-
一文掌握Ubuntu20.04深度学习环境搭建(显卡驱动、CUDA、CUDNN、NCCL、Pytorch、PaddlePaddle)
一、Ubuntu系统安装
1.1 制作U盘镜像并安装
- 准备烧录工具
首先从官网下载免费的win32diskimager并安装,这个工具用来烧录ubuntu镜像到U盘。
- 下载Ubuntu镜像
下载Ubuntu20.04对应的iso镜像。
- 准备空U盘
准备好一个空U盘(U盘t按照FAT32格式进行格式化),至少大于8G。
- 烧录
打开win32diskmager,按照下图所示写入镜像(选择iso镜像和对应的设备盘符,然后单击“写入”即可):
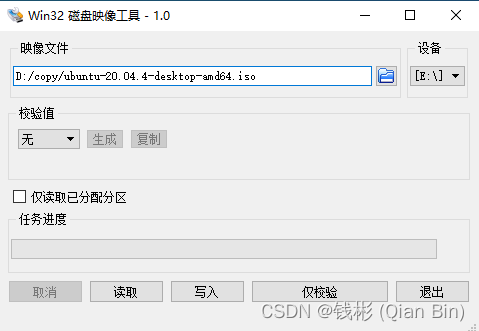
完成后U盘启动盘就准备好了。(如果想要删除U盘内容,可以使用DiskGenius来重新格式化)- 安装
插上U盘,开机进入系统bios,将U盘设为启动盘,然后按照提示步骤进行Ubuntu20.04的安装(注意:安装时推荐使用默认的英文进行安装,不要选择简体中文,等系统装好并更新后再添加中文输入法)。
安装时只勾选正常安装选项即可,其它第三方图形和硬件驱动等复选框可以不用勾选。
1.2 安装make、g++、cmake
下面安装一些开发必要的编译软件。
首先更新下系统软件源:
sudo apt-get update- 1
然后下面开始依次安装make、g++、cmake
- make
通过以下命令安装make:
sudo apt-get install make- 1
执行完后,可以通过下面的命令来查看make版本:
make -v- 1
- g++
通过以下命令安装g++:
sudo apt-get install g++- 1
执行完后,可以通过下面的命令来查看g++版本:
g++ -v- 1
- cmake
同样的,使用下面的命令进行安装:
sudo apt-get install cmake- 1
然后使用下面的命令查看版本:
cmake --version- 1
1.3 安装中文输入法
本文推荐使用百度输入法。如下图所示:
选择Ubuntu&Deepin下载。首先安装容器fcitx:
sudo apt-get install fcitx- 1
然后安装中文支持包:
打开setting-> Region & Lannguage -> InputSource下的Manage installation Language
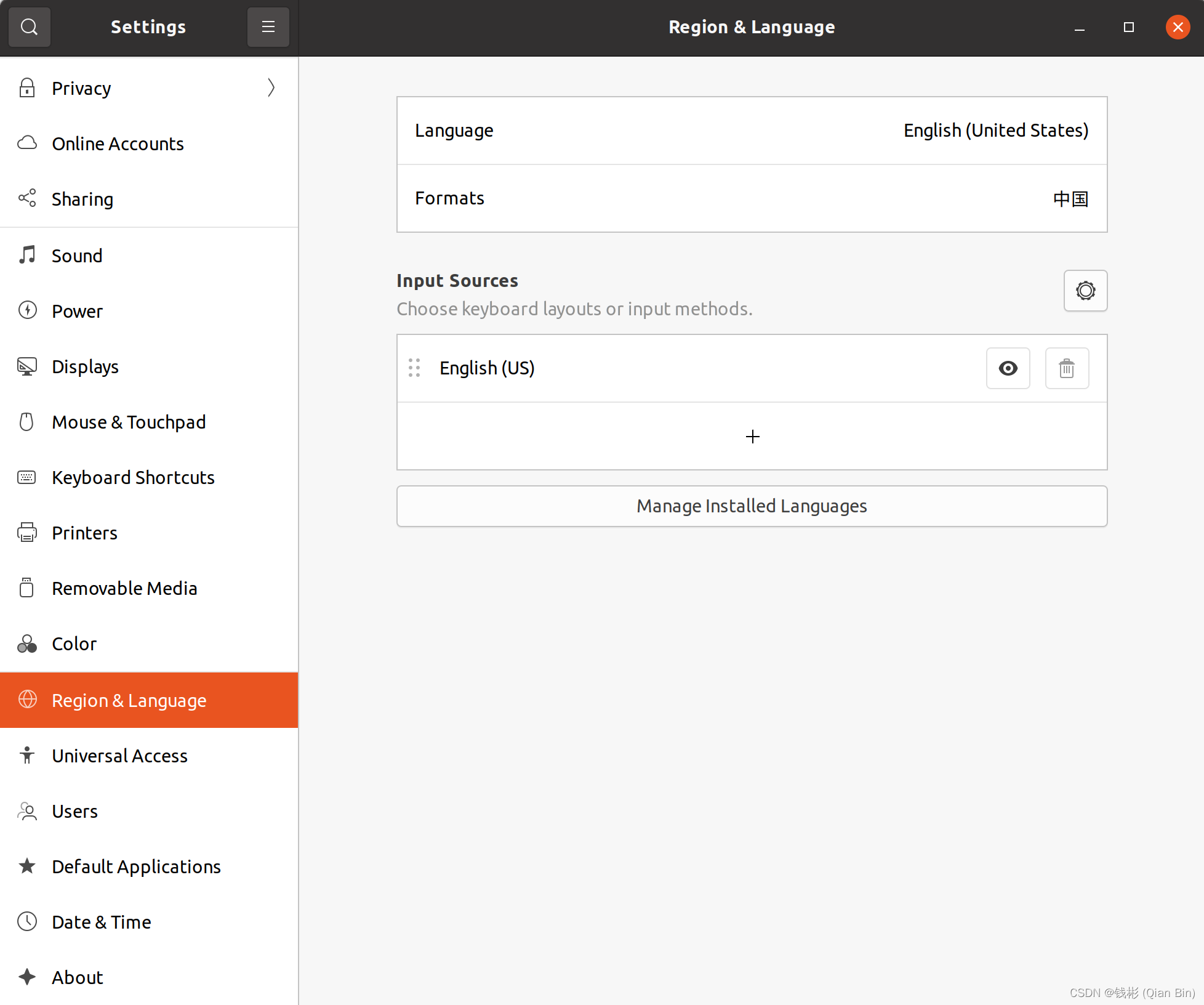 点击Installation/ Remove Language,勾选"Chinese simplified",并点击应用.
