-
21天学习挑战赛——Python正则表达式
⭐应该是凌晨之前发的这篇文章,一直写到现在,挤时间真的看不完 无 羡ღ 大佬的文章,看了还得多抽时间看,算是对正则表达式有了更深的理解。希望我的注解部分能帮助一部分人,看得容易些。还差13篇文章,干就完了!🌈
活动地址:CSDN21天学习挑战赛
目录
2.7.3(?:pattern) 和(?=pattern)的区别
1.正则表达式概述
正则表达式是一个强大的字符串处理工具,几乎所有的字符串都可以通过正则表达式来完成,其本质是一个特殊的字符序列,可以方便地检查一个字符是否与我们定义的字符序列的某种模式相匹配。
在Python的 爬虫爬取数据、数据开发、文本检索和数据筛选时会经常用到正则表达式来筛选字符串,正则表达式内嵌在Python中,并通过 re 模块实现。
2.re模块
2.1 re.match
re.match 尝试从字符串地起始位置匹配正则表达式,如果起始位置匹配不成功,则返回None,匹配成功则返回匹配的子符串。
函数语法:re.match(pattern, string, flags=0)
参数说明:
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等。
用法举例:匹配字符串以itcast开头的语句
- import re #导入re模块
- req = re.match('itcast','itcast.com')
- print(req.group()) #输出:itcast
分析:由于 match 方法是匹配字符串开头,如果开头不满足则返回None,如果满足则返回匹配到的子字符串 itcast。
对flag位进行补充一下,这里补充的部分对match和后面方法的可选标志位都是适用的:
修饰符 描述 re.I 是匹配对大小写不敏感 re.L 做本地化识别(locate-aware)匹配 re.M 多行匹配,影响 ^ 和 $ re.S 使 . 匹配包括换行符(\n)在内的所有字符 re.U 根据Unicode字符集解析字符,这个标志影响\w 、\W 、\b 、\B re.X 该标志通过给予你灵活的格式以便你将正则表达式写得更易于理解 2.2匹配单个字符
单字符匹配常用字符 字符 功能 . 匹配任意1个字符(除了换行符\n) [ ] 匹配[ ]中列举得字符 \d 匹配数字,即0-9 \D 匹配非数字,即不是数字的字符 \s 匹配空白,即空格、tab键 \S 匹配非空白 \w 匹配单词字符,即a-z、A-Z、0-9、_(下划线) \W 匹配非单词字符 2.2.1 “.”用法举例
- import re #导入re模块
- req = re.match('.','M')
- print(req.group()) #输出:M
- req = re.match('t.o','too')
- print(req.group()) #输出:too
- req = re.match('t.o','two')
- print(req.group()) #输出:two
分析:由于“.”可以匹配到任意字符,所以在匹配时只要是字符都可以匹配到。
2.2.2“[ ]”用法举例
- import re #导入re模块
- req = re.match('[hH]','hello word')
- print(req.group()) #输出:h
- req = re.match('[hH]','Hello word')
- print(req.group()) #输出:H
- req = re.match('[1-35-7]Hello word','7Hello word')
- print(req.group()) #输出:7Hello word
分析:“[ ]”使用 match 方法匹配字符串,字符串开头满足“[ ]”中存在的一个字符即可匹配搭配到。在匹配数字时,可以在“[ ]”中写入0123匹配0-3中的一个数,也可以直接写入0-3;写[0-35-7]实际上是数字0-7不包括4。
2.2.3“\d”用法举例
- import re #导入re模块
- req = re.match('嫦娥1号','嫦娥1号发射成功')
- print(req.group()) #输出:嫦娥1号
- req = re.match('嫦娥\d号','嫦娥2号发射成功')
- print(req.group()) #输出:嫦娥2号
分析: “\d” 可以匹配数字0-9,即使在字符串中对应位置数字不确定,填入\d即可匹配出其中的数字。
2.3匹配多个字符
匹配多字符常用字符 字符 功能 * 匹配前一个字符出现0次或无限次,即可有可无 + 匹配前一个字符出现1次或无限次,即至少有一次 ? 匹配前一个字符出现1次或0次,即要么有1次,要么没有(必须满足或者此位没有字符,不满足会报错) {m} 匹配前一个字符出现m次 {m,n} 匹配前一个字符出现m-n次,至少m次。 2.3.1“*” 用法举例
匹配字符串中第一个为大写字母,第二个是小写字母,小写字母可以没有。
- #导入re模块
- import re
- #使用match方法进行匹配操作
- result = re.match('[A-Z][a-z]*','Ab')
- #打印匹配到的字符串
- print(result.group())
分析: 如果将上面代码的 * 删除,则匹配的是一个大写字母和一个小写字母,如果不存在大小字母挨着,并且顺序是先大后小,将报以下错误:
AttributeError: 'NoneType' object has no attribute 'group'2.3.2 “+” 用法举例:
匹配变量是否符合 ”存在一个或无限个 “a-z、A-Z、_" 加上满足一个单字符(a-z、A-Z、0-9)其中一个,并且单字符可有可无。
- #导入re模块
- import re
- #设置测试表量数组
- names = ["name1", "_name", "2_name", "__name__"]
- #遍历数组,并打印是否符合要求
- for name in names:
- ret = re.match("[a-zA-Z_]+[\w]*",name)
- if ret:
- print("变量名 %s 符合要求" % ret.group())
- else:
- print("变量名 %s 非法" % name)
- #输出:变量名 name1 符合要求
- # 变量名 _name 符合要求
- # 变量名 2_name 非法
- # 变量名 __name__11 符合要求
分析:我们来分析一下,为什么符合和不符合。第一个字符串 name1 满足大小写字符和下划线任意组合n个加上可有可无的大小写字母、数字、下划线的任意组合n个,这里说的”加上“并不是代码里的"+" 代码里的“+”是指”+“前面字符出现1次或无限次,至少有1次都可以。第三个字符串 2_name 因为不符合匹配要求,应该先出现大小写字母和下划线至少1次的组合,后出现大小写字母、下划线、数组有没有都可以的情况。其余同理。
2.3.3“?” 用法举例
匹配出 0到99之间 的数字
- import re #导入re模块
- req = re.match('[1-9]?[0-9]','7') #使用match方法匹配字符
- print(req.group()) #输出:7
- req = re.match('[1-9]?\d','66') #使用match方法匹配字符
- print(req.group()) #输出:66
- req = re.match('[1-9]?\d','09') #使用match方法匹配字符
- print(req.group()) #输出:0
分析:因为数字7只有1位,而 ? 前面的字符要么出现1次,要么出现0次,按道理来说,如果符合了前面的条件,后面匹配的数字就匹配不到了,会报错,然后并没有,如果将 ? 删除,则会报错。匹配66同理。匹配09时,因为0不符合[1-9],而 ? 前面的字符要么出现1次,要么出现0次,0就再和 \d 匹配,符合范围,只匹配到0,这并不是想要的结果。如果有大佬可以解决欢迎评论区见!👏
2.3.4 {m} 及 {m,n} 用法举例
匹配出8-20位的密码,可以实大小写英文字母、数字、下划线。
- import re #导入re模块
- req = re.match('[a-zA-Z0-9_]{6}','12a3g456789') #使用match方法匹配字符
- print(req.group()) #打印结果
- #输出:12a3g4
- req = re.match('[a-zA-Z0-9_]{8,20}','1ad12f23s34455ff66') #使用match方法匹配字符
- print(req.group()) #打印结果
- #输出:1ad12f23s34455ff66
分析:第一段代码匹配满足大小写字母、数字及下划线的前6个,需要挨着的;第二段代码,匹配前8-20个满足要求的字符,可以少于20,但必须大于等于8个才行。
2.4匹配开头和结尾
开头和结尾字符 字符 功能 ^ 匹配字符串开头 $ 匹配字符串结尾 2.4.1 “^” 用法举例
匹配135开头的电话号码。
- import re #导入re模块
- req = re.match('^135[0-9]{8}','13566666666') #使用match方法匹配字符
- print(req.group()) #输出:13566666666
- req = re.match('^135[0-9]{8}','17866666666') #使用match方法匹配字符
- print(req.group()) #报错:AttributeError: 'NoneType' object has no attribute 'group'
分析:第二段代码报错的原因是字符串开头不是135,必须是开头匹配,在字符串里面存在135也会报错。
2.4.2 “$” 用法举例
匹配出163的邮箱地址,且@符号之间有4-20位,例如:helloword@163.com
- import re #导入re模块
- email_list = ['Laowang@163.com','Laowang@163.comheihei','.com.Laowang@qq.com']
- for email in email_list:
- req = re.match('[\w]{4,20}@163\.com', email)
- if req:
- print('%s 符合规定的邮箱地址,匹配后的结果是:%s'%(email,req.group()))
- else:
- print('%s 不符合要求'%email)
- #输出:Laowang@163.com 符合规定的邮箱地址,匹配后的结果是:Laowang@163.com
