-
05-分布式计算框架
目录
文章内容来自:南京大学 / 星环科技课程,大数据理论与实践课程Ⅰ
对细节部分引用其他网络资源进行补充。
一,MapReduce
1,简介
MR是面向离线批处理的分布式计算框架
核心思想:分而治之,并行计算。移动计算,非移动数据;
适用场景
- 数据统计,如网站的PV、UV统计
- 搜索引擎构建索引
- 海量数据查询
- 复杂数据分析算法实现
不适用场景
- OLAP:要求毫秒或秒级返回结果
- 流计算:输入数据集是动态的,而MapReduce是静态的
- DAG计算
- -多个任务之间存在依赖关系,后一个的输入是前一个的输出,构成DAG有向无环图
- -MapReduce很难避免Suffle,造成大量磁盘IO,导致性能较为低下
2,原理
2.1 基本概念
1,Job & Task(作业与任务)
- 作业是客户端请求执行的一个工作单元。包括输入数据、MapReduce程序、配置信息
- 任务是将作业分解后得到的细分工作单元。分为Map任务和Reduce任务
2,Split(切片)
- 输入数据被划分成等长的小数据块,称为输入切片(Input Split),简称切片
- Split是逻辑概念,仅包含元数据信息,如数据的起始位置、长度、所在节点等
- 每个Split交给一个Map任务处理,Split的数量决定Map任务的数量
- Split大小默认等于HDFS Block大小,Split的划分方式由程序设定,Split与HDFS Block没有严格的对应关系。Split越小,Map任务越多,并发度越高,但开销也越大;Split越大,任务越少,并发度降低
3,Map阶段(映射)
- 由若干Map任务组成,任务数量由Split数量决定
