前言#
前面有一篇文章《一个有些意思的项目--文件夹对比工具(一)》,里面简单讲了下diff算法之--Myers算法。
既然是算法,就会有实现,比如git diff中有Myers的实现,git diff默认就是用了这个算法(也可以选择其他算法);这个Myers算法,在linux的diff工具中也有实现;或者在一些js库、java库等都有实现。
另外,既然是算法,那就有输入和输出,如果大家都正确实现的话,按理说输出格式也是能达成统一的。
接下来我们就看一下在各个软件中的输出格式。
git diff 输出格式#
样例文件#
附原文件内容,有兴趣可以跟着试试。
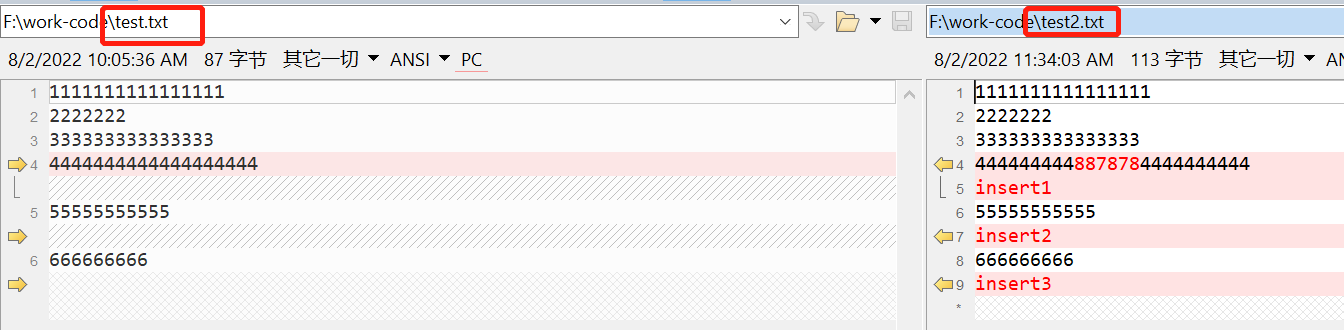
1111111111111111
2222222
333333333333333
4444444444444444444
55555555555
666666666
1111111111111111
2222222
333333333333333
4444444448878784444444444
insert1
55555555555
insert2
666666666
insert3
输出格式#
之前我以为只能在版本间对比文件差异,原来文件也是可以直接对比的,如下:
git diff test.txt test2.txt
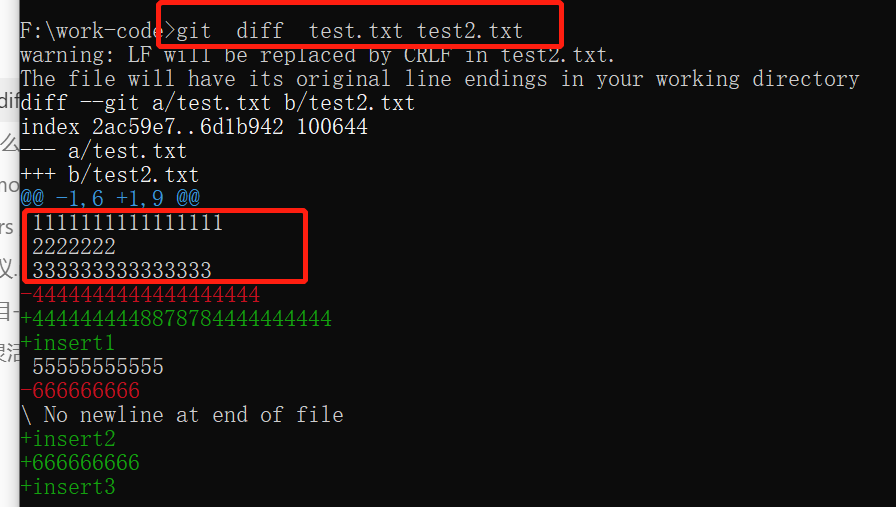
这里可以看到,输出中还包含了一些两侧没变动的行,这是怎么回事呢?主要是,默认情况下,会输出差异行的上下文(即差异行的前面几行和后面几行,默认是三行)。
为了方便我们对比差异,我们先开启一个选项,不展示上下文。
-U
--unified=
Generate diffs with
lines of context instead of the usual three. Implies --patch.
