-
(五)fastai应用
目前:fastai lesson8~lesson11的部分都重构了
- mnist数据集比较简单、28×28的像素,都是一样的。背景也比较干净,同时是分类任务,用简单的网络就可以处理的。
- 由于数据集过于简单,没办法看到一些基本操作的效果,改为后面的Imagenette的数据集
1. 使用线性模型
pytorch中的参数初始化方法总结_ys1305的博客-CSDN博客_reset_parameters
model = nn.Sequential(nn.Linear(), nn.ReLU(), nn.Linear())
- pytorch的默认初始化,在各个层的reset_parameters()方法中。

- # 在这里对mnist数据集进行分类处理,实现acc的提升
- from exp.nb_09c import *
- """ 0.数据准备
- 没有用自己写的DataBunch,ItemList等接口。ImageList的get是要去open的
- mnist走的还是pytorch的Dataloader的接口
- """
- x_train,y_train,x_valid,y_valid = get_data() # 这个函数在nb_02.py中定义
- x_train,x_valid = normalize_to(x_train,x_valid) # nb_05.py中
- n,m = x_train.shape
- c = y_train.max().item() + 1
- bs = 512
- # 使用Dataset来管理batch数据: nb_03.py
- train_ds,valid_ds = Dataset(x_train, y_train),Dataset(x_valid, y_valid)
- # nb_08.py get_dls在nb_03.py,使用的是Dataloader
- data = DataBunch(*get_dls(train_ds, valid_ds, bs), c)
- loss_func = F.cross_entropy
- """ 1. 线性模型(50,10),使用pytorch的nn.Module基类,不重构了
- """
- nh = 50
- def init_linear_(m, f):
- if isinstance(m, nn.Linear):
- f(m.weight, a=0.1)
- if getattr(m, 'bias', None) is not None: m.bias.data.zero_()
- for l in m.children(): init_linear_(l, f)
- def init_linear(m, uniform=False):
- f = init.kaiming_uniform_ if uniform else init.kaiming_normal_
- init_linear_(m, f)
- # ① model,由于是自定义的线性模型,没有初始化
- model = nn.Sequential(nn.Linear(m, nh), nn.ReLU(), nn.Linear(nh, c))
- lr = 0.5
- # get_runner nb_06.py 由于不是CNN网络,所以不是get_cnn_runner
- # 使用get_runner而不是get_learner
- # device = torch.device('cuda', 0)
- # torch.cuda.set_device(device)
- cbfs = [partial(AvgStatsCallback, accuracy), CudaCallback, Recorder, ProgressCallback]
- phases = combine_scheds([0.3, 0.7], cos_1cycle_anneal(0.2, 0.6, 0.2))
- sched = ParamScheduler('lr', phases)
- # Learner在nb_09b.py 线性模型、交叉熵loss、lr、cbfs、opt 在Learner.fit中有opt的初始化函数的。
- # ② 优化器 nb_09b.py 简单的sgd梯度下降,weight_decay是l2正则化
- learn = Learner(model=model, data=data, loss_func=loss_func, lr=lr, cb_funcs=cbfs)
- # 可以在fit的时候添加一个cbs
- # sgd: p = p - lr*p.grad
- # weight_decay: p = p * ( 1 - lr*wd)
- def append_stats(hook, mod, inp, outp):
- if not hasattr(hook,'stats'): hook.stats = ([],[],[])
- means,stds,hists = hook.stats
- means.append(outp.data.mean().cpu()) # 激活元的值
- stds .append(outp.data.std().cpu())
- hists.append(outp.data.cpu().histc(40,0,10)) #histc isn't implemented on the GPU
- def get_hist(h):
- return torch.stack(h.stats[2]).t().float().log1p() # h.stats[2]为直方图
- with Hooks(model, append_stats) as hooks:
- learn.fit(1) # pytorch_init + sgd
- fig, [ax0, ax1] = plt.subplots(1,2, figsize=(10,4))
- for h in hooks:
- ms, ss, hi = h.stats
- ax0.plot(ms), ax0.set_title("act_means", loc='center'), ax0.set_xlabel('batches')
- ax0.legend(range(3))
- ax1.plot(ss), ax1.set_title("act_stds", loc='center'), ax1.set_xlabel('batches')
- ax1.legend(range(3))
- fig,axes = plt.subplots(2,2, figsize=(15,6))
- for ax,h in zip(axes.flatten(), hooks[:3]):
- ax.imshow(get_hist(h), origin='lower'), ax.set_title("acts_hist", loc='center'), ax.set_xlabel('activiations')
- ax.axis('off')
- plt.tight_layout()
- def get_min(h): # 将直方图的前两个数加起来
- h1 = torch.stack(h.stats[2]).t().float()
- return h1[:2].sum(0)/h1.sum(0)
- fig,axes = plt.subplots(2,2, figsize=(15,6))
- for ax,h in zip(axes.flatten(), hooks[:3]):
- ax.plot(get_min(h)), ax.set_title("hist[:2] zero ratio", loc='center'), plt.xlabel('batches')
- ax.set_ylim(0,1)
- plt.tight_layout()