- 输入:Split切片(key-value) 。输出:中间计算结果(key-value)
4,Reduce阶段(化简)
- 由若干Reduce任务组成,任务数量由程序指定
- 输入:Map阶段输出的中间结果(key-value)。输出:最终结果(key-value)
5,Shuffle阶段(混洗)
- Shuffle是Map和Reduce之间的强依赖关系(Shuffle依赖)导致的,即每个Reduce的输入依赖于所有Map的输出
- Map和Reduce阶段的中间环节(虚拟阶段),分为Map端Shuffle和Reduce端Shuffle
- 包括Partition(分区)、Sort(排序)、Spill(溢写)、Merge(合并)和Fetch(抓取)等工作
Partition(分区)
- Reduce任务数量决定了Partition数量,Partition编号 = Reduce任务编号
- 利用“哈希取模”对Map输出数据分区,即Partition编号 = key hashcode % reduce task num(%为取模)
- Partition为具有相同编号的Reduce任务供数
哈希取模的作用
- 数据划分:将一个数据集随机分成若干个子集(Hash函数选择不当可能造成数据倾斜)
- 数据聚合:将Key相同的数据聚合在一起
避免和减少Shuffle是MapReduce程序调优的关键
2.2 程序执行过程
1,MR执行过程
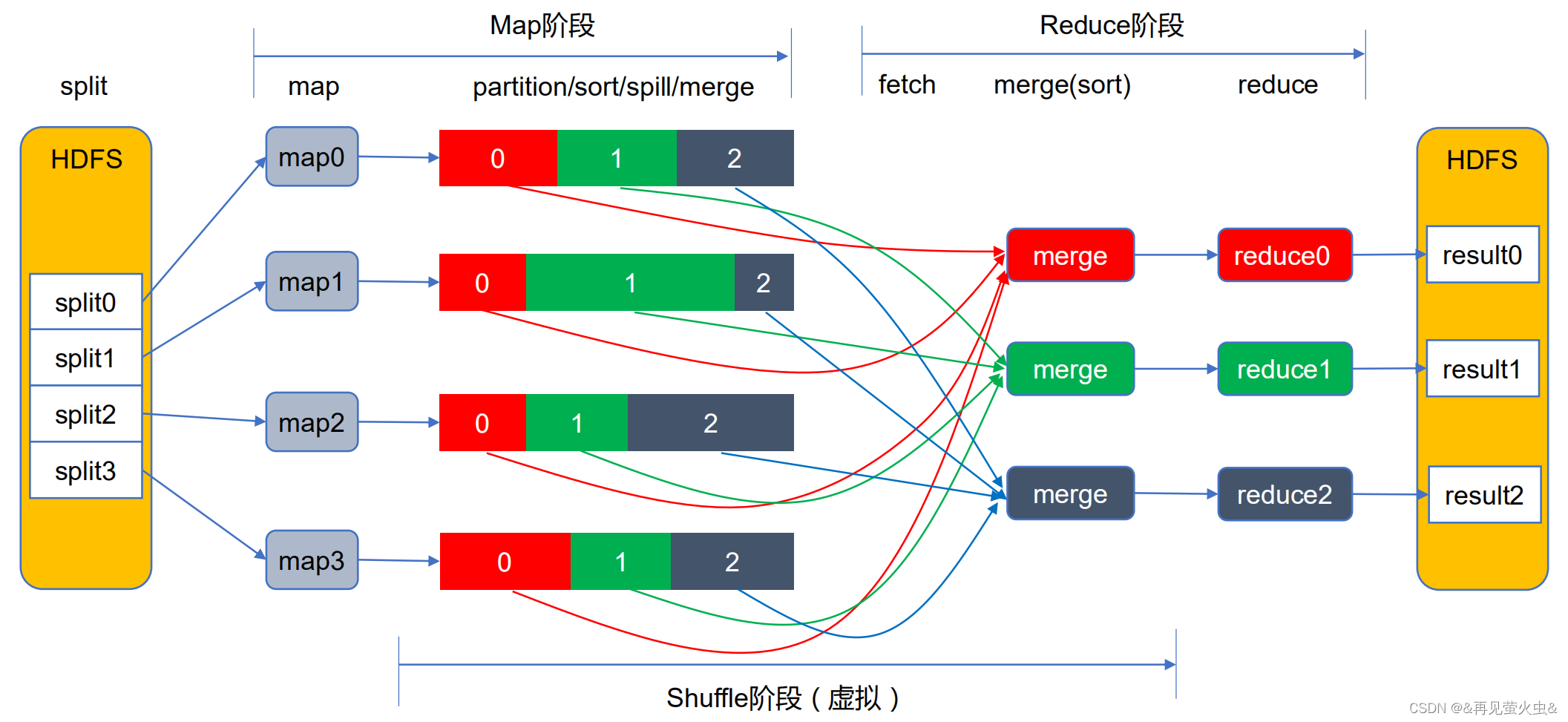
2,shuffle详解
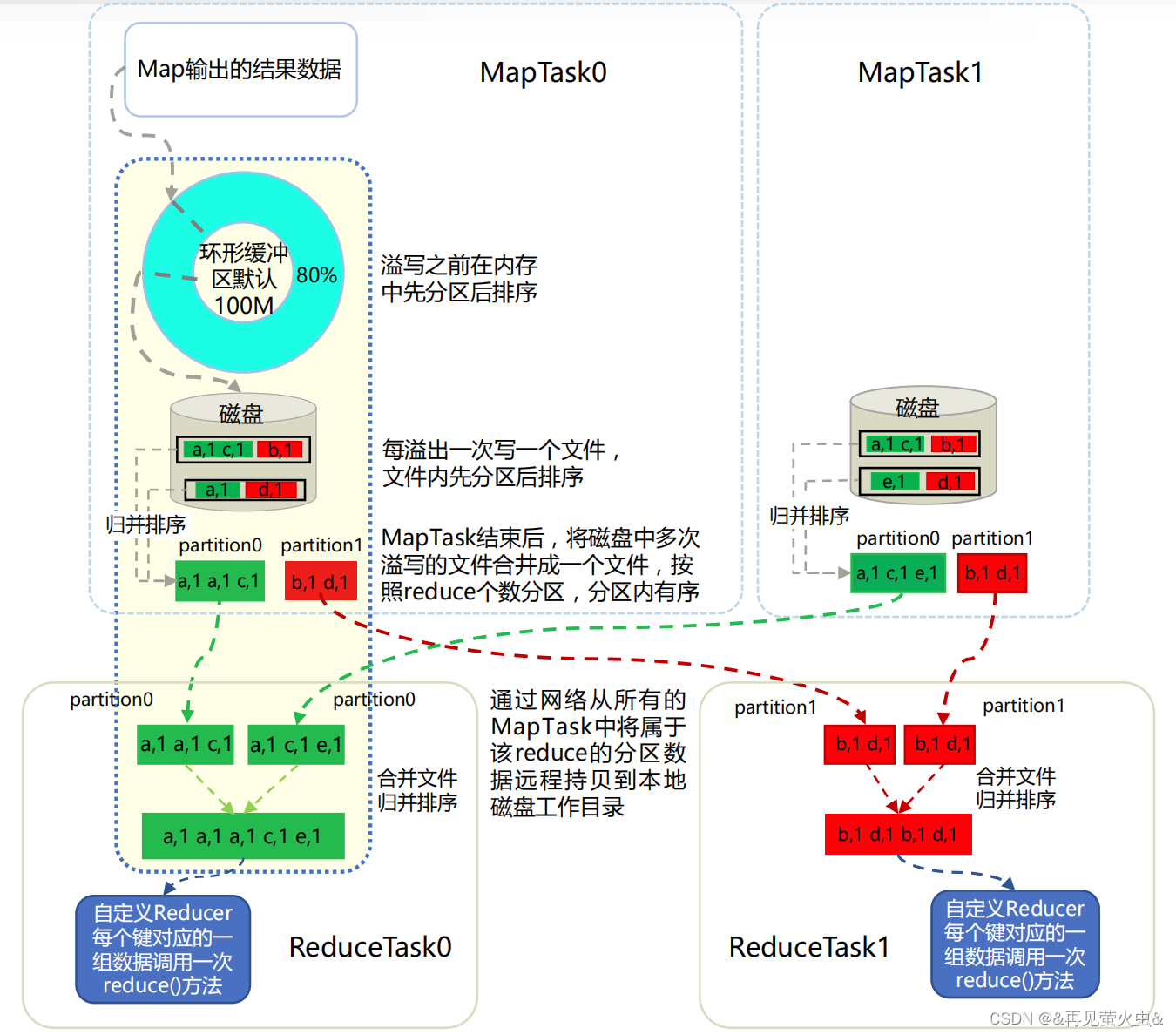
注意:在溢写之前需要先进行排序(便于后续归并排序),MapTask结束后仍需要通过归并排序将所有溢写文件合并为一个文件。