- # Laowang@163.comheihei 符合规定的邮箱地址,匹配后的结果是:Laowang@163.com
- # .com.Laowang@qq.com 不符合要求
分析:在匹配中在 “.” 前面加反斜杠\,在这里是转义字符,这里应该匹配点,而不是前面学的匹配任意除换行符"\n"外的任何单个字符。
2.5匹配分组
匹配分组常用字符 字符 功能 A|B A和B是任意正则表达式,一旦A匹配成功,B就不再进行匹配,即使它能产生更好的匹配 (ab) 将括号中字符作为一个分组 \num 引用分组num匹配到的字符串 (?P ) 分组起别名(注意:P要大写) (?P=name) 引用别名为name分组匹配的的字符串(注意:P要大写) 2.5.1 “|” 用法举例
匹配出0-100之间的数字。
- import re #导入re模块
- req = re.match('[1-9]?\d$|100','78')
- print(req.group())#输出:78
- req = re.match('[1-9]?\d$|100','100')
- print(req.group())#输出:100
分析:第一段代码由于前面条件满足,[1-9]可有可无,\d 是匹配数字0-9加上 $ 匹配末尾满足条件的,先匹配数字8,前面由于存在字符7并且在[1-9]内,所以满足匹配条件;第二段代码,由于第2个0,满足 \d 而前面存在字符0,不满足,去匹配100成功,则匹配到100。
2.5.2“()” 用法举例
匹配出163、126、qq邮箱。
- import re #导入re模块
- email_list = ['Laowang@163.com','Laowang@126.com','Laowang@qq.com','Laowang@eamil.com']
- for email in email_list:
- req = re.match('\w{4,20}@(163|126|qq)\.com',email)
- if req:
- print(req.group())
- else:
- print('%s 不属于163、126、qq邮箱中的一个'%email)
- # 输出:Laowang@163.com
- # Laowang@126.com
- # Laowang@qq.com
- # Laowang@eamil.com 不属于163、126、qq邮箱中的一个
- ret = re.match("([^-]*)-(\d+)","010-12345678")
- print(ret.group())#输出:010-12345678
- print(ret.group(1))#输出:010
- print(ret.group(2))#输出:12345678
分析:第一段代码就是在 () 中增加了或的关系,满足其中一个即可;第二段代码,使用 () 将匹配的结果分为了两部分,[^-]* 是匹配 “-”之前的所有字符,即使加上“隔壁老王”,也会被匹配到group(1),\d+ 是匹配一个至无限个数字,至少有一次存在。
2.5.3“\” 用法举例
匹配出类似 hh 左右两“<>”内字符相同的字符串
- import re #导入re模块
- test_list = ['LaoWang','LaoWang']
- for test in test_list:
- req = re.match(r'<([a-zA-Z]*)>\w*',test)
- if req :
- print(req.group())
- else:
- print('%s 格式不符合'%test)
- # 输出:LaoWang
- # LaoWang 格式不符合
分析:由于题目要求,左右相同,在匹配完第一个“<>”内容后,即可直接对比“()”中得到的字符串,对比用到了 "\1"意思是对比第一个得到的“()”的字符串。加上转义字符 r 是为了保持原字符串中的“\”的含义,如果不加 r 也可以双反斜杠“\\”代表一个反斜杠“\”。
2.5.4(?P
)和(?P=name)用法举例 - import re #导入re模块
- test_list = ['
www.GebiLaoWang.cn
','www.GebiLaoWang.cn'
] - for test in test_list:
- req = re.match('<(?P
\w*)><(?P ,test)\w*)>.*' - if req :
- print('%s 格式符合'%req.group())
- else:
- print('%s 格式不符合'%test)
- # 输出:
www.GebiLaoWang.cn
格式符合 - #
www.GebiLaoWang.cn 格式不符合
分析:上面代码中是为了筛查左右“<>”中对称的字符串。而 (?P
2.6高级用法
2.6.1 re.search
re.search 扫描整个字符串并返回匹配成功的第一段字符串;匹配成功 re.search 方法返回匹配成功的结果,否则返回None。
函数用法: re.search(pattern, string, flag=0)
参数说明:
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、多行匹配等。
用法举例:
- import re #导入re模块
- line = 'Laowang is a man!'
