-
Zookeeper入门
目录
基本概念
zookeeper翻译过来是动物园管理员,来管理Hadoop(大象),Hive(蜜蜂)等等。
zookeeper是一个分布式的分布式应用程序协调服务,提供的功能有配置管理,分布式锁,集群管理。
配置管理
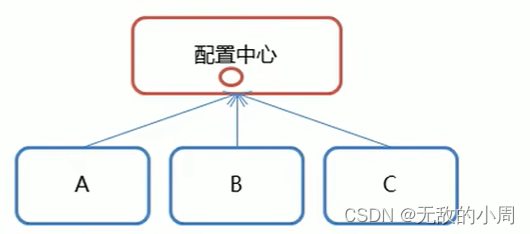
提供一个配置中心,管理A,B,C等各个服务的配置文件
分布式锁
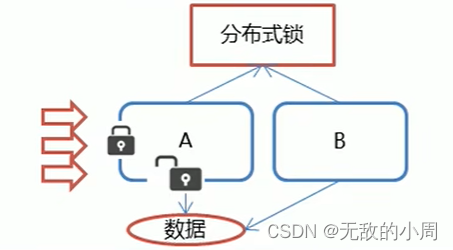
当用户A,B访问数据时,zookeeper会提供分布式锁来保证数据安全。
注册中心
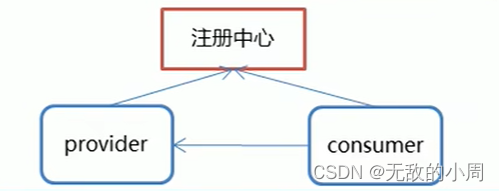
提供方先将自己的地址给注册中心,consumer要是想访问provider的话,就去注册中心找地址。
zookeeper的安装
- Step1:将zookeeper压缩包上传到虚拟机中
- Step2:解压 tar -zxvf 路径名
- Step3:将confg目录下的zoo_sample.cfg复制一份,名字为zoo.cfg,更改zoo.cfg中的dataDir,该路径可以由自己创建,用来存储数据。
- Step4:启动zookeeper,到bin目录下,输入./skServer.sh start,查看状态./zkServer.sh status
zookeeper数据模型
数据模型说明
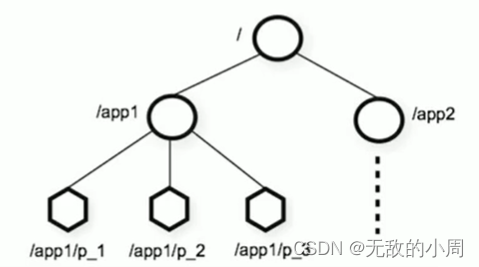
- zookeeper是一个树形目录服务,数据模型和Linux的文件系统模型类似,是一个层次化结构
- 这里面每个节点称为ZNode,每个节点上都会保存自己的数据和节点信息
- 节点可以有子节点,也允许有少量数据(1MB)存储在该节点之下
节点分类
- persistent 持久化节点
- ephemeral 临时节点 -e
- persistent_sequential 持久化顺序节点 -s
- ephemeral_sequential 临时顺序节点 -es
持久化节点:节点创建好后,即使zookeeper客户端断开连接,服务端也关了,再次打开节点也还存在
临时节点:当前与客户端连接的会话断开后,临时节点就消失了
zookeeper的命令操作
zookeeper服务端常用命令
- 要在bin目录下执行
- ./zkServer.sh start 启动zookeeper服务
- ./zkServer.sh status 查看zookeeper服务状态
- ./zkServer.sh stop 停止zookeeper服务
- ./zkServer.sh restart 重启zookeeper服务
zookeeper客户端常用命令
- ./zkCli.sh -server node1:2181 打开zookeeper客户端
- quit 关闭客户端
- ls / 查看根目录下的节点
- ls /zookeeper 查看zookeeper下的节点
- ls -s 查看节点详细信息
- create /app1 创建(持久)节点
- create /app2 abcde 创建节点并且包含数据
- get /zookeeper 获取节点数据
- set /app2 abc 设置节点数据
- delete /app1 删除节点
- deleteall /app1 删除该节点及该节点的内容
- help 查看命令介绍
- create -e /app1 创建临时节点
- create -s /app1 创建持久化顺序节点
- create -es /app1 创建临时顺序节点
zookeeper JavaAPI操作
Curator:是zookeeper的Java客户端,与上面的客户端功能相同,只是操作的形式不同。
创建连接
- @Test
- public void testConnect(){
- /*
- * param1:connectString 连接字符串 zkServer的地址和端口 192.168.88.151:2181
