-
Java面试八股文整理
一、Java基础
1. JRE和JDK的区别
-
定义
JRE(Java Runtime Enviroment) 是Java的运行环境。面向Java程序的使用者,而不是开发者。如果你仅下载并安装了JRE,那么你的系统只能运行Java程序。JRE是运行Java程序所必须环境的集合,包含JVM标准实现及 Java核心类库。它包括Java虚拟机、Java平台核心类和支持文件。它不包含开发工具(编译器、调试器等)。
JDK(Java Development Kit) 又称J2SDK(Java2 Software Development Kit),是Java开发工具包,它提供了Java的开发环境(提供了编译器javac等工具,用于将java文件编译为class文件)和运行环境(提 供了JVM和Runtime辅助包,用于解析class文件使其得到运行)。如果你下载并安装了JDK,那么你不仅可以开发Java程序,也同时拥有了运 行Java程序的平台。JDK是整个Java的核心,包括了Java运行环境(JRE),一堆Java工具tools.jar和Java标准类库 (rt.jar)。
-
区别
JRE主要包含:java类库的class文件(都在lib目录下打包成了jar)和虚拟机(jvm.dll);
JDK主要包含:java类库的 class文件(都在lib目录下打包成了jar)并自带一个JRE。那么为什么JDK要自带一个JRE呢?而且jdk/jre/bin下的client 和server两个文件夹下都包含jvm.dll(说明JDK自带的JRE有两个虚拟机)。
2. Java中equals()和==的区别
- equals() 是判断两个变量或者实例指向同一个内存空间的值是不是相同
- “==” 是判断两个变量或者实例是不是指向同一个内存空间
- java中的数据类型,可分为两类:
- 基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean
他们之间的比较,应用双等号 “==” ,比较的是他们的值。 - 复合数据类型(类)
当他们用 “==” 进行比较的时候,比较的是他们在 内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。 JAVA当中所有的类都是继承于Object这个基类的,在Object中的基类中定义了一个equals() 的方法,这个方法的初始行为是比较对象的内存地址,但在一些类库当中这个方法被覆盖掉了,如String,Integer,Date在这些类当中equals() 有其自身的实现,而不再是比较类在堆内存中的存放地址了。
对于复合数据类型之间进行equals() 比较,在没有覆写equals() 方法的情况下,他们之间的比较还是基于他们在内存中的存放位置的地址值的,因为Object的equals() 方法也是用双等号 “==” 进行比较的,所以比较后的结果跟双等号 “==” 的结果相同。
- 基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean
3. 两个对象的hashCode()相同,则equals()也一定为true么
- 首先,答案肯定是不一定。同时反过来equals()为true,hashCode()也不一定相同。
- 类的hashCode()方法和equals()方法都可以重写,返回的值完全在于自己定义。
- hashCode()返回该对象的哈希码值;equals()返回两个对象是否相等。
- 关于hashCode()和equals()方法是有一些常规协定 :
- 两个对象用equals()比较返回true,那么两个对象的hashCode()方法必须返回相同的结果。
- 两个对象用equals()比较返回false,不要求hashCode()方法也一定返回不同的值,但是最好返回不同值,以提高哈希表性能。
- 重写equals()方法,必须重写hashCode()方法,以保证equals方法相等时两个对象hashcode返回相同的值。
4. java中的final关键字
-
final关键字可以用来修饰引用、方法和类。
-
用来修饰一个引用
- 如果引用为基本数据类型,则该引用为常量,该值无法修改;
- 如果引用为引用数据类型,比如对象、数组,则该对象、数组本身可以修改,但指向该对象或数组的地址的引用不能修改。
- 如果引用时类的成员变量,则必须当场赋值,否则编译会报错。
-
用来修饰一个方法
- 当使用final修饰方法时,这个方法将成为最终方法,无法被子类重写。但是,该方法仍然可以被继承。
-
用来修饰类
- 当用final修改类时,该类成为最终类,无法被继承。简称为“断子绝孙类”。
5. java 中操作字符串都有哪些类?它们之间有什么区别?
主要是一下三种:String、StringBuffer、StringBuilder
String和StringBuilder和StringBuffer的区别
String
StringBuffer
StringBuilder
String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间
StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量
可变类,速度更快
不可变
可变
可变
线程安全,因为 StringBuffer 的所有公开方法都是 synchronized 修饰的
线程不安全
多线程操作字符串
单线程操作字符串
6. String str = “i” 与 String str = new String(“i”)一样吗?
- 不一样,因为内存的分配方式不一样。
- String str = "i"的方式,Java虚拟机会将其分配到常量池中;而String str = new String(“i”)则会被分到堆内存中。
- String str=“i”; 因为String 是final类型的,所以“i”应该是在常量池;而new String(“i”);则是新建对象放到堆内存中。
7. Java如何将字符串反转
-
利用 StringBuffer 或 StringBuilder 的 reverse 成员方法:
// StringBuffer public static String reverse1(String str) { return new StringBuilder(str).reverse().toString(); }- 1
- 2
- 3
- 4
-
利用 String 的 toCharArray 方法先将字符串转化为 char 类型数组,然后将各个字符进行重新拼接:
// toCharArray public static String reverse2(String str) { char[] chars = str.toCharArray(); String reverse = ""; for (int i = chars.length - 1; i >= 0; i--) { reverse += chars[i]; } return reverse; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
利用 String 的 CharAt 方法取出字符串中的各个字符:
// charAt public static String reverse3(String str) { String reverse = ""; int length = str.length(); for (int i = 0; i < length; i++) { reverse = str.charAt(i) + reverse; } return reverse; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
8. Java-String类的常用方法总结
-
String类
String类在java.lang包中,java使用String类创建一个字符串变量,字符串变量属于对象。java把String类声明的final类,不能有类。String类对象创建后不能修改,由0或多个字符组成,包含在一对双引号之间。 -
String类对象的创建
字符串声明:String stringName;
字符串创建:stringName = new String(字符串常量);或stringName = 字符串常量; -
String类构造方法
1、public String()
无参构造方法,用来创建空字符串的String对象。String str1 = new String();- 1
2、public String(String value)
用已知的字符串value创建一个String对象。String str2 = new String("asdf"); 2 String str3 = new String(str2);- 1
3、public String(char[] value)
用字符数组value创建一个String对象。char[] value = {'a','b','c','d'}; String str4 = new String(value);//相当于String str4 = new String("abcd");- 1
- 2
4、public String(char chars[], int startIndex, int numChars)
用字符数组chars的startIndex开始的numChars个字符创建一个String对象。char[] value = {'a','b','c','d'}; String str5 = new String(value, 1, 2);//相当于String str5 = new String("bc");- 1
- 2
5、public String(byte[] values)
用比特数组values创建一个String对象。byte[] strb = new byte[]{65,66}; String str6 = new String(strb);//相当于String str6 = new String("AB");- 1
- 2
-
String类常用方法
1、求字符串长度
public int length()//返回该字符串的长度String str = new String("asdfzxc"); int strlength = str.length();//strlength = 7- 1
- 2
2、求字符串某一位置字符
public char charAt(int index)//返回字符串中指定位置的字符;注意字符串中第一个字符索引是0,最后一个是length()-1。String str = new String("asdfzxc"); char ch = str.charAt(4);//ch = z- 1
- 2
3、提取子串
用String类的substring方法可以提取字符串中的子串,该方法有两种常用参数:-
public String substring(int beginIndex)//该方法从beginIndex位置起,从当前字符串中取出剩余的字符作为一个新的字符串返回。
-
public String substring(int beginIndex, int endIndex)//该方法从beginIndex位置起,从当前字符串中取出到endIndex-1位置的字符作为一个新的字符串返回。
String str1 = new String(“asdfzxc”);
String str2 = str1.substring(2);//str2 = “dfzxc”
String str3 = str1.substring(2,5);//str3 = “dfz”
4、字符串比较
-
public int compareTo(String anotherString)//该方法是对字符串内容按字典顺序进行大小比较,通过返回的整数值指明当前字符串与参数字符串的大小关系。若当前对象比参数大则返回正整数,反之返回负整数,相等返回0。
-
public int compareToIgnore(String anotherString)//与compareTo方法相似,但忽略大小写。
-
public boolean equals(Object anotherObject)//比较当前字符串和参数字符串,在两个字符串相等的时候返回true,否则返回false。
-
public boolean equalsIgnoreCase(String anotherString)//与equals方法相似,但忽略大小写。
String str1 = new String(“abc”);
String str2 = new String(“ABC”);
int a = str1.compareTo(str2);//a>0
int b = str1.compareToIgnoreCase(str2);//b=0
boolean c = str1.equals(str2);//c=false
boolean d = str1.equalsIgnoreCase(str2);//d=true
5、字符串连接
public String concat(String str)//将参数中的字符串str连接到当前字符串的后面,效果等价于"+"。String str = "aa".concat("bb").concat("cc"); 相当于String str = "aa"+"bb"+"cc";- 1
- 2
6、字符串中单个字符查找
-
public int indexOf(int ch/String str)//用于查找当前字符串中字符或子串,返回字符或子串在当前字符串中从左边起首次出现的位置,若没有出现则返回-1。
-
public int indexOf(int ch/String str, int fromIndex)//改方法与第一种类似,区别在于该方法从fromIndex位置向后查找。
-
public int lastIndexOf(int ch/String str)//该方法与第一种类似,区别在于该方法从字符串的末尾位置向前查找。
-
public int lastIndexOf(int ch/String str, int fromIndex)//该方法与第二种方法类似,区别于该方法从fromIndex位置向前查找。
String str = “I am a good student”;
int a = str.indexOf(‘a’);//a = 2
int b = str.indexOf(“good”);//b = 7
int c = str.indexOf(“w”,2);//c = -1
int d = str.lastIndexOf(“a”);//d = 5
int e = str.lastIndexOf(“a”,3);//e = 2
7、字符串中字符的大小写转换
-
public String toLowerCase()//返回将当前字符串中所有字符转换成小写后的新串
-
public String toUpperCase()//返回将当前字符串中所有字符转换成大写后的新串
String str = new String(“asDF”);
String str1 = str.toLowerCase();//str1 = “asdf”
String str2 = str.toUpperCase();//str2 = “ASDF”
8、字符串中字符的替换
-
public String replace(char oldChar, char newChar)//用字符newChar替换当前字符串中所有的oldChar字符,并返回一个新的字符串。
-
public String replaceFirst(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的第一个和字符串regex相匹配的子串,应将新的字符串返回。
-
public String replaceAll(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的所有和字符串regex相匹配的子串,应将新的字符串返回。
String str = “asdzxcasd”;
String str1 = str.replace(‘a’,‘g’);//str1 = “gsdzxcgsd”
String str2 = str.replace(“asd”,“fgh”);//str2 = “fghzxcfgh”
String str3 = str.replaceFirst(“asd”,“fgh”);//str3 = “fghzxcasd”
String str4 = str.replaceAll(“asd”,“fgh”);//str4 = “fghzxcfgh”
9、其他类方法
-
String trim()//截去字符串两端的空格,但对于中间的空格不处理。
String str = " a sd ";
String str1 = str.trim();
int a = str.length();//a = 6
int b = str1.length();//b = 4 -
boolean statWith(String prefix)或boolean endWith(String suffix)//用来比较当前字符串的起始字符或子字符串prefix和终止字符或子字符串suffix是否和当前字符串相同,重载方法中同时还可以指定比较的开始位置offset。
String str = “asdfgh”;
boolean a = str.statWith(“as”);//a = true
boolean b = str.endWith(“gh”);//b = true -
regionMatches(boolean b, int firstStart, String other, int otherStart, int length)//从当前字符串的firstStart位置开始比较,取长度为length的一个子字符串,other字符串从otherStart位置开始,指定另外一个长度为length的字符串,两字符串比较,当b为true时字符串不区分大小写。
-
contains(String str)//判断参数s是否被包含在字符串中,并返回一个布尔类型的值。
String str = “student”;
str.contains(“stu”);//true
str.contains(“ok”);//false -
String[] split(String str)//将str作为分隔符进行字符串分解,分解后的字字符串在字符串数组中返回。
String str = “asd!qwe|zxc#”;
String[] str1 = str.split(“!|#”);//str1[0] = “asd”;str1[1] = “qwe”;str1[2] = “zxc”;
-
字符串与基本类型的转换
-
字符串转换为基本类型
java.lang包中有Byte、Short、Integer、Float、Double类的调用方法:public static byte parseByte(String s) public static short parseShort(String s) public static short parseInt(String s) public static long parseLong(String s) public static float parseFloat(String s) public static double parseDouble(String s)- 1
- 2
- 3
- 4
- 5
- 6
例如:
int n = Integer.parseInt("12"); float f = Float.parseFloat("12.34"); double d = Double.parseDouble("1.124");- 1
- 2
- 3
-
基本类型转换为字符串类型
String类中提供了String valueOf()放法,用作基本类型转换为字符串类型。static String valueOf(char data[]) static String valueOf(char data[], int offset, int count) static String valueOf(boolean b) static String valueOf(char c) static String valueOf(int i) static String valueOf(long l) static String valueOf(float f) static String valueOf(double d)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
例如:
String s1 = String.valueOf(12); String s1 = String.valueOf(12.34);- 1
- 2
-
进制转换
使用Long类中的方法得到整数之间的各种进制转换的方法:Long.toBinaryString(long l) Long.toOctalString(long l) Long.toHexString(long l) Long.toString(long l, int p)//p作为任意进制- 1
- 2
- 3
- 4
-
9. 抽象类必须要有抽象方法吗?