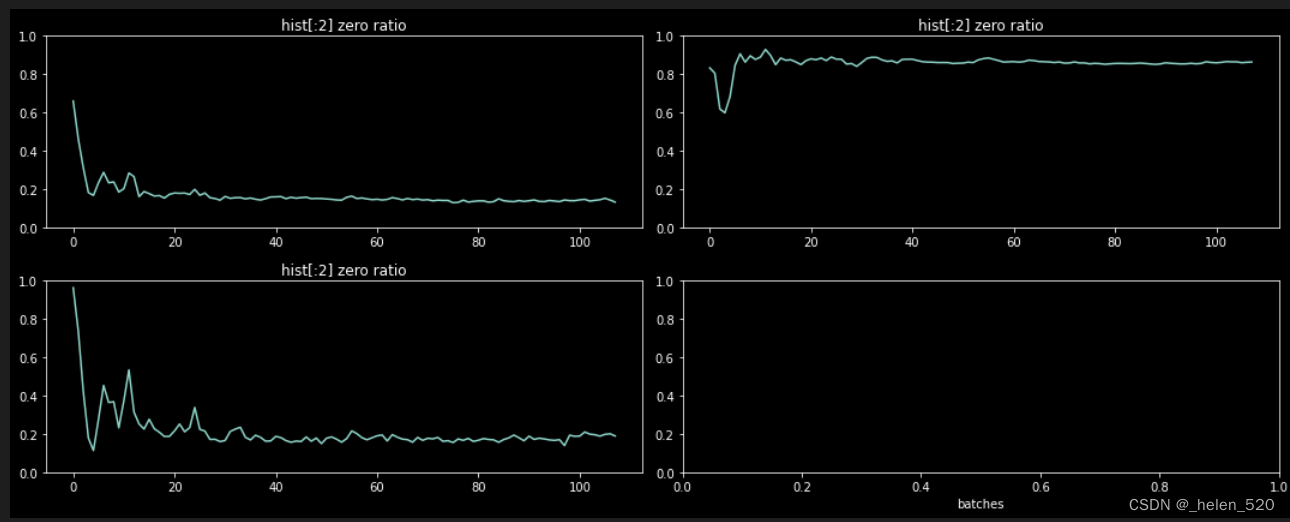

① Linear的模型,需要自己写一个。Learner在nb_09b.py中,opt是在fit的时候才去构建了Opt的对象。
② opt如果是sgd,就是默认的。不写就可以了。
③ 如果cuda启动不起来,电脑需要重启。
2. Imagenette数据集调试记录
Pytorch 调试常用
代码仓库:Dive-into-DL-PyTorch/2.2_tensor.md at master · ShusenTang/Dive-into-DL-PyTorch · GitHub
李沐的《动手学深度学习》原书中MXNet代码实现改为PyTorch实现。本项目面向对深度学习感兴趣,尤其是想使用PyTorch进行深度学习的童鞋。本项目并不要求你有任何深度学习或者机器学习的背景知识,你只需了解基础的数学和编程,如基础的线性代数、微分和概率,以及基础的Python编程。
目录如下所示:

1. Tensor的使用



- mnist数据集比较简单、28×28的像素,都是一样的。背景也比较干净,同时是分类任务,用简单的网络就可以处理的。
-
相关阅读:
Ubuntu 下 VSCode Tab 间距非常小解决方案
LeetCode每日一题(309. Best Time to Buy and Sell Stock with Cooldown)
记录一下自己涉及到的时间及金额方法的处理
C++核心基础教程之STL容器详解 list
移动Web第四天 1 移动适配
fastdds库架构
【LeetCode热题100】--102.二叉树的层序遍历
【调度优化】基于遗传算法求解工件的并行调度组合优化问题附matlab代码
C++测手速小游戏
虹科分享 | 想买车无忧?AR为您带来全新体验!
- 原文地址:https://blog.csdn.net/haronchou/article/details/126031631
