-
Linux shell
bash介绍
shell有很多种,查看所有shell类型:cat /etc/shells
不同的用户使用不同的shell,这个取决于用户的配置,该配置在文件: /etc/passwd查看得知:root用户是使用bash这个shell,还有些隐藏用户使用的是/sbin/nologin这个特殊的shell,这个是不能登录的用户,如果把root的shell改为nologin,则root就不能登录了。
Linux的默认shell程序是bash,存放在/bin/bash。
bash的优点:
- 历史命令:存放在~/bash_history中,存放的是上一次登录使用到的所有命令
- 命令与文件补全
- 设置别名:alias查看所有别名,alias ll='ls -l' :临时的设置别名,unalias ll取消该别名
- 要永久设置别名,需要设置到~/.bashrc文件里,这是针对单用户的,全局生效的话就需要加到/etc/bashrc
- 修改了配置文件,要用source /etc/bashrc重新载入配置文件,然后别名才会生效
- 程序化脚本
- 任务管理、前台后台控制
- 可以使用通配符
我们通常输入的命令可分为:
内部命令:系统启动的时候这些命令就会被调用内存,常住在内存中,所以执行效率很高
外部命令∶是系统软件的功能,不是bash提供的功能,在用户需要运行这些软件的时候,才现从硬盘上把程序文件调入内存中,执行
#单行注释,:<
type
type命令:可以检测那些命令是外部命令那些是内部命令,type的三种结果如下

命令的执行与编辑
ctrl+u删除光标前面的命令 ,ctrl+k删除光标后面的命令串
ctrl+a光标移动到命令串的最前面,ctrl+e光标移动到最后面
输入history查看历史命令,然后!编号,等于重新执行该命令,按!!是执行前一个命令
ctrl+L:清空屏幕,clear
ctrl+c:结束运行中的程序
ctrl+d:退出终端
bash的变量
变量在使用前必须加上$符号或${},使用echo可以读取变量

变量的设置规则:
- 等号两边不能直接接空格,如果有空格可以使用双引号和单引号将变量内容结合起来
- 双引号内的特殊字符如$等,可以保有原本的特性;而单引号内的字符全部为一般字符
- 可用转义字符【\】将特殊的符号($、[Enter]、空格、'等)变成一般字符
- 字符串其中可以带其他的命令提供的字符,使用【`命令`或$(命令)】,如version=this$(uname -r),另外的$((运算))
- 若该变量为扩增变量内容时,可用"$变量名称"或${变量}累加内容。PATH=${PATH}:/home
- 若该变量需要在其他子程序执行,需要以export来使变量变为环境变量。export PATH
- 取消变量使用unset,如uset myName
环境变量
使用env和export查看环境变量,用set查看所有变量包括自定义的变量,分别列出一些常见的环境变量:
- HOME:代表用户的家目录
- HISTSIZE:记录bash命令的最大记录数
- PATH:执行文件查找的路径
- LANG:语系
- PS1:提示字符的设置,就是[lxc@com ~]$这一串东西,可以由我们自定义
- $:目前这个shell程序的pid进程号
- ?:上一个执行的命令的返回值,0表示成功,非0表示执行错误
- RANDOM:0-32767中的随机数
子进程只会继承父进程的环境变量,不会继承父进程的自定义变量。
set -u 设置后,使用未声明的变量会提示出错
变量内容的删除、取代与替换
一、删除
var为变量名
- ${var#v*r}:从左到右匹配将:头部是“v”,尾部是“r”的最短的部分删除
- ${var##v*r}:从左到右匹配将:头部是“v”,尾部是“r”的最长的部分删除
- ${var%v*r}:从右到左匹配将:头部是“v”,尾部是“r”的最短的部分删除
- ${var%%v*r}:从右到左匹配将:头部是“v”,尾部是“r”的最长的部分删除
如name=aaa.bbb.ccc.txt
$echo ${name#*.}:得到bbb.ccc.txt
$echo ${name##*.}:得到txt
echo ${name%.*}:得到aaa.bbb.ccc
echo ${name%%.*}:得到aaa
二、替换
var为变量名,
${var/v/r}:将v换成r,从左到右第一个
${var//v/r}:将所有的v换成r
read
读取用户从键盘上输入的变量。
- -p :后面可以接提示字符
- -t:后面可以接等待的描述,不会一直阻塞等待
- -s:不回显
read -p 请输入: -t 30 name
declare、typeset
声明变量的类型:declare [-aixr] 变量名
- -a:将变量定义为数组类型(array),-A是关联数组,下标为字符
- -i:将变量定义为整数类型(int)
- -x:与export一样,将变量变为环境变量
- -r:将变量设置为readonly类型,变量不能被更改,也不能unset
上面的-都可以换成+,就是取消的意思
变量默认是字符串类型,如下需要把name变为int类型的,否则的话结果就是100+100+100