Map端
1,Map任务将中间结果写入环形内存缓冲区Buffer(默认100M);
2,当Buffer的数据量达到阈值(默认80%)时,对缓冲区内数据进行分区(Partition)和排序(Sort)。 先按“key hashcode % reduce task num”对数据进行分区,分区内再按key排序。然后将数据溢写(Spill)到磁盘的一个临时文件中。如果在溢写过程中,剩余20%的空间又被耗尽,这时就会触发panding,等80%空间腾出来之后再继续写;
3,Map任务结束前,将多个临时文件合并(Merge)为一个Map输出文件,文件内数据先分区后排序
Reduce端
1,Reduce任务从多个Map输出文件中抓取(Fetch)属于自己的分区数据(Partition编号=Reduce任务编号)
2,对抓取到的分区数据做归并排序,生成一个Reduce输入文件(文件内数据按key排序)
- 如果内存缓冲区够大,就直接在内存中完成归并排序,然后落盘
- 如果内存缓冲区不够,先将分区数据写到相应的文件中,再通过归并排序合并为一个大文件
关于环形缓冲区的介绍可以参考这里@大数据架构师Evan【设计思想赏析-MapReduce环形缓冲区】
2.3 作业运行模式
1,JobTracker/TaskTracker模式(Hadoop 1.X)
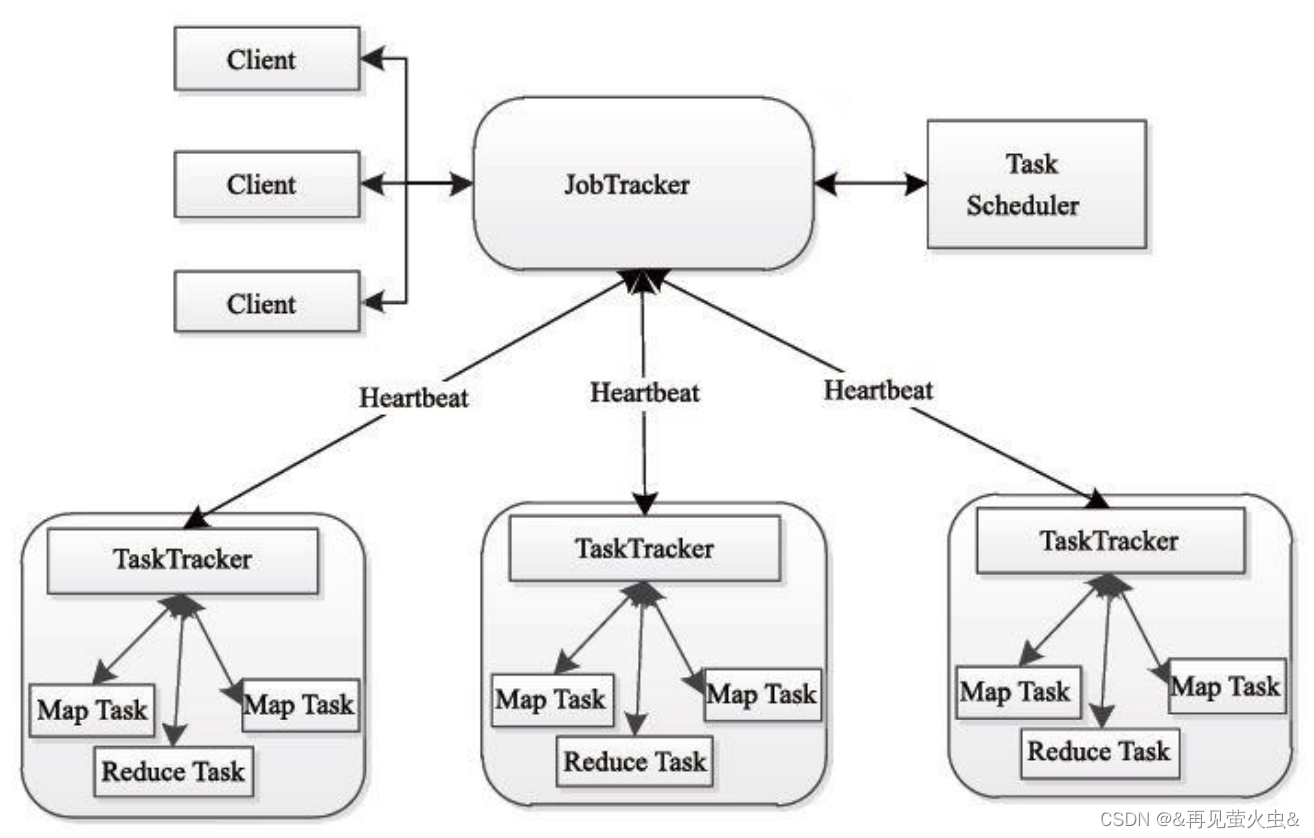
JobTracker节点(Master)
- 调度任务在TaskTracker上运行
- 若任务失败,指定新TaskTracker重新运行
TaskTracker节点(Slave)
- 执行任务,发送进度报告
存在的问题
