-
轻量级网络整理及其在Yolov5上的实现
我的学习路线依旧是

以及一些比较新的轻量级网络
华为唯一真神涵盖了大量backbone1.PP-LCNet
整体block架构:
NET_CONFIG = { "blocks2": # k, in_c, out_c, s, use_se [[3, 16, 32, 1, False]], "blocks3": [[3, 32, 64, 2, False], [3, 64, 64, 1, False]], "blocks4": [[3, 64, 128, 2, False], [3, 128, 128, 1, False]], "blocks5": [[3, 128, 256, 2, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False], [5, 256, 256, 1, False]], "blocks6": [[5, 256, 512, 2, True], [5, 512, 512, 1, True]] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
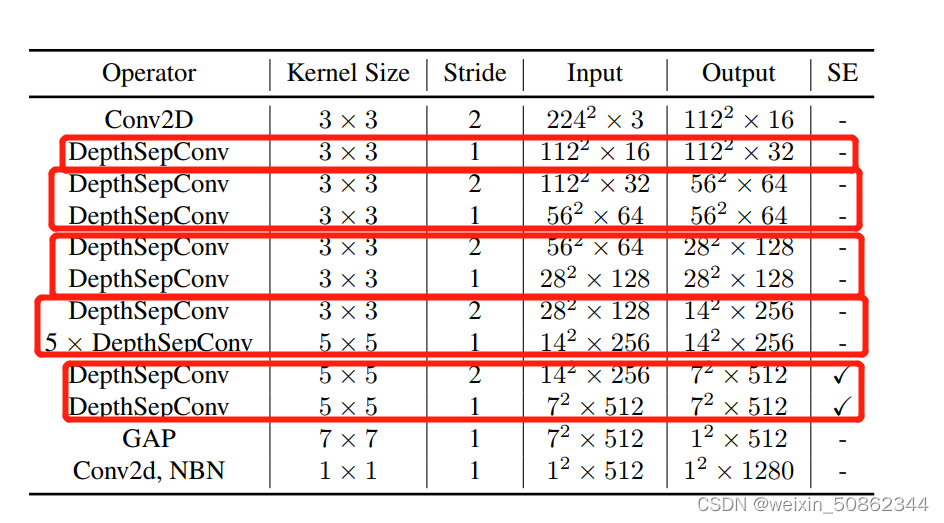
block的对应关系如上图红圈,其他代码都挺规整的我也在我自己的数据集上进行了MobileNetv3+yolov5,PP-LCNet+yolov5,效果确实会好一点!
2.MobileNet(v2)
MobileNet(v2),MobileNet(v3)的代码看这里!!!博主也得很好我就不细写了

1.代码理解疑难点
1)在每个bottleneck(由一个或者多个倒残差结构组成)结构中规定的s指的是第1层倒残差结构的步距stride = s if i == 0 else 1 # s只规定block中第1层倒残差结构的步距,其它层的步距都为1- 1
- 2
2)初始化
# weight initialization,初始化权重 for m in self.modules(): if isinstance(m, nn.Conv2d): # 如果是卷积层,对权重进行凯明初始化 nn.init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: # 如果有bias,将偏置设置为0 nn.init.zeros_(m.bias) elif isinstance(m, nn.BatchNorm2d): # 如果子模块是BN层 nn.init.ones_(m.weight) # 将方差设置为1 nn.init.zeros_(m.bias) # 将均值设置为0 elif isinstance(m, nn.Linear): # 如果子模块是全连接层 # normal为正态分布函数,将权重调整为均值为0,方差为0.01的正态分布 nn.init.normal_(m.weight, 0, 0.01) nn.init.zeros_(m.bias) # 将偏置设置为0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
MobileNet(v3)
MobileNet(v2),MobileNet(v3)的代码看这里!!!博主也得很好我就不细写了
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi) # 给InvertedResidualConfig传入默认超参数α=1- 1
functools.partial(func[,*args][, **kwargs])接受一个函数作为参数,后面可传入参数供传入函数调用
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)- 1
不管是v2还是v3使用shortcut的条件都相同!!!
①步长为1
②input/output channel相同layers.append(ConvBNActivation(cnf.expanded_c, # 无论是否使用SE模块,最后一层卷积的input_c都等于DW卷积后的output_c cnf.out_c, # 输出特征矩阵的channel为配置文件中给定的#out kernel_size=1, norm_layer=norm_layer, activation_layer=nn.Identity)) # 最后1层卷积的激活函数为线性激活,即没有做任何处理- 1
- 2
- 3
- 4
- 5
- 6
nn.Identity:不区分参数的占位符标识运算符。

