-
Hadoop运行模式、本地运行模式(官方WordCount)、完全分布式运行模式(开发重点)、scp、rsync 远程同步工具、xsync集群分发脚本
文章目录
- 3.Hadoop运行模式
- 3.1本地运行模式(官方WordCount)
- 3.2完全分布式运行模式(开发重点)
- 3.2.1虚拟机准备
- 3.2.2编写集群分发脚本xsync
- 3.2.2.1scp(secure copy)安全拷贝
- 3.2.2.1.1scp定义
- 3.2.2.1.2基本语法
- 3.2.2.1.3实操
- 3.2.2.1.3.1前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、/opt/software两个目录,并且已经把这两个目录修改为summer:summer
- 3.2.2.1.3.2在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上
- 3.2.2.1.3.3在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上
- 3.2.2.1.3.4在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上
- 3.2.2.2rsync远程同步工具
- 3.2.2.3xsync集群分发脚本
3.Hadoop运行模式
Hadoop官方网站:http://hadoop.apache.org/
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
完全分布式模式:多台服务器组成分布式环境。生产环境使用。
3.1本地运行模式(官方WordCount)
3.1.1创建在hadoop-3.1.3文件下面创建一个testinput文件夹
- [summer@hadoop102 hadoop-3.1.3]$ mkdir testinput
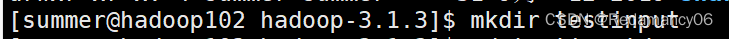
3.1.2在testinput文件下创建一个word.txt文件

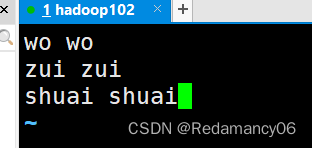
3.1.3编辑word.txt文件
wo wo zui zui shuai shuai- 1
- 2
- 3
- 4
3.1.4回到Hadoop目录/opt/module/hadoop-3.1.3

3.1.5执行程序
- [summer@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount testinput/ testoutput
输入输出路径必须有,输出路径得需要不存在
3.1.6查看结果
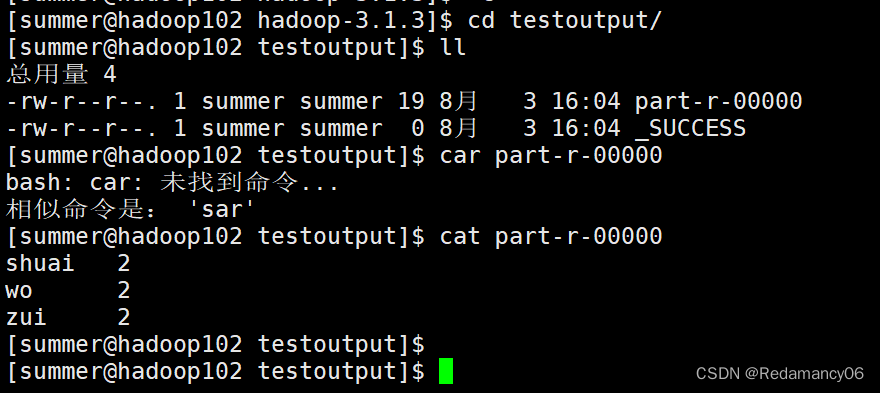
- [summer@hadoop102 testoutput]$ cat part-r-00000
shuai 2
wo 2
zui 2
3.2完全分布式运行模式(开发重点)
分析:
1)准备3台客户机(关闭防火墙、静态IP、主机名称)
2)安装JDK
3)配置环境变量
4)安装Hadoop
5)配置环境变量
6)配置集群
7)单点启动
8)配置ssh
9)群起并测试集群3.2.1虚拟机准备
看我之前写的博客