-
答:不需要,
抽象类不一定有抽象方法;但是包含一个抽象方法的类一定是抽象类。(有抽象方法就是抽象类,是抽象类可以没有抽象方法)
-
解释:
-
抽象方法:
java中的抽象方法就是以abstract修饰的方法,这种方法只声明返回的数据类型、方法名称和所需的参数,没有方法体,也就是说抽象方法只需要声明而不需要实现。
-
抽象方法与抽象类:
当一个方法为抽象方法时,意味着这个方法必须被子类的方法所重写,否则其子类的该方法仍然是abstract的,而这个子类也必须是抽象的,即声明为abstract。abstract抽象类不能用new实例化对象,abstract方法只允许声明不能实现。如果一个类中含有abstract方法,那么这个类必须用abstract来修饰,当然abstract类也可以没有abstract方法。 一个抽象类里面没有一个抽象方法可用来禁止产生这种类的对象。
-
Java中的抽象类:
abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。
在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在 interface中一般不定义数据成员),所有的成员方法都是abstract的。
-
10. 普通类和抽象类有哪些区别
-
关键点:abstract修饰符(抽象方法)、具体实现过程、实例化、子类实现父类的抽象方法
- 普通类中不可含有抽象方法,可以被实例化;
- 抽象类,则抽象类中所有的方法自动被认为是抽象方法,没有实现过程,不可被实例化;
- 抽象类的子类,除非也是抽象类,否则必须实现该抽象类声明的方法
11. 抽象类可以使用final修饰吗?
- 当然不可以,通过理解抽象类的作用我们就发现了,抽象类必须要被继承,如果用final修饰抽象类,这个抽象类就无法被继承,自然就无法使用了。
12. java中abstract类和interface的区别
-
相同点
- 两者都是抽象类,都不能实例化。
- interface实现类及abstrct class的子类都必须要实现已经声明的抽象方法。
-
不同点
- interface需要实现,要用implements,而abstract class需要继承,要用extends。
- 一个类可以实现多个interface,但一个类只能继承一个abstract class。
- interface强调特定功能的实现,而abstractclass强调所属关系。
- 尽管interface实现类及abstrct class的子类都必须要实现相应的抽象方法,但实现的形式不同。interface中的每一个方法都是抽象方法,都只是声明的(declaration,没有方法体),实现类必须要实现。而abstract class的子类可以有选择地实现。
13. Java中的IO流
指的是将不同的输入输出源通过流的形式进行输入或输出的操作,流是一种抽象的描述,在程序中指的是数据的一种转移方式。
-
IO流的分类:
- 按照数据的流向:
输入流、输出流 - 按照流数据的格式:
字符流、字节流 - 按照流数据的包装过程:
节点流(低级流)、处理流(高级流)
- 按照数据的流向:
-
最基本的几种进行简单介绍:
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
-
Java文本文件读取的大致过程如下:
- 构建文件对象,
- 使用文件对象构造Reader对象可以是FileReader、InputStreamReader、RandomAccessFile等
- 使用Reader对像构建BufferedReader对象(主要使用其**readLine()**方法,用于按行读取文件)
- 按行读取文件,将每行获取到的字符串进行处理。
14. BIO,NIO,AIO 有什么区别
- BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
- NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
- AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
15. Files的常用方法有哪些?
- Files.exists() 检测文件路径是否存在
- Files.createFile()创建文件
- Files.createDirectory()创建文件夹
- Files.delete() 删除文件或者目录
- Files.copy() 复制文件
- Files.move() 移动文件
- Files.size()查看文件个数
- Files.read() 读取文件
- Files.write()写入文件
16. 类加载过程
-
加载
加载指的是将类的class文件读入到内存,并为之创建一个java.lang.Class对象,也就是说,当程序中使用任何类时,系统都会为之建立一个java.lang.Class对象。
类的加载由类加载器完成,类加载器通常由JVM提供,这些类加载器也是前面所有程序运行的基础,JVM提供的这些类加载器通常被称为系统类加载器。除此之外,开发者可以通过继承ClassLoader基类来创建自己的类加载器。
通过使用不同的类加载器,可以从不同来源加载类的二进制数据,通常有如下几种来源。
- 从本地文件系统加载class文件,这是前面绝大部分示例程序的类加载方式。
- 从JAR包加载class文件,这种方式也是很常见的,前面介绍JDBC编程时用到的数据库驱动类就放在JAR文件中,JVM可以从JAR文件中直接加载该class文件。
- 通过网络加载class文件。
- 把一个Java源文件动态编译,并执行加载。
类加载器通常无须等到“首次使用”该类时才加载该类,Java虚拟机规范允许系统预先加载某些类。
-
链接
当类被加载之后,系统为之生成一个对应的Class对象,接着将会进入连接阶段,连接阶段负责把类的二进制数据合并到JRE中。类连接又可分为如下3个阶段。
-
验证:验证阶段用于检验被加载的类是否有正确的内部结构,并和其他类协调一致。Java是相对C++语言是安全的语言,例如它有C++不具有的数组越界的检查。这本身就是对自身安全的一种保护。验证阶段是Java非常重要的一个阶段,它会直接的保证应用是否会被恶意入侵的一道重要的防线,越是严谨的验证机制越安全。验证的目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。其主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
四种验证做进一步说明:
- 文件格式验证:主要验证字节流是否符合Class文件格式规范,并且能被当前的虚拟机加载处理。例如:主,次版本号是否在当前虚拟机处理的范围之内。常量池中是否有不被支持的常量类型。指向常量的中的索引值是否存在不存在的常量或不符合类型的常量。
- 元数据验证:对字节码描述的信息进行语义的分析,分析是否符合java的语言语法的规范。
- 字节码验证:最重要的验证环节,分析数据流和控制,确定语义是合法的,符合逻辑的。主要的针对元数据验证后对方法体的验证。保证类方法在运行时不会有危害出现。
- 符号引用验证:主要是针对符号引用转换为直接引用的时候,是会延伸到第三解析阶段,主要去确定访问类型等涉及到引用的情况,主要是要保证引用一定会被访问到,不会出现类等无法访问的问题。
-
准备:类准备阶段负责为类的静态变量分配内存,并设置默认初始值。
-
解析:将类的二进制数据中的符号引用替换成直接引用。说明一下:符号引用:符号引用是以一组符号来描述所引用的目标,符号可以是任何的字面形式的字面量,只要不会出现冲突能够定位到就行。布局和内存无关。直接引用:是指向目标的指针,偏移量或者能够直接定位的句柄。该引用是和内存中的布局有关的,并且一定加载进来的。
-
-
初始化
初始化是为类的静态变量赋予正确的初始值,准备阶段和初始化阶段看似有点矛盾,其实是不矛盾的,如果类中有语句:private static int a = 10,它的执行过程是这样的,首先字节码文件被加载到内存后,先进行链接的验证这一步骤,验证通过后准备阶段,给a分配内存,因为变量a是static的,所以此时a等于int类型的默认初始值0,即a=0,然后到解析(后面在说),到初始化这一步骤时,才把a的真正的值10赋给a,此时a=10。
17. java中覆盖和重载的区别
- 子类继承了父类,但重写了父类的方法,因此虽然是从父类中拿到的方法但重写之后与父类方法有了区别,因此称为覆盖(即子类方法覆盖了父类方法)
- 重载的含义,一个类中可以有多个同名不同参(参数列表不同)的方法。
区别
覆盖(override)
重载(overload)
实现上
子类对父类方法的重写
同一个类中建立多个同名方法
参数
与父类同名同参
与别的方法同名不同参
返回
子类与父类返回类型要一致
无此要求
权限
子类不能覆盖父类的private方法
无此要求
父类一个方法只能在子类覆盖一次
重载只要参数不同,可以多次
覆盖是针对父类方法的重写
同类中的方法均可重载
重写要求子类比父类抛出更少的异常
无此要求
18. Java 浅拷贝和深拷贝
19. Java的垃圾回收机制
垃圾收集GC(Garbage Collection)是Java语言的核心技术之一, 在Java中,程序员不需要去关心内存动态分配和垃圾回收的问题,这一切都交给了JVM来处理。
-
什么样的对象才是垃圾?
这个问题其实很简单,对于Java对象来讲,如果说这个对象没有被其他对象所引用该对象就是无用的,此对象就被称为垃圾,其占用的内存也就要被销毁。那么自然而然的就引出了我们的第二个问题,判断对象为垃圾的算法都有哪些?
-
标记垃圾的算法
Java中标记垃圾的算法主要有两种, 引用计数法和可达性分析算法。
-
引用计数法
引用计数法就是给对象中添加一个引用计数器,每当有一个地方引用它,计数器就加 1;当引用失效,计数器就减 1;任何时候计数器为 0 的对象就是不可能再被使用的,可以当做垃圾收集。这种方法实现起来很简单而且优缺点都很明显。
- 优点 执行效率高,程序执行受影响较小
- 缺点 无法检测出循环引用的情况,导致内存泄露
-
可达性分析算法
这个算法的基本思想就是通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
那么什么对象可以作为GCRoot?
