-
Hadoop MapReduce 1.x 工作原理
下面解释一下作业在经典的 MapReduce 1.0 中运行的工作原理。最顶层包含4个独立的实体:
- 客户端:提交 MapReduce 作业。
- JobTracker:协调作业的运行。JobTracker 是一个Java应用程序,它的主类是 JobTracker。
- TaskTracker:运行作业划分后的任务。TaskTracker 是一个 Java 应用程序,它的主类是 TaskTracker。
- 分布式文件系统(一般为HDFS):用来在其他实体间共享作业文件。
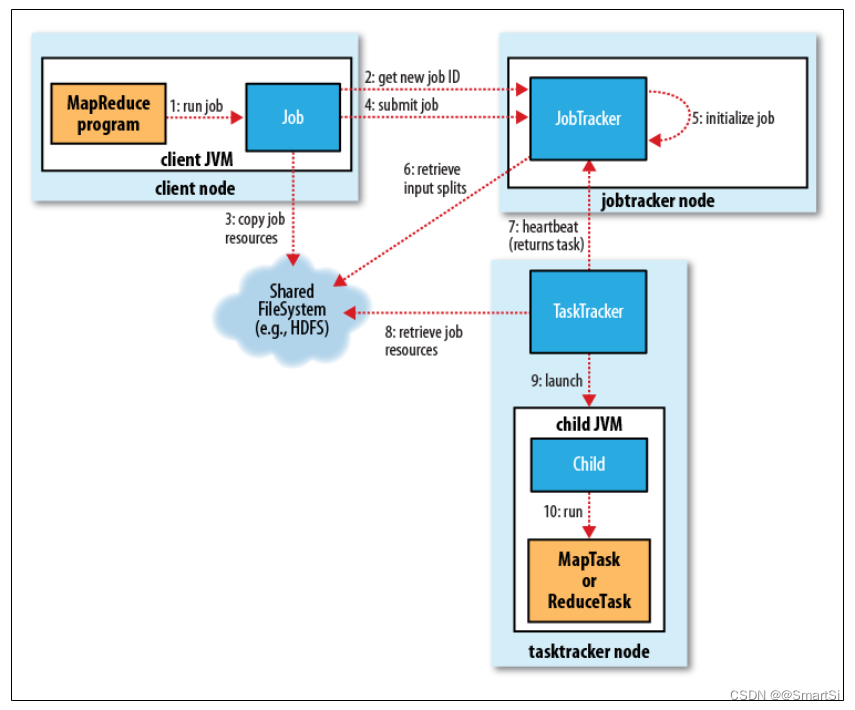
1. 作业提交
Job 的 submit() 方法创建一个内部的 JobSunmmiter 实例,并且调用其 submitJobInternal() 方法。提交作业后,waitForCompletion() 每秒轮询作业的进度,如果发现自上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器。如果失败,导致作业失败的错误被记录到控制台。
JobSunmmiter 所实现的作业提交过程如下:
- 通过调用 JobTracker 的 getNewJobId() 方法向 JobTracker 请求一个新的作业ID。参见上图步骤2。
- 检查作业的输出。例如,如果没有指定输出目录或者输出目录已经存在,作业就不提交,错误抛回给 MapReduce 程序。
- 计算作业的输入分片。如果分片无法计算,比如因为输入路径不存在,作业不会提交,错误返回给 MapReduce 程序。
- 将运
-
相关阅读:
【软考】关键路径和松弛时间的定义和计算方式
PHP 变量
AI初识--LLM、ollama、llama都是些个啥?
socket学习二、accept、read、write函数详解
论文解析-基因序列编码算法DeepSEA
python机器学习与深度学习在气象领域中的实践技术应用
netty系列之:可以自动通知执行结果的Future,有见过吗?
Button及Button的功能扩展
出门在外保护好自己
【poi 看这一篇就够了!!!】使用poi导出定制excle表格
- 原文地址:https://blog.csdn.net/SunnyYoona/article/details/126131891