-
【地平线 开发板】实现模型转换并在地平线开发板上部署的全过程操作记录(魔改开发包)
1 背景介绍
之前花了很长时间,磕磕碰碰终于把服务器端训练得到的模型成功跑在地平线开发板上,用的还是Python推理(被鄙视了),感兴趣的可以查看另一篇博文:PyTorch实现神经网络自制分类数据集的训练并将其部署在地平线旭日3开发板上的全流程。
这段时间总感觉心里不太舒服,我只是想在开发板上跑一个分类模型而已,也太费事了吧!
最近,我又去学了亿点点,后知后觉,发现这个过程其实还挺简单的,只是自己刚开始学的时候,不会用而已(真香)!
为了方便和我水平类似的初级开发者,结合自己之前的经历,把困扰自己的一些问题记录一下。
同时,以mobilenetv1分类模型为例,把自己用到的部分从开发包里抽取出来,方便以后快速学习,不用再跳"老远"去调用文件!
如果大家看这篇文章有任何吃力的地方,欢迎查看我写的其它博文或者问地平线的技术支持哈!
如果大家对这篇文章有任何修改建议的话,欢迎评论留言哦,我在空闲时会修改的!2 基础知识问答
作为一个只会在服务器上跑跑开源代码的CV工程师(本调参侠),第一次使用开发板跑模型,可能会有以下几点疑问:
问题1: 服务器上训练得到的模型不可以直接运行在地平线开发板上?
答: 不可以,这是由于芯片的计算架构不同导致的,因此我们需要“工具链”帮我们把模型运行起来。问题2: 什么是工具链?什么是AI工具链?
答:
工具链: 将程序代码转换为机器能够理解的指令集,这个过程中使用到的一些列软件工具集。AI 工具链: 在实现人工智能业务场景落地过程中,完成AI算法模型部署所涉及到的一系列软件工具集,具有模型量化、优化、编译、部署、调试等功能。
问题3: AI工具链的相关知识只适用于地平线一家公司吗?
答: 知识是互通的,包括华为、英伟达、地平线等,AI工具链的使用过程趋同,主要包括模型准备、转换(量化、编译)、验证、板端部署四个部分。问题4: 为什么要去学习地平线的AI工具链?它有什么特色呢?
答: 听说挺好用的,具体调研之后再来回答吧。问题5: CMake没学过,C++没学过,能在地平线开发板上跑一个深度学习模型吗?
答: 这两个我都没学过,这次用地平线开发包里的例子跑起来了,哈哈哈。下面开始介绍正文。
3 文件准备与简介
本文所有用到的文件如下:
. ├── mobilenetv1_224x224_export_bin │ ├── 01_check.sh │ ├── 02_preprocess.sh │ ├── 03_build.sh │ ├── 04_inference.sh │ ├── 05_evaluate.sh │ ├── data │ ├── mobilenet_config.yaml │ ├── origin_model │ └── utils ├── mobilenetv1_complile_board │ ├── code │ │ ├── build_j5.sh │ │ ├── CMakeLists.txt │ │ ├── deps_gcc9.3 │ │ └── mobilenetv1_main │ └── j5 │ ├── data │ ├── model │ └── script └── run_docker.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
文件简介如下:
-
run_docker.sh文件:运行这个脚本,即可进入docker环境中 -
mobilenetv1_224x224_export_bin文件夹:把服务器端训练得到的模型转换生成可以上板运行的bin模型(二进制文件)
01_check.sh:把模型转换快速跑一遍,看是否报错
02_preprocess.sh:处理一些图片,用于后面模型量化
03_build.sh:结合mobilenet_config.yaml,转换生成可以上板的bin模型
04_inference.sh:推理一张图片
05_evaluate.sh:推理验证集所有图片
data文件夹:存放数据集图片和标签
mobilenet_config.yaml:用于模型转换的配置文件,简单配置一下即可
origin_model文件夹:存放服务器端训练得到的模型(onnx模型)
utils文件夹:存放模型推理前后处理python代码,用于调试mobilenetv1_complile_board文件夹:CMake编译,生成上板运行的模型和代码
build_j5.sh:运行它即可完成CMake编译
CMakeLists.txt:build_j5.sh会调用它
deps_gcc9.3:高深了,不用改
mobilenetv1_main文件夹:里面是可修改的c++代码,不难
script文件夹:里面是一个sh脚本,用于在开发板上运行代码4 模型转换与验证
4.1 总体介绍
该小节所有操作均在开发机中运行,主要操作过程如下图:

