次化分类,反映了 Scikit-Learn 中流行的 API,并且允许使用最常见的本地层次化分类设计模式进行训练和预测。
🚧 『Neo-tree.nvim』用于管理文件系统(和其他类似树状结构)的 Neovim 插件
https://github.com/nvim-neo-tree/neo-tree.nvim
Neo-tree 是一个 Neovim 插件,可以浏览文件系统和其他树状结构,包括侧边栏、浮动窗口等。

🚧 『StreamX』 Flink/Spark 极速开发框架,一站式流数据处理平台
https://github.com/streamxhub/streamx
StreamX 提供开箱即用的流式大数据开发体验,规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的 Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程,提供了 Scala/Java 两套 api,打造了一站式大数据平台。项目的初衷是让流处理更简单,极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务。

博文&分享
👍 『Paper Writing Tips』论文撰写投稿技巧(中文)
https://github.com/mikeroyal/Photogrammetry-Guide
为了帮助初学者在投稿时快速定位&避免一些小错误,项目总结了作者在投稿过程中的经验。项目列写的常见错误均配有正反示例,终稿必查可用于投稿前一周的自查,并汇总了网络上优质的公开资源。

👍 『Photogrammetry Guide』摄影测量(Photogrammetry)指南
https://github.com/mikeroyal/Photogrammetry-Guide
Photogrammetry Guide 涵盖摄影测量的学习资源、应用程序/库/工具、Autodesk 开发、LiDAR 开发、游戏开发、机器学习、Python 开发、R 开发等,可以帮助使用者更高效地进行摄影测量开发。

数据&资源
🔥 『高效 Pandas 指南』随书代码
https://github.com/mattharrison/effective_pandas_book

🔥 『Awesome Camouflaged Object Detection』用于伪装/隐藏目标检测(COD)的相关资源列表
https://github.com/visionxiang/awesome-camouflaged-object-detection

研究&论文

可以点击 这里 回复关键字日报,免费获取整理好的论文合辑。
科研进展
- CVPR 2022 『计算机视觉』 MiniViT: Compressing Vision Transformers with Weight Multiplexing
- 2022.07.20 『计算机视觉』 CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
- 2022.07.21 『计算机视觉』 TinyViT: Fast Pretraining Distillation for Small Vision Transformers
- 2022.07.16 『计算机视觉』 You Should Look at All Objects
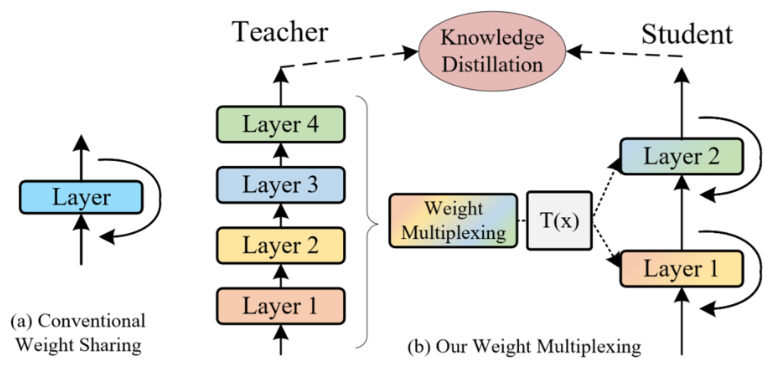
⚡ 论文:MiniViT: Compressing Vision Transformers with Weight Multiplexing
论文时间:CVPR 2022
所属领域:计算机视觉
对应任务:Image Classification,图像分类
论文地址:https://arxiv.org/abs/2204.07154
代码实现:https://github.com/microsoft/cream,https://github.com/microsoft/AutoML
论文作者:Jinnian Zhang, Houwen Peng, Kan Wu, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
论文简介:The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks./MiniViT的核心思想是对连续的transformer块的权重进行复用。
论文摘要:视觉Transformer(ViT)模型由于其较高的模型能力,最近在计算机视觉领域引起了广泛关注。然而,ViT模型有大量的参数,限制了它们在有限内存设备上的适用性。为了缓解这个问题,我们提出了MiniViT,一个新的压缩框架,它在保持相同性能的同时实现了视觉Transformer的参数减少。MiniViT的核心思想是复用连续Transformer块的权重。更具体地说,我们使权重在各层之间共享,同时对权重进行转换以增加多样性。在自注意上的权重提炼也被应用于将知识从大规模的ViT模型转移到权重复用的紧凑模型。综合实验证明了MiniViT的功效,表明它可以将预先训练好的Swin-B变换器的大小减少48%,同时在ImageNet上实现了1.0%的Top-1准确性的提高。此外,使用单层参数,MiniViT能够将DeiT-B的参数从86M压缩到9M的9.7倍,而不会严重影响其性能。最后,我们通过报告MiniViT在下游基准上的表现来验证它的可转移性。