- JobTracker存在单点故障
- JobTracker负载太重(上限4k节点)
- JobTracker缺少对资源的全面管理
- TaskTracker对资源的描述过于简单
- 源码难于理解
2,YARN模式(Hadoop 2.X )
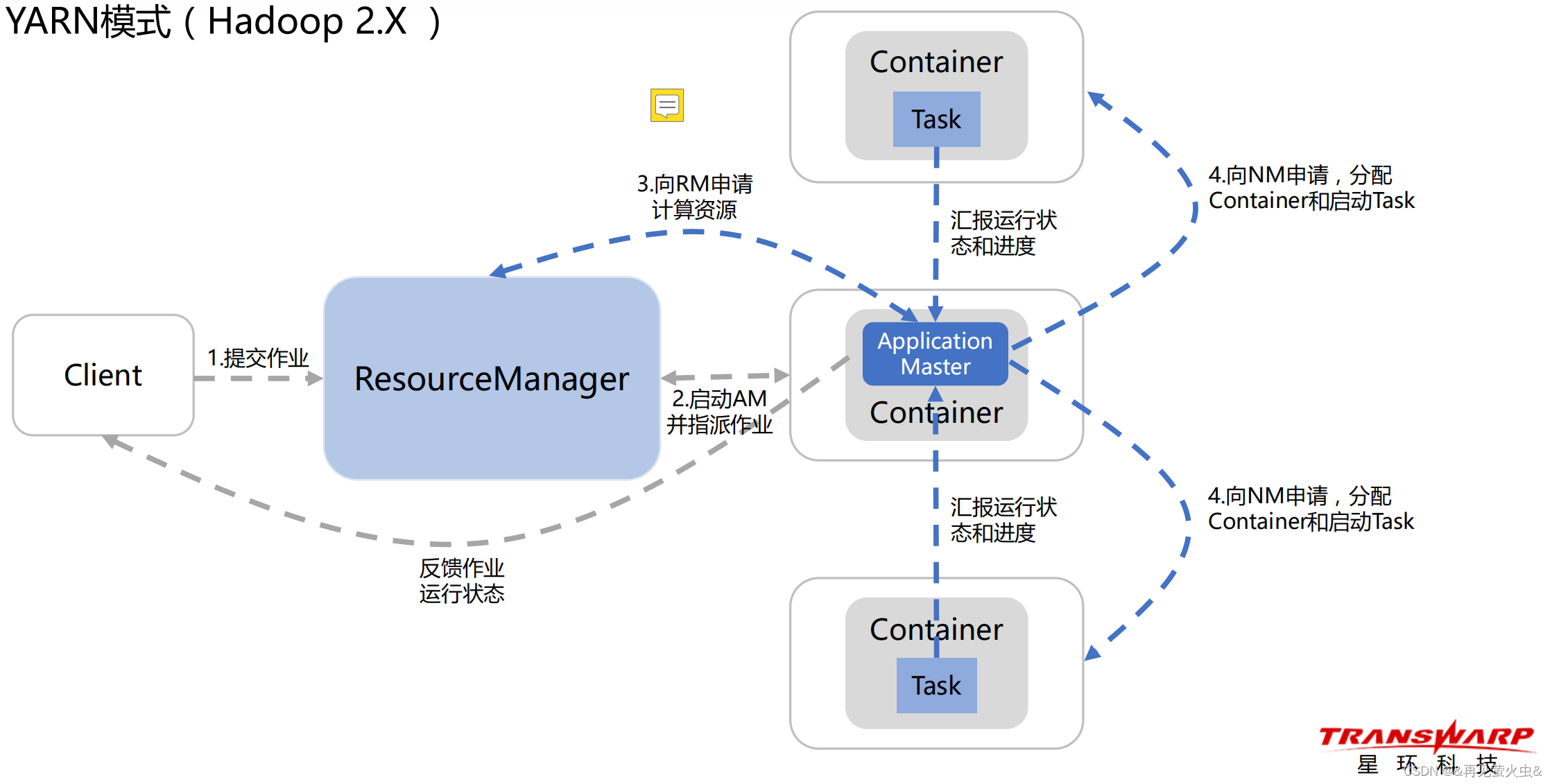
二,Spark
1,简介
1.1 背景
MapReduce有较大的局限性
- 仅支持Map、Reduce两种语义操作,划分为两个阶段(模型较为粗糙)
- 执行效率低,时间开销大(很难避免Shuffle)
- 主要用于大规模离线批处理
- 不适合迭代计算、在线分析、实时流处理等场景
计算框架种类多,选型难,学习成本高
- 批处理:MapReduce
- 流处理:Storm、Flink
- 在线分析:Impala、Presto
- 机器学习:Mahout
统一计算框架,简化技术选型,降低学习成本
- 在统一框架下,实现离线批处理、流处理、在线分析和机器学习
1.2 概念
由加州大学伯克利分校的AMP实验室开源
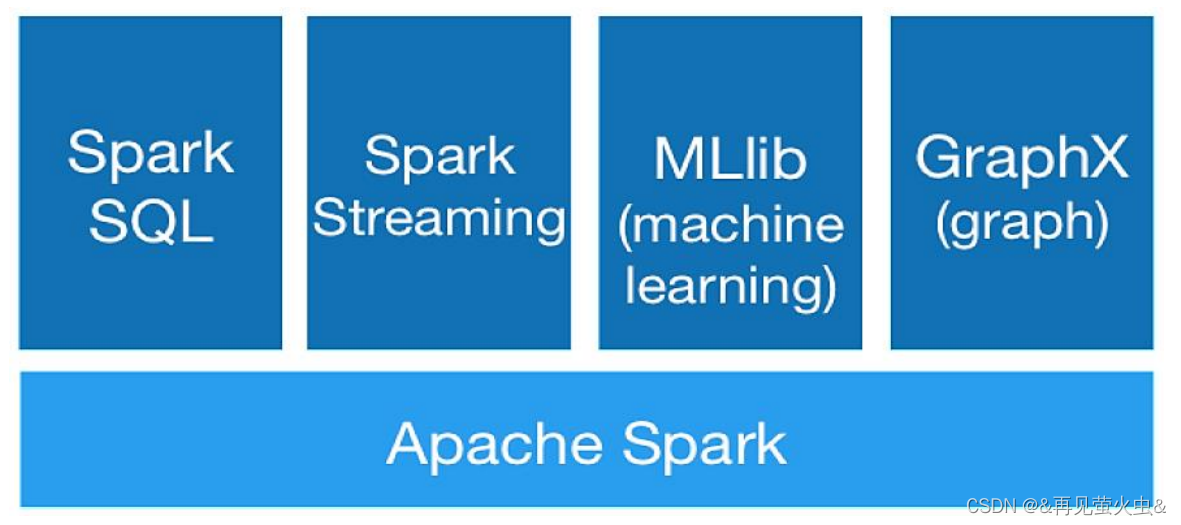
高性能的分布式通用计算引擎
- Spark Core:核心计算框架
- Spark SQL:结构化数据查询
- Spark Streaming:实时流处理
- Spark MLib:机器学习
- Spark GraphX:图计算
具有高吞吐、低延时、通用易扩展、高容错等特点
采用Scala语言开发
提供多种运行模式
1.3 特点
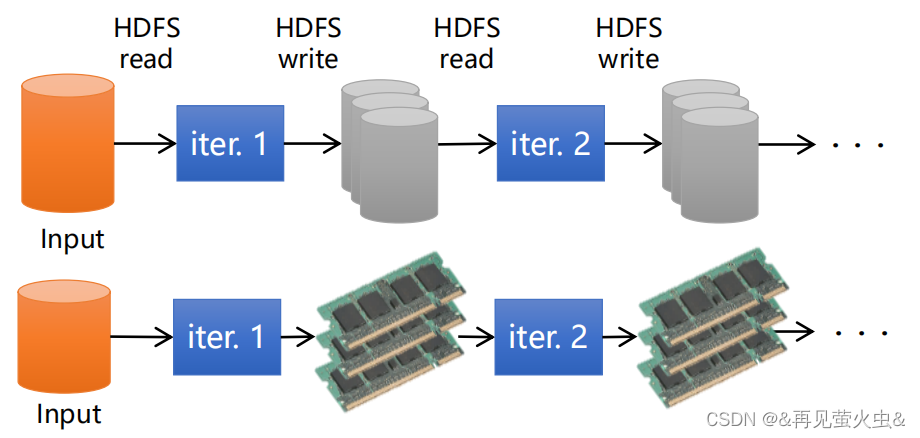
计算高效
- 语义操作多样,模型设计精细
