-
Python数据可视化------下载数据
CSV文件格式:
要在文本文件中存储数据,一个简单的方式是将数据作为一系列以逗号分隔的值(comma——separated)写入文件。这样的文件称为CSV文件。
举例:
USWA,weather,01,02 aaa,bbb,ccc,02,04- 1
- 2
阅读CSV文件对于我们来说不宜阅读,但使用程序进行处理会很简单。
分析文件头:
import csv#csv模块是包含在Python标准库中 ,可用于分析CSV文件中的数据行 #使用我们之前学过的文件操作的内容打开文件 filename='sitka_weather_07-2018_simple.csv' with open(filename) as f: reader=csv.reader(f)#调用csv.reader()并将存储的文件作为实参传递给它 #为了创建一个与该文件相关联的阅读器对象 header_row=next(reader)#next()函数,返回文件中的下一行 #由于只调用了一次next()函数,因此得到的是文件的第一行 print(header_row)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果为该文件的文件头:
reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一个元素存储在列表中。
['STATION', 'NAME', 'DATE', 'PRCP', 'TAVG', 'TMAX', 'TMIN']- 1
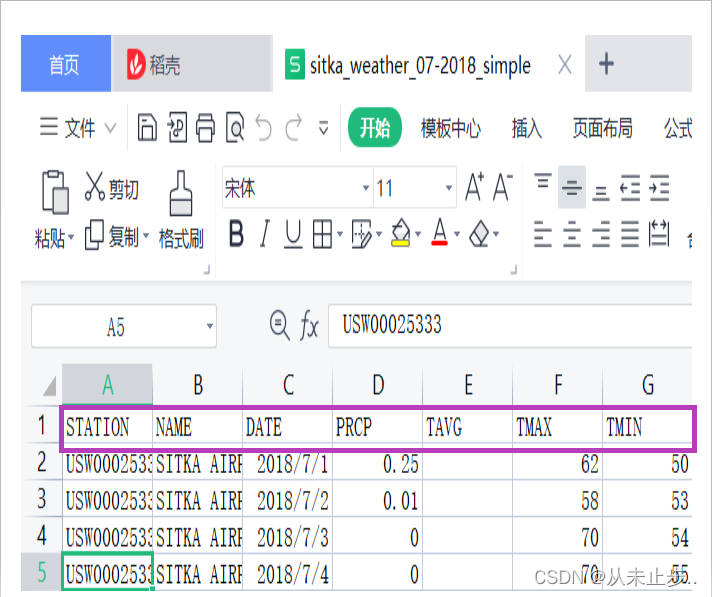
打印文件头及其位置:
为了让文件数据更加容易理解,现在我们将每个文件头及其位置打印出来:
import csv filename='sitka_weather_07-2018_simple.csv' with open(filename) as f: reader=csv.reader(f) header_row=next(reader) #调用enumerate()来获取每个元素的索引及其值 for index,column_header in enumerate(header_row): print(index,column_header)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出每个文件头的索引:
0 STATION 1 NAME 2 DATE 3 PRCP 4 TAVG 5 TMAX 6 TMIN- 1
- 2
- 3
- 4
- 5
- 6
- 7