点击Installation/ Remove Language,勾选"Chinese simplified",并点击应用.keyboard input method system选择:fcitx
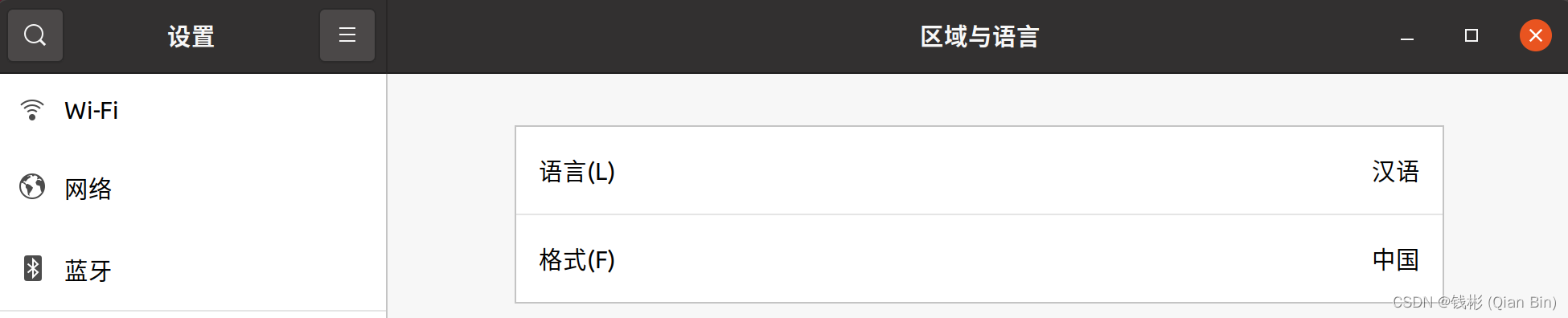
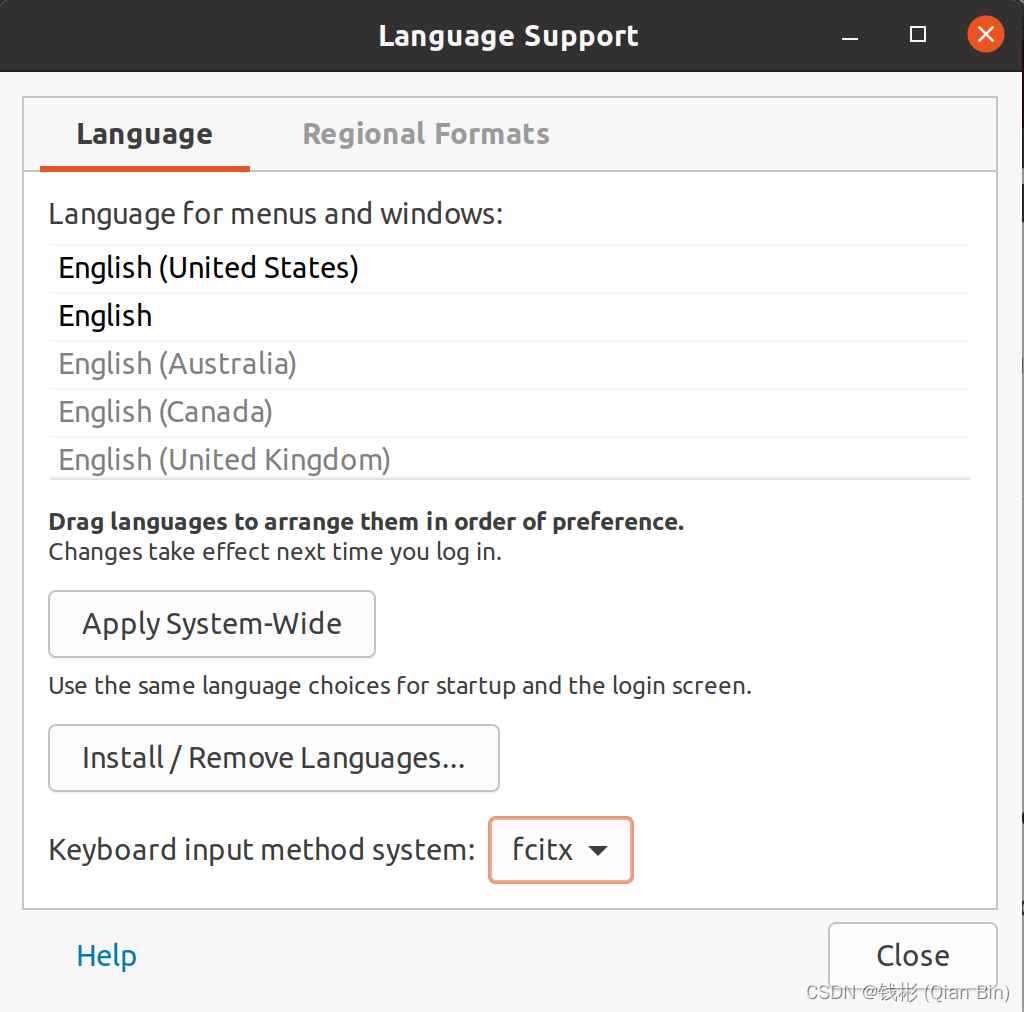 点击"Apply System-Wide"。然后回到区域与语言设置界面,将格式切换为“中国”。此时会等待60多秒时间,并且会退出当前用户。
点击"Apply System-Wide"。然后回到区域与语言设置界面,将格式切换为“中国”。此时会等待60多秒时间,并且会退出当前用户。
 然后需要重新登录,登录后会发现系统已经切换成中文的了。
然后需要重新登录,登录后会发现系统已经切换成中文的了。接下来正式安装输入法。
首先通过命令行更新系统:
sudo apt-get update- 1
然后通过命令行安装fcitx、qt:
sudo apt-get install fcitx-bin fcitx-table fcitx-config-gtk fcitx-frontend-all- 1
sudo apt-get install qtcreator qml-module-qtquick-controls2- 1
最后通过cd命令切换到下载的输入法安装包根目录,然后通过命令行安装百度输入法:
sudo dpkg -i fcitx-baidupinyin.deb- 1
安装完成后重启系统。
重启后会自动启动百度输入法配置界面,按照默认配置即可。
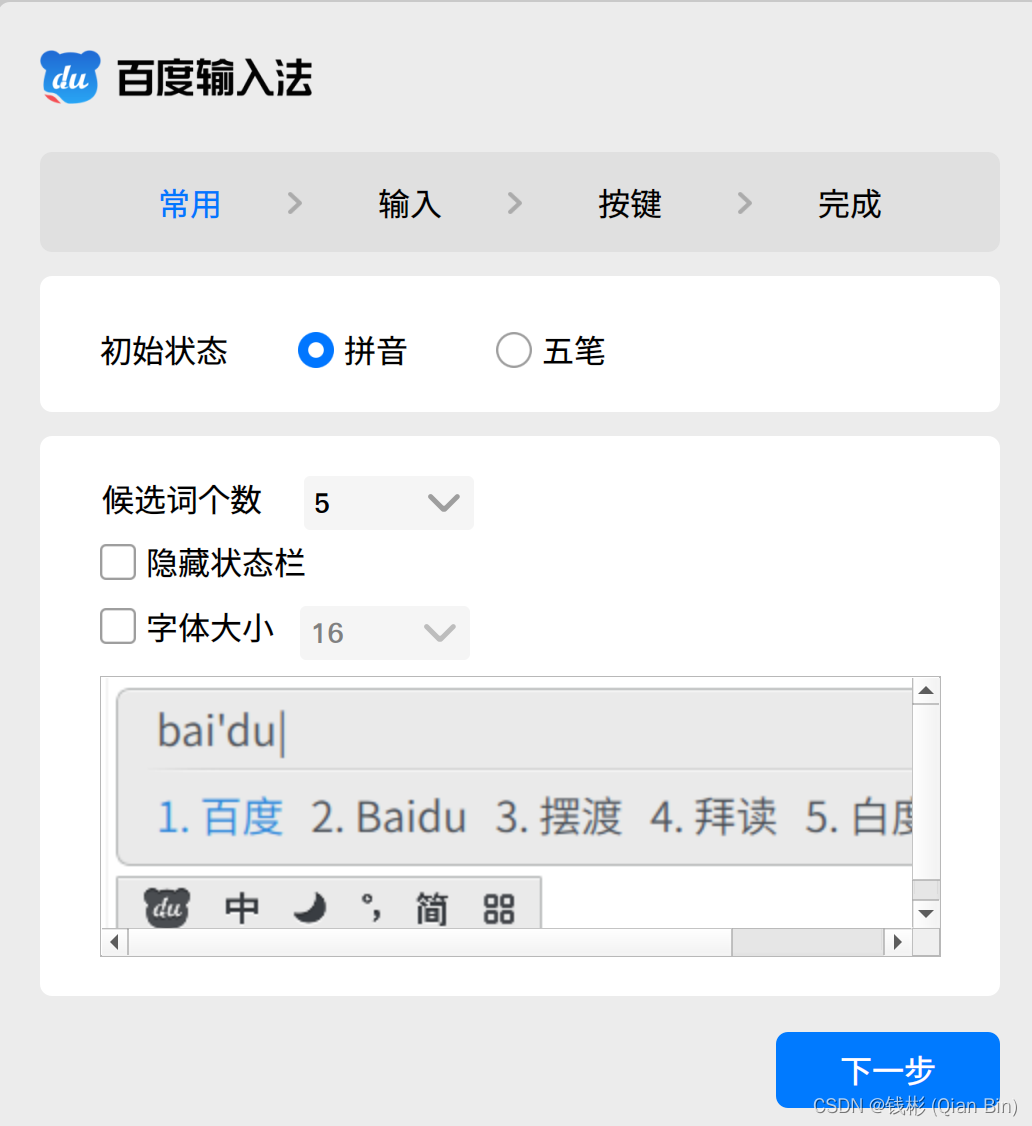 接下来点击顶部右侧输入法图标,然后选择输入法配置:
接下来点击顶部右侧输入法图标,然后选择输入法配置:
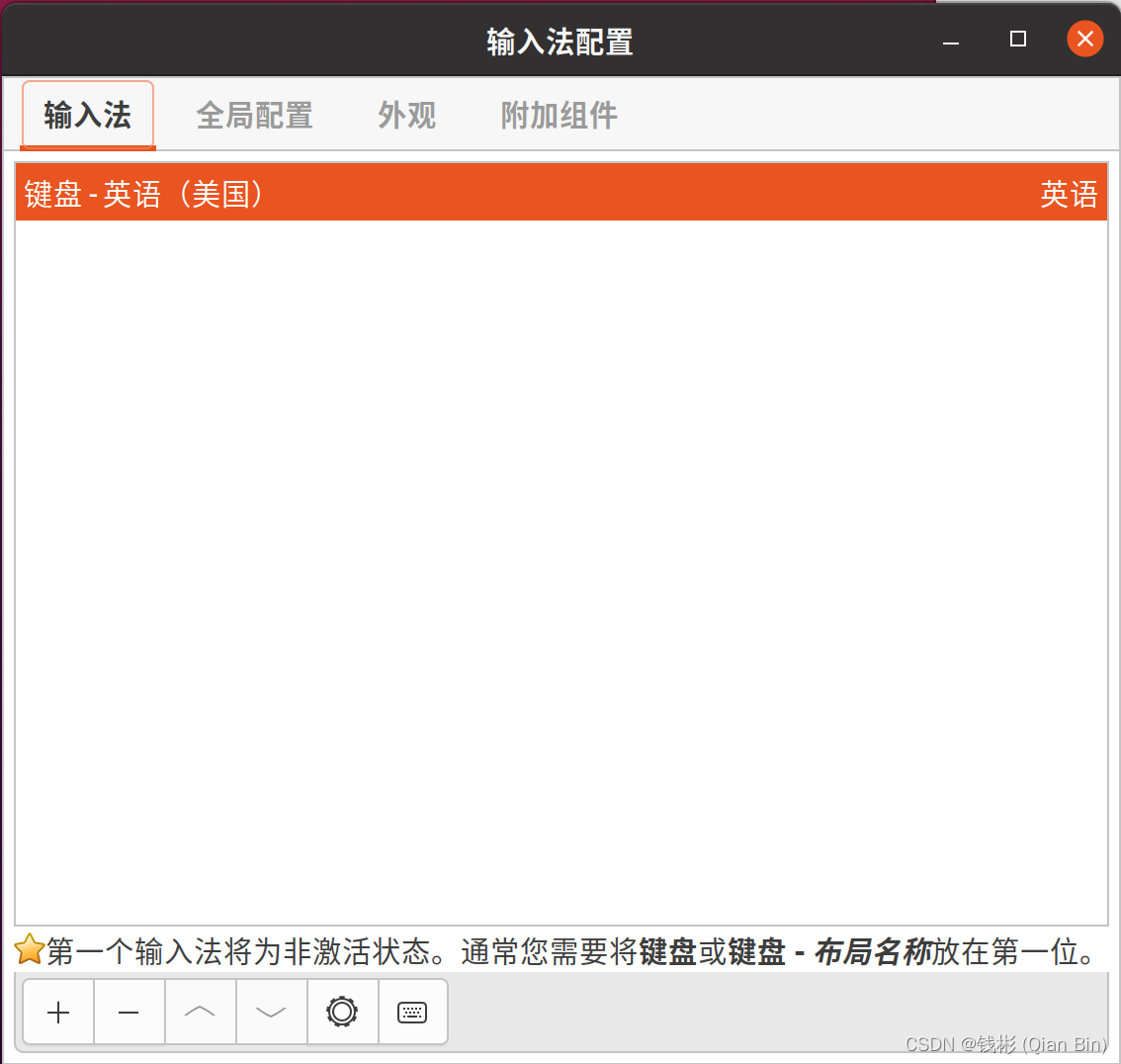 点击“+”符号添加百度拼音输入法,如下图所示:
点击“+”符号添加百度拼音输入法,如下图所示:
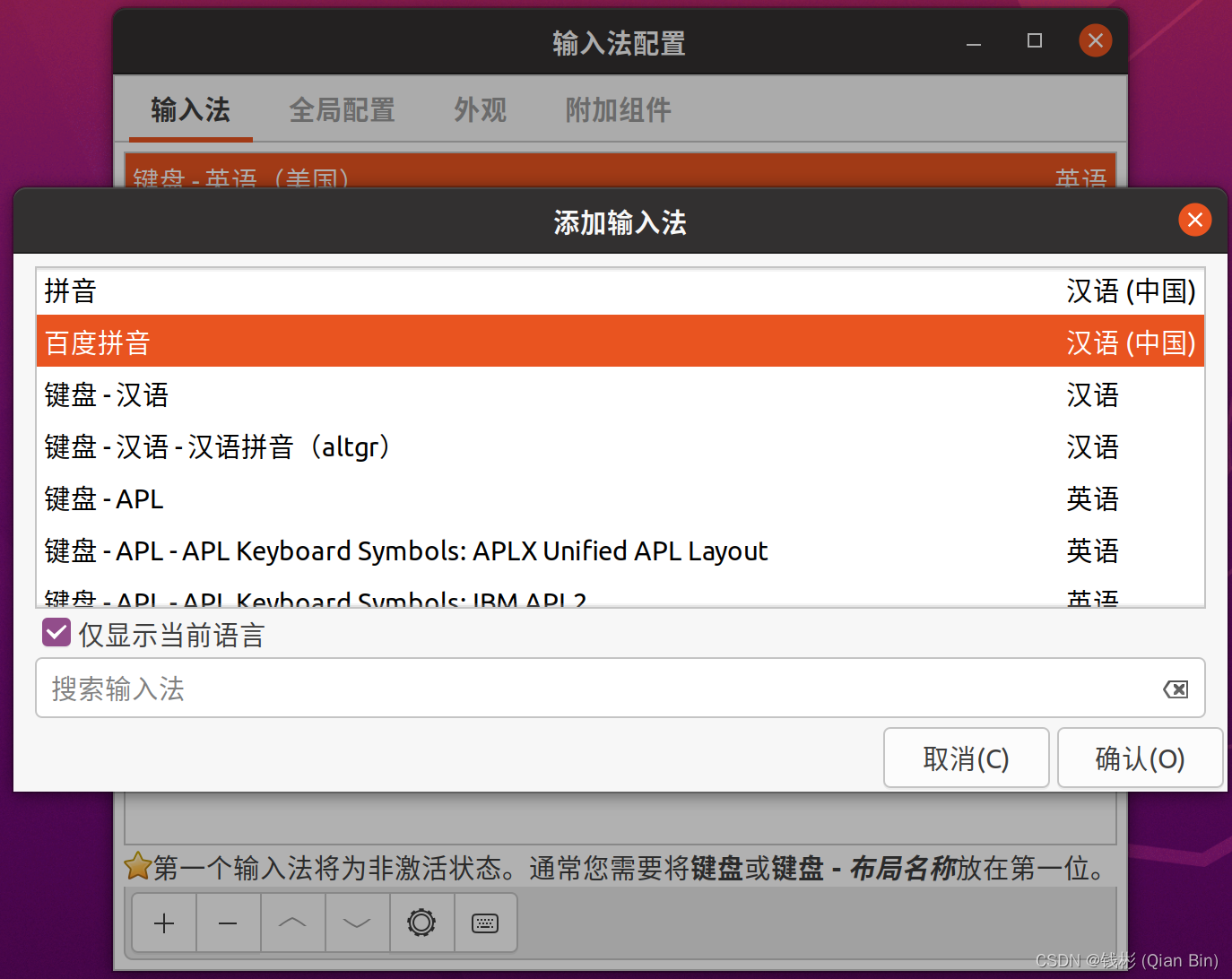 然后将百度输入法调整到最顶部:
然后将百度输入法调整到最顶部:
 配置完就可以正常使用了。
配置完就可以正常使用了。如果想要卸载百度输入法,可以使用下面的命令实现:
sudo dpkg --purge remove fcitx-baidupinyin:amd64- 1
1.4 安装VS Code
为了后面方便的调试Python代码,我们首先来装一下对应的IDE:VS Code。
去官网下载后进行安装:
sudo dpkg -i visual_code_1.69.2-1658162013_amd64.deb- 1
二、深度学习环境安装
2.1 切换Python版本