- 利用RDD内存计算和Cache缓存机制,支持迭代计算和数据共享,减少数据读取的IO开销
- 利用DAG引擎,减少中间计算结果写入HDFS的开销
- 利用多线程池模型,减少任务启动开销,避免Shuffle中不必要的排序和磁盘IO操作
通用易用
- 适用于批处理、流处理、在线分析、机器学习等场景
- 提供了丰富的开发API,支持Scala、Java、Python、R等
运行模式多样
- Local模式
- Standalone模式
- YARN/Mesos模式
2,原理
2.1 编程模型
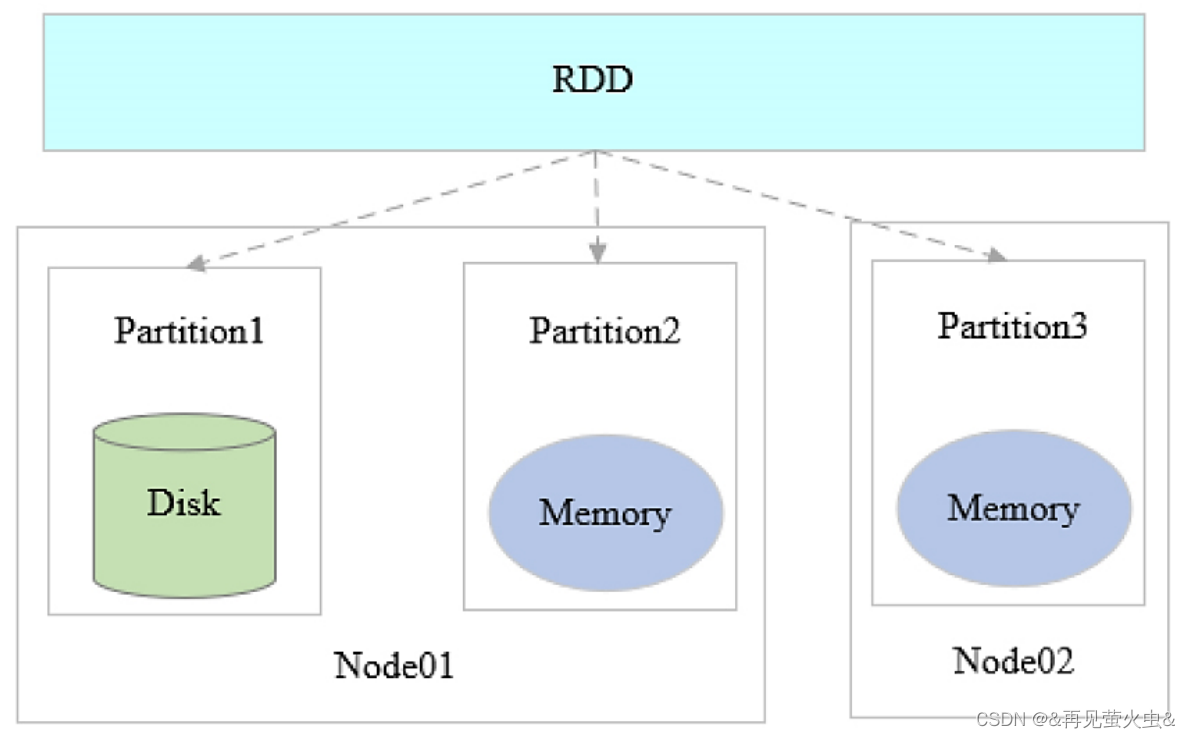
1,RDD(Resilient Distributed Datesets) 弹性分布式数据集
RDD相当于Table,由分布在集群中的多个Partition组成
Partition(分区)
- 分布在集群的不同节点中
- 只读数据集
- 通过转换操作来构造
- 失效后自动重构(弹性)
- 存储在内存或磁盘中
Spark基于RDD进行计算
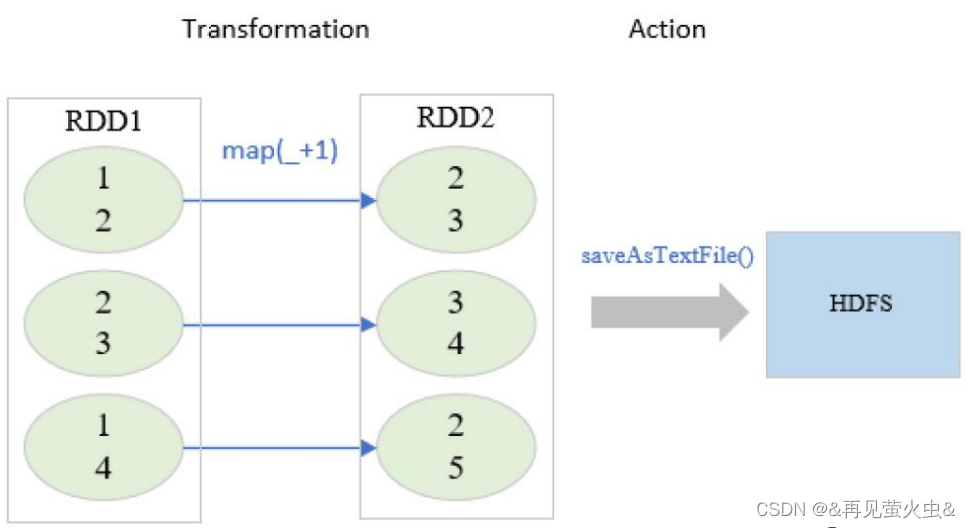
2,RDD操作(Operator)
Transformation(转换)
- 将Scala集合或Hadoop输入数据构造成一个新RDD
- 通过已有的RDD产生新RDD
- 惰性执行:只记录转换关系,不触发计算
- 例如:map、filter、flatmap、union、distinct、sortbykey
Action(动作)
- 通过RDD计算得到结果或者落盘
- 真正触发计算
- 例如:first、count、collect、foreach、saveAsTextFile
以rdd1.map(_,+1).saveAsTextFile(“hdfs://node01:9000”)为例