从输出的索引内容可得,名称在第二行,它的索引值为1,日期在第三行,它的索引值为2等等。
提取并读取文件:
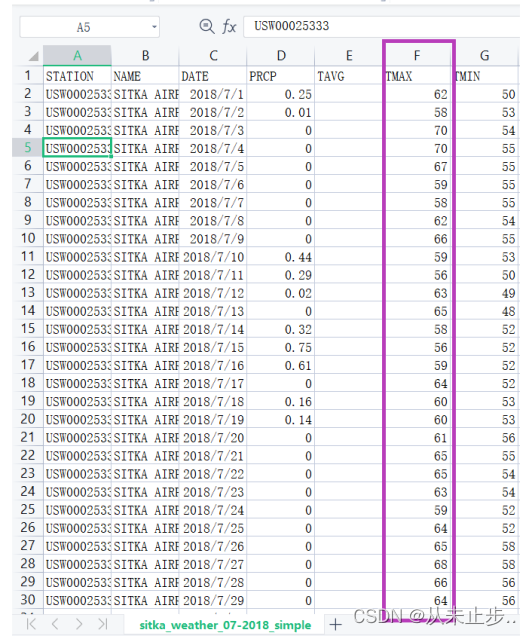
假设现在我们想要读取每天的最高气温:
import csv filename='sitka_weather_07-2018_simple.csv' with open(filename) as f: reader=csv.reader(f) header_row=next(reader) highs=[]#用来存储我们读取的数据 for row in reader:#遍历CSV文件剩下的部分 #由于上面我们已经读取了文件的第一行,所以阅读器将从上次停留的地方继续往下读,也就是第二行开始 high=int(row[5])#每次读取文件的索引值为5的那部分 highs.append(high) print(highs)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如下所示,我们输出了文件索引值为5的部分,也确实是最高温度。
[62, 58, 70, 70, 67, 59, 58, 62, 66, 59, 56, 63, 65, 58, 56, 59, 64, 60, 60, 61, 65, 65, 63, 59, 64, 65, 68, 66, 64, 67, 65]- 1
- 2
绘制温度图表:
前面我们学习了Matplotlib,现在我们就可以可视化这些温度数据。
举例:
import csv import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] filename = 'sitka_weather_07-2018_simple.csv' with open(filename) as f: ---snip--- plt.style.use("seaborn")#根据最高温度绘制图表 fig, ax = plt.subplots() ax.plot(highs, c="red") #设置横纵坐标标签等 ax.set_title("2018年7月每日最高温度",fontsize=24) ax.set_xlabel('',fontsize=16) ax.set_ylabel('温度(F)',fontsize=16) ax.tick_params(axis='both',which='major',labelsize=16) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出效果如下图所示:
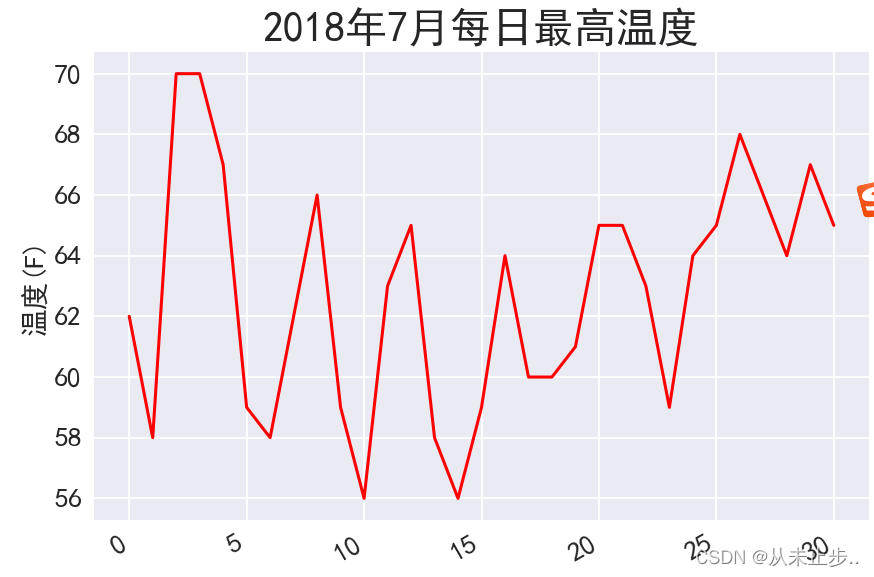