模板虚拟机环境准备http://t.csdn.cn/oACCG
克隆虚拟机http://t.csdn.cn/3VXn23.2.2编写集群分发脚本xsync
3.2.2.1scp(secure copy)安全拷贝
3.2.2.1.1scp定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
3.2.2.1.2基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称- 1
- 2
3.2.2.1.3实操
3.2.2.1.3.1前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、/opt/software两个目录,并且已经把这两个目录修改为summer:summer
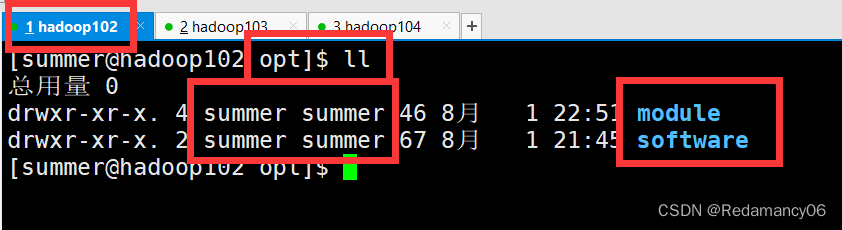
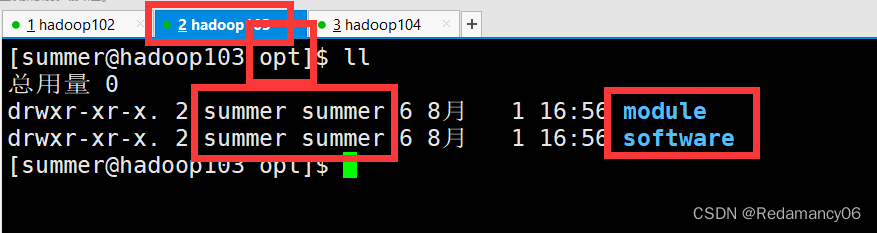

如果有哪一台虚拟机没有将目录修改为summer:summer,或者没有创建好/opt/module、/opt/software两个目录看我之前的博客http://t.csdn.cn/EOONM,
1.1.6
3.2.2.1.3.2在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上
- [summer@hadoop102 module]$ scp -r jdk1.8.0_212/ summer@hadoop103:/opt/module/
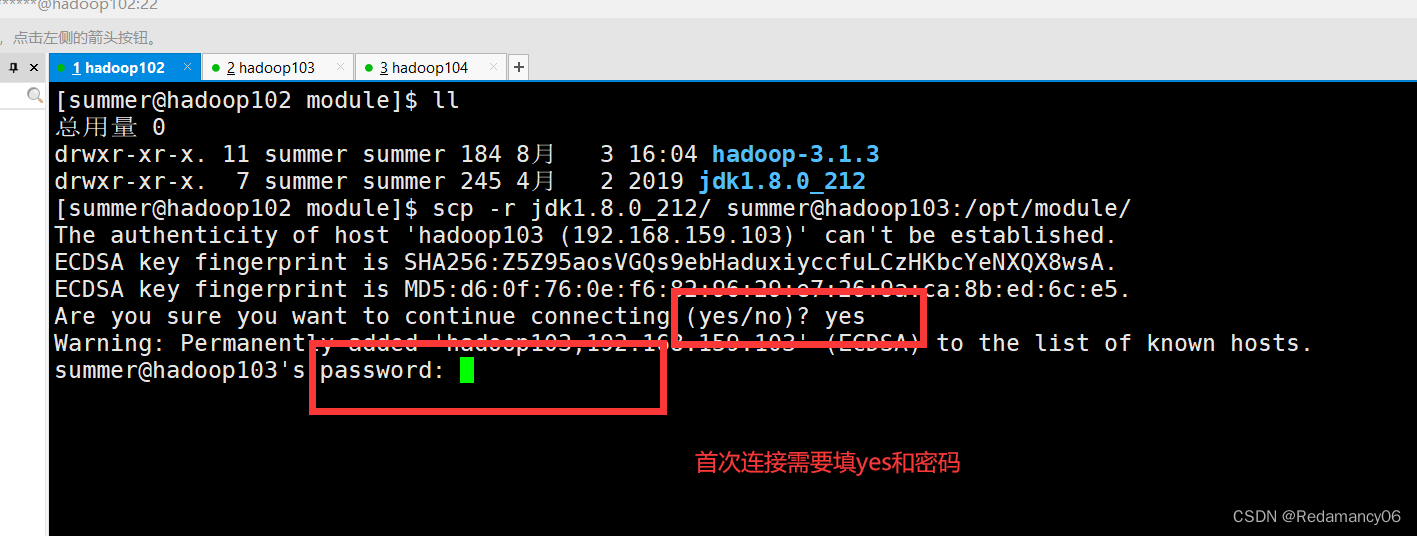