- searchObj = re.search('(.*) is (.*?) .*',line,re.M|re.I)
- if searchObj:
- print('searchObj.group():',searchObj.group())
- print('searchObj.group(1):',searchObj.group(1))
- print('searchObj.group(2):',searchObj.group(2))
- else:
- print('Nothing found!')
- #输出:searchObj.group(): Laowang is a man!
- # searchObj.group(1): Laowang
- # searchObj.group(2): a
分析:标志位上用到了修饰符可选标志位 re.I 使匹配对大小写不敏感,re.M 使多行匹配,会影响 ^ 和 $ 。
re.match 与 re.search 的区别:re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,即使字符串中存在满足正则表达式的一部分,也会匹配失败,函数返回None,而 re.search匹配整个字符串,直至找到一个能匹配正则表达式的。下面是解释这段话的示例代码:
- import re #导入re模块
- line = 'Laowang is a man!'
- matchObj = re.match('man',line,re.M|re.I)
- if matchObj:
- print('match --> matchObj.group():',matchObj.group())
- else:
- print('No match!')
- #输出:No match!
- searchBoj = re.search('man',line,re.M|re.I)
- if searchBoj:
- print('search --> searchObj.group():',searchBoj.group())
- else:
- print('No search!')
- #输出:search --> searchObj.group(): man
2.6.2 re.findall
re.findall 在字符串中找到正则表达式所匹配的所有子串,并以一个列表的形式返回,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意:match、search 是顶多找到一个子串就返回,而 findall 看名字就知道找到所有的。
函数语法:re.findall(pattern, string, flags=0)
参数说明:
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、多行匹配等。
用法举例:1.统计出python、c、c++的文章浏览次数 ;2.找出"="两侧对应关系。
- import re #导入re模块
- req = re.findall('\d+','python = 9999, c = 6666, c++ = 12345')
- print(req)
- #输出:['9999', '6666', '12345']
- req = re.findall(r'(\w+)=(\d+)', 'set weight=65 and height=170')
- print(req)
- #输出:[('weight', '65'), ('height', '170')]
2.6.3 re.sub
re.sub 是将匹配到的数据进行替换。
函数语法:re.sub(pattern, rep1, string, count=0, flags=0)
参数说明:(前三个为必选参数,后两个为可选参数)
- pattern:匹配的正则表达式
- req1:替换的字符串,也可为一个函数
- string:要被查找替换的原始字符串
- count:匹配替换的最大次数。默认为0 ,表示替换所有能匹配到的字串。
- flags:编译时的匹配模式,数字形式。
用法举例: 1.移除解释内容;2.移除非数字内容;3.将字符串中匹配到的数字乘2。
- import re #导入re模块
- date = '2022-08-02 # 这是日期'
- req = re.sub('#.*$','',date) #删除解释内容
- print(req)
- #输出:2022-08-02
- req = re.sub('\D','',date) #移除非数字内容
- print(req)
- #输出:20220802
- def double(matched):
- value = int(matched.group('value'))
- return str(value*2)
- s = 'A23G4HFD567'
- print(re.sub('(?P
\d+)' , double, s)) #repl参数是一个函数 - #输出:A46G8HFD1134