开启这个选项后,输出如下:
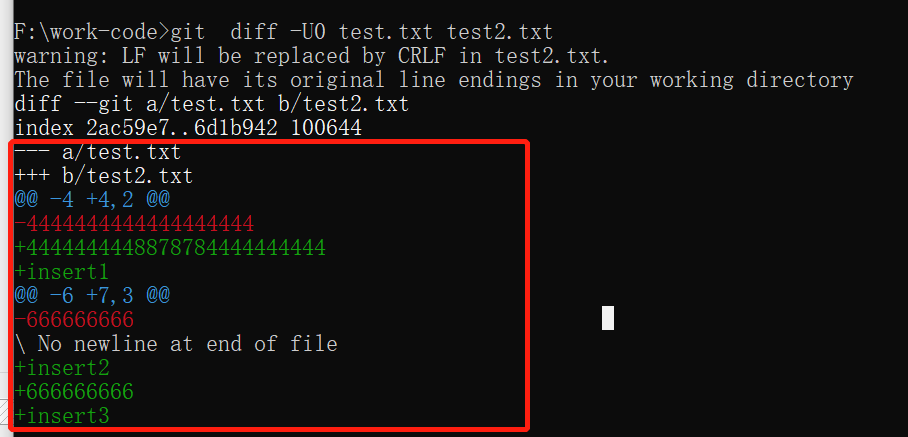
我们看的里面有很多奇怪的符号,看得似懂非懂的,还有一些数字,也不知道啥意思,我们暂且不表,接下来,看看linux diff工具的输出。
linux diff输出格式#
样例文件#
同上。
输出格式(-U选项)#
-U选项,在linux diff文档里,是这个意思,我们指定 -U 0,就是0行上下文。
-u, -U NUM, --unified[=NUM] output NUM (default 3) lines of unified context
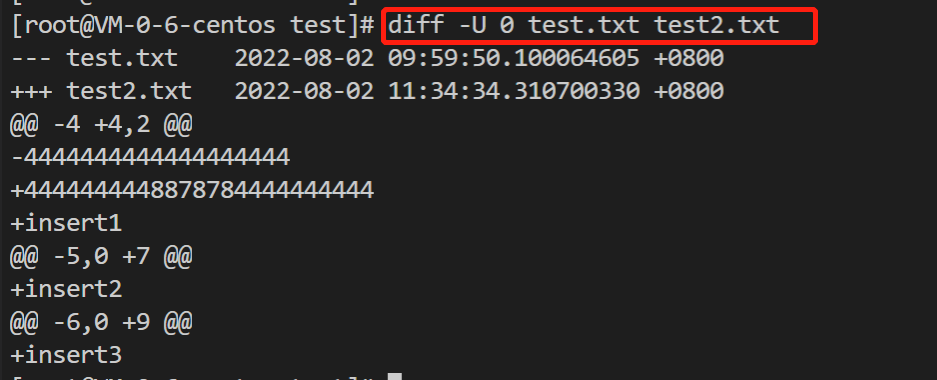
看起来,格式差不太多哈,不过内容不太一样,这个先不用管,大家虽然都是同一个算法,但是部分工具会使用该算法的变体,所以输出有些不同也是正常。
先聚焦于输出格式即可。
默认输出格式(不带各类选项)#

看起来有点奇怪,输出都没有那些@@符号了,好像格式不同了,这是咋回事。
输出格式(-c选项)#
其实还有个选项,如下:
-c, -C NUM, --context[=NUM] output NUM (default 3) lines of copied context
这个看起来像是上下文之类的,我们测试下:
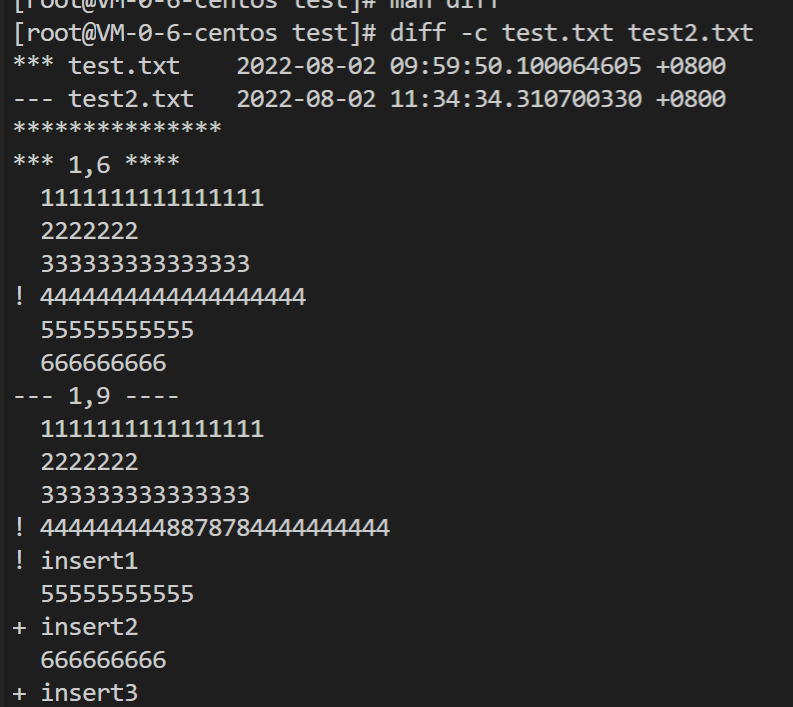
看上去和默认格式、-U格式都不同。
linux diff输出的两种格式(官方文档)#
具体内容都是来自于官方文档:https://www.gnu.org/software/diffutils/manual/html_node/index.html
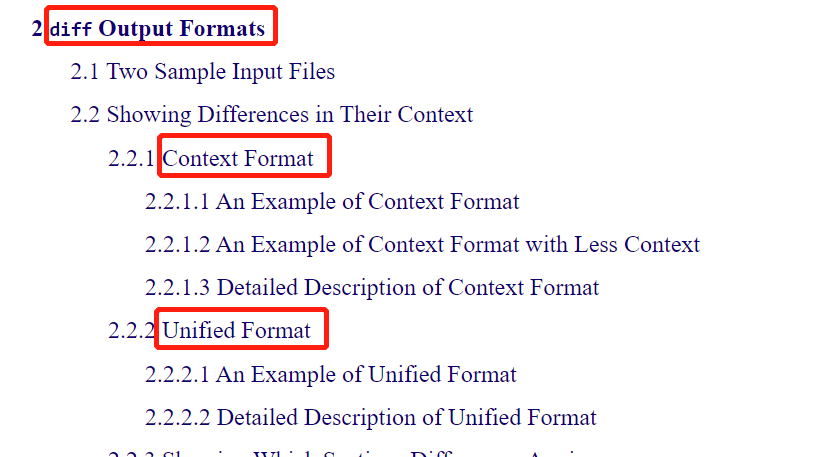
这里提到了两种格式:
-
Context Format,即-c选项时,这种对比文件时,感觉不是很直观;主要的场景是,用diff来生成代码补丁,代码差异行上下有上下文,方便补丁程序patch来进行差异代码定位。