- 虚拟机栈中的引用对象
- 方法区中的常量引用对象
- 方法区中的类静态属性引用对象
- 本地方法栈中的引用对象
- 活跃线程中的引用对象
-
-
如何将垃圾回收?
在Java中存在着四种垃圾回收算法,标记清除算法、复制算法、标记整理算法以及分代回收算法。我们接下来会分别介绍他们。
-
标记清除算法
该算法分为“标记”和“清除”两个阶段:标记阶段的任务是标记出所有需要被回收的对象,清除阶段就是回收被标记的对象所占用的空间。它是最基础的收集算法,效率也很高,但是会带来两个明显的问题:
- 效率问题
- 空间问题(标记清除后会产生大量不连续的碎片)*
-
复制算法
为了解决效率问题,我们开发出了复制算法。它可以将内存分为大小相同的两块,每次 使用其中的一块。当第一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
简单来说就是该对象分为对象面以及空闲面,对象在对象面上创建,对象面上存活的对象会被复制到空闲面,接下来就可以清除对象面的内存。
这种算法的优缺点也比较明显
- 优点:解决碎片化问题,顺序分配内存简单高效
- 缺点:只适用于存活率低的场景,如果极端情况下如果对象面上的对象全部存活,就要浪费一半的存储空间。
-
标记整理算法
为了解决复制算法的缺陷,充分利用内存空间,提出了标记整理算法。该算法标记阶段和标记清除一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存。
-
分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法就是根据具体的情况选择具体的垃圾回收算法。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
-
20. Java文本文件读取的大致过程如下:
- 构建文件对象,
- 使用文件对象构造Reader对象可以是FileReader、InputStreamReader、RandomAccessFile等
- 使用Reader对像构建BufferedReader对象(主要使用其**readLine()**方法,用于按行读取文件)
- 按行读取文件,将每行获取到的字符串进行处理。
21. 多线程
-
有三种使用线程的方法:
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以理解为任务是通过线程驱动从而执行的。
-
start()和run()的区别:
-
start方法:
通过该方法启动线程的同时也创建了一个线程,真正实现了多线程。无需等待run()方法中的代码执行完毕,就可以接着执行下面的代码。此时start()的这个线程处于就绪状态,当得到CPU的时间片后就会执行其中的run()方法。这个run()方法包含了要执行的这个线程的内容,run()方法运行结束,此线程也就终止了。
-
run方法:
通过run方法启动线程其实就是调用一个类中的方法,当作普通的方法的方式调用。并没有创建一个线程,程序中依旧只有一个主线程,必须等到run()方法里面的代码执行完毕,才会继续执行下面的代码,这样就没有达到写线程的目的。
而run方法是业务逻辑实现的地方,本质上和任意一个类的任意一个成员方法并没有任何区别,可以重复执行,被一个线程反复调用,也可以被单独调用
-
-
总结一下:
1.start() 可以启动一个新线程,run()不能
2.start()不能被重复调用,run()可以
3.start()中的run代码可以不执行完就继续执行下面的代码,即进行了线程切换。直接调用run方法必须等待其代码全部执行完才能继续执行下面的代码。
4.start() 实现了多线程,run()没有实现多线程。
22. Java反射机制
-
一、什么是反射:
- Java反射机制的核心是在程序运行时动态加载类并获取类的详细信息,从而操作类或对象的属性和方法。本质是JVM得到class对象之后,再通过class对象进行反编译,从而获取对象的各种信息。
- Java属于先编译再运行的语言,程序中对象的类型在编译期就确定下来了,而当程序在运行时可能需要动态加载某些类,这些类因为之前用不到,所以没有被加载到JVM。通过反射,可以在运行时动态地创建对象并调用其属性,不需要提前在编译期知道运行的对象是谁。
-
二、反射的原理:
下图是类的正常加载过程、反射原理与class对象:Class对象的由来是将.class文件读入内存,并为之创建一个Class对象。
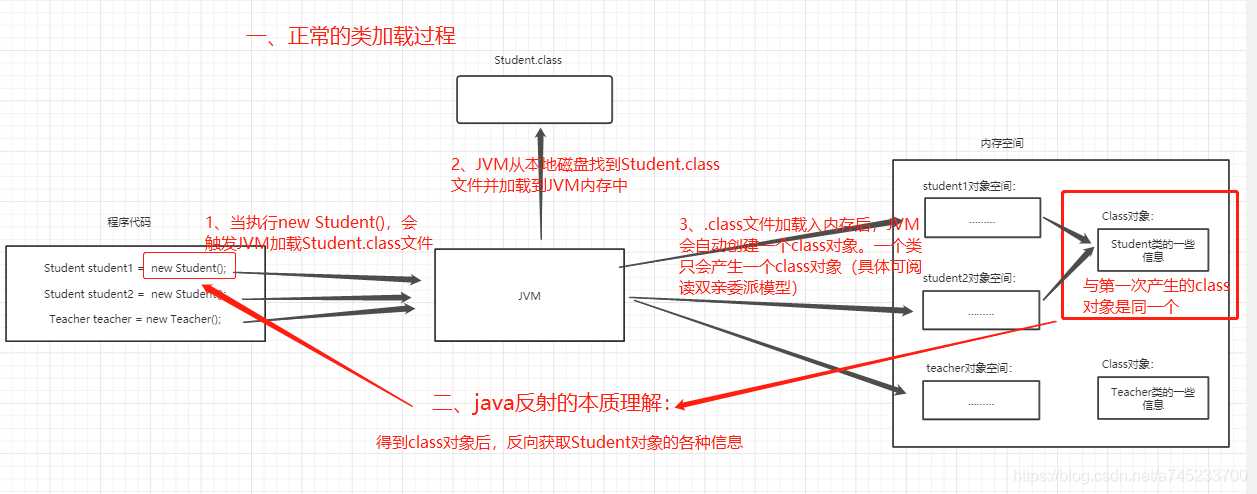
-
三、反射的优缺点:
- 优点:
- 在运行时获得类的各种内容,进行反编译,对于Java这种先编译再运行的语言,能够让我们很方便的创建灵活的代码,这些代码可以在运行时装配,无需在组件之间进行源代码的链接,更加容易实现面向对象。
- 缺点:
- 反射会消耗一定的系统资源,因此,如果不需要动态地创建一个对象,那么就不需要用反射;
- 反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
- 优点:
-
四、反射的用途:
- 反编译:.class–>.java
- 通过反射机制访问java对象的属性,方法,构造方法等
- 当我们在使用IDE,比如Ecplise时,当我们输入一个对象或者类,并想调用他的属性和方法是,一按点号,编译器就会自动列出他的属性或者方法,这里就是用到反射。
- 反射最重要的用途就是开发各种通用框架。比如很多框架(Spring)都是配置化的(比如通过XML文件配置Bean),为了保证框架的通用性,他们可能需要根据配置文件加载不同的类或者对象,调用不同的方法,这个时候就必须使用到反射了,运行时动态加载需要的加载的对象。
二、Java容器
1. Java中常见的容器有哪些?
常用容器可分为Collection和Map,Collection是存储对象的集合,而Map是存储键值对的集合。
其中,Collection又分为List、Set、Queue,而Map的实现类为HashMap、LinkedHashMap、TreeMap、HashTable。-
List接口(有序,可重复):
- ArrayList:底层是动态数组,支持随机访问。
- LinkedList:底层是双向链表,只能顺序访问。
-
Set接口(不可重复):
- HashSet(无序):基于哈希表。支持快速查找,但不支持有序性操作,且不维持插入顺序信息。
- TreeSet(有序):底层是红黑树。支持快速查找(O(logn))但效率比HashSet(O(1))低。支持有序性操作,例如在一定范围内查找元素。
- LinkedHashSet(有序):底层是链表+哈希表。使用哈希表存储元素,再维护一个双向链表保存元素的插入信息。
-
Queue接口:
- LinkedList:可实现双向队列
- PriorityQueue:基于堆结构的优先队列。
-
Map接口:
- HashMap:基于哈希表。
- LinkedHashMap:使用双向链表维护插入顺序。
- HashTable:线程安全的HashMap,已淘汰。推荐ConcurrentHashMap。
- TreeMap:基于红黑树。
-
常用集合的分类:
-
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序 -
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
2. int与integer的区别
- Integer是int提供的封装类,而int是java的基本数据类型
- Integer默认值是null,而int默认值是0;
- 声明为Integer的变量需要实例化,而声明为int的变量不需要实例化
- Integer是对象,用一个引用指向这个对象,而int是基本类型,直接存储数据
- 类似的还有:float Float;double Double;string String等
- 举个例子:当需要往ArrayList,HashMap中放东西时,像int,double这种内建类型是放不进去的,因为容器都是装 object的,这是就需要这些内建类型的外覆类了。
- Java中每种内建类型都有相应的外覆类
3. Array 和ArrayList的区别
-
长度的区别:
-
Array是数组,声明好之后,其长度就已经固定。
ArrayList底层是用数组实现的,但是ArrayList的长度是可变的,在每次添加时,如果发现空间不足的话,会创建一个长度大概是原来1.5倍的新数组(java8源码),然后把原来的数组元素复制过去。
-
-
存放数据的区别:
-
Array可以除了可以存放对象类型的数据之外,还可以存放基本数据类型的数据。
而ArrayList只能存放对象数据类型的数据,因为它的类在定义时已经是针对Object的子类做了泛型的约束。
-
4. HashTable和HashMap区别
-
继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
-
线程安全性不同
javadoc中关于hashmap的一段描述如下:此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
Hashtable 中的方法是Synchronized的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问,如下所示:
-
是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
-
key和value是否允许null值
其中key和value都是对象,并且不能包含重复key,但可以包含重复的value。
通过上面的ContainsKey方法和ContainsValue的源码我们可以很明显的看出:
Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。 -
两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
-
hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值。
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值, Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
-
内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
5. 数组和链表的区别?
- 不同:
- 链表是链式的存储结构;数组是顺序的存储结构。
- 链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
- 链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难;数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再编程一开始时指定,故当达到最大长度时,扩充长度不如链表方便。
- **相同:**两种结构均可实现数据的顺序存储,构造出来的模型呈线性结构。
6. hashmap的实现:数组+链表+红黑树
-
数组+链表:数组寻址容易,插入删除难;链表寻址难,插入删除容易
-
链表长度超过8,转变为使用红黑树
-
存put(k,v):首先把(k,v)封装到Node对象;然后调用hashCode()方法计算k的hash值;最后通过哈希算法将hash值转换成数组下标,下标上如果没有元素就把Node添加到该位置,如果下标对应位置有链表,比较链表中每个key的equals()返回,若全为false则添加到链表末尾,若有一个返回true则覆盖
-
红黑树:
- 节点要么黑,要么红
- 根节点为黑
- 空的(NIL/NULL)的叶子节点为黑
- 红节点的子节点必须为黑
- 从一个节点到该节点的子孙节点的所有路劲包含相同数目的黑节点
- 保证红黑树的方法:变色,旋转(左旋转and右旋转)
7. 线程池
又以上介绍我们可以看出,在一个应用程序中,我们需要多次使用线程,也就意味着,我们需要多次创建并销毁线程。而创建并销毁线 程的过程势必会消耗内存。而在Java中,内存资源是及其宝贵的,所以,我们就提出了线程池的概念。
-
线程池: Java中开辟出了一种管理线程的概念,这个概念叫做线程池,从概念以及应用场景中,我们可以看出,线程池的好处,就是可以方便的管理线程,也可以减少内存的消耗。
那么,我们应该如何创建一个线程池那Java中已经提供了创建线程池的一个类:Executor
而我们创建时,一般使用它的子类:ThreadPoolExecutor.