然后就等待拷贝成功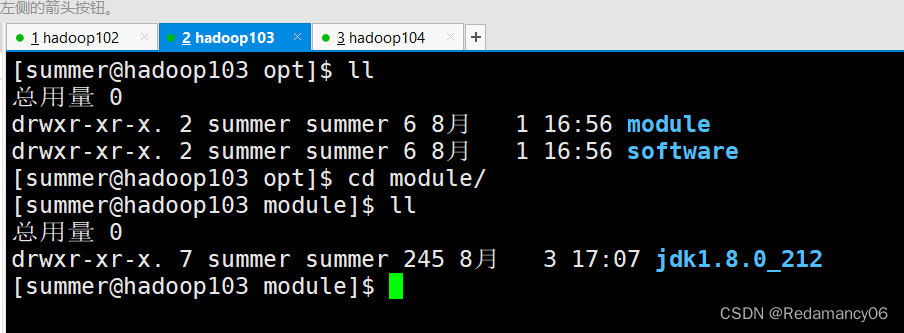
看到hadoop103已经有了jdk了,说明从hadoop102向hadoop103拷贝成功了
3.2.2.1.3.3在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上
- [summer@hadoop103 module]$ scp -r summer@hadoop102:/opt/module/hadoop-3.1.3 ./


然后就等待拷贝成功
看到hadoop103已经有了hadoop了,说明hadoop103从hadoop102中的hadoop拿过来了
3.2.2.1.3.4在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上
- [summer@hadoop103 module]$ scp -r summer@hadoop102:/opt/module/* summer@hadoop104:/opt/module/
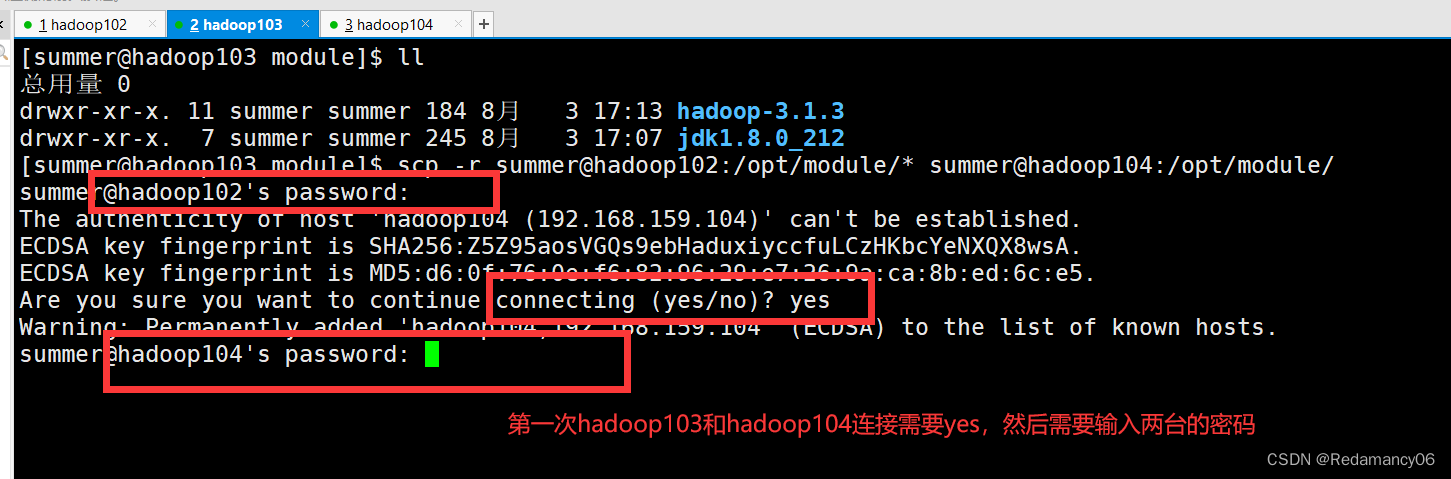

然后就等待拷贝成功
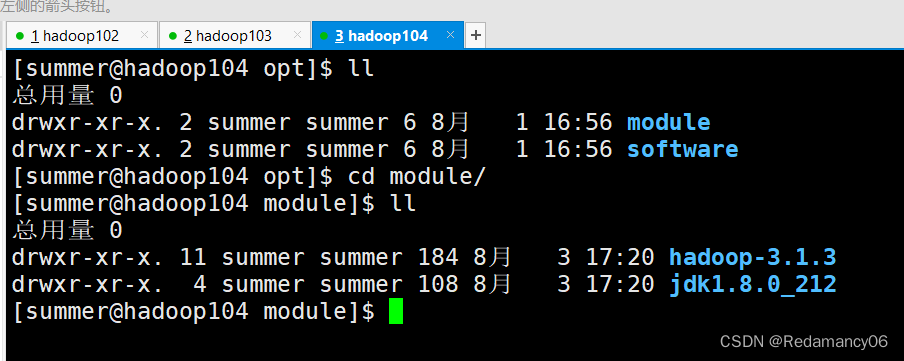
看到hadoop104已经有了jdk和hadoop了,说明在hadoop102中从hadoop102中的jdk和hadoop拷贝到了hadoop104中了
