-
【分析BMI指数~python】
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。分析班级BMI指数
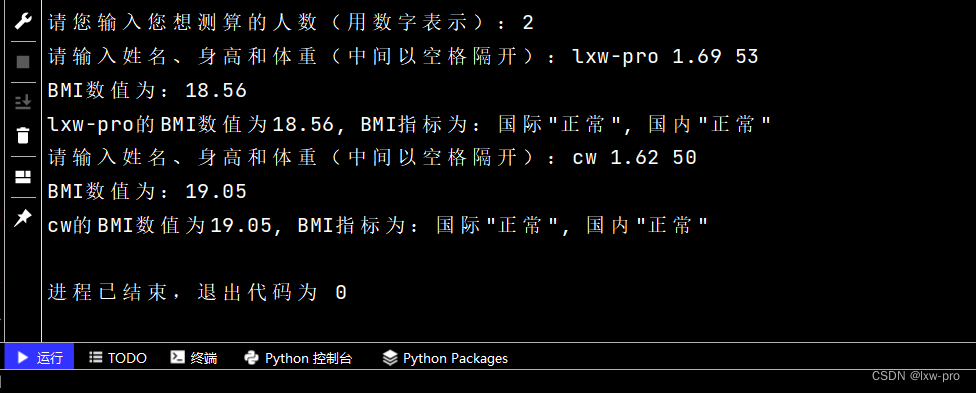
n = int(input("请您输入您想测算的人数(用数字表示):")) for i in range(n): classBmi = input("请输入姓名、身高和体重(中间以空格隔开):").split(' ') name = classBmi[0] height = eval(classBmi[1]) weight = eval(classBmi[2]) bmi = weight / pow(height, 2) print("BMI数值为:{:.2f}".format(bmi)) who, nat = "", "" if bmi < 18.5: who, nat = "偏瘦", "偏瘦" elif 18.5 <= bmi < 24: who, nat = "正常", "正常" elif 24 <= bmi < 25: who, nat = "正常", "偏胖" elif 25 <= bmi < 28: who, nat = "偏胖", "偏胖" elif 28 <= bmi < 30: who, nat = "偏胖", "偏胖" else: who, nat = "肥胖", "肥胖" print('{0}的BMI数值为{1}, BMI指标为:国际"{2}", 国内"{3}"'.format(name, format(bmi, '.2f'), who, nat))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行效果如下:
分析年级BMI指数
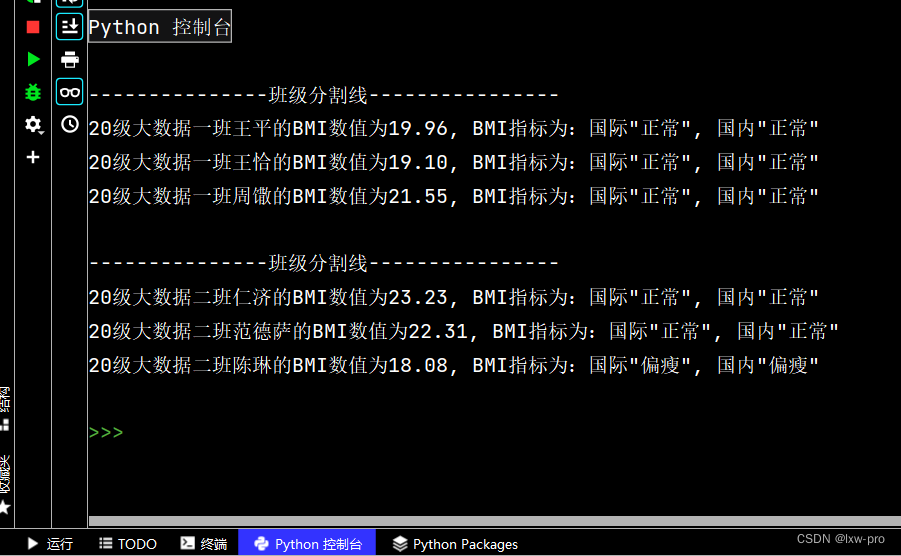
gradeBmis = [[('20级大数据一班', "王平", 1.66, 55), ('20级大数据一班', '王恰', 1.65, 52), ('20级大数据一班', '周馓', 1.75, 66)], [('20级大数据二班', "仁济", 1.66, 64), ('20级大数据二班', '范德萨', 1.72, 66), ('20级大数据二班', '陈琳', 1.76, 56)]] for classes in gradeBmis: print("\n---------------班级分割线----------------") for person in classes: className, name, height, weight = person[0], person[1], person[2], person[3] who, nat = "", "" bmi = weight / pow(height, 2) if bmi < 18.5: who, nat = "偏瘦", "偏瘦" elif 18.5 <= bmi < 24: who, nat = "正常", "正常" elif 24 <= bmi < 25: who, nat = "正常", "偏胖" elif 25 <= bmi < 28: who, nat = "偏胖", "偏胖" elif 28 <= bmi < 30: who, nat = "偏胖", "偏胖" else: who, nat = "肥胖", "肥胖" print('{0}{1}的BMI数值为{2}, BMI指标为:国际"{3}", 国内"{4}"'.format(className, name, format(bmi, '.2f'), who, nat))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行效果如下:
————————————————————————————————————————————
Pandas 每日一练:
# -*- coding = utf-8 -*- # @Time : 2022/7/28 20:34 # @Author : lxw_pro # @File : pandas-10 练习.py # @Software : PyCharm import pandas as pd lxw = pd.read_excel("site.xlsx") print(lxw)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl 0 0 1 2016-11-30 ... 8.8 6.77 30.00% 1 1 2 2016-11-30 ... 7.5 5.77 30.00% 2 2 3 2016-11-30 ... 5.0 3.85 30.00% 3 3 4 2016-11-30 ... 19.6 7.54 30.00% 4 4 5 2016-12-02 ... 13.5 10.38 30.00% .. ... ... ... ... ... ... ... 751 751 752 2016-12-31 ... 1.0 0.77 30.00% 752 752 753 2016-12-31 ... 2.0 1.54 30.00% 753 753 754 2016-12-31 ... 1.0 0.77 30.00% 754 754 755 2016-12-31 ... 7.6 2.92 30.00% 755 755 756 2016-12-31 ... 3.3 2.54 30.00% [756 rows x 8 columns]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
61、以lxw的列名创建一个dataframe
lm = pd.DataFrame(columns=lxw.columns.to_list()) print(lm)- 1
- 2
运行结果为:
Empty DataFrame Columns: [Unnamed: 0, Unnamed: 0.1, create_dt, sku_cnt, sku_sale_prc, yye, sku_cost_prc, lrl] Index: []- 1