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueueworkQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) - 1
- 2
- 3
- 4
- 5
- 6
- 7
这是其中最重要的一个构造方法,这个方法决定了创建出来的线程池的各种属性,线程池中的corePoolSize就是线程池中的核心线程数量,这几个核心线程,只是在没有用的时候,也不会被回收,maximumPoolSize就是线程池中可以容纳的最大线程的数量,而keepAliveTime,就是线程池中除了核心线程之外的其他的最长可以保留的时间,因为在线程池中,除了核心线程即使在无任务的情况下也不能被清除,其余的都是有存活时间的,意思就是非核心线程可以保留的最长的空闲时间,而util,就是计算这个时间的一个单位,workQueue,就是等待队列,任务可以储存在任务队列中等待被执行,执行的是FIFIO原则(先进先出)。threadFactory,就是创建线程的线程工厂,最后一个handler,是一种拒绝策略,我们可以在任务满了知乎,拒绝执行某些任务。
-
线程池的执行流程又是怎样的呢?
有图我们可以看出,任务进来时,首先执行判断,判断核心线程是否处于空闲状态,如果不是,核心线程就先就执行任务,如果核心线程已满,则判断任务队列是否有地方存放该任务,若果有,就将任务保存在任务队列中,等待执行,如果满了,在判断最大可容纳的线程数,如果没有超出这个数量,就开创非核心线程执行任务,如果超出了,就调用handler实现拒绝策略。
-
handler的拒绝策略:
- 第一种AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
- 第二种DisCardPolicy:不执行新任务,也不抛出异常
- 第三种DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
- 第四种CallerRunsPolicy:直接调用execute来执行当前任务
-
四种常见的线程池:
- CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。
- SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
- SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。
- FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程
8. HashMap和HashSet的区别
-
什么是HashSet
HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。
public boolean add(Object o) //方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。- 1
- 2
-
什么是HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap允许键和值为null。HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
public Object put(Object Key,Object value) //方法用来将元素添加到map中。- 1
- 2
-
HashSet和HashMap的区别
HashMap
HashSet
HashMap实现了Map接口
HashSet实现了Set接口
HashMap储存键值对
HashSet仅仅存储对象
使用put()方法将元素放入map中
使用add()方法将元素放入set中
HashMap中使用键对象来计算hashcode值
HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false
HashMap比较快,因为是使用唯一的键来获取对象
HashSet较HashMap来说比较慢
三、数据结构和算法
1. 二叉树的特性 时间复杂度计算过程写一下
二叉树是一棵树,且每个节点都不能有多于两个的儿子,且二叉树的子树有左右之分,次序不能颠倒。
-
二叉树的性质
- 在二叉树中的第i层上至多有2^(i-1)个结点(i>=1)。
- 深度为k的二叉树至多有2^k - 1个节点(k>=1)。
- 对任何一棵二叉树T,如果其叶结点数目为n0,度为2的节点数目为n2,则n0=n2+1。
-
**满二叉树:**深度为k且具有2^k-1个结点的二叉树。即满二叉树中的每一层上的结点数都是最大的结点数。
-
**完全二叉树:**深度为k具有n个结点的二叉树,当且仅当每一个结点与深度为k的满二叉树中的编号从1至n的结点一一对应。
-
具有n个节点的完全二叉树的深度为log2n + 1。
二叉搜索树,平衡二叉树,红黑树的算法效率
操作
二叉查找树
平衡二叉树
红黑树
查找
O(n)
O(logn)
Olog(n)
插入
O(n)
O(logn)
Olog(n)
删除
O(n)
O(logn)
Olog(n)
Olog(n)怎么算出来的
在一个树中查找一个数字, 第一次在根节点判断,第二次在第二层节点判断 以此类推,树的高度是多少就会判断多少次 树的高度和节点的关系就是以2为底,树的节点总数n的对数- 1
- 2
- 3
- 4
2. 手写二分 有序正负数组找到近 0 的两个数
public static int[] divide(int[] array){ int mid = (min + max) / 2; int[] result = new int[2]; while(array[mid] != 0){ if(array[mid] > 0){ max = mid - 1; } if(array[mid] < 0){ min = mid + 1; } if(min >= max){ break; } mid = (min + max) / 2; } result[0] = array[mid - 1]; result[1] = array[mid + 1]; return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3. 二叉树三种遍历:
public class TreeNode{ int val; public TreeNode(va){ val = va; } TreeNode left; TreeNode right; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
前序遍历:(根左右)
/*递归法*/ ArrayListpre = new ArrayList<>(); public ArrayList DLR(TreeNode root){ if(root == null){ return pre; } pre.add(root.val); DLR(root.left); DLR(root.right); return pre; } /*非递归法 1、申请一个栈stack,然后将头节点压入stack中。 2、从stack中弹出栈顶节点,打印,再将其右孩子节点(不为空的话)先压入stack中,最后将其左孩子节点(不为空的话)压入stack中。 3、不断重复步骤2,直到stack为空,全部过程结束。*/ public List preorderTraversal(TreeNode root) { List list=new ArrayList (); Stack stack=new Stack (); if (root!=null) { stack.push(root); while(!stack.empty()) { TreeNode tr=stack.pop(); list.add(tr.val); if(tr.right!=null) { stack.push(tr.right); } if(tr.left!=null) { stack.push(tr.left); } } } return list; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
中序遍历:(左根右)
/*递归法*/ ArrayListmid = new ArrayList<>(); public ArrayList LDR(TreeNode root){ if(root == null){ return mid; } LDR(root.left); mid.add(root.val); LDR(root.right); return mid; } /*非递归法 1、申请一个栈stack,初始时令cur=head 2、先把cur压入栈中,依次把左边界压入栈中,即不停的令cur=cur.left,重复步骤2 3、不断重复2,直到为null,从stack中弹出一个节点,记为node,打印node的值,并令cur=node.right,重复步骤2 4、当stack为空且cur为空时,整个过程停止。*/ public List inorderTraversal(TreeNode head) { List list=new ArrayList (); Stack stack=new Stack (); if (head!=null) { while(head!=null||!stack.empty()) { if(head!=null) { stack.push(head); head=head.left; }else { head=stack.pop(); list.add(head.val); head=head.right; } } } return list; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
后序遍历:(左右根)
/*递归法*/ ArrayListpost = new ArrayList<>(); public ArrayList LRD(TreeNode root){ if(root == null){ return post; } LRD(root.left); LRD(root.right); post.add(root.val); return post } /*非递归法 用非递归的方式实现后序遍历有点麻烦。 1、申请一个栈s1,然后将头节点压入栈s1中。 2、从s1中弹出的节点记为cur,然后依次将cur的左孩子节点和右孩子节点压入s1中。 3、在整个过程中,每一个从s1中弹出的节点都放进s2中。 4、不断重复步骤2和步骤3,直到s1为空,过程停止。 5、从s2中依次弹出节点并打印,打印的顺序就是后序遍历的顺序。*/ public List postorderTraversal(TreeNode head) { List list = new ArrayList (); Stack stack1 = new Stack (); Stack stack2 = new Stack (); if (head != null) { stack1.push(head); while(!stack1.empty()) { head = stack1.pop(); stack2.push(head); if (head.left != null) { stack1.push(head.left); } if (head.right != null) { stack1.push(head.right); } } while(!stack2.empty()) { list.add(stack2.pop().val); } } return list; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
4. 队列模拟栈:
Class QueueToStack{ Queuequeue1 = new LinkedList<>(); Queue queue2 = new LinkedList<>(); public void push(int x){ if (queue1.isEmpty() && queue2.isEmpty()){ queue1.add(x); } else if(queue1.isEmpty() && !queue2.isEmpty()){ queue1.add(x); while (!queue2.isEmpty()){ queue1.add(queue2.remove()); } } else if(!queue1.isEmpty() && queue2.isEmpty()){ queue2.add(x); while (!queue1.isEmpty()){ queue2.add(queue1.remove()); } } } public int pop(){ return queue1.isEmpty() ? queue2.remove() : queue1.remove(); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
四、Linux基本命令
-
pwd 显示工作路径
-
chmod 777和754 修改文件权限
读取权限 r = 4
写入权限 w = 2
执行权限 x = 1 -
查看进程状态ps,查看cpu状态 top。查看占用端口的进程号netstat grep
-
ps aux | less 输入下面的ps命令,显示所有运行中的进程
-
pgrep:通过程序的名字来查询进程,默认只显示PID
-
pidof: 根据程序名称,查找其相关进程的ID号
-
lsof -i:端口号:查看端口占用情况
-
top :动态实时显示cpu、内存、进程等使用情况(类似windows下的任务管理器)
-
kill -9 进程号 :强制杀死进程
-
renice NI PID:调整已经启动的进程的nice值
-
nice -n NI COMMAND:在启动时指定nice值
-
tar -zxvf archive.tar.gz 解压一个gzip格式的压缩包
-
sed ‘s/stringa1/stringa2/g’ example.txt 将example.txt文件中的 “string1” 替换成 “string2”
-
sed ‘/^$/d’ example.txt 从example.txt文件中删除所有空白行
-
*sed '/ #/d; /^$/d’ example.txt 从example.txt文件中删除所有注释和空白行
-
echo ‘esempio’ | tr ‘[:lower:]’ ‘[:upper:]’ 合并上下单元格内容
-
sed -e ‘1d’ result.txt 从文件example.txt 中排除第一行
-
sed -n ‘/stringa1/p’ 查看只包含词汇 "string1"的行
-
*sed -e 's/ $//’ example.txt 删除每一行最后的空白字符
-
sed -e ‘s/stringa1//g’ example.txt 从文档中只删除词汇 “string1” 并保留剩余全部
-
sed -n ‘1,5p;5q’ example.txt 查看从第一行到第5行内容
-
sed -n ‘5p;5q’ example.txt 查看第5行
-
sed -e 's/00/0/g’ example.txt* 用单个零替换多个零
-
cat file1 | command( sed, grep, awk, grep, etc…) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中
-
cat file1 | command( sed, grep, awk, grep, etc…) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
-
grep Aug /var/log/messages 在文件 '/var/log/messages’中查找关键词"Aug"
-
grep ^Aug /var/log/messages 在文件 '/var/log/messages’中查找以"Aug"开始的词汇
五、数据库
1. MySQL数据库设计三范式
- 1NF:字段不可分;
- 2NF:有主键,非主键字段依赖主键;
- 3NF:非主键字段不能相互依赖;
解释:
-
1NF:原子性 字段不可再分,否则就不是关系数据库;
-
2NF:唯一性 一个表只说明一个事物;
-
3NF:每列都与主键有直接关系,不存在传递依赖;
基本sql语句
1.自然连接(natural join)
自然连接将表中具有相同名称的列自动进行匹配,自然连接不必指定任何同等连接条件也不能认为指定哪些列需要被匹配,自然连接得到的结果表中,两表中名称相同的列只出现一次。select * from employee natural join department;- 1
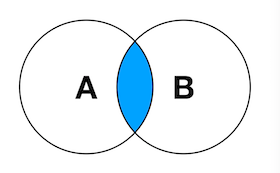
2.内连接(inner join):产生的结果是A和B的交集(相同列里面的相同值)
内连接查询能将左表和右表中能关联起来的数据连接后返回,返回的结果就是两个表中所有相匹配的数据。select * from TableA as A inner join TableB B on A.PK = B.PK; select * from TableA as A inner join TableB B on A.PK > B.PK;- 1
- 2
3.外连接(outer join)
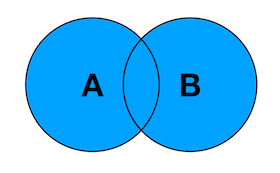
内连接是要显示两张表的内存,而外连接不要求如此,外连接可以依据连接表保留左表,右表或全部表的行为而分为左外连接右外连接和全连接。select * from TableA as A left(right/full) join TableB as B on A.PA = B.PK;- 1
Full Join:产生的结果是A和B的并集(如果没有相同的值会用null作为值)
Left Join:产生表A的完全集,而B表中匹配的则有值(没有匹配的则以null值取代)
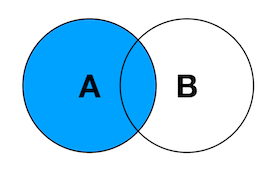
Right Join:产生表B的完全集,而A表中匹配的则有值(没有匹配的则以null值取代)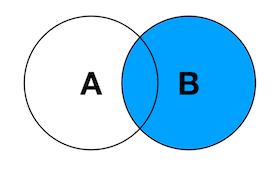
4.交叉连接(cross join)
又称笛卡尔连接,交叉连接返回两个集合的笛卡尔积。select * from TableA cross join TableB;- 1
-
左连接:
SELECT song.`name` FROM song LEFT JOIN (SELECT song_id FROM list_song WHERE song_list_id BETWEEN 24 AND 50) s ON song.id = s.song_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2. 数据库中事务的四大特性(ACID)
如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性:
-
原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
-
一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
-
隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
-
持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
-
脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B) update account set money=money - 100 where name=’A’;- 1
- 2
- 3
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账( 此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
-
不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
-
虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
-
3. 现在来看看MySQL数据库为我们提供的四种隔离级别:
-
**Serializable (串行化):**可避免脏读、不可重复读、幻读的发生。
-
**Repeatable read (可重复读):**可避免脏读、不可重复读的发生。
-
**Read committed (读已提交):**可避免脏读的发生。
-
**Read uncommitted (读未提交):**最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
4. 索引的优点和缺点
-
为什么要创建索引呢(优点)?