图片呈现给我们的内容并不是完美的,它只是反映出了温度的变化趋势,而并没有表明某日期对应的相关温度。
下面我们就对其进行优化,给它添加日期,在添加之前,我们先来学习模块datetime
模块datetime:
from datetime import datetime#导入日期模块中的datetime类 first_date=datetime.strptime("2018-07-01","%Y-%m-%d")#方法strptime是将包含日期的字符串作为第一个参数,而第二个参数表明日期的格式 print(first_date)- 1
- 2
- 3
输出结果如下:
2018-07-01 00:00:00- 1
方法strptime()可接受各种实参,并且可根据实参来解读对应的日期:
如下图所示:

在图表中添加日期:
import csv from datetime import datetime import matplotlib.pyplot as plt import matplotlib plt.style.use('seaborn') plt.rcParams['font.sans-serif'] = ['SimHei'] matplotlib.rcParams['font.family']='sans-serif' filename = 'sitka_weather_07-2018_simple.csv' with open(filename) as f: reader = csv.reader(f) header_row = next(reader) dates,highs = [],[] # 用来存储我们读取的数据 for row in reader: # 遍历CSV文件剩下的部分 # 由于上面我们已经读取了文件的第一行,所以阅读器将从上次停留的地方继续往下读,也就是第二行开始 current_date=datetime.strptime(row[2],"%Y-%m-%d") high=int(row[5]) dates.append(current_date) highs.append(high) fig,ax = plt.subplots() ax.plot(dates,highs, c="red") ax.set_title("2018年7月每日最高温度",fontsize=24) ax.set_xlabel('',fontsize=16) fig.autofmt_xdate() ax.set_ylabel("温度(F)",fontsize=16) ax.tick_params(axis='both',which='major',labelsize=16) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
