-
SparkCore系列-10、Spark 内核调度
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、https://databricks.com/spark/about

回顾
上篇文章介绍了Spark的共享变量,使用共享变量能够提升效率,解决内存。
Spark core的内核调度介绍
Spark的核心是根据RDD来实现的, Spark Scheduler则为Spark核心实现的重要一环,其作用
就是任务调度。 Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依
赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任
务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。以词频统计WordCount程序为例, Job执行是DAG图:

RDD依赖
RDD 的容错机制是通过将 RDD 间转移操作构建成有向无环图来实现的。从抽象的角度看,
RDD 间存在着血统继承关系,其本质上是 RDD之间的依赖(Dependency)关系。从图的角度看, RDD 为节点,在一次转换操作中,创建得到的新 RDD 称为子 RDD,同时会
产生新的边,即依赖关系,子 RDD 依赖向上依赖的 RDD 便是父 RDD,可能会存在多个父 RDD。
可以将这种依赖关系进一步分为两类,分别是窄依赖(NarrowDependency)和 Shuffle 依赖
(Shuffle Dependency 在部分文献中也被称为 Wide Dependency,即宽依赖)。
窄依赖(Narrow Dependency)
窄依赖中: 即父 RDD 与子 RDD 间的分区是一对一的。 换句话说父RDD中,一个分区内的数据是不能被分割的,只能由子RDD中的一个分区整个利用。

上图中 P代表 RDD中的每个分区(Partition),我们看到, RDD 中每个分区内的数据在上面的几
种转移操作之后被一个分区所使用,即其依赖的父分区只有一个。比如图中的 map、 union 和 join
操作,都是窄依赖的。注意, join 操作比较特殊,可能同时存在宽、窄依赖。Shuffle 依赖(宽依赖 Wide Dependency)
Shuffle 有“洗牌、搅乱”的意思,这里所谓的 Shuffle 依赖也会打乱原 RDD 结构的操作。具体来
说, 父 RDD 中的分区可能会被多个子 RDD 分区使用。因为父 RDD 中一个分区内的数据会被分割并
发送给子 RDD 的所有分区,因此 Shuffle 依赖也意味着父 RDD与子 RDD 之间存在着 Shuffle 过程。

上图中P代表RDD中的多个分区,会发现对于 Shuffle 类操作而言,结果 RDD 中的每个分区可能
会依赖多个父 RDD 中的分区。需要说明的是,依赖关系是 RDD 到 RDD 之间的一种映射关系,是两
个 RDD 之间的依赖,如果在一次操作中涉及多个父 RDD,也有可能同时包含窄依赖和 Shuffle 依赖。如何区分宽窄依赖
区分RDD之间的依赖为宽依赖还是窄依赖,主要在于父RDD分区数据与子RDD分区数据关系:
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖;
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖,涉及Shuffle;为什么要设计宽窄依赖??
-
1)对于窄依赖来说: Spark可以并行计算; 如果有一个分区数据丢失,只需要从父RDD的对应
个分区重新计算即可,不需要重新计算整个任务,提高容错。 -
2)对应宽依赖来说: 划分Stage的依据,产生Shuffle
DAG和Stage
在图论中, 如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向
无环图(DAG图)。而在Spark中,由于计算过程很多时候会有先后顺序,受制于某些任务必须比
另一些任务较早执行的限制,必须对任务进行排队,形成一个队列的任务集合,这个队列的任务集
合就是DAG图, 每一个定点就是一个任务,每一条边代表一种限制约束(Spark中的依赖关系) 。
Spark中DAG生成过程的重点是对Stage的划分,其划分的依据是RDD的依赖关系,对于不同
的依赖关系,高层调度器会进行不同的处理。-
对于窄依赖, RDD之间的数据不需要进行Shuffle, 多个数据处理可以在同一台机器的内存中完
成,所以窄依赖在Spark中被划分为同一个Stage; -
对于宽依赖,由于Shuffle的存在,必须等到父RDD的Shuffle处理完成后,才能开始接下来的计
算,所以会在此处进行Stage的切分。

在Spark中, DAG生成的流程关键在于回溯,在程序提交后,高层调度器将所有的RDD看成是一个Stage,然后对此Stage进行从后往前的回溯,遇到Shuffle就断开,遇到窄依赖,则归并到同一个Stage。等到所有的步骤回溯完成,便生成一个DAG图。

把DAG划分成互相依赖的多个Stage,划分依据是RDD之间的宽依赖, Stage是由一组并行的Task组成。 Stage切割规则:从后往前,遇到宽依赖就切割Stage。 Stage计算模式: pipeline管道计算模式, pipeline只是一种计算思想、模式,来一条数据然后计算一条数据,把所有的逻辑走完,然后落地。准确的说: 一个task处理一串分区的数据,整个计算逻辑全部走完。
Spark Shuffle
首先回顾MapReduce框架中Shuffle过程,整体流程图如下:

Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。 Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。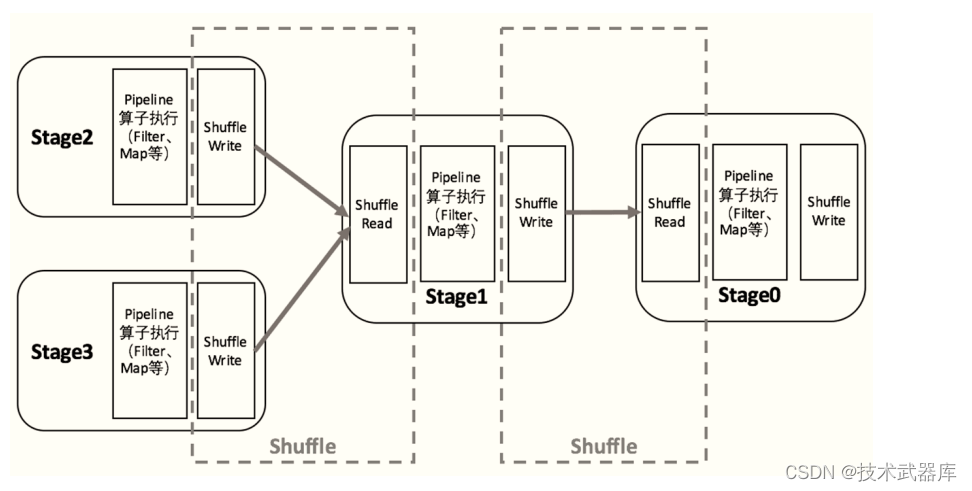
执行Shuffle的主体是Stage中的并发任务,这些任务分ShuffleMapTask和ResultTask两种,ShuffleMapTask要进行Shuffle, ResultTask负责返回计算结果,一个Job中只有最后的Stage采用ResultTask,其他的均为ShuffleMapTask。 如果要按照map端和reduce端来分析的话,ShuffleMapTask可以即是map端任务,又是reduce端任务,因为Spark中的Shuffle是可以串行的;ResultTask则只能充当reduce端任务的角色。
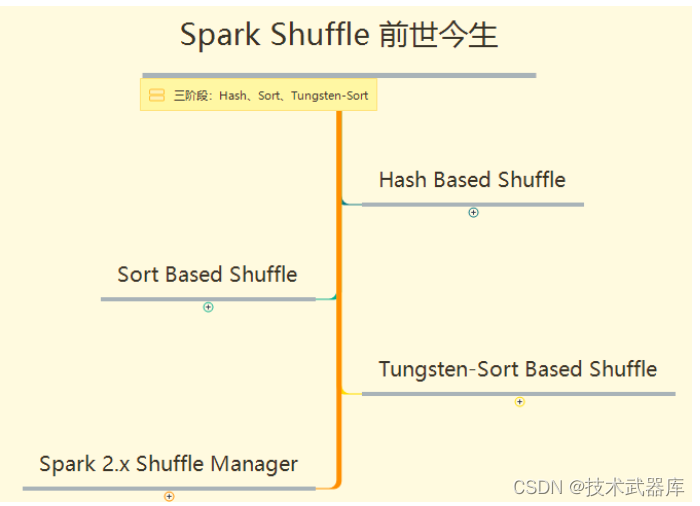
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考HadoopMapReduce的实现开始引入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到的2.0版本, Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。

具体各阶段Shuffle如何实现,参考思维导图XMIND,大纲如下:
Job 调度流程
Spark Application应用的用户代码都是基于RDD的一系列计算操作,实际运行时,这些计算操作是Lazy执行的,并不是所有的RDD操作都会触发Spark往Cluster上提交实际作业,基本上只有一些需要返回数据或者向外部输出的操作才会触发实际计算工作(Action算子),其它的变换操作基本上只是生成对应的RDD记录依赖关系(Transformation算子)。
当启动Spark Application的时候,运行MAIN函数,首先创建SparkContext对象(构建
DAGScheduler和TaskScheduler) 。第一点、 DAGScheduler实例对象
- 将每个Job的DAG图划分为Stage,依据RDD之间依赖为宽依赖(产生Shuffle)
第二点、 TaskScheduler实例对象
- 调度每个Stage中所有Task: TaskSet, 发送到Executor上执行

当RDD调用Action函数(比如count、 saveTextFile或foreachPartition)时,触发一个Job执行,调度中流程如下图所示:

Spark RDD通过其Transactions操作,形成了RDD血缘关系图, 即DAG,最后通过Action的调用,触发Job并调度执行。1)、 DAGScheduler负责Stage级的调度,主要是将DAG切分成若干Stages,并将每个Stage打包成TaskSet交给TaskScheduler调度。
2)、 TaskScheduler负责Task级的调度,将DAGScheduler给过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
Spark的任务调度总体来说分两路进行, 一路是Stage级的调度,一路是Task级的调度。

一个Spark应用程序包括Job、 Stage及Task:第一、 Job是以Action方法为界,遇到一个Action方法则触发一个Job。
第二、 Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分。
第三、 Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。Spark 基本概念
Spark Application运行时,涵盖很多概念,主要如下表格:

官方文档: http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossaryApplication:指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码;
Driver: Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
Cluster Manager:指的是在集群上获取资源的外部服务, Standalone模式下由Master负责, Yarn模式下ResourceManager负责;
Executor:是运行在工作节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执
行分区计算任务的进程;RDD: Resilient Distributed Dataset弹性分布式数据集,是分布式内存的一个抽象概念;
DAG: Directed Acyclic Graph有向无环图,反映RDD之间的依赖关系和执行流程;
Job:作业,按照DAG执行就是一个作业, Job==DAG;
Stage:阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet
任务集;Task:任务,运行在Executor上的工作单元, 1个Task计算1个分区,包括pipline上的一系列操作;
Spark 并行度
Spark作业中, 各个stage的task数量,代表了Spark作业在各个阶段stage的并行度!
资源并行度与数据并行度
在Spark Application运行时,并行度可以从两个方面理解:
1)、资源的并行度:由节点数(executor)和cpu数(core)决定的
2)、数据的并行度: task的数据, partition大小
- task又分为map时的task和reduce(shuffle)时的task;
- task的数目和很多因素有关,资源的总core数, spark.default.parallelism参数,spark.sql.shuffle.partitions参数,读取数据源的类型,shuffle方法的第二个参数,repartition的数目等等。
如果Task的数量多,能用的资源也多,那么并行度自然就好。如果Task的数据少,资源很多,有一定的浪费,但是也还好。如果Task数目很多,但是资源少,那么会执行完一批,再执行下一批。所以官方给出的建议是,这个Task数目要是core总数的2-3倍为佳。如果core有多少Task就有多少,那么有些比较快的task执行完了,一些资源就会处于等待的状态。
设置Task数量
将Task数量设置成与Application总CPU Core 数量相同(理想情况, 150个core,分配150 Task)官方推荐,Task数量,设置成Application总CPU Core数量的2~3倍(150个cpu core,设置task数量为300~500) 与理想情况不同的是:有些Task会运行快一点,比如50s就完了,有些Task可能会慢一点,要一分半才运行完,所以如果你的Task数量,刚好设置的跟CPU Core数量相同,也可能会导致资源的浪费,比如150 Task, 10个先运行完了,剩余140个还在运行,但是这个时候,就有10个CPU Core空闲出来了,导致浪费。如果设置2~3倍,那么一个Task运行完以后,另外一个Task马上补上来,尽量让CPU Core不要空闲。
设置Application的并行度
参数spark.defalut.parallelism默认是没有值的,如果设置了值,是在shuffle的过程才会起作用

案例说明
当提交一个Spark Application时,设置资源信息如下, 基本已经达到了集群或者yarn队列的资源上限:

Task没有设置或者设置的很少, 比如为100个task ,平均分配一下,每个executor 分配到2个task,每个executor 剩下的一个cpu core 就浪费掉了!虽然分配充足了,但是问题是: 并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源。 可以调整Task数目,按照原则: Task数量,设置成Application总CPU Core数量的2~3倍

实际项目中,往往依据数据量(Task数目)配置资源。下回分解
Spark的内核调度到这就结束了,很多小伙伴私信我,说Spark的Maven依赖自己找的不全,我下篇文章专门搞一个Maven依赖,帮助大家。
-
-
相关阅读:
Java高级面试问题
有关于UDP
原生nodejs-搭建后端服务器,完成数据库的链接,客户端的访问,数据库表的操作,包含表单验证,Ajax通信
计算机组成原理笔记(王道考研) 第三章:存储系统
前端配置环境和可能出现的问题
C语言文件操作 | 文件分类、文件打开与关闭、文件的读写、文件状态、文件删除与重命名、文件缓冲区
mysql锁机制
Jupyter Notebook:使用Jupyter NoteBook的时候遇到的一些坑。
Vue.js vs React:哪一个更适合你的项目?
Hustle Pro v7.8.4 快速创建订阅与营销弹窗WordPress插件优化版
- 原文地址:https://blog.csdn.net/l848168/article/details/126141480