最后,生成符合精度预期的、可上板运行的bin模型。4.2 具体操作过程
- 进入docker开发环境及
mobilenetv1_224x224_export_bin文件夹
[yxw@gpu-dev006 mobilenetv1_horizon]$ sh run_docker.sh ...下载docker镜像,自动配置并进入开发环境 [root@d94b878f5717 open_explorer]# cd mobilenetv1_224x224_export_bin- 1
- 2
- 3
- 运行
01_check.sh,检查能否完成全流程
[root@d94b878f5717 mobilenetv1_224x224_export_bin]# sh 01_check.sh 2022-07-30 17:20:39,088 INFO Start hb_mapper.... ... fc7 BPU id(0) HzSQuantizedConv prob CPU -- Softmax 2022-07-30 17:20:46,458 INFO [Fri Jul 29 17:20:46 2022] End to Horizon NN Model Convert. 2022-07-30 17:20:46,463 INFO ONNX model output num : 1 2022-07-30 17:20:46,472 INFO End model checking....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 运行
02_preprocess.sh,获取校准数据,用于后面模型量化
[root@d94b878f5717 mobilenetv1_224x224_export_bin]# sh 02_preprocess.sh python3 ./utils/data_preprocess.py \ --src_dir ./data/calibration_data/imagenet \ --dst_dir ./calibration_data_bgr \ --pic_ext .bgr \ --read_mode skimage \ --saved_data_type float32 regular preprocess write:./calibration_data_bgr/ILSVRC2012_val_00000001.bgr ...处理得到的图片文件放在这儿 write:./calibration_data_bgr/ILSVRC2012_val_00000100.bgr- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
生成的文件如下:
├── mobilenetv1_224x224_export_bin │ ├── calibration_data_bgr │ │ ├── ILSVRC2012_val_00000001.bgr │ │ ├── ... │ │ └── ILSVRC2012_val_00000100.bgr- 1
- 2
- 3
- 4
- 5
- 运行
03_build.sh,生成可以上板运行的bin模型
[root@d94b878f5717 mobilenetv1_224x224_export_bin]# sh 03_build.sh cd $(dirname $0) || exit config_file="./mobilenet_config.yaml" model_type="caffe" # build model hb_mapper makertbin --config ${config_file} \ --model-type ${model_type} 2022-07-30 17:36:12,358 INFO Start hb_mapper.... ...一系列转换过程中生成的日志 2022-07-30 17:37:50,502 INFO Convert to runtime bin file sucessfully! 2022-07-30 17:37:50,502 INFO End Model Convert- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在这一步会生成转换后的bin模型,保存在
model_output文件夹下:├── mobilenetv1_224x224_export_bin │ ├── model_output │ │ ├── MOBILENET_subgraph_0.html │ │ ├── MOBILENET_subgraph_0.json │ │ ├── mobilenetv1_224x224_nv12.bin # 可以上开发板运行的文件 │ │ ├── mobilenetv1_224x224_nv12_optimized_float_model.onnx │ │ ├── mobilenetv1_224x224_nv12_original_float_model.onnx │ │ └── mobilenetv1_224x224_nv12_quantized_model.onnx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 运行
04_inference.sh,推理一张图片,看结果是否正确
[root@d94b878f5717 mobilenetv1_224x224_export_bin]# sh 04_inference.sh python3 -u ./utils/cls_inference.py \ --model ${model} \ --image ${infer_image} \ --input_layout ${layout} \ --input_offset ${input_offset} 2022-07-30 17:40:46,281 INFO The input picture is classified to be: 2022-07-30 17:40:46,281 INFO label 340, prob 0.97917, class ['zebra'] 2022-07-30 17:40:46,281 INFO label 292, prob 0.01693, class ['tiger, Panthera tigris'] 2022-07-30 17:40:46,282 INFO label 282, prob 0.00274, class ['tiger cat'] 2022-07-30 17:40:46,282 INFO label 83, prob 0.00066, class ['prairie chicken, prairie grouse, prairie fowl'] 2022-07-30 17:40:46,282 INFO label 290, prob 0.00004, class ['jaguar, panther, Panthera onca, Felis onca']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 运行
sh 05_evaluate.sh,推理整个验证集,此处为节约资源,只推理了20张图片
[root@d94b878f5717 mobilenetv1_224x224_export_bin]# sh 05_evaluate.sh quanti test python3 -u ./utils/cls_evaluate.py \ --model ${model} \ --image_path ${imagenet_data_path} \ --label_path ${imagenet_label_path} \ --input_layout ${layout} \ --input_offset ${input_offset} 2022-07-30 17:51:12,957 INFO Init 10 processes 2022-07-30 17:51:13,157 INFO Feed batch 0/20 2022-07-30 17:51:13,161 INFO Eval batch 0/20 ... Feed一次,Eval一次 2022-07-30 17:51:15,344 INFO Feed batch 19/20 2022-07-30 17:51:15,408 INFO Eval batch 19/20 2022-07-30 17:51:16,392 INFO Batch:10/20; accuracy(all):0.5000 2022-07-30 17:51:16,393 INFO Batch:20/20; accuracy(all):0.6500 ===REPORT-START{MAPPER-EVAL}=== 0.6500 ===REPORT-END{MAPPER-EVAL}===- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
至此,在开发机中完成了生成可以上板运行的bin模型,也在开发机仿真环境(docker)中,通过
04_inference.sh和05_evaluate.sh验证了转换过程(03_build.sh)中间产物的推理效果,下面就该通过CMake构建c++工程了!5 CMake构建C++工程
作为一个不会CMake,也不会C++的小白,真心谢谢地平线提供的参考示例代码!
该小节所有操作均在开发机中运行。