- 2
- 3
62、打印所有利润率不是数字的行
for i in range(len(lxw)): if type(lxw.iloc[i, 6]) != float: lm = lm.append(lxw.loc[i]) print(lm)- 1
- 2
- 3
- 4
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl 0 0 1 2016-11-30 ... 8.8 6.77 30.00% 1 1 2 2016-11-30 ... 7.5 5.77 30.00% 2 2 3 2016-11-30 ... 5.0 3.85 30.00% 3 3 4 2016-11-30 ... 19.6 7.54 30.00% 4 4 5 2016-12-02 ... 13.5 10.38 30.00% .. ... ... ... ... ... ... ... 751 751 752 2016-12-31 ... 1.0 0.77 30.00% 752 752 753 2016-12-31 ... 2.0 1.54 30.00% 753 753 754 2016-12-31 ... 1.0 0.77 30.00% 754 754 755 2016-12-31 ... 7.6 2.92 30.00% 755 755 756 2016-12-31 ... 3.3 2.54 30.00% [756 rows x 8 columns]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
63、打印所有利润率为30.00%的行
print(lxw[lxw['lrl'].isin(['30.00%'])])- 1
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl 0 0 1 2016-11-30 ... 8.8 6.77 30.00% 1 1 2 2016-11-30 ... 7.5 5.77 30.00% 2 2 3 2016-11-30 ... 5.0 3.85 30.00% 3 3 4 2016-11-30 ... 19.6 7.54 30.00% 4 4 5 2016-12-02 ... 13.5 10.38 30.00% .. ... ... ... ... ... ... ... 751 751 752 2016-12-31 ... 1.0 0.77 30.00% 752 752 753 2016-12-31 ... 2.0 1.54 30.00% 753 753 754 2016-12-31 ... 1.0 0.77 30.00% 754 754 755 2016-12-31 ... 7.6 2.92 30.00% 755 755 756 2016-12-31 ... 3.3 2.54 30.00% [478 rows x 8 columns]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
64、重置lxw的行号
lxw = lxw.reset_index() print(lxw)- 1
- 2
运行结果为:
index Unnamed: 0 Unnamed: 0.1 ... yye sku_cost_prc lrl 0 0 0 1 ... 8.8 6.77 30.00% 1 1 1 2 ... 7.5 5.77 30.00% 2 2 2 3 ... 5.0 3.85 30.00% 3 3 3 4 ... 19.6 7.54 30.00% 4 4 4 5 ... 13.5 10.38 30.00% .. ... ... ... ... ... ... ... 751 751 751 752 ... 1.0 0.77 30.00% 752 752 752 753 ... 2.0 1.54 30.00% 753 753 753 754 ... 1.0 0.77 30.00% 754 754 754 755 ... 7.6 2.92 30.00% 755 755 755 756 ... 3.3 2.54 30.00% [756 rows x 9 columns]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
65、删除所有利润率为30.00%的行
l = [] for i in range(len(lxw)): if type(lxw.iloc[i, 6]) != float: l.append(i) sc = lxw.drop(labels=l, inplace=True) print(sc) # 运行结果为:None- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
每日一言:
在某一个拥挤的地方,人挤人,你不知道方向在哪里,但如果你站的高一点,看的远一点,就知道周遭的种种拥挤对你来说其实毫无意义!!!
持续更新中…
点赞,你的认可是我创作的
动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!
关注,你的喜欢是我长久的坚持!

欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!
-
相关阅读:
VSCode使用
Python实现WOA智能鲸鱼优化算法优化卷积神经网络回归模型(CNN回归算法)项目实战
idea 启动Flask时host设置和端口设置,以及host=0.0.0.0和127.0.0.1的区别
arduino超声波测距
使用Python配置虚拟环境
Linux 内核段符号简介
零基础小白如何自学黑客(网络安全)?
VS2022新建项目时没有ASP.NET Web应用程序 (.NET Framework)
笔试,猴子吃香蕉,多线程写法
(pytorch进阶之路三)conv2d
- 原文地址:https://blog.csdn.net/m0_66318554/article/details/125750544