The context output format shows several lines of context around the lines that differ. It is the standard format for distributing updates to source code.
-
Unified Format,即-u选项时,这种对比文件时,感觉还比较方便看;官方定义如下:
The unified output format is a variation on the context format that is more compact because it omits redundant context lines.
即该格式是context format的变体,因为省略了冗余的上下文行,显得更加紧凑。
unified format格式#
简介#
不知道大家发现没,git diff和linux diff(-u)时,产生的格式是一样的,即unified format。
为什么单独讲这个格式呢,因为我发现,有很多文件差异相关的第三方库,不管是js、java啥的,产生的格式都是unified format。
而且,js中还有一个很广泛的库diff2html,是可以接收unified format格式的文件为输入,渲染为美观大方的html组件。
所以,在软件生态来说,该格式已经是一个相对通用的交互格式了,类似于json、xml这样的标准格式,所以,我们就讲解它。
详解#
以如下输出来举例:
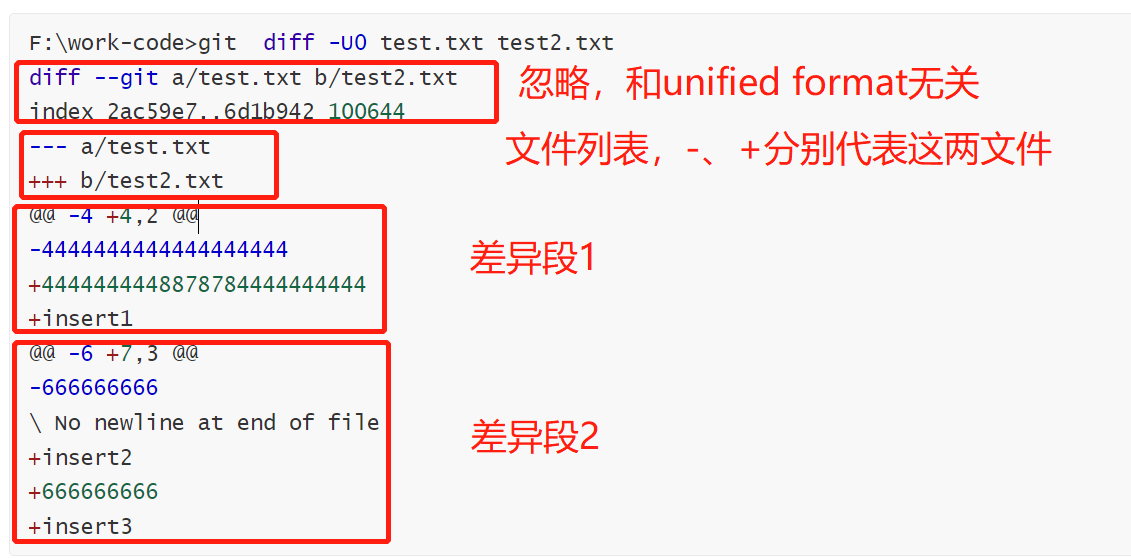
unified format一开始就是文件列表,就是上图的:
--- a/test.txt
+++ b/test2.txt
接下来就是差异段列表了,上图一共两个差异段,有点看不懂?那我们再看看样例文件在beyond compare中的对比效果。
以如下差异段来说:
@@ -4 +4,2 @@
-4444444444444444444
+4444444448878784444444444
+insert1