分析:第一段代码匹配的是“#”后的任意一个字符(除了\n)0次或无限次,且全部替换为空字符,即删除;第二段代码将非数字外的全部删除;第三段代码给每一次匹配到的字串起了别名 value,并且将匹配到的结果,传入到 double 函数中,在 double 函数中,找到 value 的值并乘2,变为字符串再返回。
2.6.4 re.split
re.split 是根据匹配进行切割字符串,并返回一个列表。
函数语法:re.split(pattern, string, maxsplit=0, falgs=0)
参数说明:(前两个是必选参数,后两个是可选参数)
- pattern:匹配的正则表达式
- string:要匹配的字符串
- maxsplit:分割次数,maxsplit=1分割一次,默认为0,不限制次数
- flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等。
用法举例:以“:”或者空格切割字符串“info:Laowang 33 shandong”
- import re #导入re模块
- req = re.split(':| ','info:Laowang 33 shandong')
- print(req) #输出:['info', 'Laowang', '33', 'shandong']
- req = re.split('a','HeiHeiHei')
- print(req) #输出:['HeiHeiHei']
分析:第一段代码中使用“:”或"空格分割字符串,返回数组;第二段代码由于字符串中不存在要分割的字符,所以不会对原字符串进行分割。
2.7特殊语法
2.7.1 (?:pattern)
() 表示捕获分组,() 会把每个分组里的值保存起来,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。而 (?:) 表示非捕获分组,和捕获分组唯一的区别是非捕获分组匹配的值不会保存器来。
用法举例:分别使用捕获分组和非捕获分组获取"123abc456"中的数字、字母、数字
- import re #导入re模块
- a = '123abc456'
- req = re.search('([0-9]*)([a-z]*)([0-9]*)',a)
- print(req.group(1)) #输出:123
- print(req.group(2)) #输出:abc
- print(req.group(3)) #输出:456
- req = re.search('(?:[0-9]*)([a-z]*)([0-9]*)',a)
- print(req.group(1)) #输出:abc
- print(req.group(2)) #输出:456
- print(req.group(3)) #报错:IndexError: no such group
分析:第二段代码,由于第一分组使用了非捕获分组,所以第一个值123不会被保存,而其余两个为捕获分组,则 abc 为保存的第一个字串,456 为第二个字串,一共两个。(?:pattern) 匹配正则表达式 pattern 但不获取匹配结果,不进行存储数据供以后使用。
2.7.2 (?=pattern)
正向肯定预查(look ahead positive assert),在任何匹配 pattern 的字符串处开始匹配查找字符串。这是一个非获取匹配,该匹配不存储数据供以后使用。
用法举例:
- import re #导入re模块
- req = re.search('Windows(?=95|98|NT|2000|XP)','WindowsXP')
- print(req.group()) #输出:Windos
- req = re.search('Windows(?=95|98|NT|2000|XP)','Windows11')
- print(req.group()) #报错:AttributeError: 'NoneType' object has no attribute 'group'
分析:'Windows(?=95|98|NT|2000|XP)' 只能匹配 Windows加上 95、98、NT、2000、XP 其中一个的组合。预查并不消耗字符,也就是说,在一个匹配发生后,即匹配到了 WIndows 进行后面的预查,预查包含 95、98、NT、2000、XP 的内容,预查匹配成功后,下一次匹配仍然会在包含 95、98、NT、2000、XP 的内容处进行匹配。
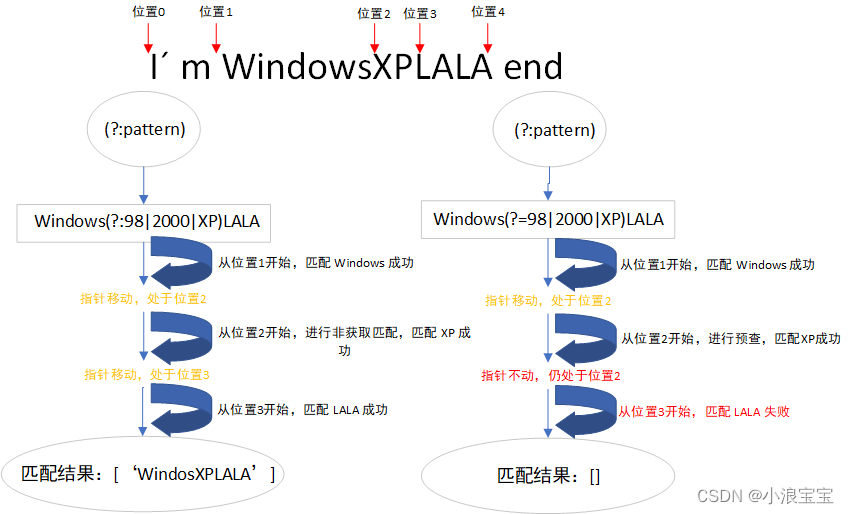
2.7.3(?:pattern) 和(?=pattern)的区别
1.(?:pattern)匹配得到的结果包含pattern,(?=pattern)不包括pattern。
- import re #导入re模块
- req = re.search('industr(?:y|is)','industry is good!')