这是因为,创建索引可以大大提高系统的性能。
第一, 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二, 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三, 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四, 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五, 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。 -
建立方向索引的不利因素(缺点)
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点,但是,为表中的每一个列都增加索引,是非常不明智的。这是因为,增加索引也有许多不利的一个方面。第一, 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二, 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三, 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
5. 查询索引怎么建立的?为什么最左前缀?
-
1. 索引建立的原则
用于索引的最好的备选数据列是那些出现在WHERE子句、join子句、ORDER BY或GROUP BY子句中的列。
仅仅出现在SELECT关键字后面的输出数据列列表中的数据列不是很好的备选列
SELECT col_a <- 不是备选列 FROM tbl1 LEFT JOIN tbl2 ON tbl1.col_b = tbl2.col_c <- 备选列 WHERE col_d = expr; <- 备选列- 1
- 2
- 3
- 4
- 5
- 6
- 7
当然,显示的数据列与WHERE子句中使用的数据列也可能相同。
我们的观点是输出列表中的数据列本质上不是用于索引的很好的备选列。 -
2. 复合索引的建立以及最左前缀原则
索引字符串值的前缀(prefixe)。如果你需要索引一个字符串数据列,那么最好在任何适当的情况下都应该指定前缀长度。
例如,如果有CHAR(200)数据列,如果前面10个或20个字符都不同,就不要索引整个数据列。
索引前面10个或20个字符会节省大量的空间
你可以索引CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列的前缀。假设你在表的state、city和zip数据列上建立了复合索引。索引中的数据行按照state/city/zip次序排列,
因此它们也会自动地按照state/city和state次序排列。这意味着,即使你在查询中只指定了state值,
或者指定state和city值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合:
state, city, zip
state, city
stateMySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,
就不会使用到这个索引。如果你搜索给定的state和具体的ZIP代码(索引的1和3列),
该索引也是不能用于这种组合值的,尽管MySQL可以利用索引来查找匹配的state从而缩小搜索的范围。如果你考虑给已经索引过的表添加索引,那么就要考虑你将增加的索引是否是已有的多列索引的最左前缀。
如果是这样的,不用增加索引,因为已经有了(例如,如果你在state、city和zip上建立了索引,那么没有必要再增加state的索引)。
6. 数据库设计(微博评论表)
CREATE TABLE `comment` ( `id` int(10) UNSIGNED NOT NULL AUTO_INCREMENT, `father_id` int(11) NULL DEFAULT NULL, `son_id` int(11) NULL DEFAULT NULL, `user_id` int(11) NULL DEFAULT NULL, `content` varchar(255) NULL DEFAULT NULL, `create_time` datetime NOT NULL, )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
计算某条微博的总评论数:
返回一条微博下面按照时间排序最近的十条评论:
显示某条评论相关的子评论:
SELECT count(*) FROM comment WHERE id = ? SELECT * FROM comment ORDER BY create_time LIMIT 10; SELECT * FROM comment WHERE father_id = ?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7. MySQL慢查询
-
概念
MySQL的慢查询,全名是慢查询日志,是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句。 -
具体环境中,运行时间超过long_query_time值的SQL语句,则会被记录到慢查询日志中。
-
long_query_time的默认值为10,意思是记录运行10秒以上的语句。
-
默认情况下,MySQL数据库并不启动慢查询日志,需要手动来设置这个参数。
-
当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
-
慢查询日志支持将日志记录写入文件和数据库表。
8. 详解MySQL(InnoDB)是如何处理死锁的
-
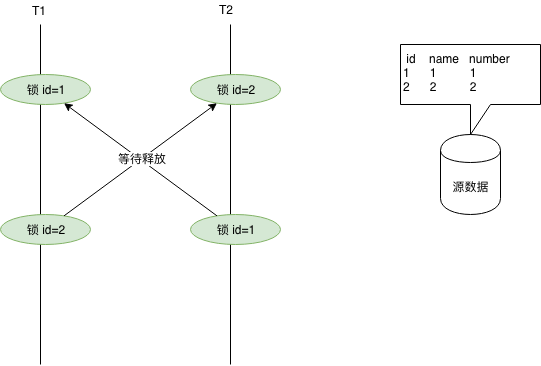
什么是死锁
官方定义如下:两个事务都持有对方需要的锁,并且在等待对方释放,并且双方都不会释放自己的锁。
这个就好比你有一个人质,对方有一个人质,你们俩去谈判说换人。你让对面放人,对面让你放人。
-
为什么会形成死锁
看到这里,也许你会有这样的疑问,事务和谈判不一样,为什么事务不能使用完锁之后立马释放呢?居然还要操作完了之后一直持有锁?这就涉及到 MySQL 的并发控制了。
MySQL的并发控制有两种方式,一个是 MVCC,一个是两阶段锁协议。那么为什么要并发控制呢?是因为多个用户同时操作 MySQL 的时候,为了提高并发性能并且要求如同多个用户的请求过来之后如同串行执行的一样(可串行化调度)。具体的并发控制这里不再展开。咱们继续深入讨论两阶段锁协议。
-
两阶段锁协议(2PL)
官方定义:
两阶段锁协议是指所有事务必须分两个阶段对数据加锁和解锁,在对任何数据进行读、写操作之前,事务首先要获得对该数据的封锁;在释放一个封锁之后,事务不再申请和获得任何其他封锁。
对应到 MySQL 上分为两个阶段:
- 扩展阶段(事务开始后,commit 之前):获取锁
- 收缩阶段(commit 之后):释放锁
就是说呢,只有遵循两段锁协议,才能实现 可串行化调度。
但是两阶段锁协议不要求事务必须一次将所有需要使用的数据加锁,并且在加锁阶段没有顺序要求,所以这种并发控制方式会形成死锁。
-
-
MySQL 如何处理死锁?
MySQL有两种死锁处理方式:
- 等待,直到超时(innodb_lock_wait_timeout=50s)。
- 发起死锁检测,主动回滚一条事务,让其他事务继续执行(innodb_deadlock_detect=on)。
由于性能原因,一般都是使用死锁检测来进行处理死锁。
-
死锁检测
死锁检测的原理是构建一个以事务为顶点、锁为边的有向图,判断有向图是否存在环,存在即有死锁。
-
回滚
检测到死锁之后,选择插入更新或者删除的行数最少的事务回滚,基于 INFORMATION_SCHEMA.INNODB_TRX 表中的 trx_weight 字段来判断。
-
如何避免发生死锁
-
收集死锁信息:
- 利用命令 SHOW ENGINE INNODB STATUS查看死锁原因。
- 调试阶段开启 innodb_print_all_deadlocks,收集所有死锁日志。
-
减少死锁:
- 使用事务,不使用 lock tables 。
- 保证没有长事务。
- 操作完之后立即提交事务,特别是在交互式命令行中。
- 如果在用 (SELECT … FOR UPDATE or SELECT … LOCK IN SHARE MODE),尝试降低隔离级别。
- 修改多个表或者多个行的时候,将修改的顺序保持一致。
- 创建索引,可以使创建的锁更少。
- 最好不要用 (SELECT … FOR UPDATE or SELECT … LOCK IN SHARE MODE)。
- 如果上述都无法解决问题,那么尝试使用 lock tables t1, t2, t3 锁多张表
-
六、Spring
1. 简单介绍Spring是什么?
1、Spring的核心是一个轻量级(Lightweight)的容器(Container)。
2、Spring是实现IoC(Inversion of Control)容器和非入侵性(No intrusive)的框架。
3、Spring提供AOP(Aspect-oriented programming)概念的实现方式。
4、Spring提供对持久层(Persistence)、事物(Transcation)的支持。
5、Spring供MVC Web框架的实现,并对一些常用的企业服务API(Application Interface)提供一致的模型封装。
6、Spring提供了对现存的各种框架(Structs、JSF、Hibernate、Ibatis、Webwork等)相整合的方案。
总之,Spring是一个全方位的应用程序框架。spring 的优点?