@@ 这一行,表示一个汇总信息,其中的-4,其实应该是-4,1。 "-"代表文件--- a/test.txt,4代表第四行,test.txt的第4行,就是4444444444444444444这一行,被省略的1,表示展示的text.txt从第4行开始的行的数量。
比如,4,2表示展示第4、5行,4,3表示展示第4、5、6行。
+4,2同理,"+"代表文件+++ a/test2.txt,也就是展示4开头的两行,即第4、5行。
大家再看看这个图,不知道是不是可以理解了:
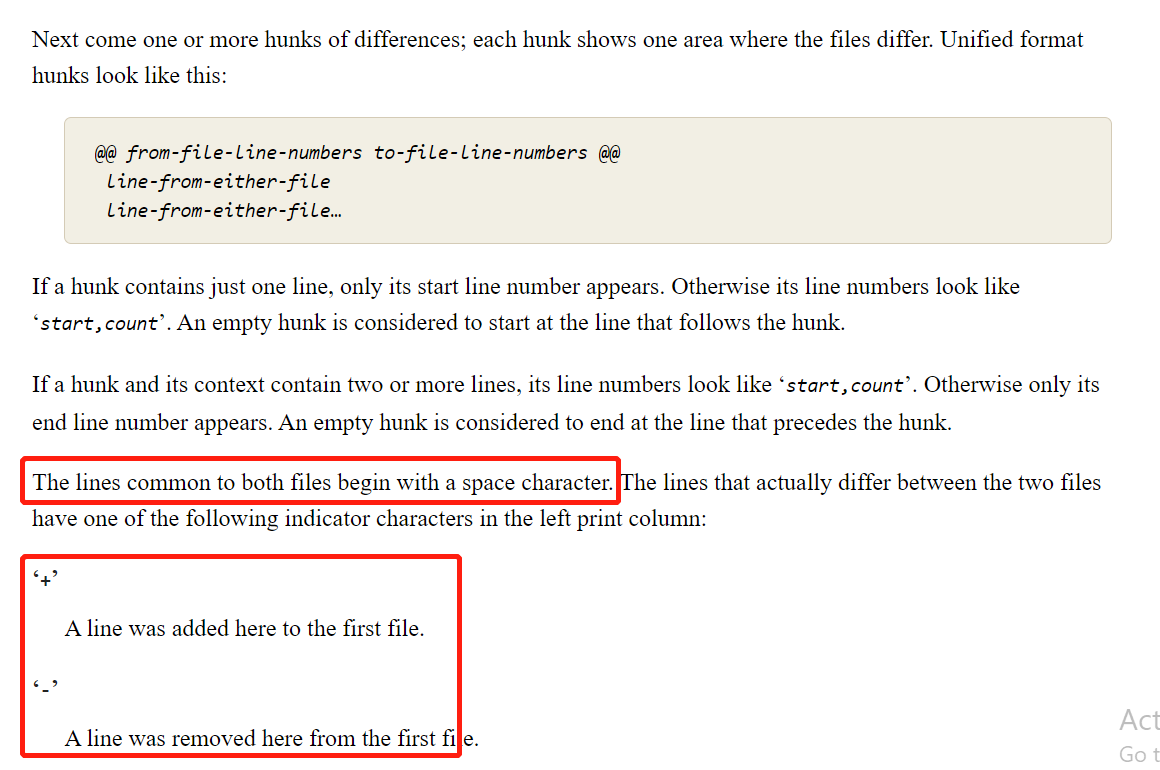
另外,@@是header行,算是一个汇总信息,就像是一个协议包的包头一样,说明包的内容的长度等,或者像是http里的content-length字段。
接下来,就是具体的内容,
@@ -4 +4,2 @@
-4444444444444444444
+4444444448878784444444444
+insert1
比如,-4444444444444444444的“-”不仅表示属于文件text.txt,还表示这行是要被删除的。“+”也是同理,表示是要新增的行。
还有一种情况是,两边行相等(比如需要展示上下文的时候),这种时候的话,前缀就是一个空字符,“ ”。
具体看下面:
https://www.gnu.org/software/diffutils/manual/html_node/Detailed-Unified.html
扩展资料:
https://en.wikipedia.org/wiki/Diff#:~:text=The unified format (要会上网)
diff2html渲染unified format#
之前提到unified format就是个中间格式,只要大家都按这个格式来,生态就建立起来了。
接下来,我们就把前面那个字符串用一个js库:diff2html来渲染一下,看看效果。
先在js中定义个字面量diffString,再用diff2html这个js库来渲染:
const diffString = `--- a/test.txt +++ b/test2.txt @@ -4 +4,2 @@ -4444444444444444444 +4444444448878784444444444 +insert1 @@ -6 +7,3 @@ -666666666 \ No newline at end of file +insert2 +666666666 +insert3`; document.addEventListener('DOMContentLoaded', function () { const targetElement = document.getElementById('filesExistInBothDir'); const configuration = { // 渲染文件列表 drawFileList: true, // 文件列表显示/隐藏的开关 fileListToggle: false, // 默认展示文件列表 fileListStartVisible: false, // 文件内容可收起/展开的开关 fileContentToggle: true, matching: 'lines', // 左右两侧双栏展示 outputFormat: 'side-by-side', // 双栏展示模式时,拖动左边的横向滚动条,右侧同步滚动 synchronisedScroll: true, // 高亮代码 highlight: true, renderNothingWhenEmpty: true, }; const diff2htmlUi = new Diff2HtmlUI(targetElement, diffString, configuration); diff2htmlUi.draw(); diff2htmlUi.highlightCode();折叠
效果如下:
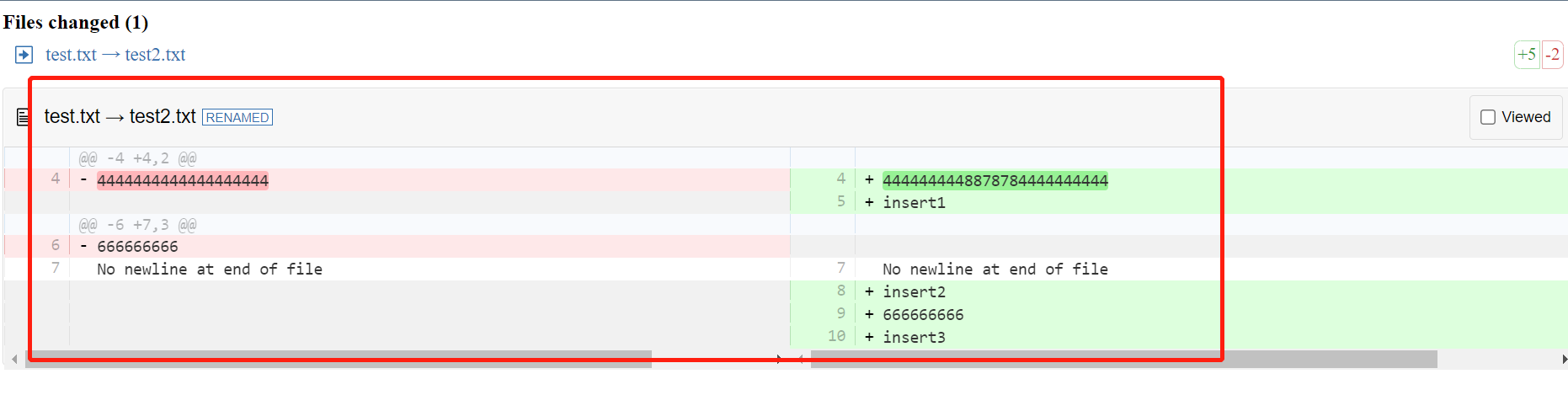
html源文件上传了,感兴趣可以看看:
https://dump-1252523945.cos.ap-shanghai.myqcloud.com/img/compare-result-162513.html