在终端输入:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150- 1
即可切换到python3,此时可以打开终端输入python验证下,正常情况可以进入Python代码编辑环境,如下图所示:
 默认Ubuntu20.04安装的python版本为3.8.10。后面我们再执行相关python脚本的时候只需要使用python命令了,而不再需要使用python3。
默认Ubuntu20.04安装的python版本为3.8.10。后面我们再执行相关python脚本的时候只需要使用python命令了,而不再需要使用python3。2.2 安装英伟达显卡驱动
首先需要到NAVIDIA官网去查自己的电脑是不是支持GPU运算。
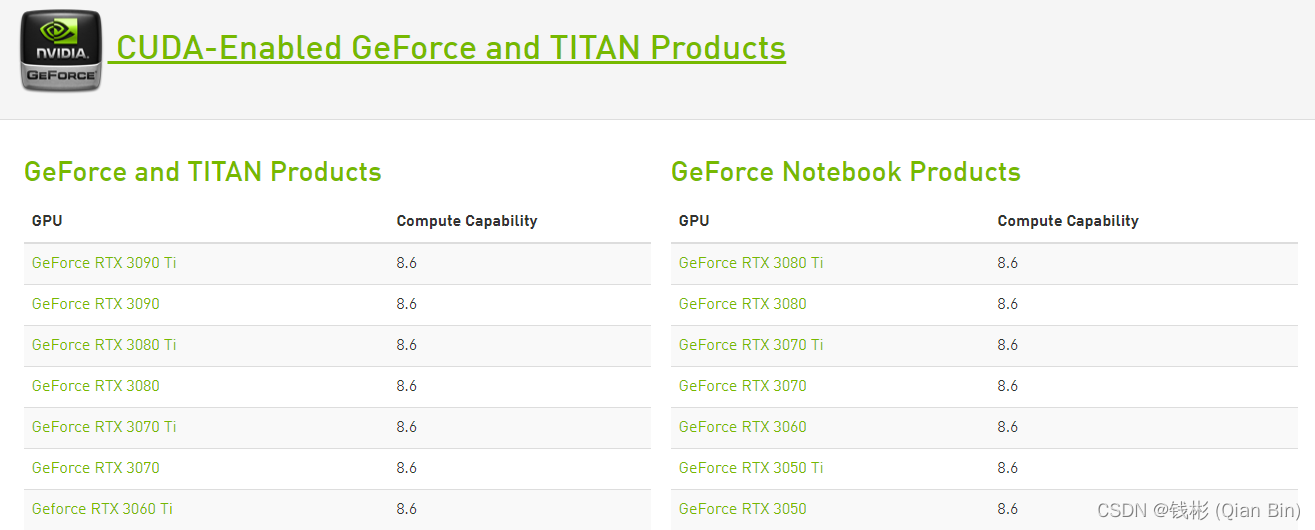
网址是:CUDA GPUs | NVIDIA Developer。打开后的界面大致如下,只要里边有对应的型号就可以用GPU运算,并且每一款设备都列出来相关的计算能力(Compute Capability)。
本文使用Geforce RTX 3090显卡,对应计算能力是8.6。
 明确了显卡性能后,接下来就开始在Ubuntu20.04中安装对应的显卡驱动。
明确了显卡性能后,接下来就开始在Ubuntu20.04中安装对应的显卡驱动。首先,检测NVIDIA图形卡和推荐的驱动程序的模型,在终端输入:
ubuntu-drivers devices- 1
输出结果如下:
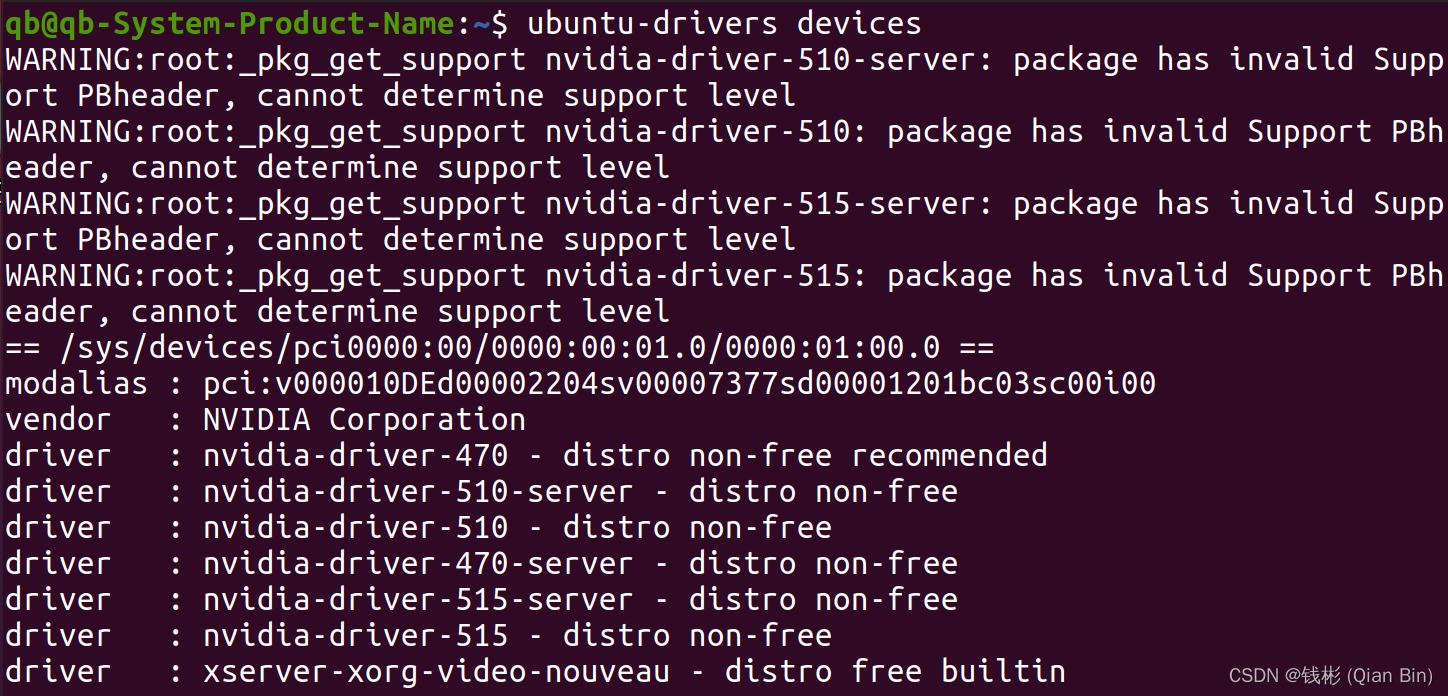 从中可以看到对应的推荐的驱动包。
从中可以看到对应的推荐的驱动包。这里尤其需要注意,建议使用自动安装方法来安装驱动,不推荐先官网下载驱动再手动安装的方式(有可能造成重启后黑屏现象,笔者在此处吃了不少亏)。
具体可以使用下面的命令:
sudo ubuntu-drivers autoinstall- 1
安装完成后重启系统,然后在终端中输入命令:
nvidia-smi- 1
可以看到下图所示效果:
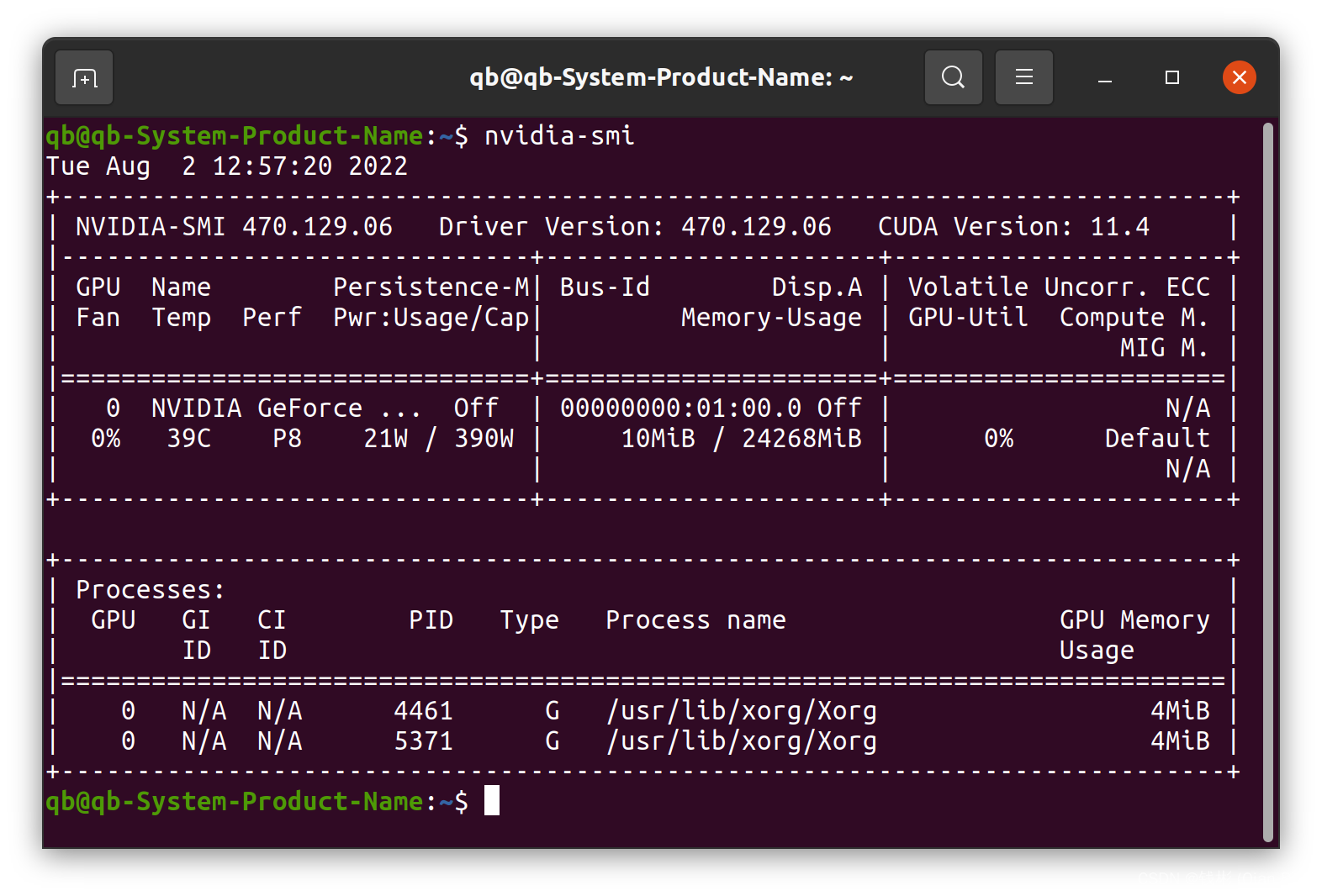 可以看到当前显卡显存为24G左右,已用10M,当前使用率0%。
可以看到当前显卡显存为24G左右,已用10M,当前使用率0%。重要!!! 在上图右上角我们看到“CUDA Version:11.4”,这个表明对于这款显卡,我们后面要装的CUDA版本最高不能超过11.4,这条信息很重要。
2.3 明确CUDA版本需求
本文最终的目的是装好深度学习环境,这里指的是最终能够正常的使用pytorch和paddlepaddle。这两款是当前使用比较多的深度学习框架,pytorch侧重于科研和模型验证,paddlepaddle更适合工业级深度学习开发部署(当然也可以使用tensorflow)。