3,RDD依赖(Dependency)
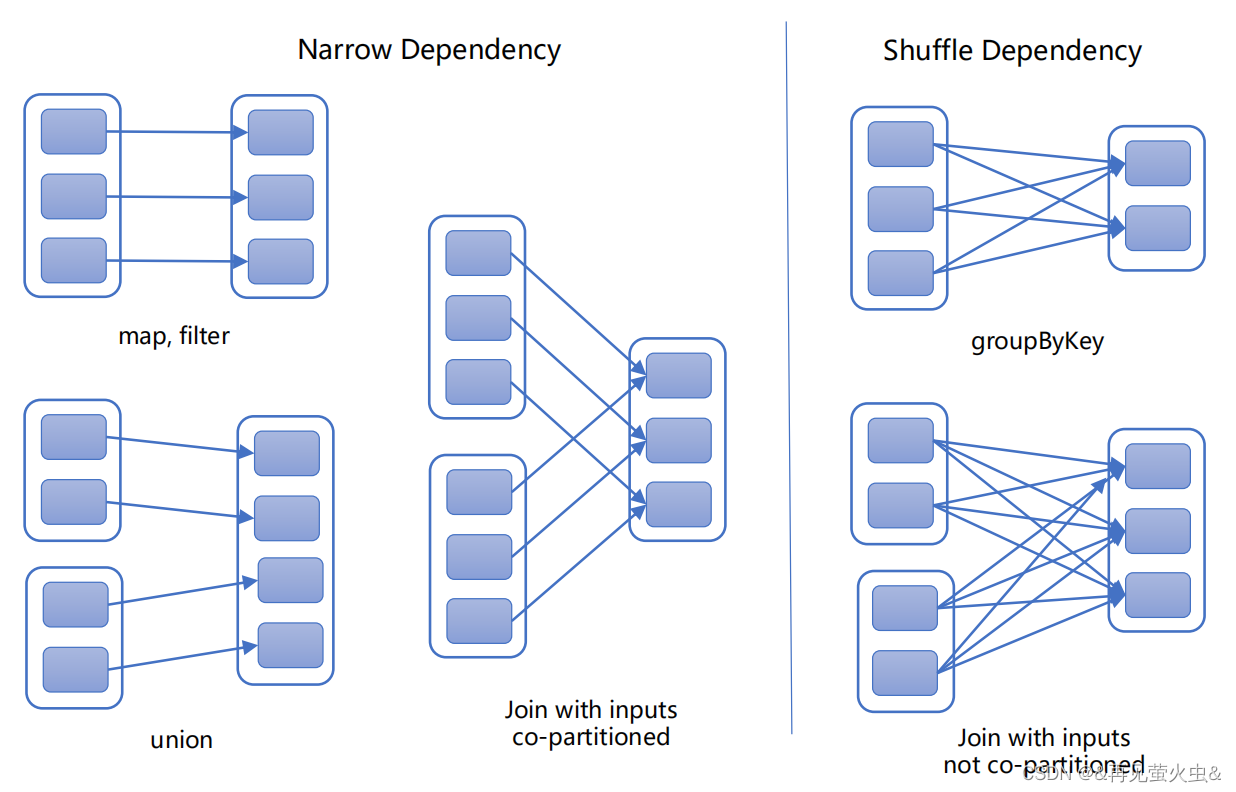
窄依赖(Narrow Dependency)
- 每个父RDD分区只能为一个子RDD分区供数,
- 子分区所依赖的父分区集合之间没有交集
- 子RDD分区数据丢失或损坏,从其依赖的父RDD分区重新计算即可,无需Shuffle
- 例如:map、filter、union
宽依赖(Wide/Shuffle Dependency)
- 每个父RDD分区为所有子RDD分区供数
- 子RDD区数据丢失或损坏,从所有父RDD分区重新计算,必须Shuffle
- 相对于窄依赖,宽依赖付出的代价要高很多,尽量避免使用
- 例如:groupByKey、reduceByKey、sortByKey
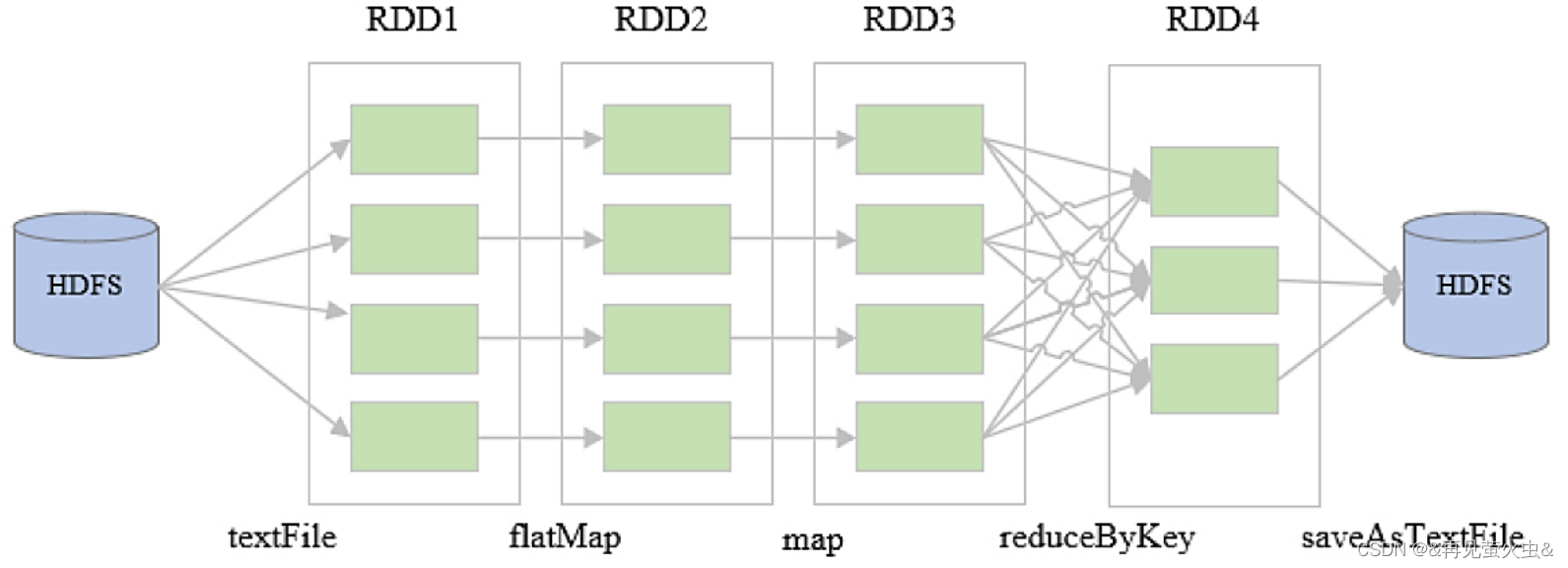
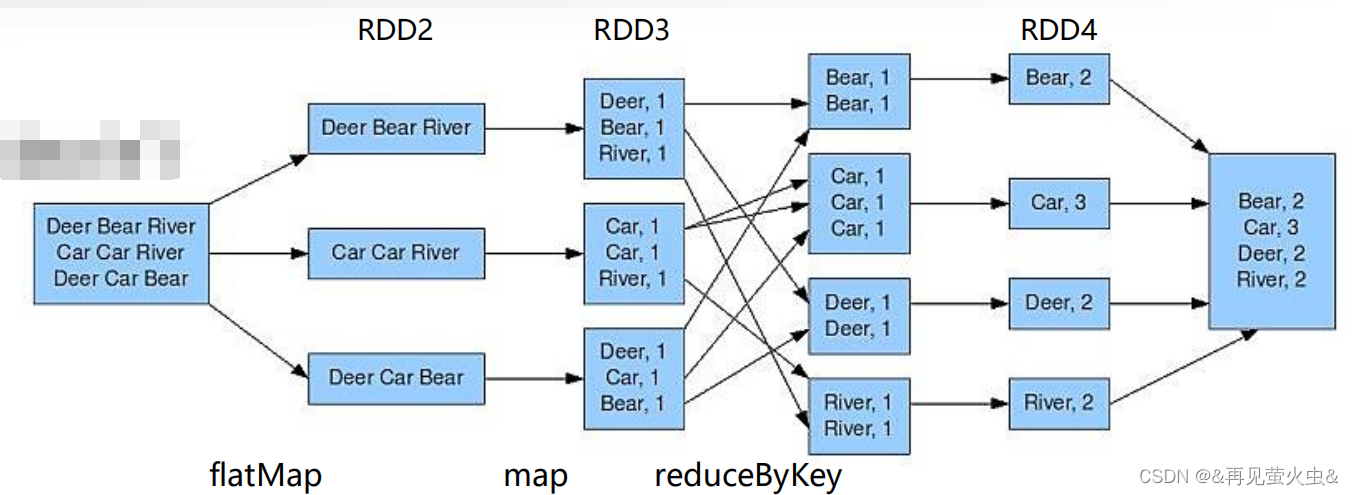
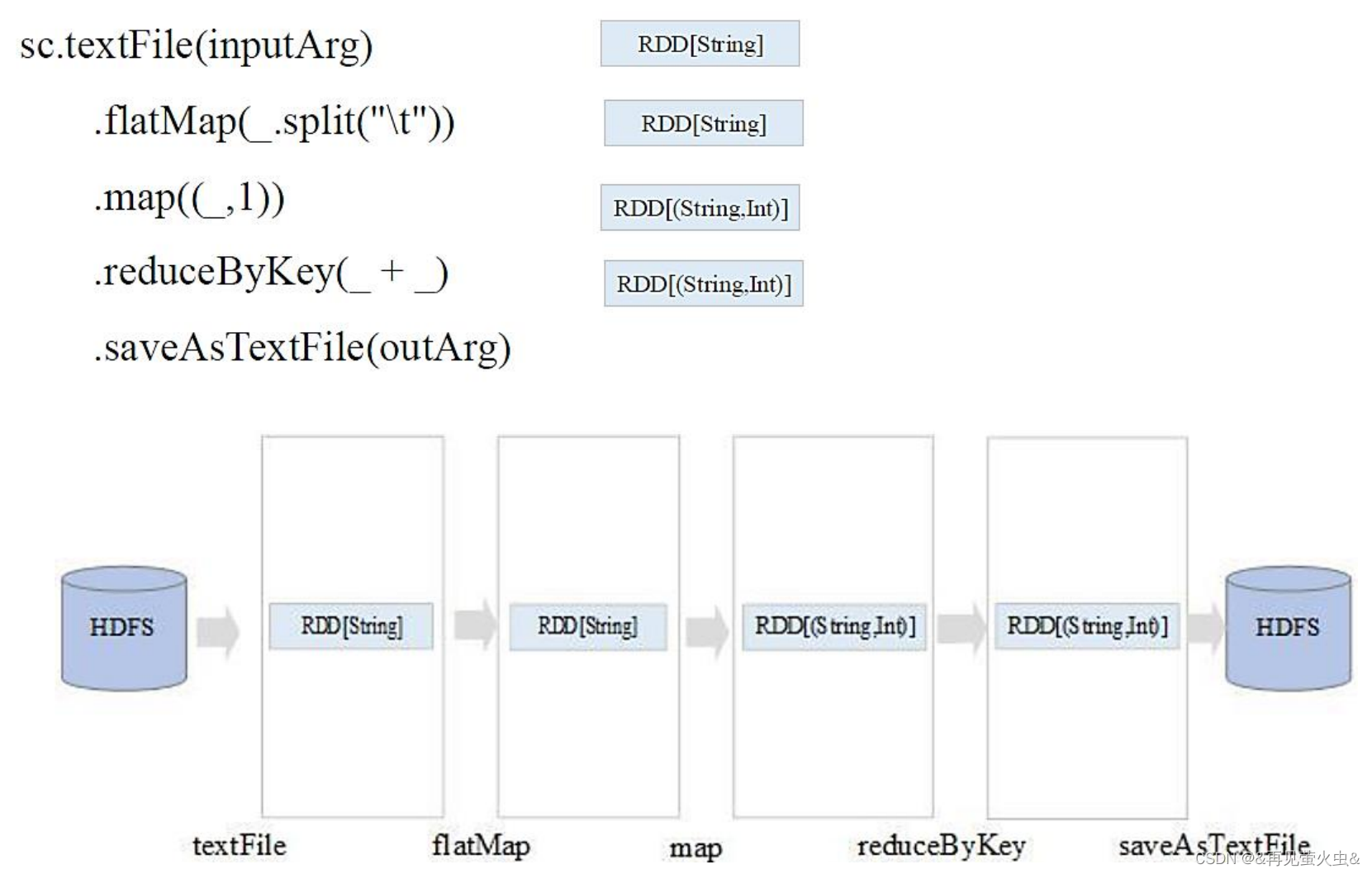
4,示例:WordCount
val rdd1 = sc.textFile(“hdfs://node01:9000/data/in”)
val rdd2 = rdd1.flatMap(_.split(“\t”))
val rdd3 = rdd2.map((_,1))
val rdd4 = rdd3.reduceByKey((_+_))
rdd4.saveAsTextFile(“hdfs://node01:9000/data/out”)
2.2 运行模式
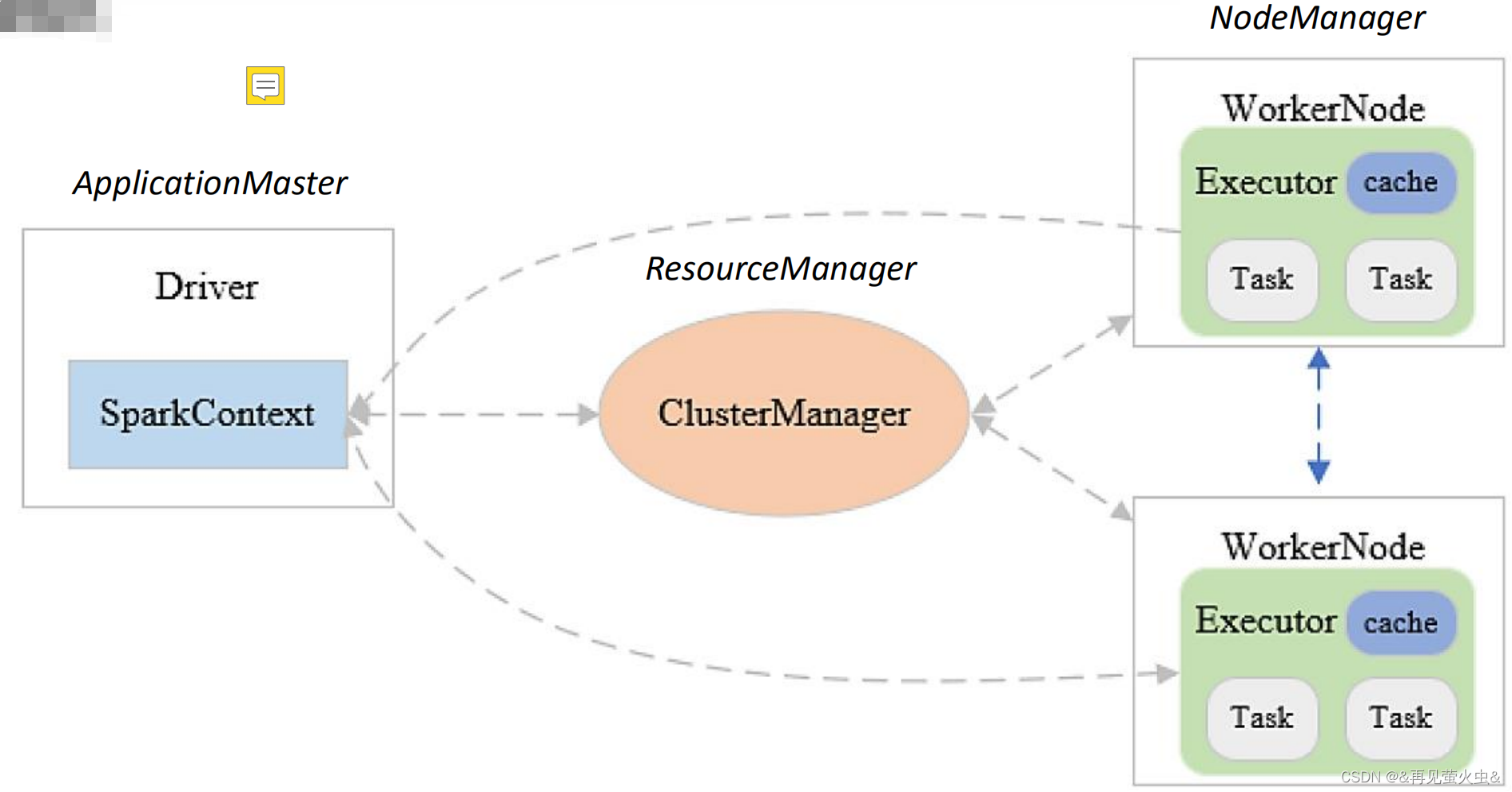