- * param1也可以写多个地址和端口,集群的形式,之间用逗号隔开
- * param2:sessionTimeoutMs 会话超时时间,当前连接多长时间没有通信而超时的时间
- * param3:connectionTimeoutMs 连接超时时间:多长时间内未连接成功
- * param4:retryPolicy 重试策略,连接失败后重新连接的策略
- * */
- 方式1
- RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,10);//每次休眠的时间和最多重试的次数
- CuratorFramework client = CuratorFrameworkFactory.newClient("192.168.88.151:2181",
- 60 * 1000, 15 * 1000, retryPolicy);
- client.start(); //开启连接
- //方式2:链式编程
- CuratorFramework client2 = CuratorFrameworkFactory.builder()
- .connectString("192.168.88.151:2181")
- .sessionTimeoutMs(60 * 1000)
- .connectionTimeoutMs(10 * 1000)
- .retryPolicy(retryPolicy)
- .namespace("myData")//每次操作是路径前面都自动加上/myData
- .build();
- client2.start();
- }
重试策略的不同的实现类

关闭连接
- public void close(){
- if(client2 != null)
- client2.close();
- }
两个注解
- @BeforeEach //每次执行都在Test之后,比如连接zookeeper服务的操作
- public void testConnect(){}
- @Test
- public void test{}
- @AfterEach //每次执行都在Test之后执行,用来释放资源
- public void close(){}
创建节点
- //1.创建持久化节点
- @Test
- public void testCreate() throws Exception {
- String path = client2.create().forPath("/app2");//会默认在/app1前面加名称空间
- System.out.println(path);
- }
- //2.创建持久化节点并带有数据
- @Test
- public void testCreate2() throws Exception {
- String path = client2
- .create()
- .withMode(CreateMode.EPHEMERAL)
- .forPath("/app5","haha".getBytes());
- System.out.println(path);
- }
- //3.创建临时节点
- @Test
- public void testCreate2() throws Exception {
- System.out.println(client2);
- String path = client2
- .create()
- .withMode(CreateMode.EPHEMERAL)
- .forPath("/app5");
- System.out.println(path);
- }
- //4.创建多级节点
- @Test
- public void testCreate3() throws Exception {
- System.out.println(client2);
- String path = client2.create()
- .creatingParentsIfNeeded()//如果父节点不存在,则创建父节点