为了能够使用他们,我们接下来需要按照顺序安装CUDA、cuDNN、nccl、paddlepaddle、pytorch。
在正式安装前我们首先要来确定当前的版本一致性,否则装到后面就会发现各种版本问题了。
前面2.2节我们装好了对应显卡的驱动,并且我们通过nvidia-smi命令知道了当前驱动最高适配到CUDA11.4,因此,我们后面安装的CUDA版本不能超过11.4。
接下来我们先看paddlepaddle和pytorch官网目前稳定版所支持的cuda。
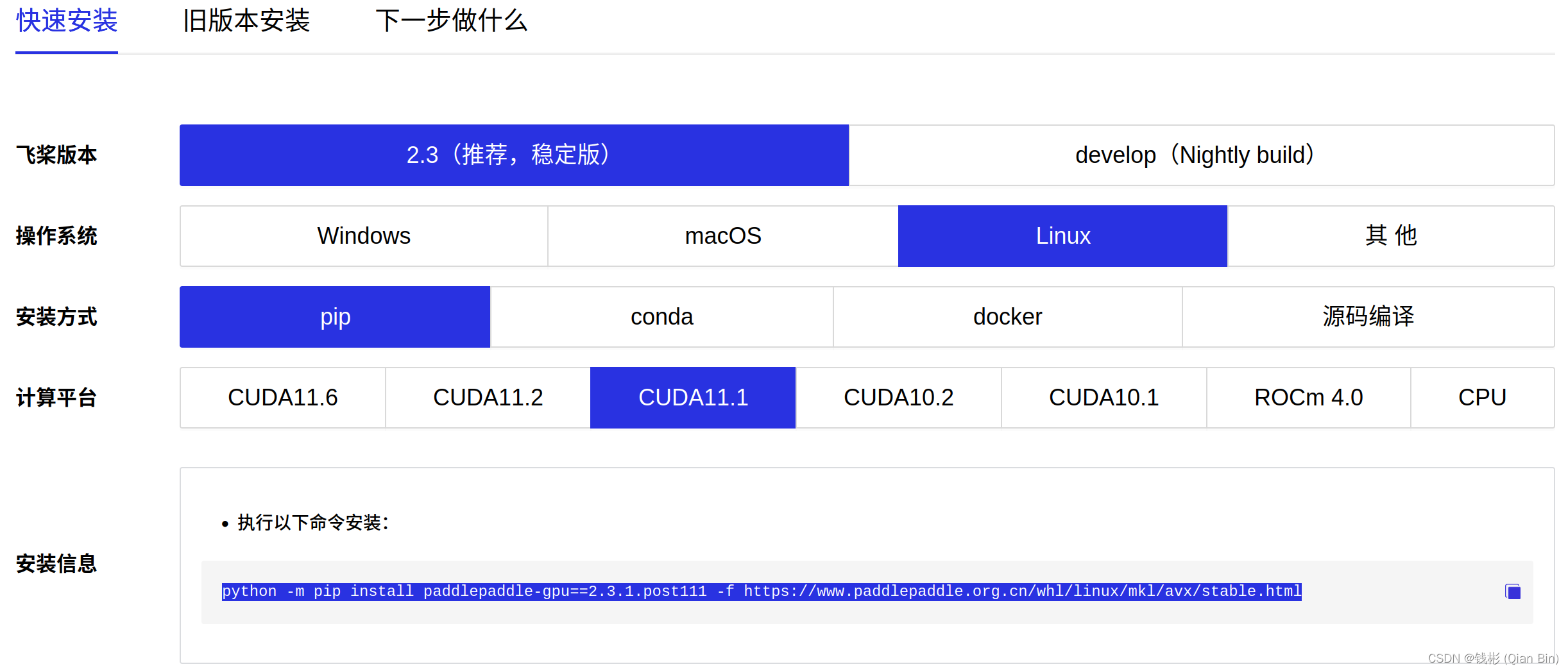
paddlepaddle目前官网安装界面如下图所示:
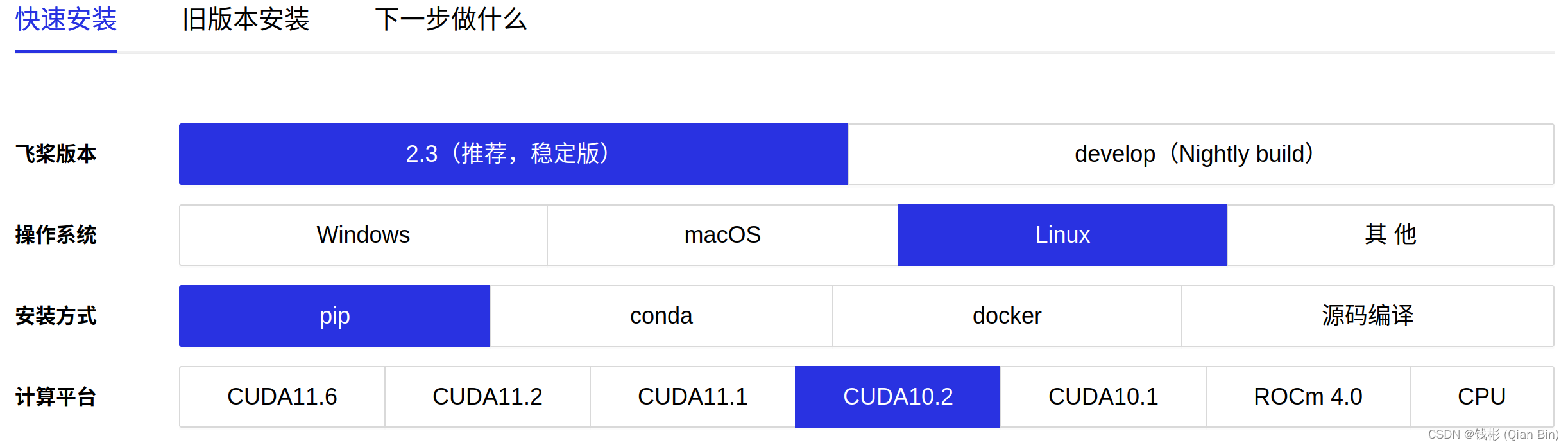 我们需要记住当前稳定版适配的CUDA类型。
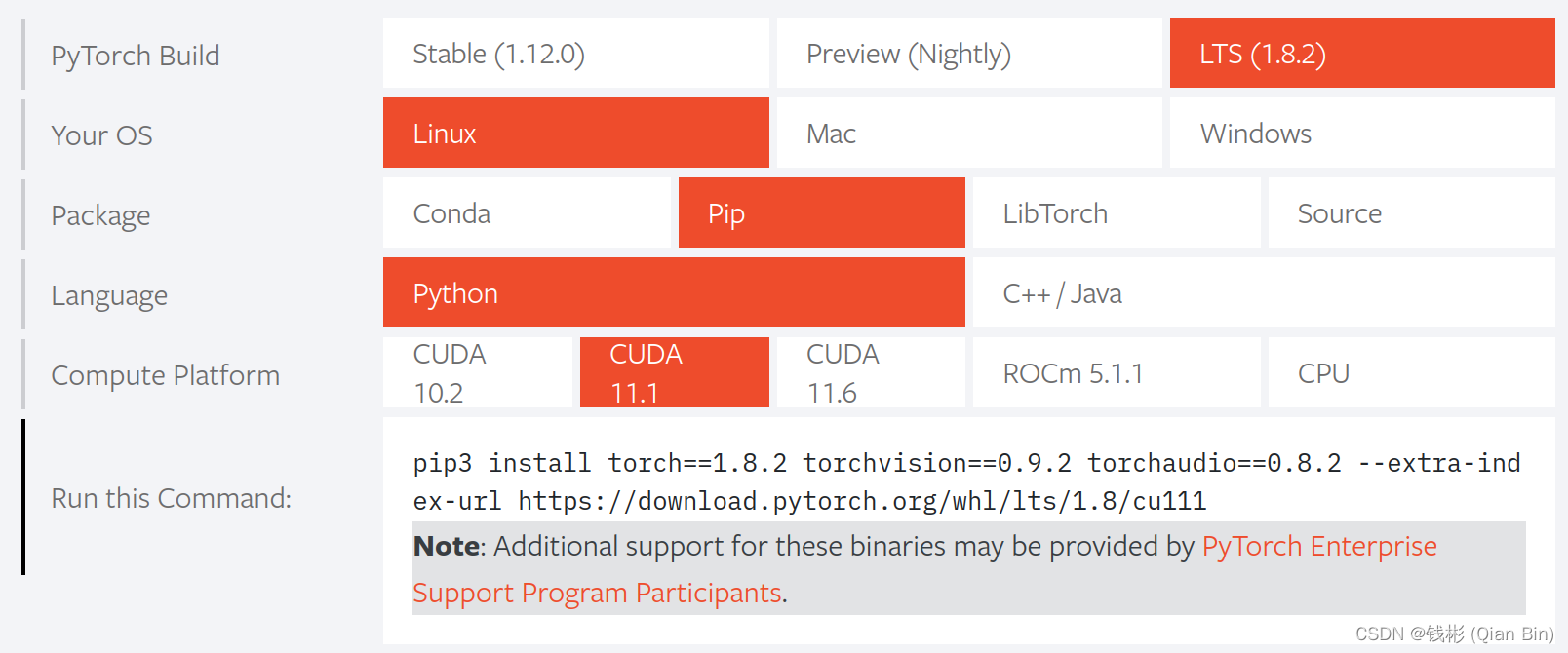
我们需要记住当前稳定版适配的CUDA类型。接下来我们再打开pytorch官网安装界面:
 可以发现当前最新版pytorch和paddlepaddle重叠的cuda版本分别为cuda10.2、11.6。但是11.6版本超过了当前本机显卡驱动所支持的版本,因此不合适。而cuda10.2这里也不推荐,因为pytorch对3090ti显卡的支持必须要使用cuda11.x版本,如果装了cuda10.2,后面pytorch训练会出现报错。那么这里怎么办呢?