1,抽象模式
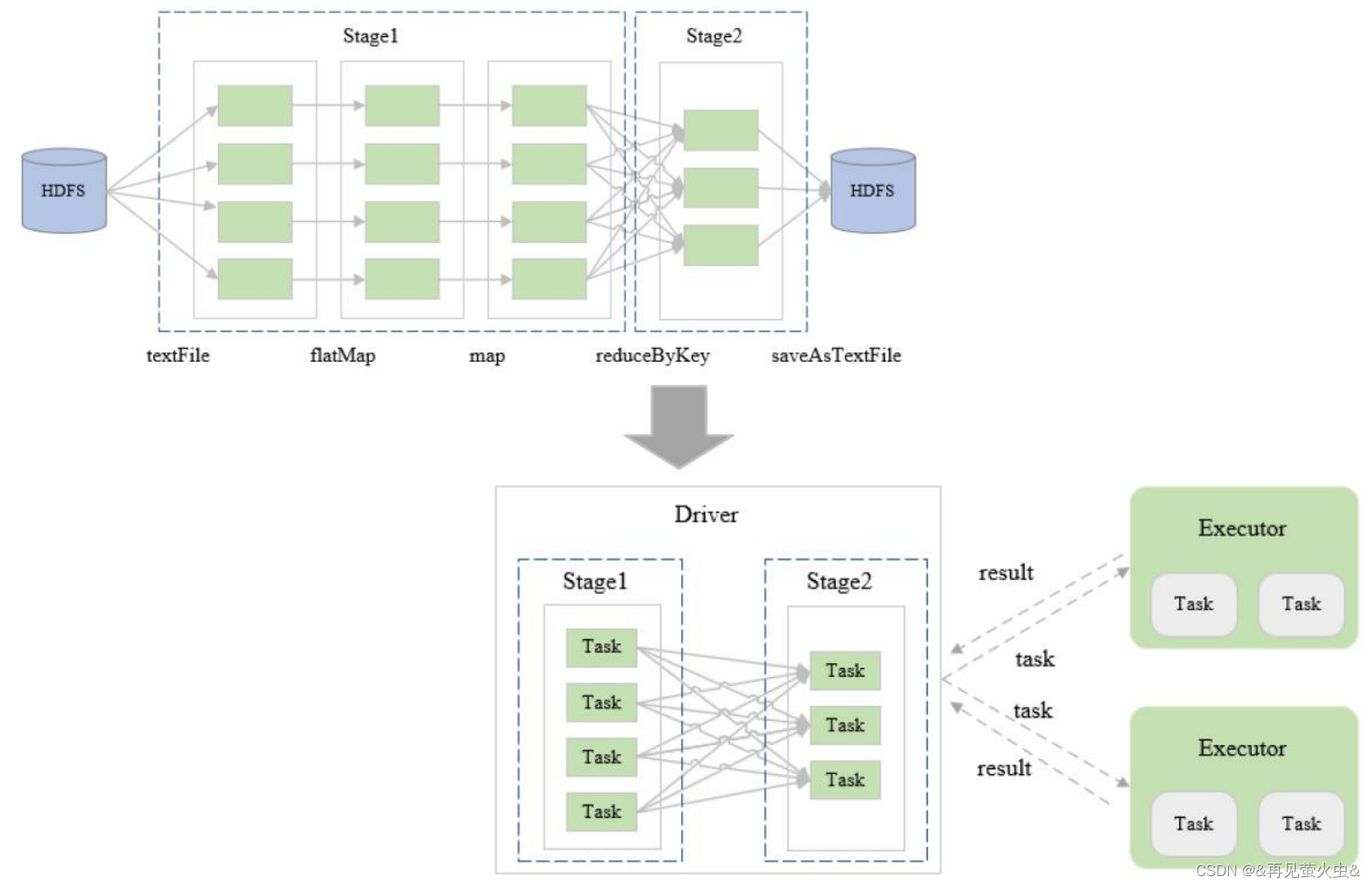
Driver
- 每个Spark作业启动一个Driver,每个Driver创建一个SparkContext
- 负责解析Spark程序、划分Stage、调度任务到Executor上执行
SparkContext
- 负责加载配置信息,初始化运行环境,创建DAGScheduler和TaskScheduler
- DAGScheduler:根据任务依赖建立DAG、根据宽依赖划分Stage、提交TaskSet
- TaskScheduler:任务调度和监管
Executor
- 负责执行Driver分发的任务,一个节点可以启动多个Executor,每个Executor通过多线程运行多个任务
Task
- Spark运行的基本单位,一个Task负责处理若干RDD分区的计算逻辑
2,Local模式
单机运行,通常用于测试
Spark程序以多线程方式直接运行在本地
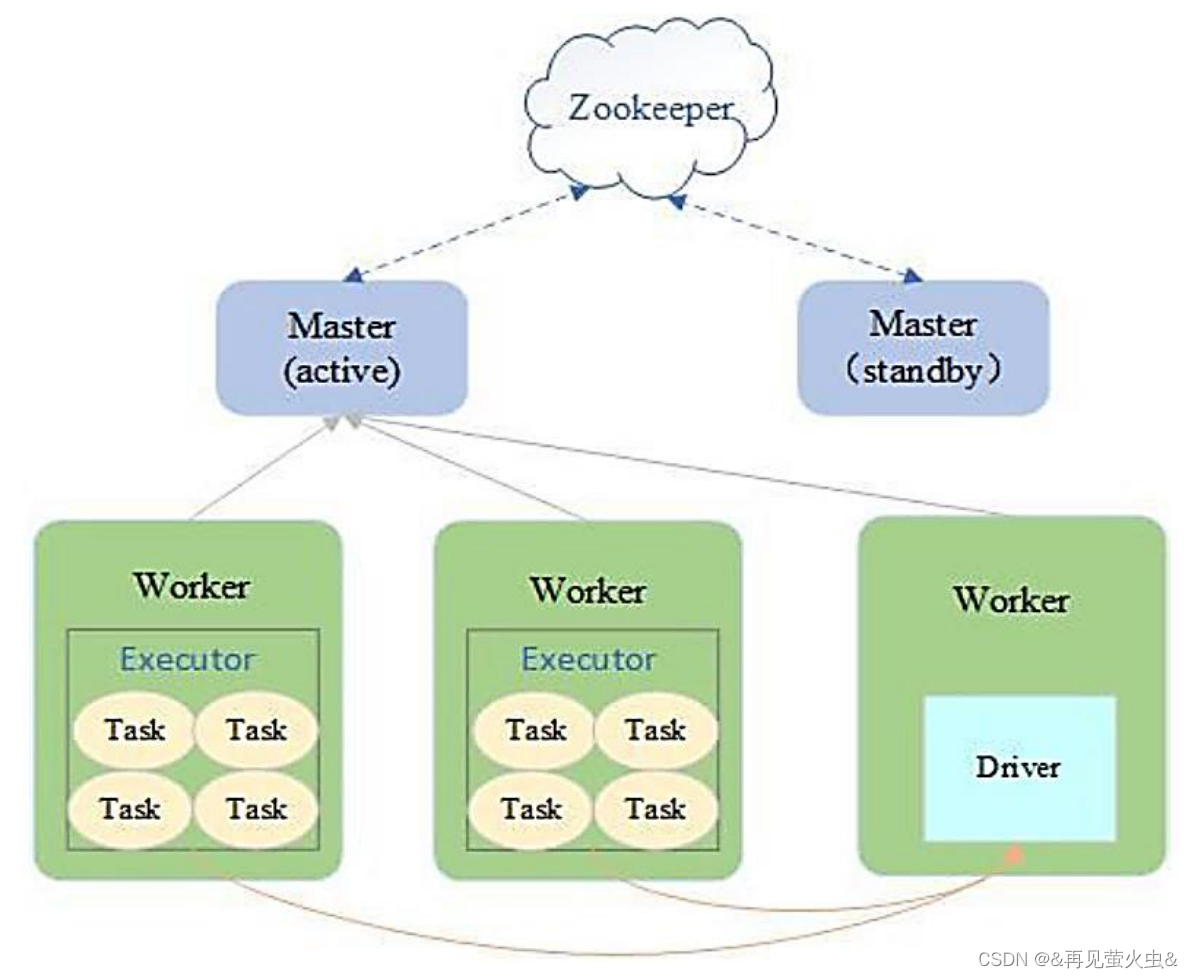
3,Standalone模式
Spark集群独立运行,不依赖于第三方资源管理系统,如YARN、Mesos
采用Master/Slave架构
- Master统一管理集群
- Driver在Worker中运行
ZooKeeper负责Master HA,避免单点故障
适用于集群规模和数据量都不大的情况
4,YARN模式
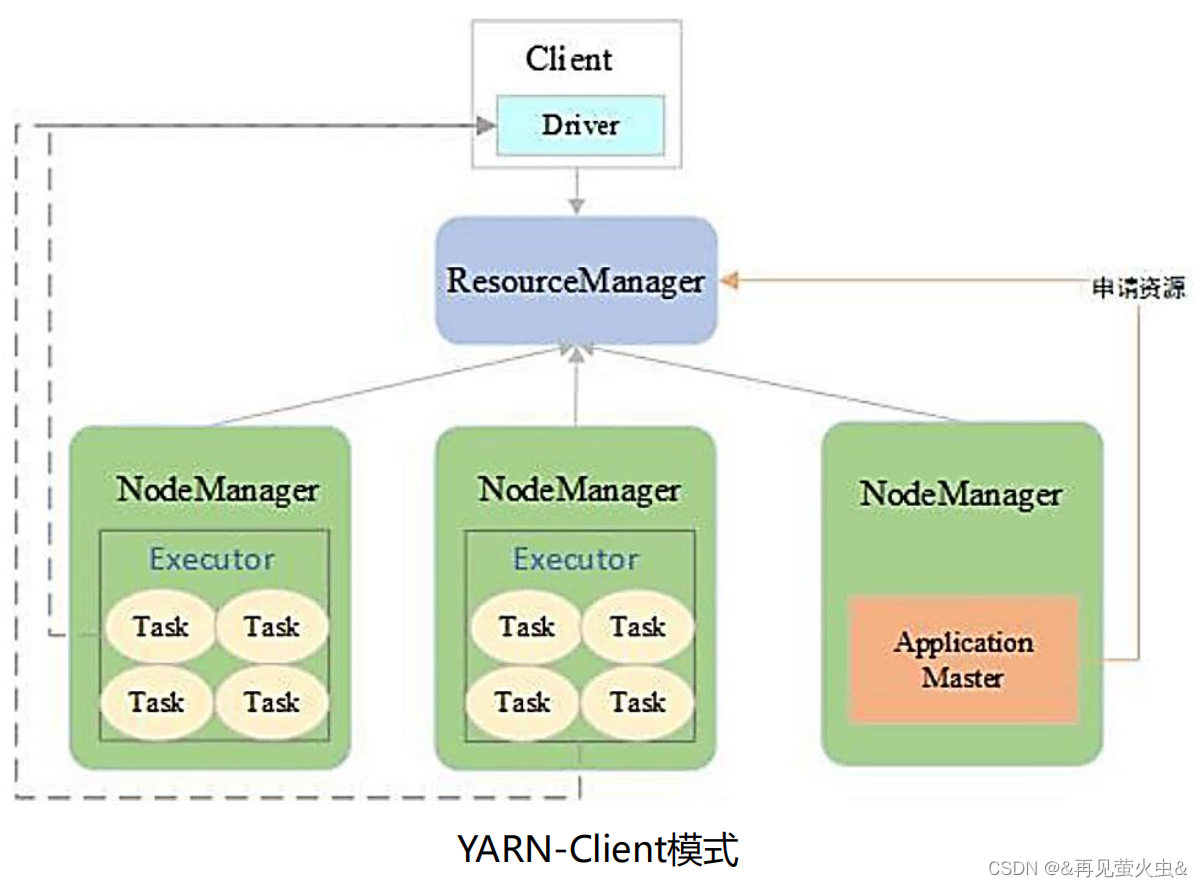
YARN-Client模式:适用于交互和调试
YARN-Cluster模式:适用于生产环境
