-
Python学习之CSDN21天学习挑战赛计划之2
接上一篇文章继续学习。。。
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。

另外这个时候可以看一下result的结果
- >>> print(result)
object; span=(0, 4), match='uart'>
1,匹配单个字符
. 表示匹配任意1个字符(除\n)
[] 表示匹配[]中列举的字符
\d 表示匹配数字,即0-9
\D 表示匹配非数字,即不是数字的都可以匹配上
\s 表示匹配空白,即空格,tab键
\S 表示匹配非空白
\w 表示匹配非特殊字符,即a-z,A-Z,0-9,_、汉字
\W 表示匹配特殊字符,非字母,非数字,非汉字,非_
example:
- >>> print(re.match(".","M"))
object; span=(0, 1), match='M'> - >>> print(re.match("fo.t","foot"))
object; span=(0, 4), match='foot'>
2,匹配多个字符
* 表示匹配前一个字符出现0次或者无限次,即可有可无
+表示匹配前一个字符或者出现无限次,即至少有一次
?表示前一个字符出现1次或者0次,即要么有1次,要么没有
{m}表示匹配前一个字符出现m次
{m,n}表示匹配前一个字符出现从m到n次
- import re
- names=["name1","_name","2_name","__name__哈哈"]
- for name in names:
- ret=re.match("[a-zA-Z_]+[\w]*",name)
- if ret:
- print("var %s,match " % ret.group())
- else:
- print("var %s,not match" % name)
执行结果如下:
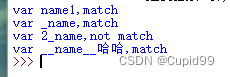
代码分析:
1,需要匹配[]中列举出的字符,包括a-zA-Z_,说明names中的第1,2,4个元素可以匹配上
2,最后一个表示哈哈也能匹配上
-
相关阅读:
mysql的安装和连接
Redis基础详解
债券涨跌逻辑及复盘
数据同步
JZ68 二叉搜索树的最近公共祖先
操作系统——复习笔记
R语言移除列表中的空元素(列表数据中包含NULL,移除NULL元素)、使用purrr包的compact函数删除NULL元素
哪些企业适合做私域?私欲怎么做成效大?
牛客网刷题(二)
第七十天 APP攻防-微信小程序&解包反编译&数据抓包&APK信息资源提取
- 原文地址:https://blog.csdn.net/Cupid99/article/details/126128640