⚡ 论文:CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
论文时间:20 Jul 2022
所属领域:计算机视觉
对应任务:Autonomous Driving,Domain Adaptation,LIDAR Semantic Segmentation,Point Cloud Segmentation,Semantic Segmentation,Unsupervised Domain Adaptation,自主驾驶,领域适应,激光雷达语义分割,点云分割,语义分割,无监督领域适应
论文地址:https://arxiv.org/abs/2207.09778
代码实现:https://github.com/saltoricristiano/cosmix-uda
论文作者:Cristiano Saltori, Fabio Galasso, Giuseppe Fiameni, Nicu Sebe, Elisa Ricci, Fabio Poiesi
论文简介:We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing./我们提出了一种用于点云UDA的新的样本混合方法,即组合式语义混合(CoSMix),这是第一个基于样本混合的点云分割UDA方法。
论文摘要:3D LiDAR语义分割是自主驾驶的基础。最近提出了几种用于点云数据的无监督领域适应(UDA)方法,以提高不同传感器和环境的模型通用性。在图像领域研究UDA问题的研究人员已经表明,样本混合可以缓解领域转移。我们提出了一种用于点云UDA的新的样本混合方法,即组合式语义混合(CoSMix),这是第一个基于样本混合的点云分割UDA方法。CoSMix由一个双分支的对称网络组成,可以同时处理标记的合成数据(源)和真实世界的无标记点云(目标)。每个分支通过混合来自另一个领域的选定数据,并利用从源标签和目标伪标签中获得的语义信息,在一个领域中运行。我们在两个大规模的数据集上对CoSMix进行了评估,结果显示它在很大程度上胜过了最先进的方法。我们的代码可在https://github.com/saltoricristiano/cosmix-uda获取。



