-
JDK8中ConcurrentHashMap底层源码解析-put和putVal方法以及数组的初始化
前言
JDK1.8 中的ConcurrentHashMap选择了与 HashMap相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁。本篇文章以JDK8为例,对ConcurrentHashMap的底层源码做一个解析,帮助大家更好的理解ConcurrentHashMap的底层原理。
一、容器初始化
我们在创建ConcurrentHashMap时,通常有以下两种做法,这2个构造方法中都没有对内部的数组做初始化
public class Test { public static void main(String[] args) { //1.无参构造 ConcurrentHashMap concurrentHashMap=new ConcurrentHashMap(); //2.传递进来一个初始容量 ConcurrentHashMap concurrentHashMap2=new ConcurrentHashMap(32); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
无参构造中没有维护任何变量的操作,如果调用该方法,数组长度默认是16
public ConcurrentHashMap() { }- 1
- 2
如果传递进来一个初始容量,ConcurrentHashMap会基于这个值计算一个比这个值大的2的幂次方数作为初始容量
public ConcurrentHashMap(int initialCapacity) { if (initialCapacity < 0) throw new IllegalArgumentException(); int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); this.sizeCtl = cap; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:调用这个方法,得到的初始容量和我们之前讲的HashMap不同,即使你传递的是一个2的幂次方数,该方法计算出来的初始容量依然是比这个值大的2的幂次方数,而HashMap是大于或者等于。
同时,在上面的构造方法中涉及到了一个变量sizeCtl,这个变量是一个非常重要的变量,而且具有非常丰富的含义,它的值不同,对应的含义也不一样,这里我们先对这个变量不同的值的含义做一下说明,后续源码分析过程中,进一步解释。
- sizeCtl为0,代表数组未初始化, 且数组的初始容量为16
- sizeCtl为正数,如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么其记录的是数组的扩容阈值
- sizeCtl为-1,表示数组正在进行初始化
- sizeCtl小于0,并且不是-1,表示数组正在扩容, -(1+n),表示此时有n个线程正在共同完成数组的扩容操作
二、put和putVal方法
当我们调用put方法往里面添加一个元素时,在put方法中会调用putVal方法
public V put(K key, V value) { return putVal(key, value, false); }- 1
- 2
- 3
由于JDK8中ConcurrentHashMap的putVal()方法太长,在这里我们可以先思考一下这个方法要做什么:
- 如果数组还未初始化,先对数组进行初始化
- 基于key计算hash值,并进行一定的扰动,同时需要计算一个数组下标,代表要存放的位置
- 把key,value,hash封装到一个Node中,利用cas将元素添加对应的位置中去
先知道我们要做什么,在去看源码,就不会那么难懂了,接下来看putVal()的底层源码,注意第一次看可能会有点懵,但是多看几遍一定会有收获。
final V putVal(K key, V value, boolean onlyIfAbsent) { //如果有空值或者空键,直接抛异常,而HashMap允许添加一个null键值对 if (key == null || value == null) throw new NullPointerException(); //基于key计算hash值,并进行一定的扰动 int hash = spread(key.hashCode()); //记录某个位置上元素的个数,如果超过8个,会转成红黑树 int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; //如果数组还未初始化,先对数组进行初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); //计算数组下标,如果该位置上没有元素,则利用cas将元素添加,添加成功返回true else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //cas+自旋(和外侧的for构成自旋循环),保证元素添加安全 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin 如果是该位置的第一个元素,直接用 CAS原则插入,无需加锁 } //如果数组下标元素的hash值为MOVED,证明正在扩容,那么协助扩容 else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); //如果数组下标元素不为空,且当前没有处于扩容操作,进行元素添加 else { V oldVal = null; //对第一个结点进行加锁,保证线程安全,执行元素添加操作,添加期间判断是否有重复键 synchronized (f) { if (tabAt(tab, i) == f) { //普通链表节点,遍历链表(同时检查有无重复键,并且用binCount记录链表长度),将元素加到链表末尾中去 if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //树节点,将元素添加到红黑树中,也要检查有无重复键 else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { //链表长度大于/等于8,将链表转成红黑树 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); //如果是重复键,直接将旧值返回 if (oldVal != null) return oldVal; break; } } } //不存在重复键,添加的是新元素,要维护集合长度,并判断是否要进行扩容操作 addCount(1L, binCount); return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
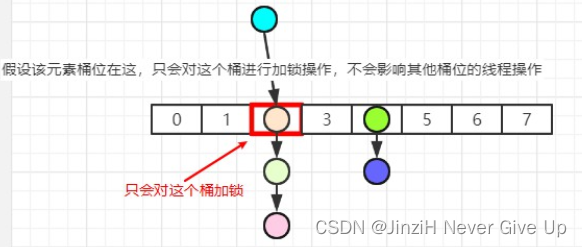
通过以上源码,我们可以看到,当需要添加元素时,会针对当前元素所对应的桶位进行加锁操作,这样一方面保证元素添加时,多线程的安全,同时对某个桶位加锁不会影响其他桶位的操作,进一步提升多线程的并发效率。
如果不清楚CAS的可以看这篇文章辅助学习:CAS操作原理与实现下面用一张图演示ConcurrentHashMap插入元素时的场景。
三、initTable方法
在putVal方法中,如果数组还未初始化,要先对数组进行初始化,调用的是initTable(),现在我们来看一下这个方法的源码:
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; //cas+自旋,保证线程安全,对数组进行初始化操作 while ((tab = table) == null || tab.length == 0) { //如果sizeCtl的值(-1)小于0,说明此时正在初始化, 让出cpu if ((sc = sizeCtl) < 0) Thread.yield(); // lost initialization race; just spin 线程让步 //cas修改sizeCtl的值为-1,修改成功,进行数组初始化,失败,继续自旋 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { //sizeCtl为0,取默认长度16,否则取sizeCtl的值 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") //基于初始长度,构建数组对象 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = tab = nt; //计算扩容阈值,并赋值给sc sc = n - (n >>> 2); } } finally { //将扩容阈值,赋值给sizeCtl sizeCtl = sc; } break; } } return tab; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
小结:数组初始化的时候利用了cas+自旋,保证线程安全,这里用到了一个上文中提到的非常重要的变量sizeCtl变量,利用cas修改sizeCtl的值为-1(sizeCtl为-1,表示数组正在进行初始化),基于初始长度,构建数组对象并计算扩容阈值赋值给sizeCtl(如果数组已经初始化,那么其记录的是数组的扩容阈值)。
总结
个人认为JDK8中ConcurrentHashMap的put和putVal方法源码跟HashMap存在很多相似的地方,不同的是ConcurrentHashMap利用了一些CAS+自旋的思想,如果该位置上没有元素直接用 CAS原则插入,无需加锁,否则就第一个结点进行加锁,保证线程安全。
-
相关阅读:
支付宝小程序云亮相!向小程序生态开放全面云服务
算法与诗数据结构 --- 查找 --- 线性表的查找
Day694.Tomcat如何支持异步Servlet -深入拆解 Tomcat & Jetty
基于SSM和VUE的留守儿童信息管理系统
web框架之路由列表及SQL语句查询数据库数据替换模板变量
【项目】短信模块对Java枚举的使用
es6 export和export default的区别
MySQL牛客题组练习
SCI论文从投稿到录用的完整处理流程-经验总结
IDEA Java1.8通过sqljdbc4连接sqlserver插入语句
- 原文地址:https://blog.csdn.net/qq_52173163/article/details/126100682