-
计算机网络 | 06.[HTTP篇] HTTP/1.1如何优化
总述
总则来说,优化思路有以下三个:
- 尽可能使用缓存;
- 减少HTTP请求次数;
- 减少HTTP响应的数据大小。
但不管怎么优化 HTTP/1.1 协议都是有限的,不然也不会出现 HTTP/2 和 HTTP/3 协议。
1. 尽可能使用缓存
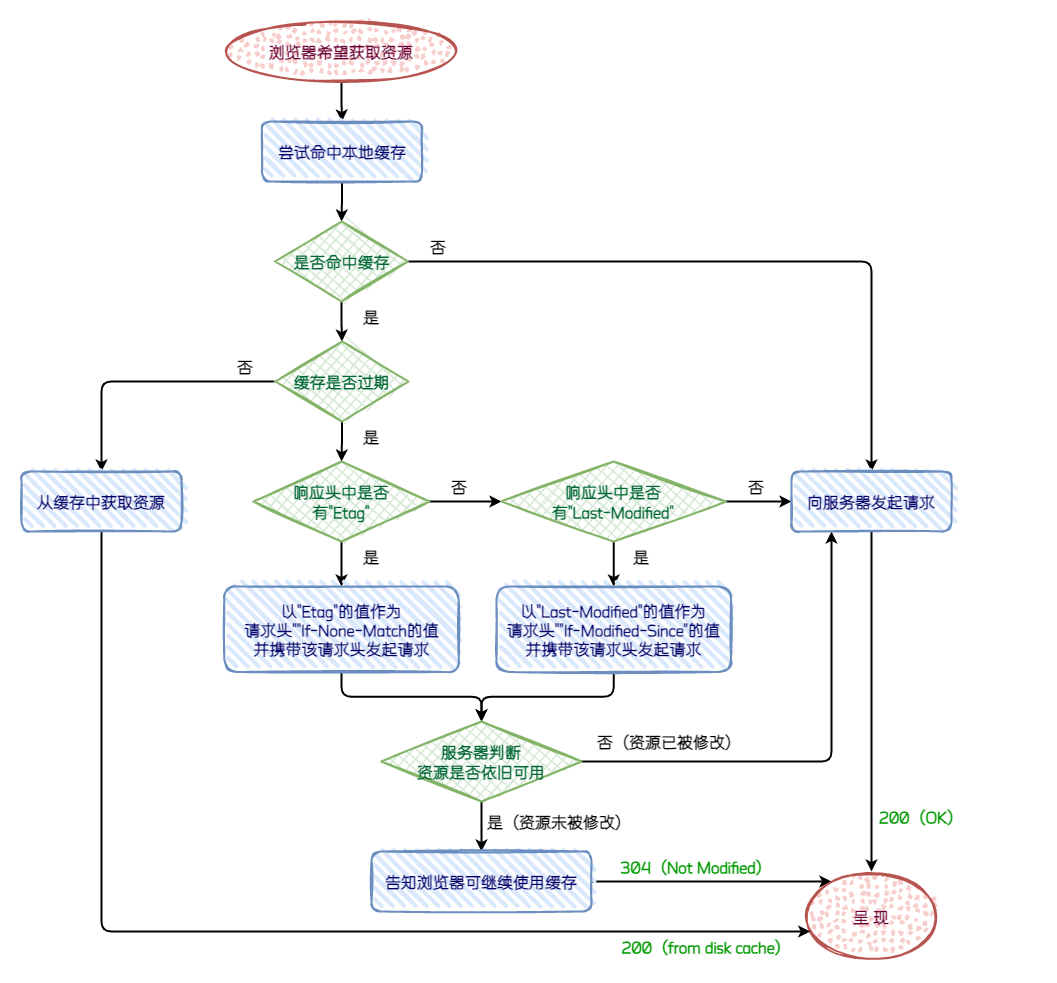
对于一些具有重复性的 HTTP 请求,比如每次请求得到的数据都一样的,我们可以把这对「请求-响应」的数据都 缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应了,这样的话 HTTP/1.1 的性能肯定肉眼可见的提升。
所以,避免发送 HTTP 请求的方法就是通过 缓存技术,HTTP 设计者早在之前就考虑到了这点,因此 HTTP 协议的头部有不少是针对缓存的字段。
缓存策略分为 强缓存策略 和 协商缓存策略,其中「协商缓存」更为常用;
协商缓存可以通过两对 请求头 / 响应头 来协同完成,分别是 If-Modified-Since / Last-Modified 和 If-None-Match / Etag,其中「If-None-Match / Etag」更为常用,其中 Etag 是响应头,其值能唯一标识某个资源。
涉及的状态码有:
- 200(OK):客户端未使用缓存,而是向服务器请求资源(发起一次请求);
- 200(from disk cache):客户端使用了本地磁盘的资源,没有发起请求;