3.2.2.2rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。3.2.2.2.1基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称- 1
- 2
选项参数说明
选项 功能 -a 归档拷贝 -v 显示复制过程 3.2.2.2.2实操
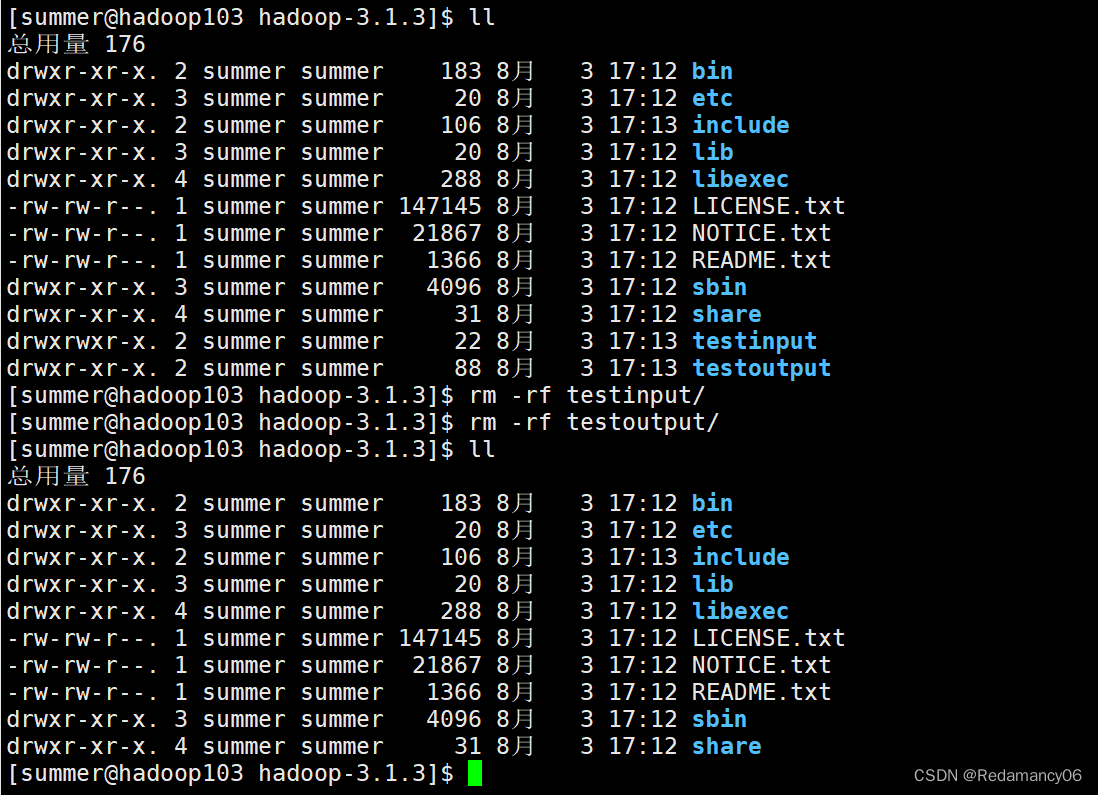
3.2.2.2.2.1删除hadoop103中/opt/module/hadoop-3.1.3/testinput和testoutput
- [summer@hadoop103 hadoop-3.1.3]$ rm -rf testinput/
- [summer@hadoop103 hadoop-3.1.3]$ rm -rf testoutput/
3.2.2.2.2.2同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
- [summer@hadoop102 module]$ rsync -av hadoop-3.1.3/ summer@hadoop103:/opt/module/hadoop-3.1.3/
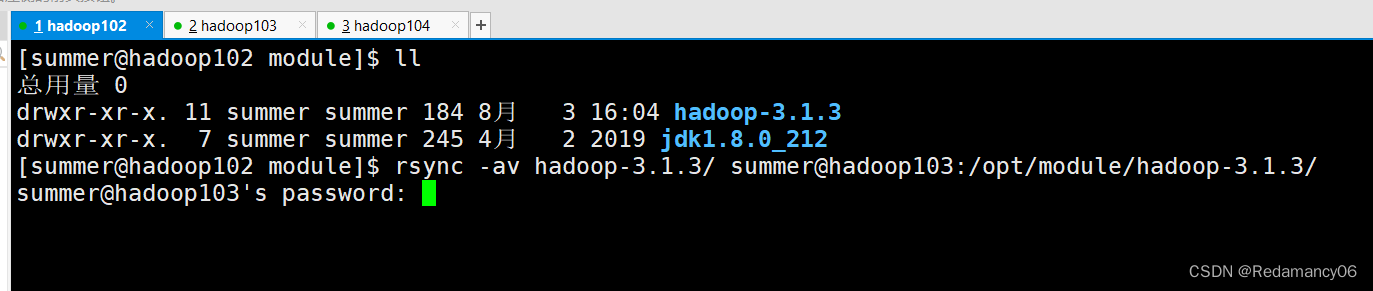
然后就等待成功,这个比scp要快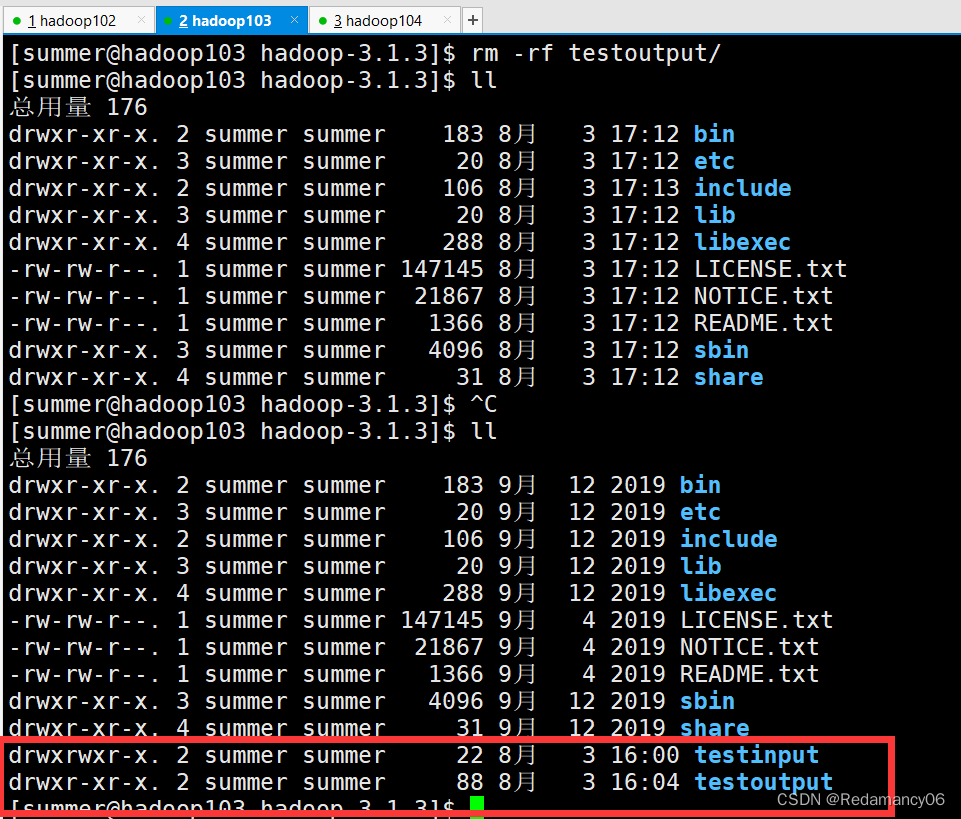
3.2.2.3xsync集群分发脚本
3.2.2.3.1需求:循环复制文件到所有节点的相同目录下
3.2.2.3.2需求分析
3.2.2.3.2.1xsync命令原始拷贝
xsync -av /opt/module summer@hadoop103:/opt/
3.2.2.3.2.2期望脚本
