-
hdfs 副本放置策略及快照功能简介
一. hdfs默认每个数据块都对应有三个副本,出于安全性和数据本地性等方面的考虑,hdfs对于副本放置的位置是有策略实现的,首先基于要求写数据块的请求方的位置归为两大类:
假设有如下的网络拓扑:
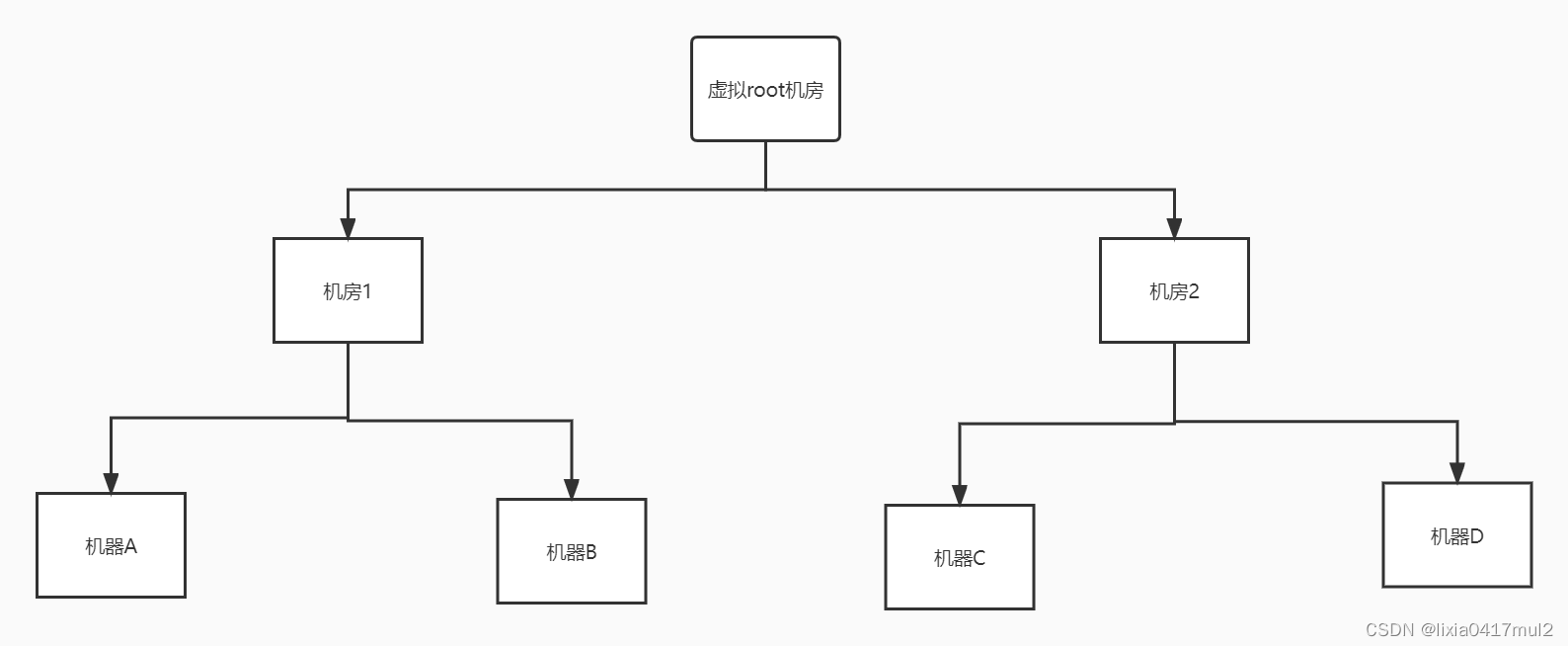
1.1 请求方来源于外部的客户端
a. 第一个副本的选择就可以随机一台机器,比如机器A
b. 第二个副本的选择就是选择和机器A属于同一个机房的机器上了,比如机器B
c.第三个副本的选择为了数据备份期间会选择另一个机房2下的机器,比如机器C1.2 请求方来源于内部的DataNode机器,比如机器C
a.第一个副本的选择要选择和机器C相同的机器上,也就是本地机器C放置一份数据
b.第二个副本的选择就是选择和机器C属于同一个机房的机器上了,比如机器D
c.第三个副本的选择为了数据备份期间会选择另一个机房1下的机器,比如机器A以上在寻找离当前机器最近的其他机器时,有一个距离的概念,距离的相关算法是最近公共祖先算法.
通过如下命令可以查看一个文件的数据块的详细位置信息:
hdfs fsck /tmp/1.txt -files -blocks -locations二:hdfs的快照功能
2.1 创建快照的命令:hadoop fs -createsnapshot path snapshotname
2.2 比较两个快照的命令: hdfs snapshopdiff 快照1 快照2
2.3 快照的实现原理是存放对应目录的一个快照,他只会保存和当前目录文件中有变化的数据,没有变化的数据他是不记录的,实现原理类似于创建子进程时对内存的写拷贝操作,只有和当前目录中有变化的文件才需要记录起来
2.4 快照的用途:其一是可以恢复丢失的数据,也就是把这个目录下的数据恢复到快照时间点的数据
2.5 快照的用途: 其二利用快照的diff功能,结合DistCp命令可以实现集群数据间的同步 -
相关阅读:
第4章_freeRTOS入门与工程实践之开发板使用
Xiaojie雷达之路---匹配滤波器
网络安全设备之防火墙技术详解
设计模式之代理模式的懂静态代理和动态代理
springboot毕设项目超市仓库管理系统15g4i(java+VUE+Mybatis+Maven+Mysql)
学习分享:如何进行全局变量的学习
SignalR WebSocket通讯机制
Docker 工作原理分析
Pytest模式执行python脚本不生成allure测试报告
【测试面经】软件测试面试题大全,软件测试必问必背面试题,敢说会70%就可以轻松拿offer......
- 原文地址:https://blog.csdn.net/lixia0417mul2/article/details/126132750