- print(req.group()) #输出:industry
- req = re.search('industr(?=y|is)','industry is good!')
- print(req.group()) #输出:industr
2.(?:pattern)消耗字符,下一字符匹配会从已匹配的位置开始。(?=pattern)不消耗字符,下一字符匹配从预查之前的位置开始。
2.7.4 (?!pattern)
正向否定预查(negative assert),在任何不匹配 pattern 的字符串处,开始匹配查找字符串。这是一个非获取匹配,该匹配不需要获取供以后使用。
用法举例:
- import re #导入re模块
- req = re.search('Windows(?!95|98|NT|2000|XP)','Windows11')
- print(req.group()) #输出:Windows
- req = re.search('Windows(?!95|98|NT|2000|XP)','WindowsXP')
- print(req.group()) #报错:'NoneType' object has no attribute 'group'
分析:‘Windows(?!95|98|NT|2000|XP)’ 是先匹配 Windows,然后匹配后面的字符串事都不是95、98、NT、2000、XP 中的任意一个,不是则匹配成功,否则匹配失败。并且,预查不消耗字符。
2.8Python 贪婪和非贪婪
正则表达式中使用到通配字,那它从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。
注:在“*”、“?”、“+”、“{m,n}”后面加上 ? ,可以使贪婪变成非贪婪。
用法举例:
- import re #导入re模块
- str = 'www.baidu.com/path'
- req = re.search(r'\w+',str) #'+'贪婪模式,匹配1个或无限个,至少一个
- print(req.group()) #输出:www
- req = re.search(r'\w+?',str) #'+?'非贪婪模式,只匹配1个
- print(req.group()) #输出:w
- req = re.search(r'\w{2,5}',str) #'{2,5}'贪婪模式,最少匹配2个,最大匹配5个
- print(req.group()) #输出:www
- req = re.search(r'\w{2,5}?',str) #'+?'非贪婪模式,只匹配2个
- print(req.group()) #输出:w2
分析:在非贪婪模式中,由于前面的条件是>=m,非贪婪模式下只要满足前面的条件即可,即满足最少的条件,直接取m的值。
2.9转义字符 r 的使用
与大多数编程语言相同,正则表达式里使用 “\” 作为转义字符,这就可能造成使用反斜杠的困扰。假如需要匹配文本中的 “\\” ,那么使用编程语言表示的正则表达式里需要4个反斜杠“\\\\”:前一个反斜杠用于在编程语言里转义后面的反斜杠为反斜杠。转义少了还好说,要是很多个那就很麻烦了。 Python的原生字符串 “r” 可以很好地解决整个问题。
- import re #导入re模块
- test = 'c:\\a\\b\\c'
- print(test) #输出:c:\a\b\c
- print(r'c:\\a\\b\\c') #输出c:\\a\\b\\c
- req = re.match('c:\\\\',test)
- print(req.group()) #输出c:\
- req = re.match(r'c:\\',test)
- print(req.group()) #输出c:\
分析:在字符串中,如果不在前面加转义字符 “r”,则在字符串中两个反斜杠代表一个反斜杠。实实际上第二段代码在匹配时都是匹配到了 'c:\\',而在输出时认为第一个反斜杠是转义字符,不输出。
-
相关阅读:
叠氮N3修饰Ag2S量子点|巯基SH偶联Ag2Se量子点|生物素Biotin改性Ag2Te量子点
使用微信公众号搭建免费查券返利机器人详细教程
[附源码]Python计算机毕业设计SSM酒店客户管理系统(程序+LW)
Nginx错误日志说明
含电热联合系统的微电网运行优化附Matlab代码
微信自动通过好友请求是怎么设置的?
静态链接与动态链接
html、css
docker容器数据卷
免费 AI 代码生成器 Amazon CodeWhisperer 初体验
- 原文地址:https://blog.csdn.net/m0_52162042/article/details/126114897