- .withMode(CreateMode.EPHEMERAL)
- .forPath("/app5/a");
- System.out.println(path);
- }
查询节点
- //1.查询数据
- @Test
- public void testGet1() throws Exception {
- byte[] data = client2.getData().forPath("/app1");
- System.out.println(new String(data));
- }
- //2.查询子节点
- @Test
- public void testGet2() throws Exception {
- List
path = client2.getChildren().forPath("/"); //[app2, app1, app4, app3] - System.out.println(path);
- }
- //3.查询状态信息
- @Test
- public void testGet3() throws Exception {
- Stat status = new Stat();
- System.out.println(status);
- client2.getData().storingStatIn(status).forPath("/app1");
- System.out.println(status);
- }
修改节点
- //1.修改数据
- @Test
- public void testSet() throws Exception {
- client2.setData().forPath("/app1","ccc".getBytes());
- }
- //2.根据版本修改,相当于锁一样,让各个客户端之间不干扰
- //每个节点都有一个版本号,每次被修改时,版本号都会变
- //修改时先查询版本号,比如查到了3,在修改数据时,携带该将版本号再去跟节点号进行验证
- //如果发现不一致,说明在你进行本次操作前,数据已经被别人修改了,所以版本号不同
- @Test
- public void testSet2() throws Exception {
- int version = 0;
- Stat status = new Stat();
- client2.getData().storingStatIn(status).forPath("/app1");
- version = status.getVersion();
- client2.setData().withVersion(version).forPath("/app1","ddd".getBytes());
- }
删除节点
- //1.删除单个节点
- @Test
- public void testDelete() throws Exception {
- client2.delete().forPath("/app1");
- }
- //2.删除带有子节点的节点
- @Test
- public void testDelete2() throws Exception {
- client2.delete().deletingChildrenIfNeeded().forPath("/app1");
- }
- //3.必须成功的删除,目的是防止网络不稳定
- @Test
- public void testDelete3() throws Exception {
- client2.delete().guaranteed().forPath("/app1");
- }
- //4.回调,删除后再紧接着执行的方法
- @Test
- public void testDelete4() throws Exception {
- client2.delete().guaranteed().inBackground(new BackgroundCallback() {
- @Override