xsync要同步的文件名称
3.2.2.3.2.3期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[summer@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/jdk1.8.0_212/bin:/home/summer/.local/bin:/home/summer/bin
3.2.2.3.3脚本实现
3.2.2.3.3.1在/home/summer/bin目录下创建xsync文件
[summer@hadoop102 ~]$ mkdir bin
[summer@hadoop102 ~]$ cd bin
[summer@hadoop102 bin]$ vim xsync
xsync文件内容为:

#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
3.2.2.3.3.2修改脚本xsync具有执行权限
- [summer@hadoop102 bin]$ chmod 777 xsync

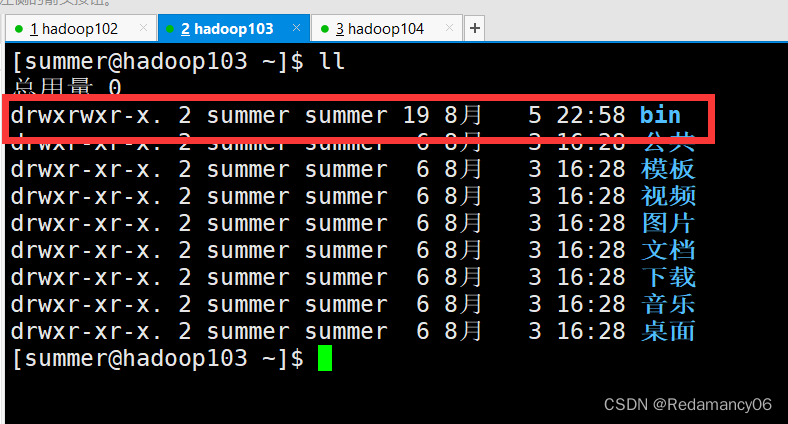
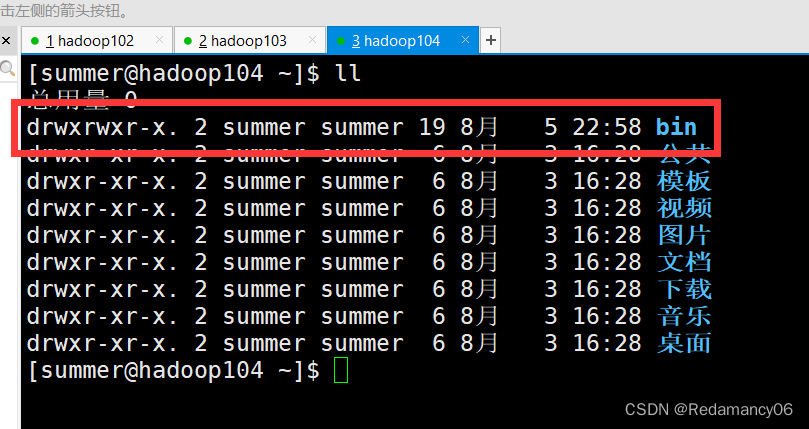
3.2.2.3.3.3测试脚本
- [summer@hadoop102 bin]$ xsync /home/summer/bin

3.2.2.3.3.4将脚本复制到/bin中,以便全局调用
- [summer@hadoop102 bin]$ sudo cp xsync /bin/
