-
go——内存分配机制
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
设计思想
1.内存分配算法采用Google的 TGMalloc算法:每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才会向加锁向全局内存池申请,减少系统调用并且避免不同线程对全局内存池的锁竞争
2.把内存切分的非常的细小,分为多级管理,以降低锁的粒度
3.回收对象内存时,并没有将其真正释放掉,只是放回预先分配的大块内存中,以便复用。只有内存闲置过多的时候,才会尝试归还部分内存给操作系统,降低整体开销
Go的内存管理组件主要有:mspan 、mcache .mcentral和mheap
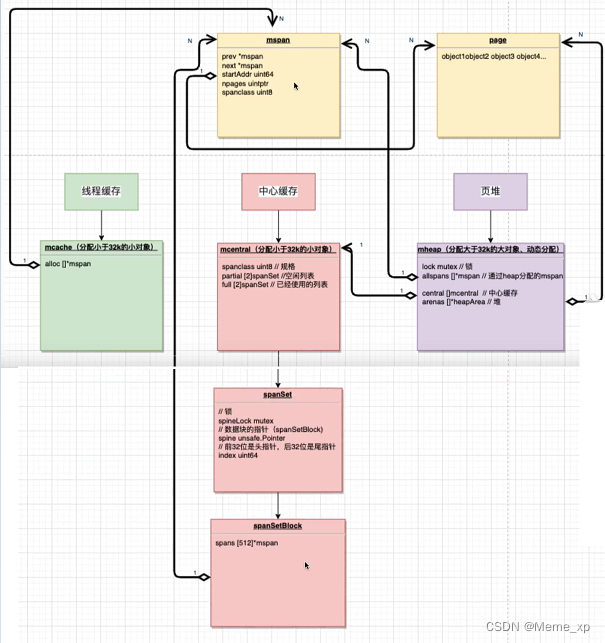
mspan其实就是一个内存管理的基础单元
mcache是线程的一个缓存,比如说每个g,每个线程,每个goroutine它会有一个mcache,mcache实际上就是有多个mspan
mcentral是一个中心缓存,不属于任何一个线程,是一个中心缓存,全局的。里面包含不同规格的span,每个规格的span分为两类:一类是空闲的一类是非空闲的
mheap也是全局的页堆,它和中心缓存全部都是有一把琐的,里面也有mspan和mcentral,
中心缓存就是在mheap上面进行管理。最后是一个堆,就是分配内存的地方分配对象:
1.微对象(0,16B)︰先使用线程缓存上的微型分配器,再依次尝试线程缓存、中心缓存、堆分配内存;
2.小对象[16B,32KB]依次尝试线程缓存、中心缓存、堆分配内存;
3.大对象(32KB,+oo):直接尝试堆分配内存;分配流程
1.首先通过计算使用的大小规格
2.然后使用mcache中对应大小规格的块分配。
3.如果mcentral 中没有可用的块,则向mheap申请,并根据算法找到最合适的mspan 。
4.如果申请到的mspan超出申请大小,将会根据需求进行切分,以返回用户所需的页数。剩余的页构成一个新的mspan放回mheap 的空闲列表。
5.如果mheap中没有可用span,则向操作系统申请一系列新的页(最小1MB)
内存逃逸机制
概念
在一段程序中,每一个函数都会有自己的内存区域存放自己的局部变量、返回地址等,这些内存会由编译器在栈中进行分配,每一个函数都会分配一个栈桢,在函数运行结束后进行销毁,但是有些变量我们想在函数运行结束后仍然使用它,那么就需要把这个变量在堆上分配,这种从"栈"上逃逸到"堆""上的现象就成为内存逃逸。
在栈上分配的地址,一般由系统申请和释放,不会有额外性能的开销,比如函数的入参、局部变量、返回值等。在堆上分配的内存,如果要回收掉,需要进行GC,那么GC一定会带来额外的性能开销。编程语言不断优化GC算法,主要目的都是为了减少GC带来的额外性能开销,变量一旦逃逸会导致性能开销变大。
逃逸机制
编译器会根据变量是否被外部引用来决定是否逃逸:
1.如果函数外部没有引用,则优先放到栈中;
2.如果函数外部存在引用,则必定放到堆中;
3.如果栈上放不下,则必定放到堆上;总结
1.栈上分配内存比在堆中分配内存效率更高
2.栈上分配的内存不需要GC处理,而堆需要
3.逃逸分析目的是决定内分配地址是栈还是堆
4.逃逸分析在编译阶段完成因为无论变量的大小,只要是指针变量都会在堆上分配,所以对于小变量我们还是使用传值效率(而不是传指针)更高一点
内存对齐机制
什么是内存对齐
为了能让CPU可以更快的存取到各个字段,Go编译器会帮你把struct结构体做数据的对齐。所谓的数据对齐,是指内存地址是所存储数据大小(按字节为单位)的整数倍,以便CPU可以一次将该数据从内存中读取出来。编译器通过在结构体的各个字段之间填充一些空白已达到对齐的目的。对齐系数
不同硬件平台占用的大小和对齐值都可能是不一样的,每个特定平台上的编译器都有自己的默认"“对齐系数”,32位系统对齐系数是4,64位系统对齐系数是8
不同类型的对齐系数也可能不一样,使用Go语言中的unsafe.Alignof 函数可以返回相应类型的对齐系数,对齐系数都符合2^n这个规律,最大也不会超过8优点
1.提高可移植性,有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了
⒉.提高内存的访问效率,32位CPU下一次可以从内存中读取32位〈4个字节)的数据,64位CPU下一次可以从内存中读取64位(8个字节)的数据,这个长度也称为CPU的字长。CPU一次可以读取1个字长的数据到内存中,如果所需要读取的数据正好跨了1个字长,那就得花两个CPU周期的时间去读取了。因此在内存中存放数据时进行对齐,可以提高内存访问效率。
缺点
1.存在内存空间的浪费,实际上是空间换时间结构体对齐
1.结构体变量中成员的偏移量必须是成员大小的整数倍
2.整个结构体的地址必须是最大字节的整数倍(结构体的内存占用是1/4/8/16byte…) -
相关阅读:
【python基础】第11回 数据类型内置方法 02
Vue前端开发:事件传参
git常用命令
2022年4月最新面经答案总结(Java基础、数据库、JVM、计网、计操、集合、多线程、Spring)持续更新
PayPal VS Block:开启全球金融科技的新未来
【postgresql】CentOS7 安装Pgweb
unity---Mesh网格编程(六)
设计模式-单例
unity学习之汇总
oracle数据库报文需要先转UTF-8,再MD5,再base64加密
- 原文地址:https://blog.csdn.net/qq_52563729/article/details/126119673