- public void processResult(CuratorFramework curatorFramework, CuratorEvent curatorEvent) throws Exception {
- System.out.println("删除成功");
- }
- }).forPath("/app1");
- }
Watch事件监听
为zookeeper的指定节点注册Watcher,并且在一些特定事件触发时,zookeeper服务端会将事件通知到特定的客户端上去,该机制是zookeeper实现分布式协调服务的重要特性
分布式锁的实现
分布式锁的出现
在单机开发时,涉及并发同步的时候,往往采用synchronized或Lock的方式来解决多线程的代码同步问题,这时候多线程运行同一个JVM上,在分布式集群工作时,属于多JVM下的工作环境,跨JVM之间已经无法通过多线程的锁解决同步问题。所以需要分布式锁用来处理跨机器进程之间的数据同步问题。
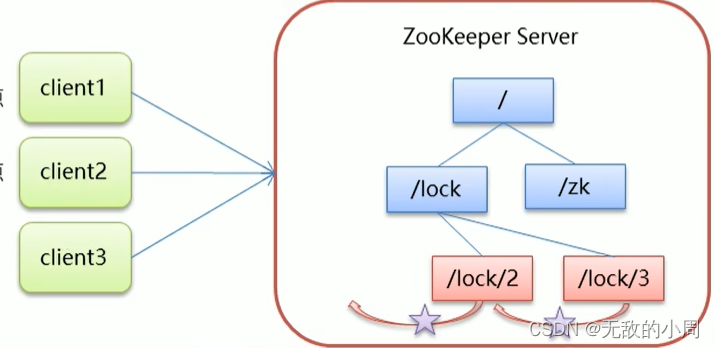
原理
锁是上在zookeeper的节点的服务上,在访问该节点的数据时,在该节点下再创建节点,用来标识,使用完毕锁,则删除该节点。
- 1.客户端获取锁时,在服务节点(lock)下创建临时顺序节点,因为避免服务器或者客户端宕机,无法正常消除节点,所以采用临时节点,不管是否宕机,只要会话结束就删除节点,顺序节点是为了有顺序的执行
- 2.获取服务节点(lock)下面所有的子节点,可认为这些子节点就是来访问的客户端,找到序号最小的节点,让其获取锁,使用完锁后,将该节点删除
- 3.如果发现自己创建的节点并非lock所有子节点中最小的,说明还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件
- 4.如果发现比自己小的那个节点被删除,则客户端的watcher会收到相应的通知,此时再次判断自己创建的节点是否是lock子结点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取比自己小的节点被注册监听
Curator的锁的分类
- InterProcessSemaphoreMutex:分布式排它锁(非可重入锁)
- InterProcessMutex:分布式可重入锁
- InterProcessReadWriteLock:分布式读写锁
- InterProcessMultiLock:将多个锁作为单个实体管理的容器
- InterProcessSemaphoreV2:共享信号量
12306案例
zookeeper集群
介绍
将zookeeper安装在多台计算机上,就构成一了一个zookeeper集群,在这个集群中,不同的机器担任不通过的角色,来完成服务的管理。
集群角色
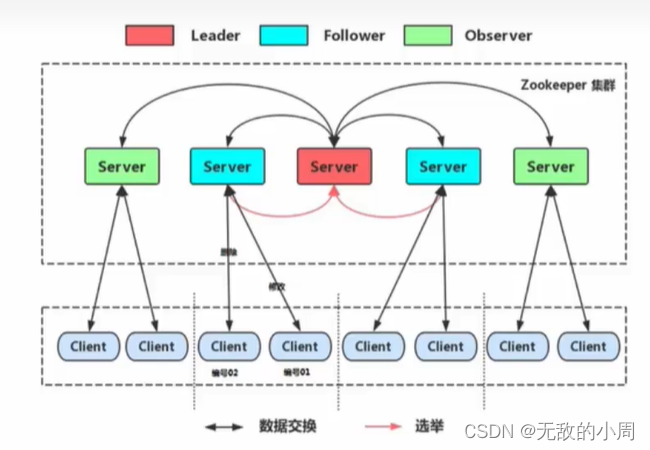
- Leader:领导者
处理事务请求(增删改)
集群内部各服务器的调度者
- Follower:跟随者
处理客户端非事务请求(查询),转发事务请求给Leader服务器
参与Leader选举投票
- Observer:观察者(减轻跟随者的压力)
处理客户端非事务请求,转发事务请求给Leader服务器
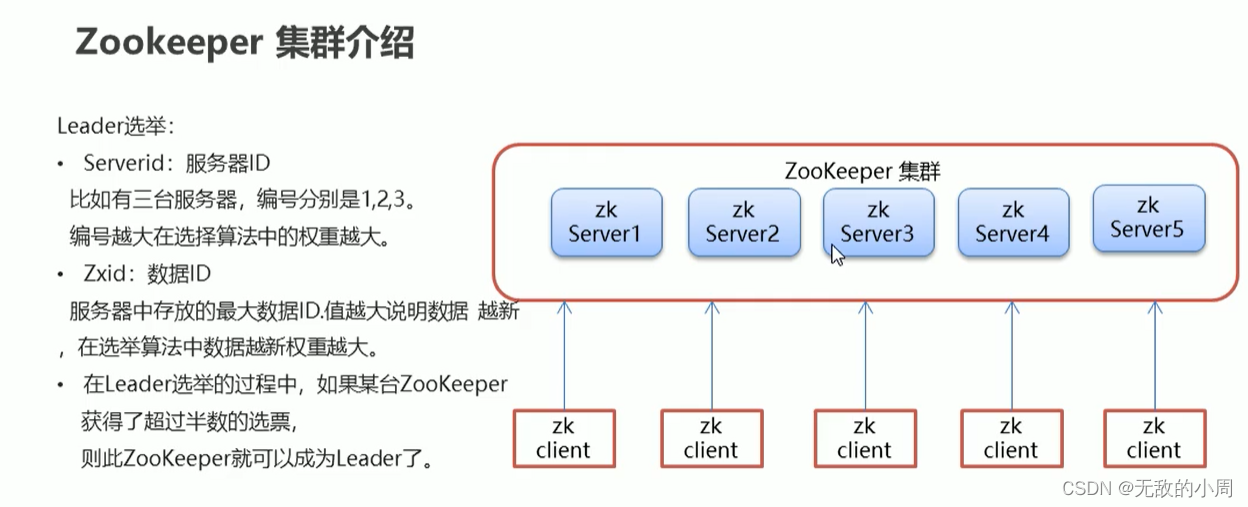
集群Leader的选举
-
相关阅读:
Day 89
如何像优秀测试人员那样思考?
Android 8.1 persisten 应用通过安装方式更新升级
CI/CD --git版本控制系统
NoSQL之redis集群(未完待续)
html中如何用vue语法,并使用UI组件库 ,html中引入vue+ant-design-vue或者vue+element-plus
linux进程管理,一个进程的一生(喂饭级教学)
技术实践干货 | 初探大规模 GBDT 训练
针对Docker容器的可视化管理工具—DockerUI
前端面经1
- 原文地址:https://blog.csdn.net/weixin_52972575/article/details/126084874