- 304(Not Modified):客户端发起请求询问资源是否可用,服务端告知资源未被修改,依旧可用,此时 响应中无数据。
详细可见文章03.[HTTP篇] HTTP缓存技术。
2. 减少HTTP请求次数
2.1. 减少重定向次数
重定向请求是指服务器 某个资源的url 发生了变更,若客户端依旧尝试通过 旧的url 访问该资源,那服务器应该通过 「302」状态码和「Location响应头(值为新的url)」响应客户端,让客户端 使用新的url重新发送请求,浏览器会自动完成。
换言之,每个重定向请求,都会使得总请求次数+1,因此要尽可能地减少重定向次数。
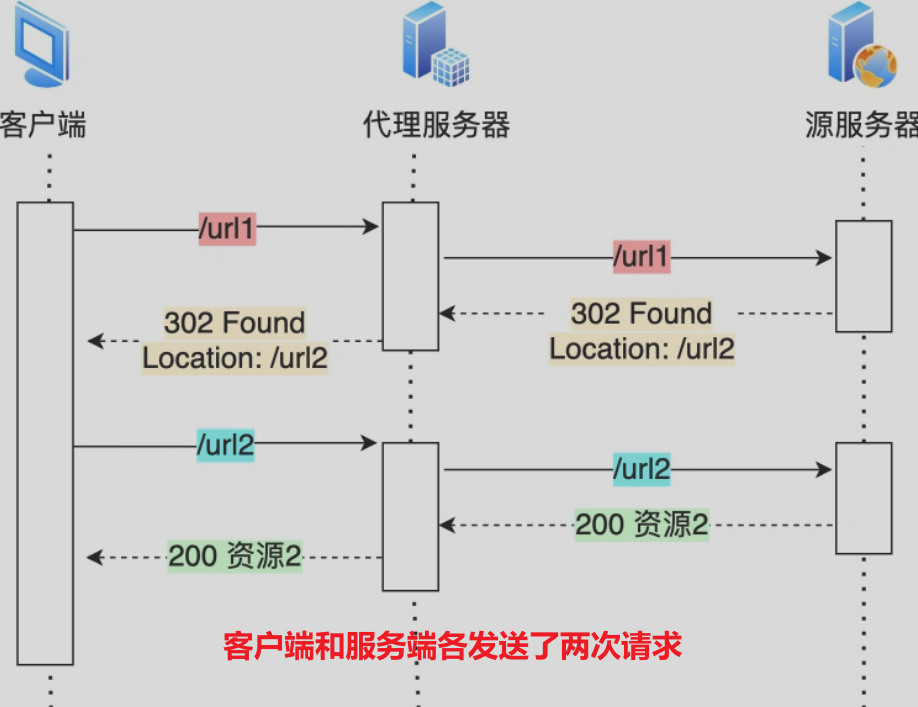
如果中间存在代理服务器,那么代理服务器可以进行优化以减少重定向的次数:
-
[最慢的情况]:一次重定向使得客户端和代理服务器 都发送了两次请求。
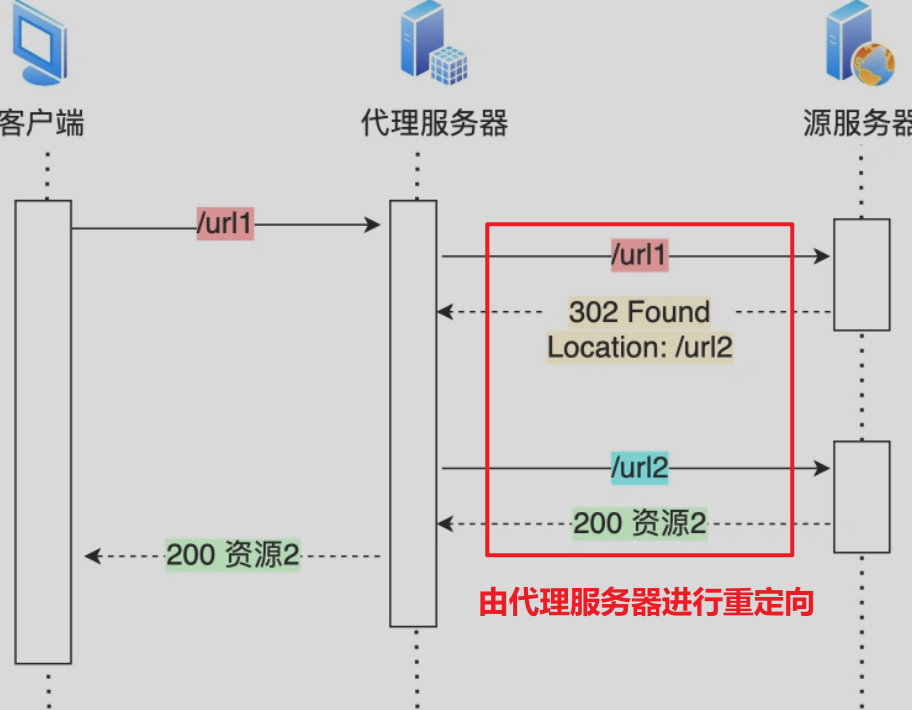
-
[优化1] 将重定向交由代理服务进行,减少客户端一次请求。
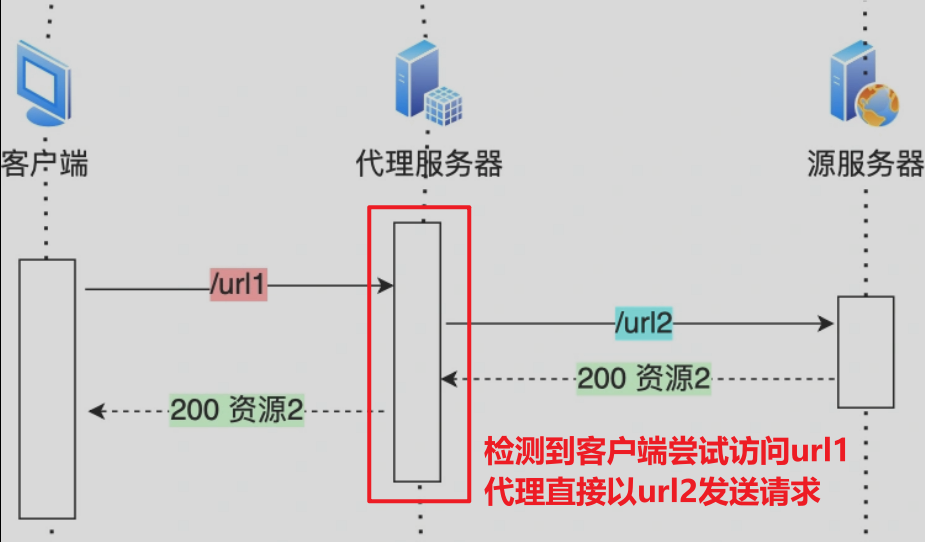
-
[优化2] 若代理服务器知晓重定向规则,当客户端尝试访问url1,代理直接以url2发送请求,再减少一次代理服务器请求。
2.2. 合并资源(合并图片、打包)
如果把多个访问小文件的请求合并成一个大的请求,虽然传输的总资源还是一样,但是减少请求,也就意味着 减少了重复发送的 HTTP 头部。
另外由于 HTTP/1.1 是请求响应模型,如果第一个发送的请求,未收到对应的响应,那么后续的请求就不会发送,于是为了防止单个请求的阻塞,所以一般浏览器会同时发起 5-6 个请求,每一个请求都是不同的 TCP 连接,那么如果合并了请求,也就会 减少 TCP 连接的数量,因而省去了 TCP 握手和慢启动过程耗费的时间。