在docker环境下,进入mobilenetv1_complile_board/code文件夹,运行build_j5.sh脚本,[root@d94b878f5717 code]# sh build_j5.sh + set -e ...编译过程略 + rm -rf arm_build- 1
- 2
- 3
- 4
这一步会在
mobilenetv1_complile_board/j5/script/文件夹下生成一个aarch64文件夹,里面放着编译生成的文件,如下图所示:

j5文件夹下的整体内容介绍如下图:

此时,我们只需要把j5文件夹下的所有内容传到开发板上即可,命令如下。scp -r j5/ root@10.64.61.209:/userdata/yx.w/code/class/- 1
传输完成后,开发板端文件目录如下:

6 开发板端推理一张图片
该小节所有操作均在开发板中运行。
上一节将
j5文件夹整个传输到开发板上,进入j5/script/mobilenetv1_main/文件夹下,运行run_mobilenetV1.sh文件,完成板端推理,如下图所示:
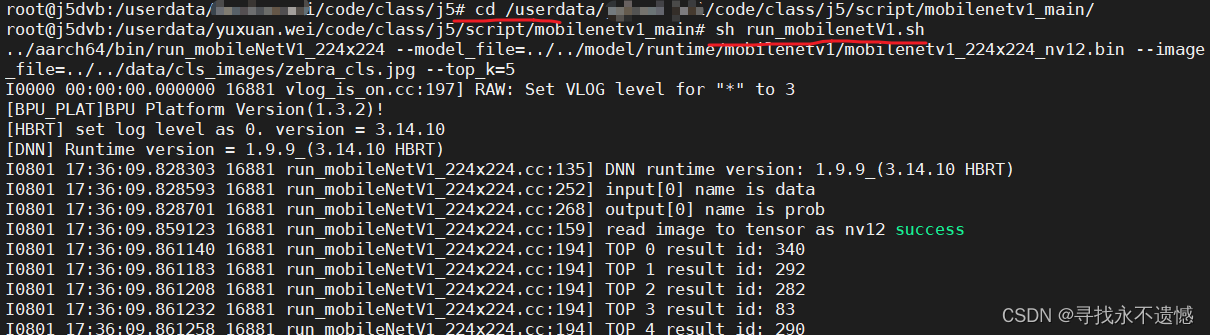
可以根据result id到标签txt文件中查看对应类别。至此,完成全过程。
7 一些思考
- 还好多学了一会地平线AI工具链的相关知识,材料真的全,使用示例代码去改,省时省力。
- 开发包也太大了吧,为了全面,感觉初始学习成本有点高,文件夹套文件夹,有点晕,对于我这种只是想在开发板上简单跑个深度学习分类、检测的人来说,学的时间有点久。
- 每次去看各种技术直播,最后都会感慨一句,“牛批!”,然后…大家有没有那种很基础的教学视频推荐啊~
- 未完待续…
-
相关阅读:
宠物赛道意外火了,行业龙头们相继奔赴IPO
智慧公厕解决方案易集成好使用的智能硬件
BeanUtils.copyProperties在spring包和apache包中使用情况
EN 1154建筑五金件受控关门装置—CE认证
【第十五篇】商城系统-商品详情页功能实现
day32 泛型 数据结构 List
冯诺依曼体系各硬件工作原理解析
推荐两款开源的绘制流程图软件
创建自己数据集全套流程
推荐系统 推荐算法 (小红书为例) 笔记 2
- 原文地址:https://blog.csdn.net/weixin_45377629/article/details/126061682
