-
深度学习论文精读[9]:PSPNet

场景解析(scene parsing)是语义分割的一个重要应用方向,区别于一般的语义分割任务,场景解析需要在复杂的自然图像场景下对更庞大的物体类别的每一个像素进行分类,场景解析在自动驾驶和机器人感知等方向应用广泛。但由于自然场景的复杂性、语义标签的多样性以及目标物体的多变性,对于场景解析问题的研究一直存在诸多困难。
场景解析一般基于FCN和空洞卷积网络来进行结构设计,后续的改进方案主要有两个方向,一种是多尺度特征集成,学界普遍的观点认为深层特征能够提取图像的语义信息但缺乏定位信息,将多尺度的特征集成起来能够显著提升模型效果。另一个则是结合图模型的结构预测,比如说使用CRF进行后处理来优化图像分割结果,这些改进方案虽然在一定程度上都能缓解像素定位问题,但对于更为复杂的图像场景仍然效果有限。将全局信息加入到语义分割网络中的设计也有很多研究提到,比如上一节的ParseNet,通过给FCN补充全局平均池化来提升分割效果。但这种全局信息不足以在一些复杂的场景解析数据集上体现效果,比如包括150个语义类别的ADE20K数据集。总结来看,FCN对于复杂的场景解析存在如下三个问题:
(1)像素上下文关系不匹配。在语义分割中,图像上下文信息非常重要,不同的像素类别之间往往存在着共现的视觉模式,比如说飞机通常只会出现在跑道上或者空中,而不会出现在马路上,所以飞机和跑道以及天空这三个对象之间存在着共现模式。
(2)语义标签的混淆。ADE20K数据集中有大量语义相近的类别,比如高山与丘陵、建筑与摩天大楼等。FCN在这种容易混淆的类别上很难做出准确的判断。
(3)小目标类别预测困难。在场景解析中,目标物体可以是任意大小,所以有时候对于小目标物体预测效果就很差,比如说对路灯和广告牌的识别,FCN表现就非常不好。
针对上述问题,相关学者基于空间金字塔池化(Spatial Pyramid Pooling, SPP)提出了一种更为广泛的、基于不同图像区域的全局上下文信息集成结构:PSPNet,提出PSPNet的论文为Pyramid Scene Parsing Network,是多尺度上下文结构方向的一个重要的网络设计。PSPNet网络结构如图1所示。
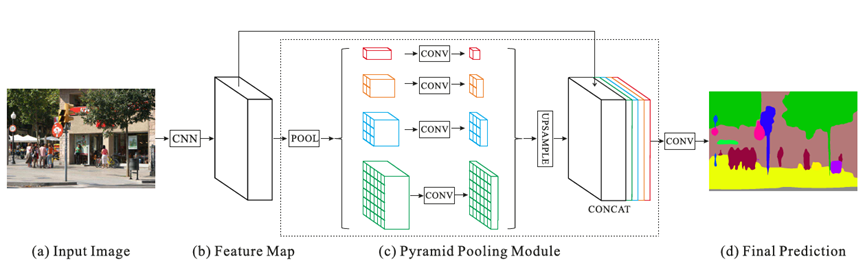
可以看到,将输入图像(a)经过CNN网络提取之后的特征图(b)送入到一个金字塔池化模块(Pyramid Pooling Module,PPM),在该模块中(c),使用四种不同尺度的全局池化(1*1、2*2、3*3和6*6)进行下采样并结合1*1卷积来生成降维后的上下文信息表征。然后直接使用双线性插值对低分辨率的特征图进行上采样,并与阶段(b)的特征图进行连接,形成最终的全局金字塔池化特征,最后再进行一组卷积后形成最终的语义分割预测结果(d)。基于上述结构,PSPNet对于场景解析任务能够提供有效的全局上下文先验信息,PPM相较于直接的全局池化,能够收集多尺度的信息表征,并且在计算开销上相比于FCN也增加不多。此外PSPNet训练时为防止梯度消失还添加了辅助损失函数作为一种深监督机制。
PSPNet在ADE20K、PASCAL VOC 2012以及Cityscapes数据集上分别进行了测试,均能达到当时SOTA的分割水平。另外也在辅助损失函数和预训练模型等方面做了充分的消融实验(ablation study)。PSPNet在ADE20K数据集上的一组测试效果如图2所示。在三张测试图像上,FCN不能够捕捉图像上下文关系(将第一张图像中水面上的船只识别为汽车),但PSPNet均能够得到很好的分割效果。

下述代码给出了PSPNet网络结构的一个简单实现流程。
- ### 定义PPM模块类
- class _PyramidPoolingModule(nn.Module):
- def __init__(self, in_dim, reduction_dim, setting):
- super(_PyramidPoolingModule, self).__init__()
- self.features = []
- for s in setting:
- self.features.append(nn.Sequential(
- nn.AdaptiveAvgPool2d(s),
- nn.Conv2d(in_dim, reduction_dim, kernel_size=1, bias=False),
- nn.BatchNorm2d(reduction_dim, momentum=.95),
- nn.ReLU(inplace=True)
- ))
- self.features = nn.ModuleList(self.features)
- # PPM前向计算流程
- def forward(self, x):
- x_size = x.size()
- out = [x]
- for f in self.features:
- out.append(F.upsample(f(x), x_size[2:], mode='bilinear'))
- out = torch.cat(out, 1)
- return out
- ### 定义PSPNet类
- class PSPNet(nn.Module):
- def __init__(self, num_classes, use_aux=True):
- super(PSPNet, self).__init__()
- self.use_aux = use_aux
- # 使用ResNet101作为预训练模型
- resnet = models.resnet101()
- self.layer0 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool)
- self.layer1, self.layer2, self.layer3, self.layer4 = resnet.layer1, resnet.layer2, resnet.layer3, resnet.layer4
- for n, m in self.layer3.named_modules():
- if 'conv2' in n:
- m.dilation, m.padding, m.stride = (2, 2), (2, 2), (1,1)
- elif 'downsample.0' in n:
- m.stride = (1, 1)
- for n, m in self.layer4.named_modules():
- if 'conv2' in n:
- m.dilation, m.padding, m.stride = (4, 4), (4, 4), (1,1)
- elif 'downsample.0' in n:
- m.stride = (1, 1)
- self.ppm = _PyramidPoolingModule(2048, 512, (1, 2, 3, 6))
- self.final = nn.Sequential(
- nn.Conv2d(4096, 512, kernel_size=3, padding=1, bias=False),
- nn.BatchNorm2d(512, momentum=.95),
- nn.ReLU(inplace=True),
- nn.Dropout(0.1),
- nn.Conv2d(512, num_classes, kernel_size=1)
- )
- # 深监督辅助损失
- if use_aux:
- self.aux_logits = nn.Conv2d(1024, num_classes, kernel_size=1)
- initialize_weights(self.aux_logits)
- initialize_weights(self.ppm, self.final)
- ### PSPNet前向计算流程
- def forward(self, x):
- x_size = x.size()
- x = self.layer0(x)
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- if self.training and self.use_aux:
- aux = self.aux_logits(x)
- x = self.layer4(x)
- x = self.ppm(x)
- x = self.final(x)
- if self.training and self.use_aux:
- return F.upsample(x, x_size[2:], mode='bilinear'), F.upsample(aux, x_size[2:], mode='bilinear')
- return F.upsample(x, x_size[2:], mode='bilinear')
往期精彩:
-
相关阅读:
Android手机自动化测试工具有哪几种?
Flutter框架性泛学习系列之二、Flutter应用层(Application Layer)上-常用Widgets与简单动画
st语言【关键字】
设计模式:饿汉式和懒汉式单例模式(C++实现)以及日志系统的实现
R 语言 基于关联规则与聚类分析的消费行为统计
trace-bpfcc
23.Gateway 动态路由,负载均衡(springcloud)
【Java技术路线】7. 异常与调试
gitlab安装以及创建用户创建组,修改密码 邮箱配置 数据备份与恢复--保姆级教学!
8年资深测试,自动化测试常见问题总结,惊险避坑...
- 原文地址:https://blog.csdn.net/weixin_37737254/article/details/126093071