可以发现当前最新版pytorch和paddlepaddle重叠的cuda版本分别为cuda10.2、11.6。但是11.6版本超过了当前本机显卡驱动所支持的版本,因此不合适。而cuda10.2这里也不推荐,因为pytorch对3090ti显卡的支持必须要使用cuda11.x版本,如果装了cuda10.2,后面pytorch训练会出现报错。那么这里怎么办呢?我们可以选择LTS(1.8.2)版本,也就是pytorch的官方长期稳定版:
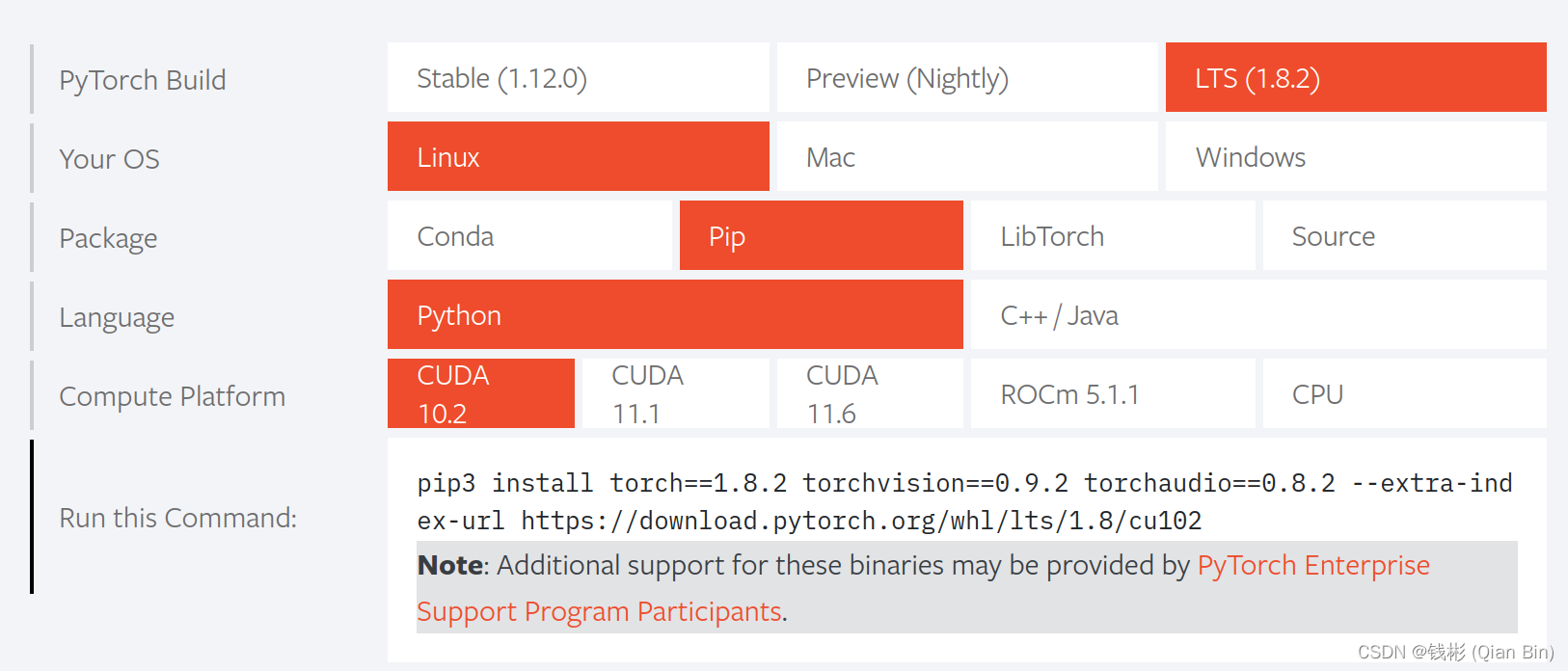 对于这个版本,我们就发现很明显,CUDA11.1就是两个框架都支持的了,并且本机驱动也支持。所以我们最终选定CUDA11.1。
对于这个版本,我们就发现很明显,CUDA11.1就是两个框架都支持的了,并且本机驱动也支持。所以我们最终选定CUDA11.1。在安装CUDA时,我们一定要结合自己的机器情况以及我们最终的目标框架需求来安装,否则胡乱安装一个版本很容易出问题。尤其如果我们需要安装多个深度学习框架的时候尤其要注意CUDA版本一致性问题。
2.4 安装CUDA
首先在英伟达官网下载cuda11.1进行安装即可。
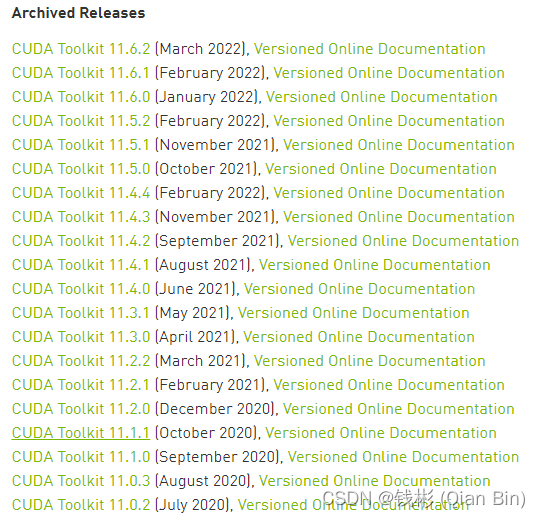
这里选择CUDA Toolkit 11.1.1,单击进入下载页面。然后按照下图所示进行选择:

按照runfile(local)安装的方式简单,只需要在终端输入上述两条NVIDIA推荐的命令就好了。为了提高下载速度,可以先在windows上使用迅雷将这个run文件下载下来,然后再拷贝到Ubuntu服务器上进行安装,安装命令如下:
sudo sh cuda_11.1.1_455.32.00_linux.run- 1
在安装过程中会跳出一些选择界面,首先是 Abort和continue,选择continue。然后输入accept后出现CUDA Installer,因为已经安装过NVIDIA的驱动了,而弹出的CUDA Installer 自带显卡驱动,所以这一步按空格去掉安装显卡驱动的选项(这一步很重要,如果不去掉可能会引起驱动冲突,导致最后pytorch配置完后,torch.cuda.is_available()=False),然后选择install,就好了。
最后一步,配置环境变量:
在终端输入下面的命令打开文件:
gedit ~/.bashrc- 1
在文件结尾输入以下语句,保存:
export PATH=/usr/local/cuda-11.1/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}- 1
- 2
上面语句需要结合自己安装的CUDA版本对照着修改即可,此处是CUDA11.1版本。
最后,更新环境变量配置
source ~/.bashrc- 1
至此cuda安装完成,输入nvcc -V命令查看cuda信息。
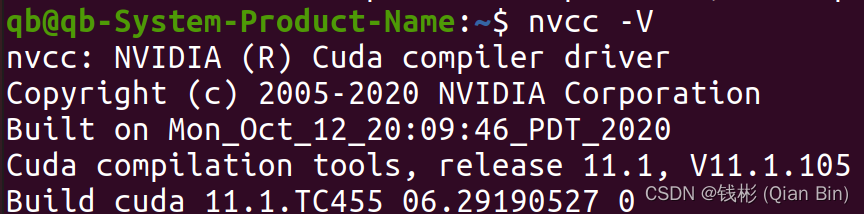 如果没有输出,证明没有安装成功,此时基本只能重装系统,想想哪里和上面的步骤不一致,然后按上面的过程再来一遍。
如果没有输出,证明没有安装成功,此时基本只能重装系统,想想哪里和上面的步骤不一致,然后按上面的过程再来一遍。2.5 安装CUDNN
安装CUDNN的过程相对比较简单。上官网进行下载。首次登录需要邮箱注册账号并登录。
一定要按照cuda的型号选择cudnn的型号,本文前面安装的是CUDA11.1,因此这里选择适配的CUDNN8.0.5进行下载安装。

单击后选择cuDNN Library for Linux(x86_64)下载安装包,注意下载完后将文件复制到电脑的home文件夹下。然后打开终端输入类似下面的命令进行解压并拷贝安装:
tar -zxvf cudnnXXXXXXXXXX.tgz cp cuda/lib64/* /usr/local/cuda-11.1/lib64/ cp cuda/include/* /usr/local/cuda-11.1/include/- 1