合并资源,让客户端使用「一个大资源的请求」去替代「多个小资源的请求」,从而减少请求次数。至于资源的切割或解压,这些影响并不大。
但是这么做也存在弊端:当大资源中的某一个小资源发生变化,客户端就需要重新下载完整的大资源文件,这「带来了额外的网络消耗」。

2.3. 资源按需获取
当用户滑动到页面的时候,再加载其附近的数据,实现资源的「按需获取」。
3.减少HTTP响应的数据大小
对响应的资源进行「压缩」:
- [无损压缩] 常用于各种文本,常用的压缩方式是gzip(本质上是使用相似的字符进行替换);
- [有损压缩] 常用于各种多媒体数据,如图片、音频和视频。
参考文章
-
相关阅读:
边端小场景音视频流分发架构
数据挖掘实战(4)——聚类(Kmeans、MiniBatchKmeans、DBSCAN、AgglomerativeClustering、MeanShift)
vue 登陆页面
合成事件在san.js中的应用
Mybatis-plus进阶篇(二)
Elasticsearch:基于 Langchain 的 Elasticsearch Agent 对文档的搜索
常见6种易被忽略的软件隐藏缺陷
C语言程序设计入门学习六步曲,六步带你入门C语言
【1】初识Java
乐趣国学—品读《弟子规》中的“泛爱众”之道(上篇)
- 原文地址:https://blog.csdn.net/xyxyxyxyxyxyx/article/details/126132914