1.降低了组件之间的耦合性 ,实现了软件各层之间的解耦
2.可以使用容易提供的众多服务,如事务管理,消息服务等
3.容器提供单例模式支持
4.容器提供了AOP技术,利用它很容易实现如权限拦截,运行期监控等功能
5.容器提供了众多的辅助类,能加快应用的开发
6.spring对于主流的应用框架提供了集成支持,如hibernate,JPA,Struts等
7.spring属于低侵入式设计,代码的污染极低
8.独立于各种应用服务器
9.spring的DI机制降低了业务对象替换的复杂性
10.Spring的高度开放性,并不强制应用完全依赖于Spring,开发者可以自由选择spring的部分或全部
2. Spring MVC
MVC框架
M: Model模型:和数据库进行交互
V: View,视图: 产生html页面
C: Controller,控制器: 接收请求,进行处理,与M和V进行交互,返回应答
MVC 是 Model、View 和 Controller 的缩写,分别代表 Web 应用程序中的 3 种职责。
- 模型:用于存储数据以及处理用户请求的业务逻辑。
- 视图:向控制器提交数据,显示模型中的数据。
- 控制器:根据视图提出的请求判断将请求和数据交给哪个模型处理,将处理后的有关结果交给哪个视图更新显示。
基于 Servlet 的 MVC 模式的具体实现如下。
- 模型:一个或多个 JavaBean 对象,用于存储数据(实体模型,由 JavaBean 类创建)和处理业务逻辑(业务模型,由一般的 Java 类创建)。
- 视图:一个或多个 JSP 页面,向控制器提交数据和为模型提供数据显示,JSP 页面主要使用 HTML 标记和 JavaBean 标记来显示数据。
- 控制器:一个或多个 Servlet 对象,根据视图提交的请求进行控制,即将请求转发给处理业务逻辑的 JavaBean,并将处理结果存放到实体模型
3. Spring Bean的作用域和生命周期
一、Bean的作用域
在Bean容器启动会读取bean的xml配置文件,然后将xml中每个bean元素分别转换成BeanDefinition对象。在BeanDefinition对象中有scope 属性,就是它控制着bean的作用域。
Spring框架支持5种作用域,有三种作用域是当开发者使用基于web的ApplicationContext的时候才生效的。下面就是Spring直接支持的作用域了,当然开发者也可以自己定制作用域。作用域
描述
单例(singleton)
(默认)每一个Spring IoC容器都拥有唯一的一个实例对象
原型(prototype)
一个Bean定义,任意多个对象
请求(request)
一个HTTP请求会产生一个Bean对象,也就是说,每一个HTTP请求都有自己的Bean实例。只在基于web的Spring ApplicationContext中可用
会话(session)
限定一个Bean的作用域为HTTPsession的生命周期。同样,只有基于web的Spring ApplicationContext才能使用
全局会话(global session)
限定一个Bean的作用域为全局HTTPSession的生命周期。通常用于门户网站场景,同样,只有基于web的Spring ApplicationContext可用
二、Bean的生命周期
前面章节介绍了bean容器以及bean的配置与注入,本章节学习bean的生命周期,了解bean是怎么来的又是怎么没的。
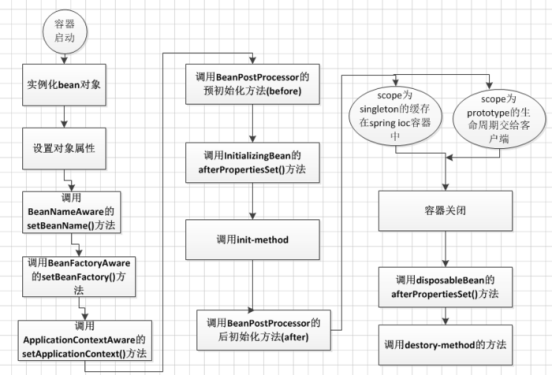
ApplicationContext容器中,Bean的生命周期流程如上图所示,流程大致如下:
- 首先容器启动后,会对scope为singleton且非懒加载的bean进行实例化,
- 按照Bean定义信息配置信息,注入所有的属性,
- 如果Bean实现了BeanNameAware接口,会回调该接口的setBeanName()方法,传入该Bean的id,此时该Bean就获得了自己在配置文件中的id,
- 如果Bean实现了BeanFactoryAware接口,会回调该接口的setBeanFactory()方法,传入该Bean的BeanFactory,这样该Bean就获得了自己所在的BeanFactory,
- 如果Bean实现了ApplicationContextAware接口,会回调该接口的setApplicationContext()方法,传入该Bean的ApplicationContext,这样该Bean就获得了自己所在的ApplicationContext,
- 如果有Bean实现了BeanPostProcessor接口,则会回调该接口的postProcessBeforeInitialzation()方法,
- 如果Bean实现了InitializingBean接口,则会回调该接口的afterPropertiesSet()方法,
- 如果Bean配置了init-method方法,则会执行init-method配置的方法,
- 如果有Bean实现了BeanPostProcessor接口,则会回调该接口的postProcessAfterInitialization()方法,
- 经过流程9之后,就可以正式使用该Bean了,对于scope为singleton的Bean,Spring的ioc容器中会缓存一份该bean的实例,而对于scope为prototype的Bean,每次被调用都会new一个新的对象,期生命周期就交给调用方管理了,不再是Spring容器进行管理了
- 容器关闭后,如果Bean实现了DisposableBean接口,则会回调该接口的destroy()方法,
- 如果Bean配置了destroy-method方法,则会执行destroy-method配置的方法,至此,整个Bean的生命周期结束。
这里在UserBean类基础上进行改造,增加了name属性并实现了ApplicationContextAware接口。
4. Springboot 注解
@PathVariable :
- 通过 @PathVariable 可以将 URL 中占位符参数绑定到控制器处理方法的入参中:URL 中的 {xxx} 占位符可以通过@PathVariable(“xxx“) 绑定到操作方法的入参中。
@RequestBody和@RequestParam
- 两个注解都是用于方法中接收参数使用的,两者也有一定的区别。
- @RequestBody这个一般处理的是在ajax请求中声明contentType: “application/json; charset=utf-8”时候。也就是json数据或者xml(我没用过这个,用的是json)
- @RequestParam这个一般就是在ajax里面没有声明contentType的时候,为默认的。。。urlencode格式时,用这个。
- @RequestBody可以直接将页面中的参数封装成实体类中的数据传输给后端
@PostMapping @GetMapping @RequestMapping
- @GetMapping是一个组合注解,是@RequestMapping(method = RequestMethod.GET)的缩写。
- @PostMapping是一个组合注解,是@RequestMapping(method = RequestMethod.POST)的缩写。
- @RequestMapping是一个非 组合注解,需要自定义请求方式。
@RestController和@Controller
- RestController相当于Controller+ResponseBody注解
如果只是使用@RestController注解Controller,则Controller中的方法无法返回jsp页面,或者html,配置的视图解析器 ,也就是相当于在方法上面自动加了ResponseBody注解,所以没办法跳转并传输数据到另一个页面,所以InternalResourceViewResolver也不起作用,返回的内容就是Return 里的内容,即数据直接甩在当前请求的页面上,适用于ajax异步请求。
5. Springboot各个层之间的联系
Springboot框架分controller层,service层和dao层,分别负责不同的业务。
- Controller层沟通前后端,注解为
@RestController。 - Service层沟通DAO层和Ccontroller层,注解为
@Service。 - DAO层沟通数据库和service层,注解为
@Repository。
View层??Controller层(响应用户请求)??Service层(接口??接口实现类)??DAO层,即Mapper层(抽象类:xxxMapper.java文件,具体实现在xxxMapper.xml)??Model层(实体类:xxx.java)

- entity层/model层/pojo层/domain层:
- 存放的是实体类,属性值与数据库中的属性值保持一致。 实现set和get方法。
- 一般数据库一张表对应一个实体类,类属性同表字段一一对应。
- dao层:即mapper层,
- 对数据库进行持久化操作,他的方法是针对数据库操作的,基本用到的就是增删改查。它只是个接口,只有方法名字,具体实现在mapper.xml中。
- dao层的作用为访问数据库,向数据库发送sql语句,完成数据的增删改查任务。
- service层: 业务层,
- service层即业务逻辑层。
- service层的作用为完成功能设计。
- service层调用dao层接口,接收dao层返回的数据,完成项目的基本功能设计。
- controller层: 控制器层,
- 导入service层,调用service方法,controller通过接收前端传过来的参数进行业务操作,在返回一个指定的路径或者数据表。表单等交互动作的处理,调到Service,将Service层的数据对象返回到视图层
- controller层即控制层。
- controller层的功能为请求和响应控制。
- controller层负责前后端交互,接受前端请求,调用service层,接收service层返回的数据,最后返回具体的页面和数据到客户端。
6. Spring的IOC和AOP原理
本文讲的是面试之Spring框架IOC和AOP的实现原理, IoC(Inversion of Control) (1). IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所。
IoC(Inversion of Control)
(1). IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。 对于Spring而言,就是由Spring来控制对象的生命周期和对象之间的关系;IoC还有另外一个名字——“依赖注入(Dependency Injection)”。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。
(2). 在Spring的工作方式中,所有的类都会在spring容器中登记,告诉spring这是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
(3). 在系统运行中,动态的向某个对象提供它所需要的其他对象。
(4). 依赖注入的思想是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。 总而言之,在传统的对象创建方式中,通常由调用者来创建被调用者的实例,而在Spring中创建被调用者的工作由Spring来完成,然后注入调用者,即所谓的依赖注入or控制反转。 注入方式有两种:依赖注入和设置注入;
IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
什么是DI机制?
依赖注入(Dependecy Injection)和控制反转(Inversion of Control)是同一个概念,具体的讲:当某个角色 需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中 创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 因此也称为依赖注入。 spring以动态灵活的方式来管理对象 , 注入的两种方式,设置注入和构造注入。
设置注入的优点: 直观,自然
通过setter访问器实现
灵活性好,但setter方法数量较多
时效性差
通过无参构造函数实例化构造注入的优点: 可以在构造器中决定依赖关系的顺序。
通过构造方法实现
灵活性差,仅靠重载限制太多
时效性好
通过匹配的构造方法实例化,但建议保留无参构造AOP(Aspect Oriented Programming)
1、AOP面向方面编程基于IoC,是对OOP的有益补充;
2、 AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了 多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的 逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
3、 AOP代表的是一个横向的关 系,将“对象”比作一个空心的圆柱体,其中封装的是对象的属性和行为;则面向方面编程的方法,就是将这个圆柱体以切面形式剖开,选择性的提供业务逻辑。而 剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹,但完成了效果。
4、 实现AOP的技术,主要分为两大类:
一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;
二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。7. Spring实现AOP:JDK动态代理和CGLIB代理
JDK动态代理: 其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理;其核心的两个类是InvocationHandler和Proxy。
CGLIB代理: 实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM(开源的java字节码编辑类库)操作字节码实现的,性能比JDK强;需要引入包asm.jar和cglib.jar。
使用AspectJ注入式切面和@AspectJ注解驱动的切面实际上底层也是通过动态代理实现的。
AOP使用场景:
Authentication 权限检查
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 延迟加载
Debugging 调试
logging, tracing, profiling and monitoring 日志记录,跟踪,优化,校准
Performance optimization 性能优化,效率检查
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务管理
另外Filter的实现和struts2的拦截器的实现都是AOP思想的体现。8. RestFul 规范是怎么样的?