- 2
- 3
注意,将上面的版本替换为你自己的版本。到这里就安装完成了。其实,cuDNN的安装本质上就是复制一堆的文件到CUDA中去。
我们可以使用如下的命令查看cuDNN的信息:
cat /usr/local/cuda-11.1/include/cudnn_version.h | grep CUDNN_MAJOR -A 2- 1
注意:根据自己的cuda版本将上面cuda后面的数字进行更改。
正常输出如下所示:
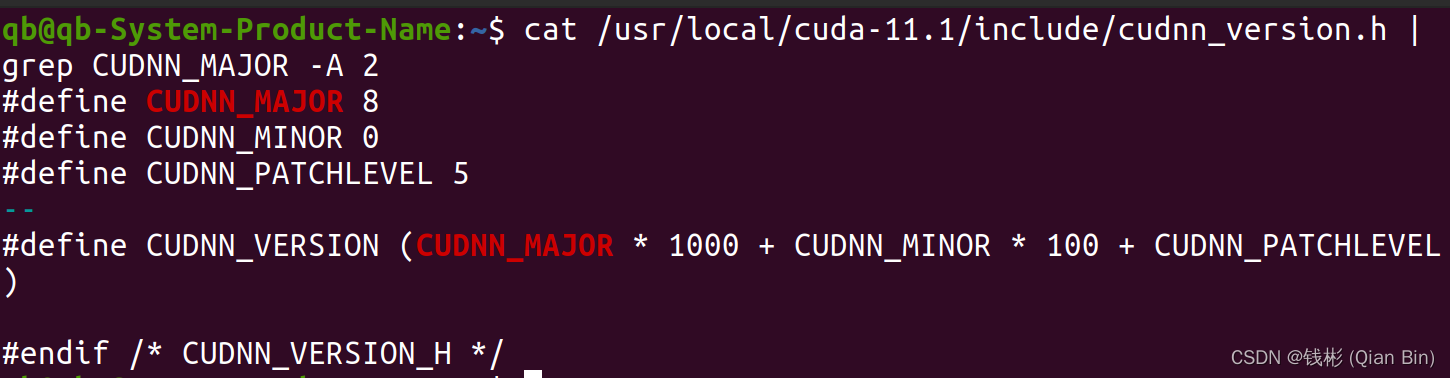 CUDN + cuDNN安装完成,我们可以监控一下gpu状态:
CUDN + cuDNN安装完成,我们可以监控一下gpu状态:watch -n 1 nvidia-smi- 1
如果能有输出,就证明cuda和cudnn能正确匹配。
2.6 安装NCCL
由于深度学习分布式训练需要nccl支持,因此本小节来安装nccl。
nccl 下载链接:https://developer.nvidia.com/nccl/nccl-legacy-downloads (与cudnn相似,需要注册登录后才能下载) 需要注册登录后 本人选择的是:NCCL 2.8.4, for CUDA 11.1。
针对本文环境,使用下面的命令来安装:
sudo dpkg -i nccl-local-repo-ubuntu2004-2.8.4-cuda11.1_1.0-1_amd64.deb sudo apt update sudo apt install libnccl2=2.8.4-1+cuda11.1 libnccl-dev=2.8.4-1+cuda11.1- 1
- 2
- 3
2.7 安装PaddlePaddle
这里参照官网进行安装即可:
 具体命令如下:
具体命令如下:python -m pip install paddlepaddle-gpu==2.3.1.post111 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html- 1
最后进行验证。
使用 python 或 python3 进入python解释器,输入:
import paddle paddle.utils.run_check()- 1
- 2
如果出现PaddlePaddle is installed successfully!,说明已成功安装。同时会显示当前可以并行使用的GPU数量。
2.8 安装Pytorch
参照官网命令进行安装:
 具体命令如下:
具体命令如下:pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111- 1
为了加快下载速度,同样可以先把torch对应的whl文件通过windows平台的迅雷下载下来,再拷贝到Ubuntu服务器上离线安装,下载地址。
最后验证安装是否成功。
打开Python,输入以下命令:
import torch print(torch.cuda.is_available())- 1
- 2
正常的话输出“True”。
好了,到这里就全部结束了。
-
相关阅读:
Vue3:自定义图标选择器(包含 SVG 图标封装)
hadoop.ipc:Client
Oracle LiveLabs实验:8 Partitioning Techniques in Oracle Database
FutureTask源码深度剖析
(附源码)计算机毕业设计SSM居民个人健康服务平台
MySQL数据库系统教程
【微搭低代码】家校协同管理系统实战开发教程
5分钟get一个技术点!揭秘一种加密框架的技术实现
Win11系统svchost.exe一直在下载怎么办?
3.程序控制
- 原文地址:https://blog.csdn.net/qianbin3200896/article/details/126063445