对于最后的分类器的代码:self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel), # 输入c等于上面计算所得,输出last_channel为初始化中传入参数 nn.Hardswish(inplace=True), # 使用HS激活函数 nn.Dropout(p=0.2, inplace=True), nn.Linear(last_channel, num_classes)) # 输入节点个数为上1个FC层输出的节点个数,输出节点个数为分类类别个数- 1
- 2
- 3
- 4
- 5
图片中看上去是conv操作为什么代码用的是Linear?
其实很简单:在pooling操作之后,可以理解成将通道转化成(11通道数)的特征图像,使用1*1的卷积实际就是对其进行映射
花了一个不太正式的图大概长这样GhostNet
作者遵循MobileNetV3的基本体系结构的优势,然后使用Ghost bottleneck替换MobileNetV3中的bottleneck
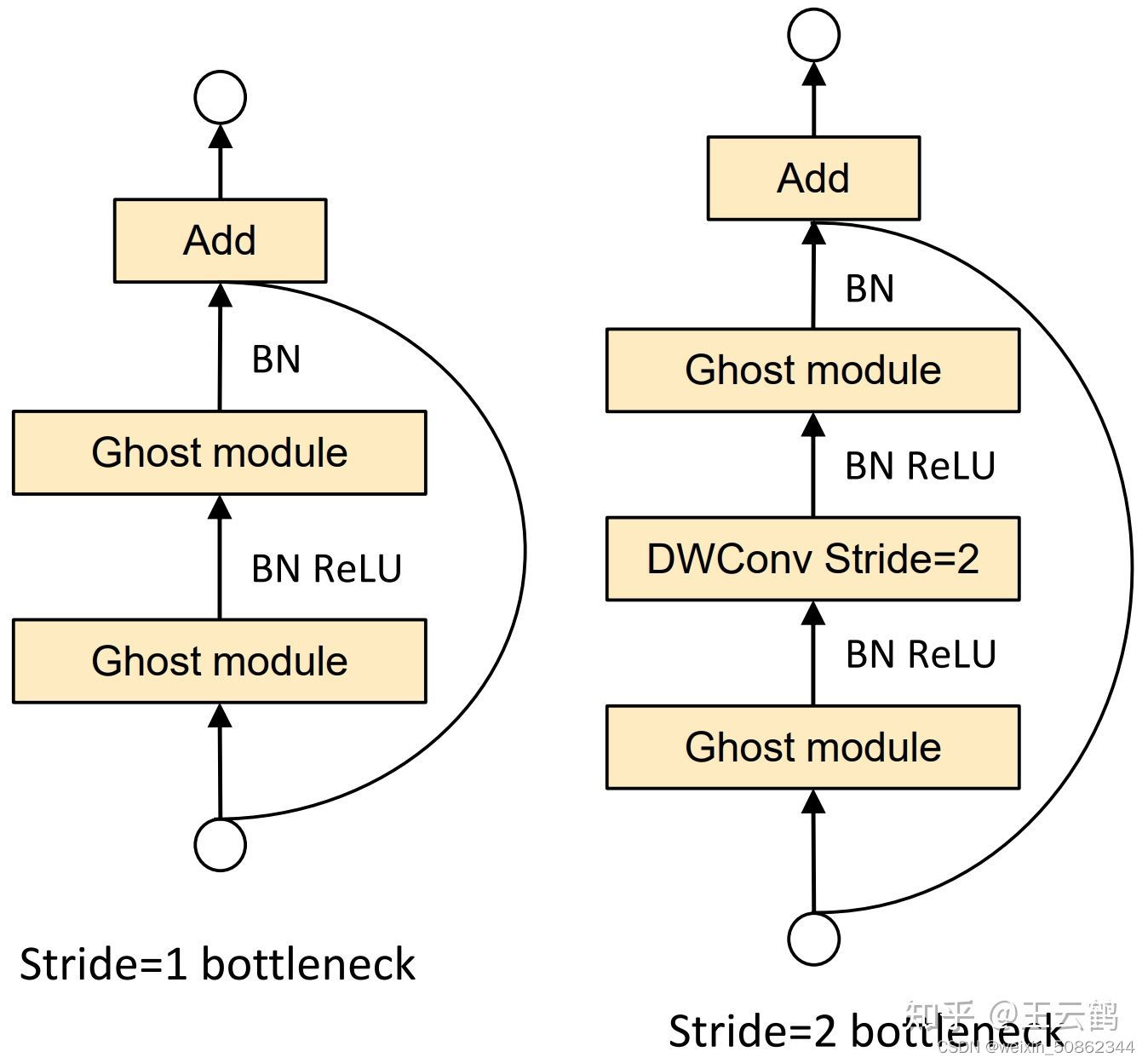
作为整个架构中使用最多的模块GhostModule代码如下:class GhostModule(nn.Module): def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True): super(GhostModule, self).__init__() self.oup = oup init_channels = math.ceil(oup / ratio) new_channels = init_channels*(ratio-1) self.primary_conv = nn.Sequential( nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False), nn.BatchNorm2d(init_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) self.cheap_operation = nn.Sequential( nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False), nn.BatchNorm2d(new_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) def forward(self, x): x1 = self.primary_conv(x) x2 = self.cheap_operation(x1) out = torch.cat([x1,x2], dim=1) return out[:,:self.oup,:,:]#只返回需要的通道数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
cheap_operation为什么使用过conv来实现的?
G-Ghost RegNet 新升级的Ghost

-
相关阅读:
C语言实现带头双向循环链表
阿里云Code并配置IDEA
Spring Boot DTO 到实体映射
jmeter,实现不写文本文件 只要写脚本,自动的给注册
Appium 全新 2.0 全新跨平台生态,版本特性抢鲜体验!
启动Spring Boot项目
金融大模型的下一步是什么?奇富科技费浩峻:大模型需要向小模型学习
Spring MVC中如何进行转发和重定向呢?
贝叶斯定理,先验信念,似然,后验概率
我赢助手教你抖音短视频实操课:如何写出爆款标题(上)爆款标题的分类
- 原文地址:https://blog.csdn.net/weixin_50862344/article/details/126130589