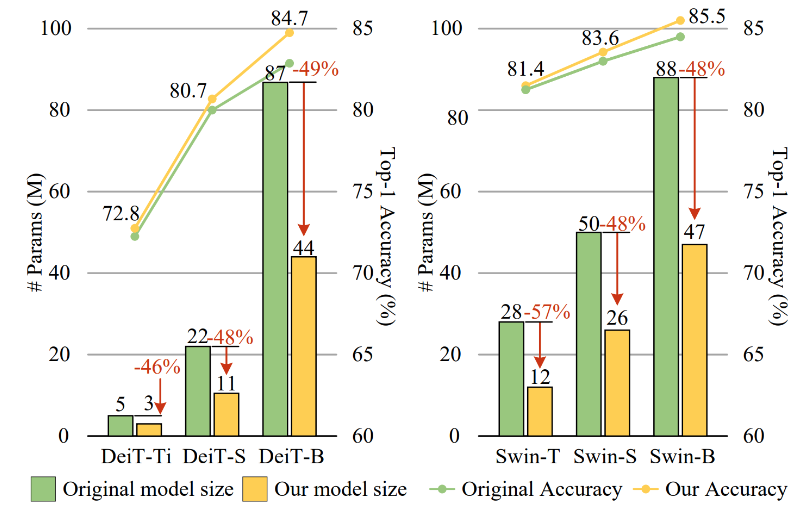
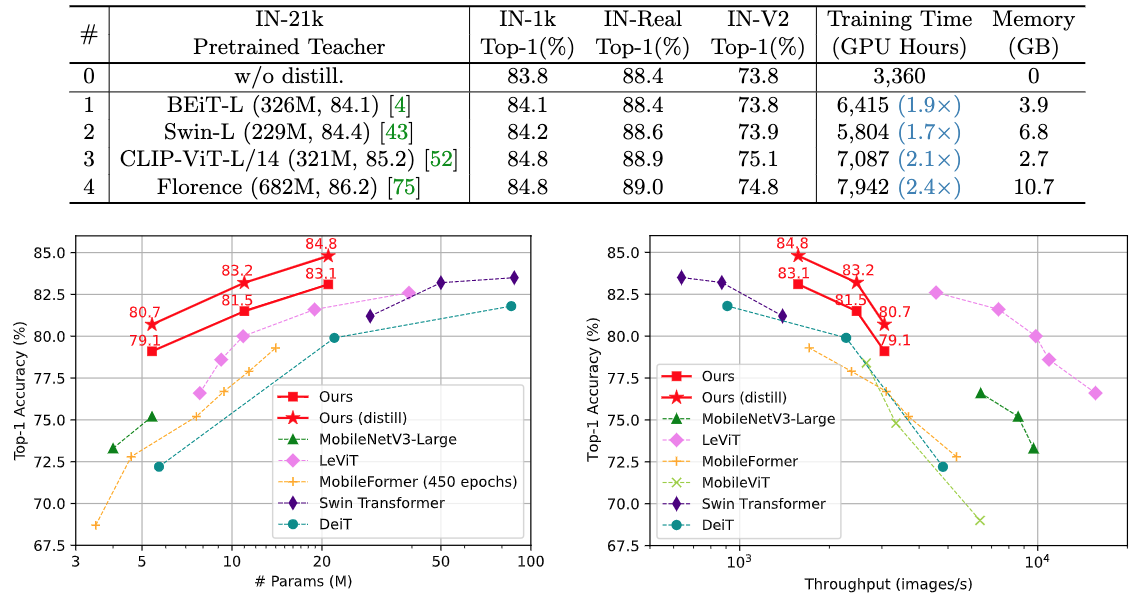
⚡ 论文:TinyViT: Fast Pretraining Distillation for Small Vision Transformers
论文时间:21 Jul 2022
所属领域:计算机视觉
对应任务:Image Classification,Knowledge Distillation,图像分类,知识蒸馏
论文地址:https://arxiv.org/abs/2207.10666
代码实现:https://github.com/microsoft/cream
论文作者:Kan Wu, Jinnian Zhang, Houwen Peng, Mengchen Liu, Bin Xiao, Jianlong Fu, Lu Yuan
论文简介:It achieves a top-1 accuracy of 84. 8% on ImageNet-1k with only 21M parameters, being comparable to Swin-B pretrained on ImageNet-21k while using 4. 2 times fewer parameters./它在ImageNet-1k上达到了84.8%的最高准确率。8%,与在ImageNet-21k上预训练的Swin-B相当,而使用的参数少4.2倍。
论文摘要:视觉transformer(ViT)由于其显著的模型能力,最近在计算机视觉领域引起了极大的关注。然而,大多数流行的ViT模型存在大量的参数,限制了它们在资源有限的设备上的适用性。为了缓解这个问题,我们提出了TinyViT,一个新的微小而高效的小型视觉transformer系列,通过我们提出的快速蒸馏框架对大规模数据集进行预训练。其核心思想是将知识从大型预训练模型转移到小型模型上,同时使小型模型能够获得大规模预训练数据的好处。更具体地说,我们在预训练期间应用蒸馏法进行知识转移。大型教师模型的对数被稀疏化并提前存储在磁盘中,以节省内存成本和计算开销。小小的学生transformer在计算和参数的限制下从大型预训练模型中自动缩减。综合实验证明了TinyViT的功效。它在ImageNet-1k上仅用21M的参数就达到了84.8%的最高准确率,与在ImageNet-21k上预训练的Swin-B相当,而使用的参数少了4.2倍。此外,提高图像分辨率,TinyViT可以达到86.5%的准确率,略好于Swin-L,而只使用11%的参数。最后但同样重要的是,我们证明了TinyViT在各种下游任务中的良好转移能力。代码和模型可在https://github.com/microsoft/Cream/tree/main/TinyViT获取。