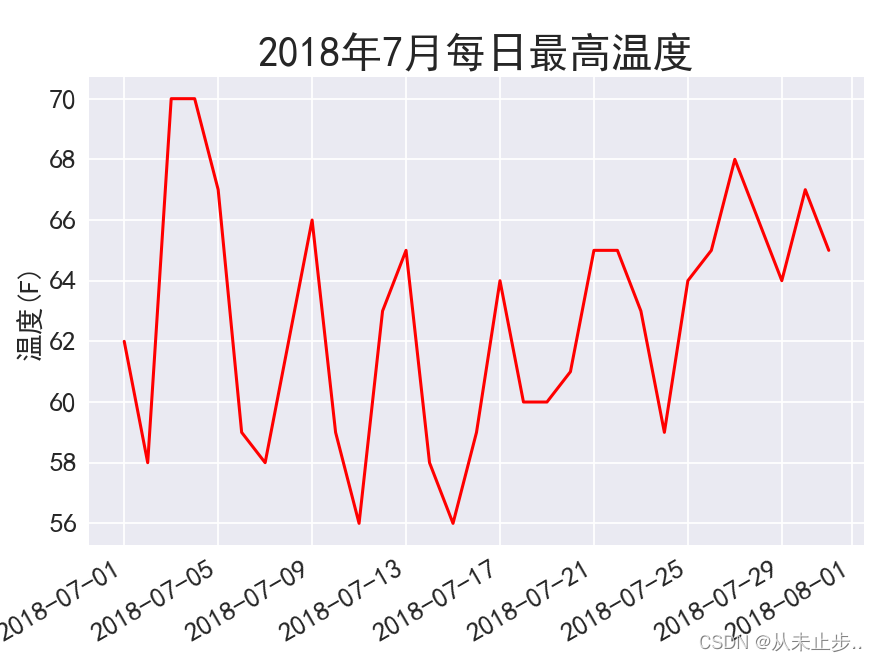
涵盖更长的时间:
上面我们可视化的数据为7月份一个月的天气,现在我们尝试可视化一整年的数据:
---snip--- filename = 'sitka_weather_2018_simple.csv'#打开覆盖一整年数据的文件 with open(filename) as f: reader = csv.reader(f) header_row = next(reader) highs = [] # 用来存储我们读取的数据 for row in reader: # 遍历CSV文件剩下的部分 # 由于上面我们已经读取了文件的第一行,所以阅读器将从上次停留的地方继续往下读,也就是第二行开始 high=int(row[5]) highs.append(high) fig,ax = plt.subplots() ax.plot(highs, c="red") ax.set_title("2018年每日最高温度",fontsize=24) ---snip---- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如下图所示,输出一整年的温度数据。
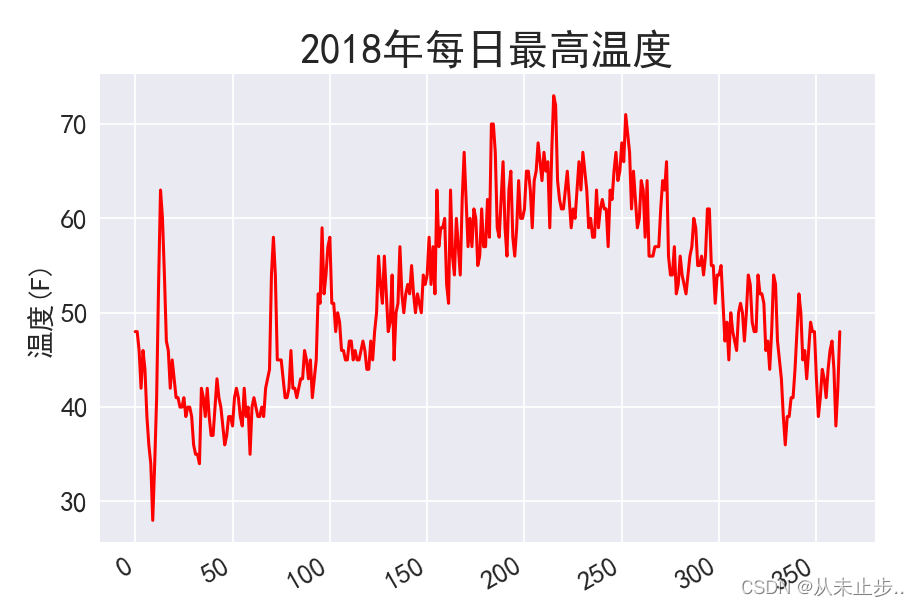
数据系列结合:
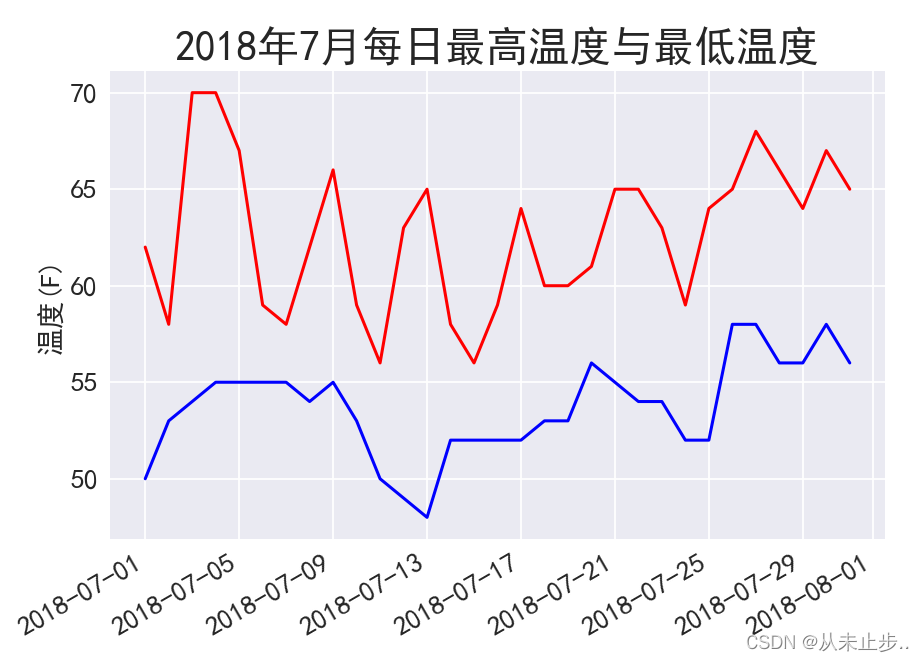
上面我们对2018一整年的最高温度数据进行可视化,为了能够更加了解一整年的温度情况,我们可以尝试将最低温度和最高温度数据结合,进行可视化分析:
对上述代码增加读取最低温度部分的代码,再修改图像的标签即可。
low=int(row[6]) lows.append(low) ax.plot(dates,lows, c="blue") ax.set_title("2018年7月每日最高温度与最低温度",fontsize=24)- 1
- 2
- 3
- 4
输出如下图所示:
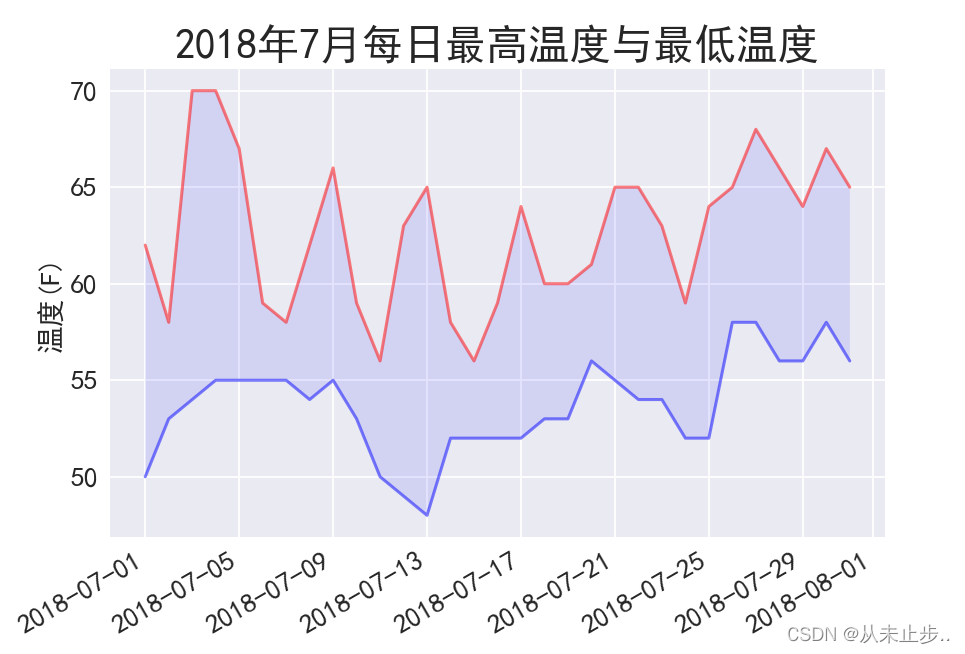
给图表区域着色:
---snip--- #alpha指定颜色的透明度,等于零为完全透明,等于1为完全不透明 ax.plot(dates,highs, c="red",alpha=0.5) ax.plot(dates,lows, c="blue",alpha=0.5) ax.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1)#调用fill__between()函数,该函数的作用是填充两条水平曲线之间的区域 #fill__betweenx()函数的作用是填充两条垂直曲线之间的区域 ---snip---- 1