3.2.2.3.3.5同步环境变量配置(root所有者)
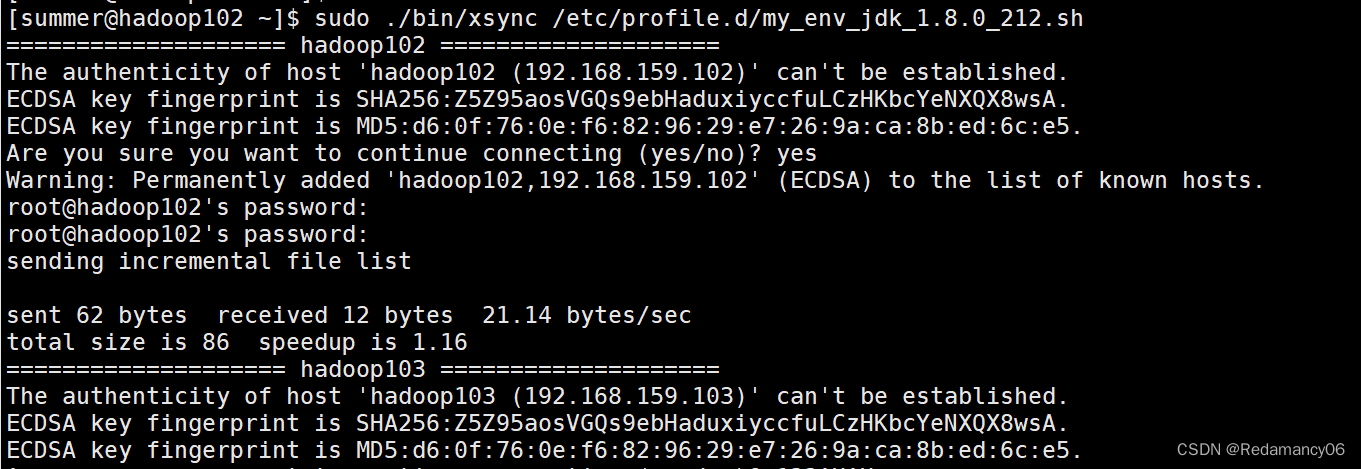
- [summer@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env_hadoop-3.1.3.sh
- [summer@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env_jdk_1.8.0_212.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全



让环境变量生效
- [summer@hadoop103 ~]$ source /etc/profile
- [summer@hadoop104 ~]$ source /etc/profile
-
相关阅读:
从源码分析RocketMq消息的存储原理
【计算机网络笔记】Cookie技术
zookeeper原理
fast planner中拓扑路径搜索及代码解析--topo_prm.cpp
记一次Linux server偶发CPU飙升问题的跟进与解决
挑战100天 AI In LeetCode Day05(热题+面试经典150题)
MS SQL SERVER中的一些特殊表达
洞见云原生微服务及微服务架构浅析
自动驾驶学习笔记(七)——感知融合
Go-Excelize API源码阅读(十三)—— GetSheetVisible、SetSheetFormatPr
- 原文地址:https://blog.csdn.net/Redamancy06/article/details/126141606