-
好好学习第一天:手写数字识别
跟着“k同学啊”一起学习深度学习,希望自己能坚持下来。
活动地址:CSDN21天学习挑战赛
第一天学习博客深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天_K同学啊的博客-CSDN博客

我的学习笔记
一、知识点总结
1.基本原理
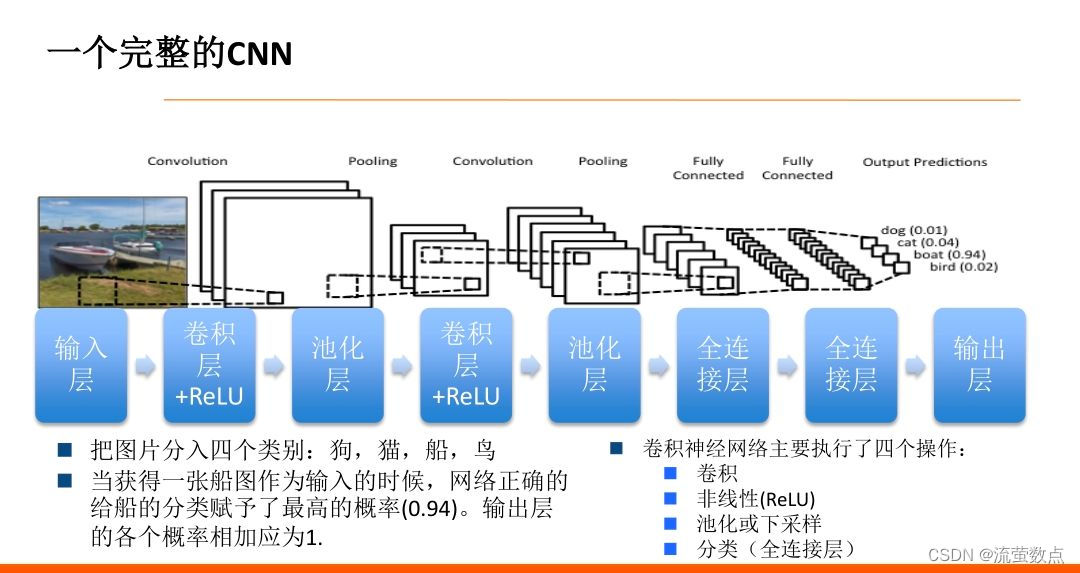
输入层:将数据输入到训练网络。
卷积层:提取图片特征。
池化层:下采样,降低了每个特征映射的维度,但是保留了最重要的信息。最大池化成效最好。
全连接层:卷积层和池化层的输出代表了输入图像的高级特征,全连接层的目的就是类别基于训练集用这些特征进行分类。除了分类以外,加入全连接层也是学习特征之间非线性组合的有效办法。使用softmax激励函数作为输出层的多层感知机。
卷积+池化=特征提取器
全连接层=分类器
输出层:输出结果b
2.本次模型是CNN——LeNet-5模型

步幅(stride):每次滑过的像素数。步幅越大,特征映射越小。
输出数量为10:恰好针对了10个数字的概率。10个节点,分别代表数字0-9,第i的节点的数值越接近0,代表与数字i越相似。
2.数据集是MNIST手写数据集,60000张训练集,10000张测试集,图片大小28*28。
二、实验过程
1.导入库和数据集,我用的是CPU
- import tensorflow as tf
- from tensorflow.keras import datasets, layers, models
- import matplotlib.pyplot as plt
- #这句下载数据集
- (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()

2.归一化
把数变为(0,1)之间的小数,使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确;加快学习算法的收敛速度。
- # 将像素的值标准化至0到1的区间内。
- train_images, test_images = train_images / 255.0, test_images / 255.0
- train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
- """
- 输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
- """

3.可视化
- plt.figure(figsize=(20,10))
- for i in range(20):
- plt.subplot(5,10,i+1)
- plt.xticks([])
- plt.yticks([])
- plt.grid(False)
- plt.imshow(train_images[i], cmap=plt.cm.binary)
- plt.xlabel(train_labels[i])
- plt.show()

4.调整图片格式
- #调整数据到我们需要的格式
- train_images = train_images.reshape((60000, 28, 28, 1))
- test_images = test_images.reshape((10000, 28, 28, 1))
- train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
- """
- 输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
- """

5.构建模型
- model = models.Sequential([
- layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),#卷积层1,卷积核3*3
- layers.MaxPooling2D((2, 2)), #池化层1,2*2采样
- layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3
- layers.MaxPooling2D((2, 2)), #池化层2,2*2采样
- layers.Flatten(), #Flatten层,连接卷积层与全连接层
- layers.Dense(64, activation='relu'), #全连接层,特征进一步提取
- layers.Dense(10) #输出层,输出预期结果
- ])
- # 打印网络结构
- model.summary()

6.编译模型
- """
- 这里设置优化器、损失函数以及metrics
- 这三者具体介绍可参考我的博客:
- https://blog.csdn.net/qq_38251616/category_10258234.html
- """
- model.compile(optimizer='adam',
- loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
- metrics=['accuracy'])
7.训练模型,CPU训练确实有点慢
- """
- 这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
- 关于model.fit()函数的具体介绍可参考我的博客:
- https://blog.csdn.net/qq_38251616/category_10258234.html
- """
- history = model.fit(train_images, train_labels, epochs=10,
- validation_data=(test_images, test_labels))

8.输出结果
plt.imshow(test_images[1])
9.输出测试集中第一张图片的预测结果
- pre = model.predict(test_images) # 对所有测试图片进行预测
- pre[1] # 输出第一张图片的预测结果

三、总结
训练过程比较慢,刚开始训练到第9代自己就停了,只好重新训练。
-
相关阅读:
Tomcat配置文件
C语言:文件操作
嵌入式开发环境Vscode开发STM32单片机程序
拓端tecdat|R语言高级图像处理
IDA Pro与x64dbg联动调试记录
loadrunner lr解决参数化一次取多条记录【一对多问题】
C++11delete与default
【CTFHUB】SSRF原理之简单运用(一)
抽象类和接口
lv5 嵌入式开发-5 线程的创建和参数传递
- 原文地址:https://blog.csdn.net/liuyingshudian/article/details/126117123