通用的接口规范:Restful 接口规范 - 规定了url如何编写;请求方式的含义;响应的数据规则
-
url 编写
https协议 - 保证数据安全性
api字眼 - 标识操作的是数据
v1、v2字眼 - 数据的不同版本共存
资源复数 - 请求的数据称之为资源
拼接条件 - 过滤群查接口数据(https://api.baidu.com/books/limit=3&ordering=-price)
# 版本:应该将API的版本号放入URL http://www.example.com/app/1.0/apples http://www.example.com/app/1.1/apples http://www.example.com/app/2.0/apples # 路劲:对于一个简洁结构,你应该始终用名词。 此外,利用的HTTP方法可以分离网址中的资源名称的操作。 GET /products :将返回所有产品清单 POST /products :将产品新建到集合 GET /products/4 :将获取产品4 PATCH /products/4 将更新产品4(部分属性更新) PUT /products/4:将更新产品4 (全部属性更新)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
请求方式
/books/ - get - 群查
/books/(pk)/ - get - 单查
/books/ - post - 单增
/books/(pk)/ - put - 单整体改
/books/(pk)/ - patch - 单局部改
/books/(pk)/ - delete - 单删
请求方法
请求地址
后端操作
GET
/students
获取所有学生
POST
/students
增加学生
GET
/students/1
获取编号为1的学生
PUT
/students/1
更新编号为1的学生(全部属性)
DELETE
/students/1
删除编号为1的学生
PATCH
/students/1
更新编号为1的学生(部分属性)
-
响应结果
网络状态码与状态信息:2xx | 3xx | 4xx | 5xx
数据状态码:前后台约定规则 - 0:成功 1:失败 2:成功无结果
数据状态信息:自定义成功失败的信息解释(英文)
数据本体:json数据
数据子资源:头像、视频等,用资源的url链接
# 状态码 200 OK - [GET]:服务器成功返回用户请求的数据 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - []:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作 401 Unauthorized - []:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - []:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。 # 返回结果 GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
9. @Autowired 与@Resource的区别
-
@Autowired是根据类型进行自动装配的。如果当Spring上下文中存在不止一个UserDao类型的bean时,就会抛出BeanCreationException异常;如果Spring上下文中不存在UserDao类型的bean,也会抛出BeanCreationException异常。我们可以使用@Qualifier配合@Autowired来解决这些问题。
-
@Resource有两个属性是比较重要的,分是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
- @Resource装配顺序
- 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
- 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
- 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
- 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
- @Resource装配顺序
-
@Autowired 与@Resource的区别:
-
@Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
-
@Autowired默认按类型(byType)装配(这个注解是属于spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
@Autowired ()
@Qualifier ( “TestService” )
private TestService testService; -
@Resource(这个注解属于J2EE的),默认按照名称(byName)进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource (name= "TestService" ) private TestService testService;- 1
- 2
-
Redis是什么
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
- 基于内存运行,性能高效
- 支持分布式,理论上可以无限扩展
- key-value存储系统
- 开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型
- 操作具有原子性
- 持久化
- 高并发读写
- 支持lua脚本
Redis的应用场景有哪些?
Redis 的应用场景包括:缓存系统(“热点”数据:高频读、低频写)、计数器、消息队列系统、排行榜、社交网络和实时系统。

Redis的数据类型及主要特性
Redis提供的数据类型主要分为5种自有类型和一种自定义类型,这5种自有类型包括:String类型、哈希类型、列表类型、集合类型和顺序集合类型。

爬虫系统设计
爬虫系统的组成部分
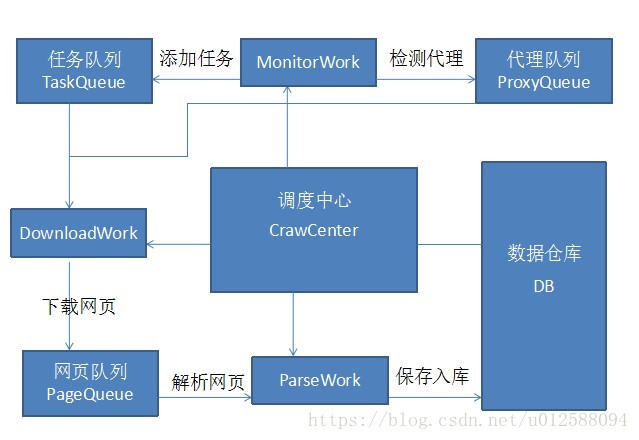
爬虫的组件
下载任务解析任务
检测任务
调度中心
任务队列
数据仓库
代理任务
从上面的图片中可以清晰的看出整个爬虫系统 在单机的状态是如何工作的,其实整个系统看起来就是消费者和生产者的关系,所以需要一个装载任务的容器,那么这个容器要有基本的要求:断点续传,能够在项目意外暂停的时候,保存未消费的任务状态,记录已经消费的任务状态,这样当项目重启的时候,能够加载未消费的任务然后继续消费?给出两种方案:
一、通过数据库记录每一条任务的状态,比如添加一个selected字段标识这条任务是否在队列,添加status字段标识这条任务是否被消费过,一旦任务消费了,立马改变status字段状态,selected状态,这样系统突然停止的话,根据selected标识还未被消费的状态,然后把这部分数据添加到系统的任务队列之中,这样的策略虽然能够达到要求,但是不足的地方要不断的和数据库进行通信,要经受大量的写请求,那么要求数据库对表级锁的支持要必须好,性能方面不适合大规模的抓取任务。
二、通过文件存储来实现对任务状态的记录,每次任务队列中拿到的数据都会存储到一个文件中,按照文件大小做rollingFile,那么每一个新的任务加进来,都会首先被放到一个head文件,当head文件不停增长的时候,到一定大小的时候,一个新的head文件就会被加进来,同时有一个checkpoint的文件,记录任务的消费状态,难么当系统异常重启的时候,通过checkpoint文件定位到已经消费到的文件位置,然后把对应位置以后的所有任务都添加到任务队列中,达到记录任务的状态与持久化存储。七、计算机网络
1. GET 和 POST请求区别是什么?
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
2. session和cookie的区别,这个技术是解决什么问题
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。 - session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。 - 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
- Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
3. TCP和UDP
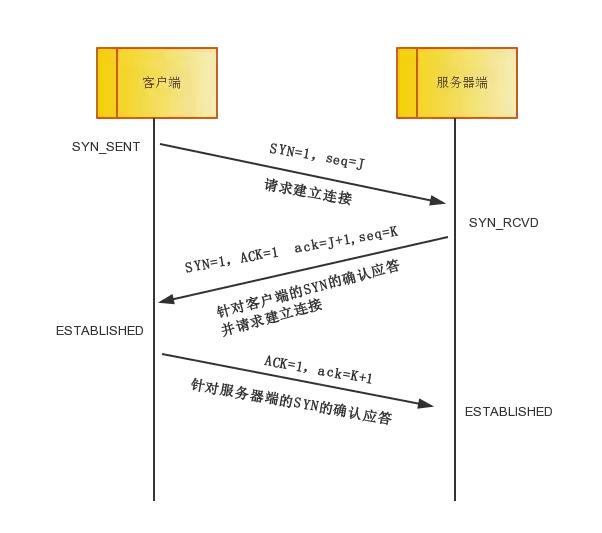
第一次握手: 主机A通过向主机B 发送一个含有同步序列号的标志位的数据段给主机B,向主机B 请求建立连接,通过这个数据段, 主机A告诉主机B 两件事:我想要和你通信;你可以用哪个序列号作为起始数据段来回应我。
第二次握手: 主机B 收到主机A的请求后,用一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A,也告诉主机A两件事:我已经收到你的请求了,你可以传输数据了;你要用那个序列号作为起始数据段来回应我
第三次握手: 主机A收到这个数据段后,再发送一个确认应答,确认已收到主机B 的数据段:"我已收到回复,我现在要开始传输实际数据了,这样3次握手就完成了,主机A和主机B 就可以传输数据了。
3次握手的特点
没有应用层的数据 ,SYN这个标志位只有在TCP建立连接时才会被置1 ,握手完成后SYN标志位被置0。
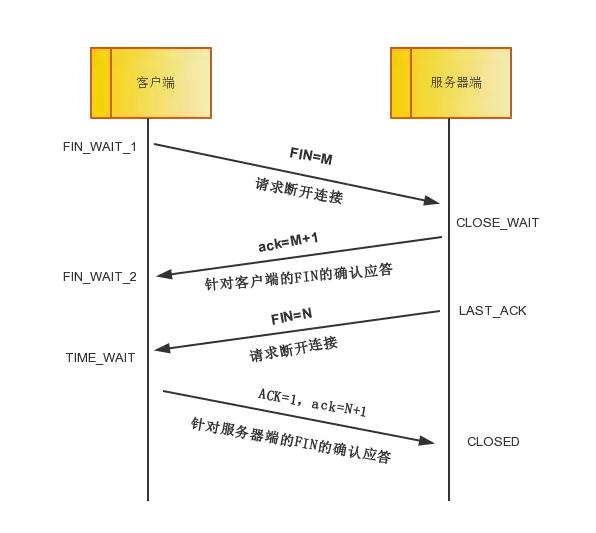
第一次: 当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求 ;FIN-WAIT
第二次: 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1;CLOSE-WAIT
第三次: 由B 端再提出反方向的关闭请求,将FIN置1 ;LAST-ACK
第四次: 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束.。CLOSED
由TCP的三次握手和四次断开可以看出,TCP使用面向连接的通信方式, 大大提高了数据通信的可靠性,使发送数据端和接收端在数据正式传输前就有了交互, 为数据正式传输打下了可靠的基础。
名词解释
1、ACK 是TCP报头的控制位之一,对数据进行确认。确认由目的端发出, 用它来告诉发送端这个序列号之前的数据段都收到了。 比如确认号为X,则表示前X-1个数据段都收到了,只有当ACK=1时,确认号才有效,当ACK=0时,确认号无效,这时会要求重传数据,保证数据的完整性。
2、SYN 同步序列号,TCP建立连接时将这个位置1。
3、FIN 发送端完成发送任务位,当TCP完成数据传输需要断开时,,提出断开连接的一方将这位置1。
4. TCP与UDP区别总结:
- TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
- TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
- TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等) - 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
- TCP首部开销20字节;UDP的首部开销小,只有8个字节
- TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
5. TCP/IP
- 物理层:
- 作用:定义一些电器,机械,过程和规范,如集线器;
- PDU(协议数据单元):bit/比特
- 设备:集线器HUB;
- 注意:没有寻址的概念;
- 数据链路层:
- 作用:定义如何格式化数据,支持错误检测;
- 典型协议:以太网,帧中继(古董级VPN)
- PDU:frame(帧)设备:以太网交换机;
- 备注:交换机通过MAC地址转发数据,逻辑链路控制;
- 网络层:
- 作用:定义一个逻辑的寻址,选择最佳路径传输,路由数据包;
- 典型协议:IP,IPX,ICMP,ARP(IP->MAC),IARP;
- PDU:packet/数据包;
- 设备:路由器
- 备注:实现寻址
- 传输层:
- 作用:提供可靠和尽力而为的传输;
- 典型协议:TCP,UDP,SPX,port(65535个端口),EIGRP,OSPF,
- PDU:fragment 段;
- 无典型设备;
- 备注:负责网络传输和会话建立;
- 会话层:
- 作用:控制会话,建立管理终止应用程序会话;
- 典型协议:NFS, SQL, ASP, PHP, JSP, RSVP(资源源预留协议), windows,
- 备注:负责会话建立;
- 表示层:
- 作用:格式化数据;
- 典型协议:ASCII, JPEG. PNG, MP3. WAV, AVI,
- 备注:可以提供加密服务;
- 应用层:
- 作用:控制应用程序;
- 典型协议:telnet, ssh, http, ftp, smtp, rip, BGP, (未完待续)
- 备注:为应用程序提供网络服务;
Q:什么时候有PDU?