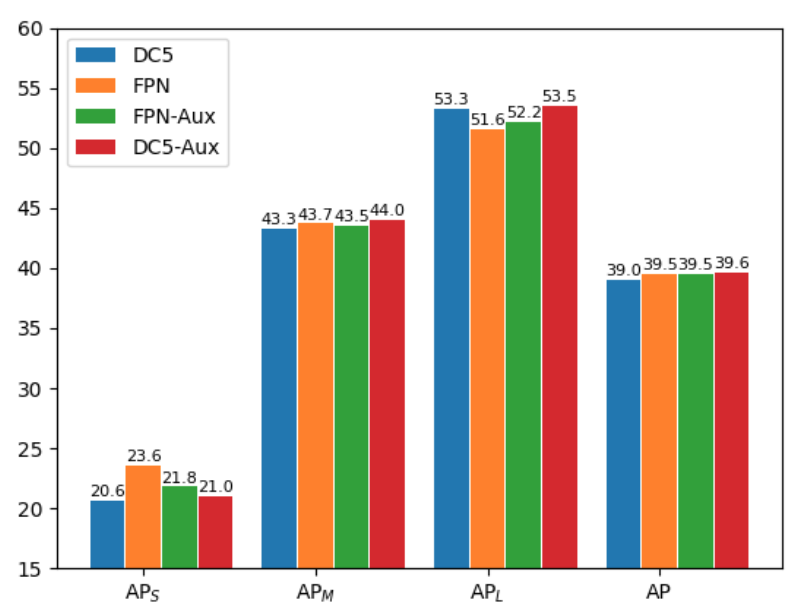
⚡ 论文:You Should Look at All Objects
论文时间:16 Jul 2022
所属领域:计算机视觉
对应任务:目标检测
论文地址:https://arxiv.org/abs/2207.07889
代码实现:https://github.com/charlespikachu/yslao
论文作者:Zhenchao Jin, Dongdong Yu, Luchuan Song, Zehuan Yuan, Lequan Yu
论文简介:Feature pyramid network (FPN) is one of the key components for object detectors./特征金字塔网络(FPN)是物体检测器的关键组件之一。
论文摘要:特征金字塔网络(FPN)是物体检测器的关键组件之一。然而,对于研究人员来说,有一个长期的困惑,即引入FPN后,大规模物体的检测性能通常会被抑制。为此,本文首先在检测框架中重新审视FPN,并从优化的角度揭示了FPN成功的本质。然后,我们指出,大规模物体的性能下降是由于整合FPN后产生了不恰当的反向传播路径。这使得骨干网络的每一级都只有能力查看一定规模范围内的对象。基于这些分析,我们提出了两种可行的策略,以使每一级骨干网络能够观察到基于FPN的检测框架中的所有物体。具体来说,一种是引入辅助目标函数,使每个骨干层在训练时直接接收各种尺度物体的反传播信号。另一个是以更合理的方式构建特征金字塔,避免不合理的反向传播路径。在COCO基准上进行的大量实验验证了我们的分析的合理性和我们方法的有效性。在没有任何花哨技巧的情况下,我们证明了我们的方法在各种检测框架上取得了坚实的改进(超过2%):单阶段、双阶段、基于锚、无锚和基于transformer的检测。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

-
相关阅读:
docker安装运行环境相关的容器
muduo库的高性能日志库(一)
Codeforces Round 952 (Div. 4)(实时更新)
基于.NET6的简单三层管理系统
技能大赛训练:交换机端口带宽限速配置
iOS关于搜索不规则瀑布流布局的实现小结
Vue3类与样式绑定
前端面试题2
C++容器之unordered_map、unordered_set的底层剖析
网盘——删除文件夹
- 原文地址:https://blog.csdn.net/ShowMeAI/article/details/126151566
{kind=link}