区别在于Driver位置。Driver放在Client主要便查看日志,便于调试。

2.3 运行过程
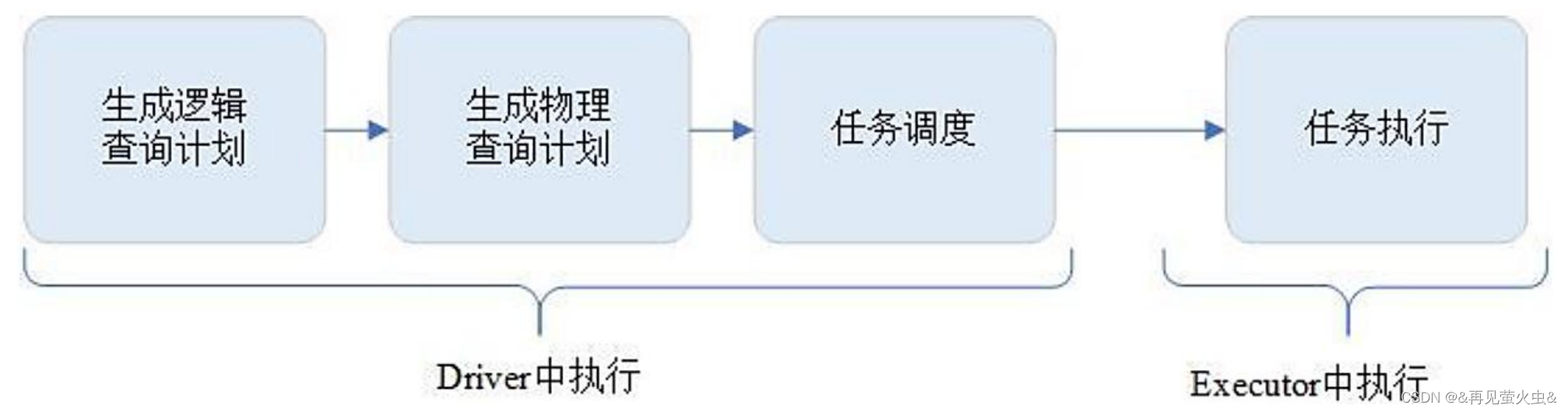
1,生成逻辑计划
2,生成物理计划
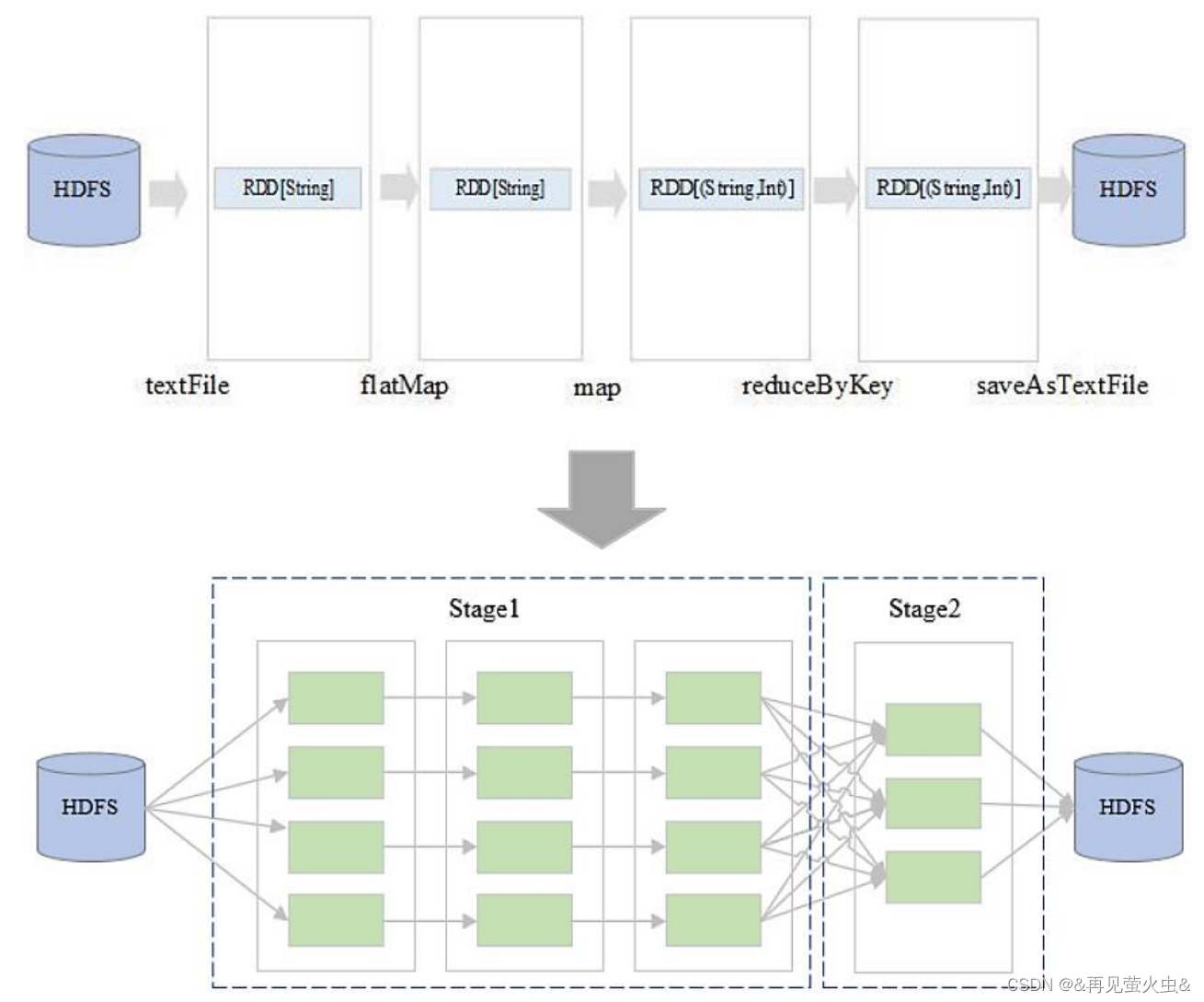
3,任务调度与执行
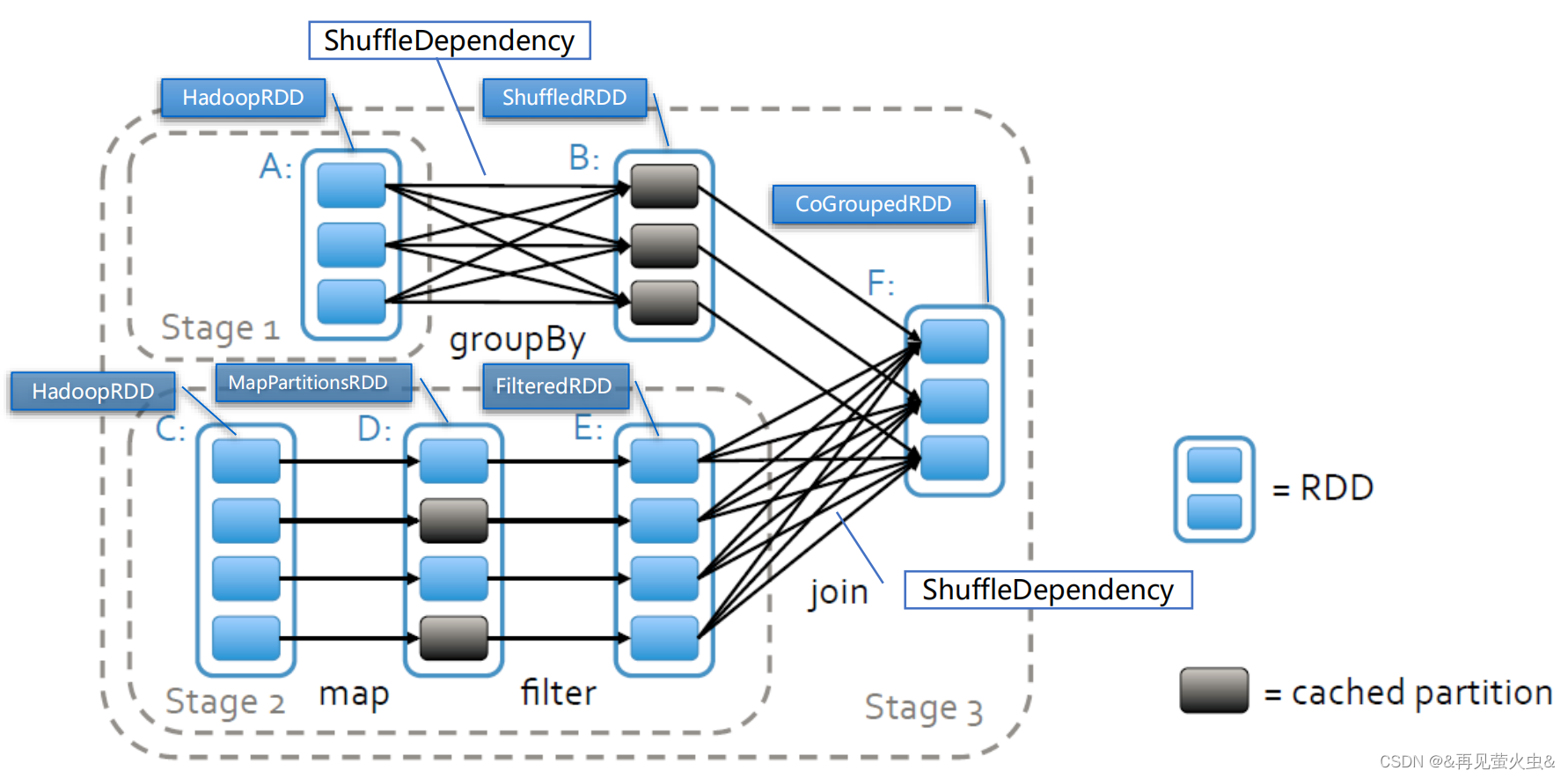
2.4 DAG任务规划与调度
DAG(Directed Acyclic Graph)
- 有向无环图DAG:一个有向图无法从任意顶点出发经过若干条边回到该点
- 受制于某些任务必须比另一些任务早执行的约束,Spark程序的内部执行逻辑可由DAG描述,节点代表任务,边代表任务间的依赖约束
DAGScheduler
- 根据任务的依赖关系建立DAG
- 根据依赖关系是否为宽依赖,即是否存在Shuffle,将DAG划分为不同的阶段(Stage)
- 将各阶段Task组成的TaskSet提交给TaskScheduler
TaskScheduler
- 负责任务调度
- 重新提交失败的Task
- 为执行速度慢的Task启动备用Task
-
相关阅读:
17---坐标移动
二分练习题
Unity布料系统_Cloth组件(包含动态调用相关)
java中的并发工具类
find方法和 findIndex方法的使用
测试与开发环境网址hosts配置
Redis作者谈Redis应用场景
大厂数仓专家实战分享:企业级埋点管理与应用
统信UOS技术开放日:四大领域全面接入AI大模型能力
MySQL中各类型文件详解
- 原文地址:https://blog.csdn.net/qq_41528502/article/details/126086471