A:当需要跟别人通信时候才有。
6. 死锁产生的4个必要条件?
-
产生死锁的必要条件:
互斥条件: 进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
请求和保持条件: 当进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件: 进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
环路等待条件: 在发生死锁时,必然存在一个进程–资源的环形链。
7. RPC基本原理及框架
RPC非常重要,很多人面试的时候都挂在了这个地方!你要是还不懂RPC是什么?他的基本原理是什么?你一定要把下边的内容记起来!好好研究一下!特别是文中给出的一张关于RPC的基本流程图,重点中的重点,Dubbo RPC的基本执行流程就是他,RPC框架的基本原理也是他,别说我没告诉你!看了下边的内容你要掌握的内容如下,当然还有很多:
1、 RPC的由来,是怎样一步步演进出来的;
2、 RPC的基本架构是什么;
3、 RPC的基本实现原理,就是下边的这张图,重点中的重点;;
一、为什么要有RPC
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
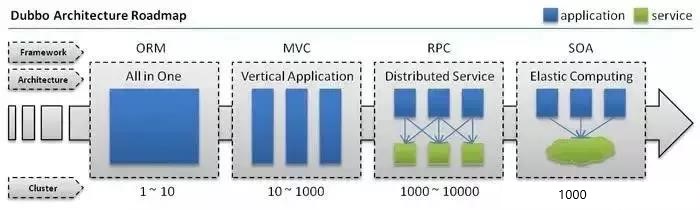
1、单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM) 是关键。
2、垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
3、分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
此时,用于提高业务复用及整合的分布式服务框架(RPC),提供统一的服务是关键。
例如:各个团队的服务提供方就不要各自实现一套序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等“业务之外”的重复技术劳动,造成整体的低效。
流动计算架构
PS:这个属于扩展内容,摘自Dubbo官网,属于架构演进的一个过程
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
4、另外一个原因
就是因为在几个进程内(应用分布在不同的机器上),无法共用内存空间,或者在一台机器内通过本地调用无法完成相关的需求,比如不同的系统之间的通讯,甚至不同组织之间的通讯。此外由于机器的横向扩展,需要在多台机器组成的集群上部署应用等等。
所以,统一RPC框架来解决提供统一的服务。
二、什么是RPC
RPC(Remote Procedure Call Protocol)远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。简言之,RPC使得程序能够像访问本地系统资源一样,去访问远端系统资源。比较关键的一些方面包括:通讯协议、序列化、资源(接口)描述、服务框架、性能、语言支持等。
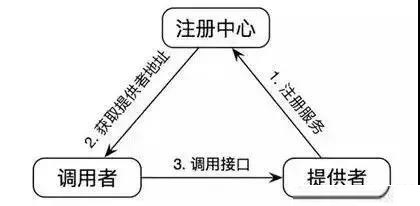
简单的说,RPC就是从一台机器(客户端)上通过参数传递的方式调用另一台机器(服务器)上的一个函数或方法(可以统称为服务)并得到返回的结果。
三、PRC架构组件
一个基本的RPC架构里面应该至少包含以下4个组件:
1、客户端(Client):
服务调用方(服务消费者)
2、客户端存根(Client Stub):
存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):
接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):
服务的真正提供者
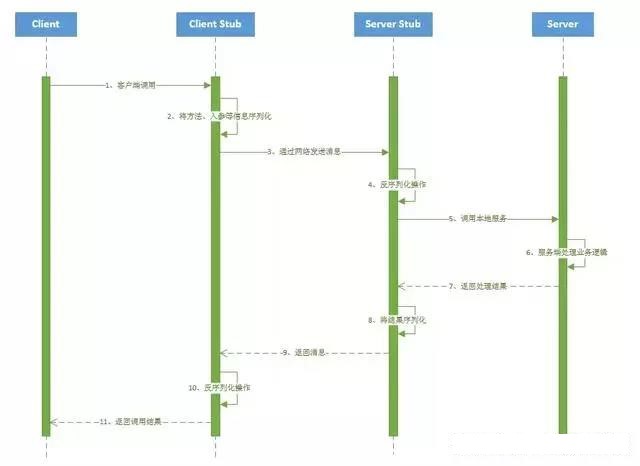
具体调用过程:
1、 服务消费者(client客户端)通过调用本地服务的方式调用需要消费的服务;
2、 客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体;
3、 客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端;
4、 服务端存根(server stub)收到消息后进行解码(反序列化操作);
5、 服务端存根(server stub)根据解码结果调用本地的服务进行相关处理;
6、 本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub);
7、 服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方;
8、 客户端存根(client stub)接收到消息,并进行解码(反序列化);
9、 服务消费方得到最终结果;
而RPC框架的实现目标则是将上面的第2-10步完好地封装起来,也就是把调用、编码/解码的过程给封装起来,让用户感觉上像调用本地服务一样的调用远程服务。
八、设计模式
一、前言
设计模式是解决问题的方案,学习现有的设计模式可以做到经验复用。拥有设计模式词汇,在沟通时就能用更少的词汇来讨论,并且不需要了解底层细节。
二、创建型
1. 单例模式(Singleton)
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提 供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
-
意图: 保证一个类仅有一个实例,并提供一个访问它的全局访问点。
-
主要解决: 一个全局使用的类频繁地创建与销毁。
-
何时使用: 当您想控制实例数目,节省系统资源的时候。‘
-
如何解决: 判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
-
关键代码: 构造函数是私有的。
-
应用实例:
- 一个班级只有一个班主任。
- Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
- 一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
-
优点:
- 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 避免对资源的多重占用(比如写文件操作)。
-
缺点:
- 没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
-
使用场景:
- 要求生产唯一序列号。
- WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
-
单例模式的几种实现方式:
-
懒汉式,线程不安全
描述: 这种方式是最基本的实现方式,这种实现最大的问题就是不支持多线程。因为没有加锁 synchronized,所以**严格意义上它并不算单例模式 **。
这种方式 lazy loading 很明显,不要求线程安全,在多线程不能正常工作。public class Singleton { private static Singleton instance; private Singleton (){} public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
接下来介绍的几种实现方式都支持多线程,但是在性能上有所差异。
-
懒汉式,线程安全
描述: 这种方式具备很好的 lazy loading,能够在多线程中很好的工作,但是,效率很低,99% 情况下不需要同步。
优点: 第一次调用才初始化,避免内存浪费。
缺点: 必须加锁 synchronized 才能保证单例,但加锁会影响效率。
getInstance() 的性能对应用程序不是很关键(该方法使用不太频繁)。public class Singleton { private static Singleton instance; private Singleton (){} public static synchronized Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
饿汉式,线程安全
描述: 这种方式比较常用,但容易产生垃圾对象。
优点: 没有加锁,执行效率会提高。
缺点: 类加载时就初始化,浪费内存。
它基于 classloader 机制避免了多线程的同步问题,不过,instance 在类装载时就实例化,虽然导致类装载的原因有很多种,在单例模式中大多数都是调用 getInstance 方法, 但是也不能确定有其他的方式(或者其他的静态方法)导致类装载,这时候初始化 instance 显然没有达到 lazy loading 的效果。public class Singleton { private static Singleton instance = new Singleton(); private Singleton (){} public static Singleton getInstance() { return instance; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
-
双检锁/双重校验锁(DCL,即 double-checked locking)
描述: 懒加载、线程安全、这种方式采用双锁机制,安全且在多线程情况下能保持高性能。
getInstance() 的性能对应用程序很关键。public class Singleton { private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-
登记式/静态内部类
描述: 这种方式能达到双检锁方式一样的功效,但实现更简单。对静态域使用延迟初始化,应使用这种方式而不是双检锁方式。这种方式只适用于静态域的情况,双检锁方式可在实例域需要延迟初始化时使用。
这种方式同样利用了 classloader 机制来保证初始化 instance 时只有一个线程,它跟第 3 种方式不同的是:第 3 种方式只要 Singleton 类被装载了,那么 instance 就会被实例化(没有达到 lazy loading 效果),而这种方式是 Singleton 类被装载了,instance 不一定被初始化。因为 SingletonHolder 类没有被主动使用,只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance。想象一下,如果实例化 instance 很消耗资源,所以想让它延迟加载,另外一方面,又不希望在 Singleton 类加载时就实例化,因为不能确保 Singleton 类还可能在其他的地方被主动使用从而被加载,那么这个时候实例化 instance 显然是不合适的。这个时候,这种方式相比第 3 种方式就显得很合理。public class Singleton { private static class SingletonHolder { private static final Singleton INSTANCE = new Singleton(); } private Singleton (){} public static final Singleton getInstance() { return SingletonHolder.INSTANCE; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
枚举
描述: 非懒加载、线程安全。这种实现方式还没有被广泛采用,但这是实现单例模式的最佳方法。它更简洁,自动支持序列化机制,绝对防止多次实例化。
这种方式是 Effective Java 作者 Josh Bloch 提倡的方式,它不仅能避免多线程同步问题,而且还自动支持序列化机制,防止反序列化重新创建新的对象,绝对防止多次实例化。不过,由于 JDK1.5 之后才加入 enum 特性,用这种方式写不免让人感觉生疏,在实际工作中,也很少用。
不能通过 reflection attack 来调用私有构造方法。public enum Singleton { INSTANCE; public void whateverMethod() { } }- 1
- 2
- 3
- 4
- 5
经验之谈: 一般情况下,不建议使用第 1 种和第 2 种懒汉方式,建议使用第 3 种饿汉方式。只有在要明确实现 lazy loading 效果时,才会使用第 5 种登记方式。如果涉及到反序列化创建对象时,可以尝试使用第 6 种枚举方式。如果有其他特殊的需求,可以考虑使用第 4 种双检锁方式。
-
简单工厂(Simple Factory)
在创建一个对象时不向客户暴露内部细节,并提供一个创建对象的通用接口。
-
工厂方法(Factory Method)
定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类。
-
抽象工厂(Abstract Factory)
提供一个接口,用于创建 相关的对象家族 。
-
生成器(Builder)
封装一个对象的构造过程,并允许按步骤构造。
-
原型模式(Prototype)
使用原型实例指定要创建对象的类型,通过复制这个原型来创建新对象。
三、行为型
-
责任链(Chain Of Responsibility)
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链发送该请求,直到有一个对象处理它为止。
-
命令(Command)
将命令封装成对象中,具有以下作用:
- 使用命令来参数化其它对象
- 将命令放入队列中进行排队
- 将命令的操作记录到日志中
- 支持可撤销的操作
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
-
-
相关阅读:
Java.lang.Class类 getConstructors()方法有什么功能呢?
WebXR 技术调研 - 在浏览器中构建扩展现实(XR)应用
CSS媒体查询简介及案例
关于#c++#的问题:在while(true)添加cout<<"按学号删除学生记录"<<endl
聊聊MySQL面试常问名词回表、索引覆盖,最左匹配
Tensorflow模型整体构建流程
Linux 添加路由的方法
SpringBoot-内容协商
Linux 7:mybash的实现和进程间通信
中国智能音箱市场销量下降,百度稳居第一 /中国即评出10个大模型创新案例 |魔法半周报
- 原文地址:https://blog.csdn.net/m0_67402125/article/details/126110224