- 2
- 3
- 4
- 5
- 6
- 7
错误检查:
在对天气的数据进行可视化时,我们应做到让任意地方的天气能够运行我们编写的代码,从而使任何地方的天气数据都能进行可视化,但是,在收集数据的过程中,我们很难保证数据的种类等是一致的,比如,信心的不完整或缺损都可能会引发异常。
举例:
import csv from datetime import datetime import matplotlib.pyplot as plt import matplotlib filename="death_valley_2018_simple.csv" with open(filename) as f: reader=csv.reader(f) header_row=next(reader) dates,highs,lows=[],[],[] for row in reader: current_date=datetime.strptime(row[2],"%Y-%m-%d") high=int(row[4]) low=int(row[5]) dates.append(current_date) for index,conlumn_header in enumerate(header_row): print(index,conlumn_header)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
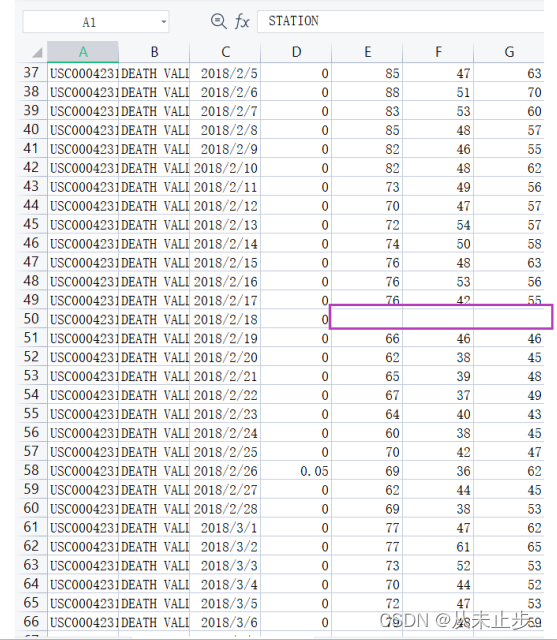
程序并没有正确运行,编译器报告给我们无法处理其中一天的最高温度,原因是无法将空字符串(‘ ’)转化为整数。
Traceback (most recent call last): File "C:/Users/Lenovo/PycharmProjects/pythonProject4/project1.py", line 42, in <module> high=int(row[4]) ValueError: invalid literal for int() with base 10: ''- 1
- 2
- 3
- 4
而当我们打开这个文件就可以找到文件中确实缺失了一些数据。
 既然我们发现异常,就要想办法去处理它,处理它的办法即为我们之前学过的try-except-else代码块。
既然我们发现异常,就要想办法去处理它,处理它的办法即为我们之前学过的try-except-else代码块。处理异常:
---snip--- for row in reader: current_date=datetime.strptime(row[2],"%Y-%m-%d") #对异常进行处理 try: high=int(row[4]) low=int(row[5]) except ValueError: print(f"Missing data for{current_date}") else: dates.append(current_date) highs.append(high) lows.append(low) #描绘图表内容 title="2018年每日最高温度和最低温度\n美国加利福尼亚州死亡谷" fig,ax = plt.subplots() ax.plot(dates,highs, c="red",alpha=0.5) ax.plot(dates,lows, c="blue",alpha=0.5) ax.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1) ax.set_title(title,fontsize=20) ax.set_xlabel('',fontsize=16) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
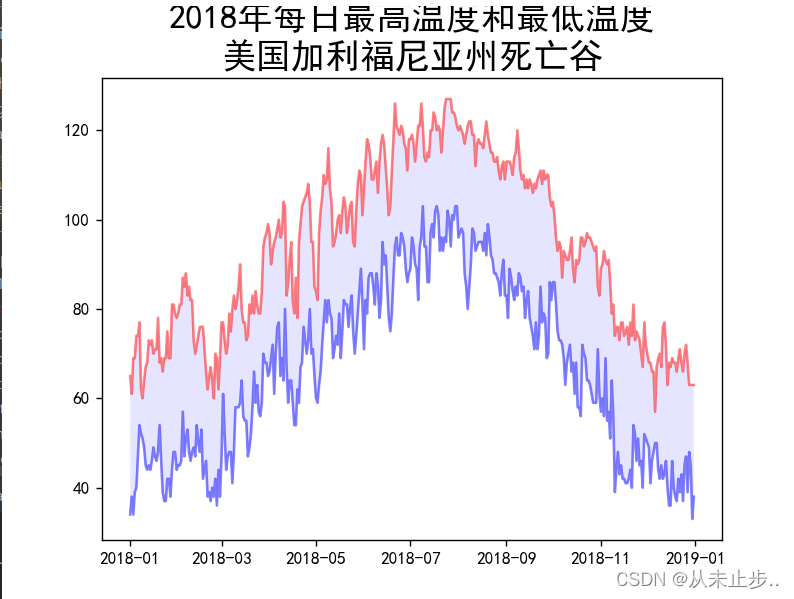
当我们对该异常进行处理之后,输出结果如下:
此时编译器并没有直接报错,而是给我们指出缺少2018年2-18日这一天的数据。
Missing data for2018-02-18 00:00:00- 1
使用try-except-else代码块对异常进行处理后,代码将忽略该天的异常,而生成除了该天以外的图像。
-
相关阅读:
39. UE5 RPG角色释放技能时转向目标方向
Win11无法将值写入注册表项如何解决?
关于Web应用和容器的指纹收集以及自动化软件的制作
JVM之初识垃圾收集器
js调用android 方法
java数据结构与算法——链表面试题
《痞子衡嵌入式半月刊》 第 71 期
2024年最新版小程序云开发数据模型的开通步骤,开始开发微信小程序前的准备工作,认真看完奥!
【MySQL 系列】在 CentOS 上安装 MySQL
视频领域 CLIP4clip:An Empirical Study of CLIP for End to End Video Clip Retrieval
- 原文地址:https://blog.csdn.net/m0_64365419/article/details/126133483