bash环境中数值运算默认只能整数形态,1/3=0;
- -p:单独列出变量的信息
declare和typeset具有相同功能
数组:
array=(1 2 3 4)同时赋多个值
[lxc@com ~]$ declare -a name
[lxc@com ~]$ name[1]=a
[lxc@com ~]$ name[2]=b
[lxc@com ~]$ read name[3]
c
[lxc@com ~]$ echo "${name[1]},${name[2]},${name[3]}"
a,b,c
如果直接echo $数组,返回的是下标0的值- ${array[@]}:代表数组的所有值
- ${#array[@]}:数组的大小
- ${!array[@]}:数组的所有索引值
- ${array[@]:1}:数组下标从1开始
- ${array[@]:1:2}:数组下标从1开始访问2个数
上面的操作对字符串也有效:${#string}
echo `expr index "${name}" c` 计算字符串name中c的索引
ulimit
限制用户的某些资源,包括开启的文件数量、可以使用的cpu时间片、可以使用的内存总量等
用法:ulimit [-SHacdfltu] [配额]
- -H:hard严格的限制,不能超过这个值
- -S:soft警告的设置,可以超过这个值,但是有警告信息,通常soft比hard小
- -a:后面不接任何参数,列出所有的限制额度
- -c:线程每个内核文件的最大容量,内核文件时程序发生错误时,系统可能将该错误写出文件
- -f:此shell可以建立的最大文件容量(一般为2G),单位是Kbytes
- -d:程序可使用的最大段内存
- -l:可用于锁定的内存量
- -t:可使用的最大cpu时间,秒
- -u:单一用户可以使用的最大进程数量
如果为0就是没有限制
bash环境配置文件
前面提到的命名别名、变量、注销bash后都会失效,想要保留这些数据就需要写入配置文件才行。
- login shell:取得bash时需要完整的登录流程。
- non-login shell:取得bash时不需要重复的登录操作,如登录的图形化界面打开终端不需要再登录;在原本的shell环境下执行bash这个命令,同样也没用输入账号密码
login shell会读取/etc/profile和~/.bash_profile这两个配置文件。
/etc/profile会读取是系统的整体配置,包括会根据登录用户设置PATH、MAIL、HOSTNAME、umask等,/etc/profile中会调用/etc/profile.d/*.sh这些文件
~/.bash_profile的内容如下,增加了PATH的内容,增加了不同用户家目录下的两个文件,还调用了~/.bashrc文件,.的功能就等于source,都能立即读取配置文件

~/.bashrc内容如下

login shell的整体流程是:
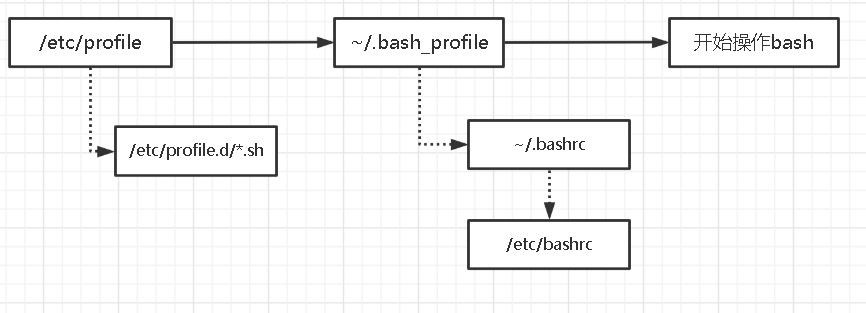
login shell配置文件读取流程 non-login shell只会读取~/.bashrc(会间接调用/etc/bashrc),/etc/bashrc可以设置整体环境,如PS1、umask等。
其他得配置文件:
~/.bash_history:就是我bash命令的历史记录
~/.bash_logout:注销bash后,系统再帮我们做完什么操作后才离开
终端的配置环境stty
stty -a:将目前所有的stty按键与内容输出出来

- intr:终止正在run的程序
- quit:发送一个quit信号给正在run的程序
- erase:向后删除字符
- kill:删除目前命令行上所有的文字
- eof:结束输入
- start:在某个程序停止后,重新启动它的output
- stop:停止目前屏幕的输出,和start相对
如 stty erase ^h :按ctrl+h向后删除
通配符与特殊符号
通配符:
- *:【0到无穷多个】任意字符
- ?:【一定有一个】任意字符
- [abcd]:【一定有一个在括号内】的任意字符,即abcd中的任意一个字符
- [1-9]:【在编码顺序内的所有字符】,即1-9之间的所有字符
- [^ abc]:^在开头代表【反向选择】,即一定有一个字符,只要不是abc中的一个即可
特殊符号:
- \:转义符号
- |:管道符
- &任务管理,将命令变为后台命令
- !:逻辑非
- /:目录符号
- >、>>:数据流重定向,输出定向,分别是【替换】、【累加】
- <、<<:数据流重定向,输入定向
- $:变量使用前导符
- ' ':单引号,不具有变量替换的功能($为纯文本)
- " ":具有变量替换的功能($可保留相关功能)
- ` `:两个`之间为可以先执行的命令,同$()
- ():在中间为子shell的起始和结束
- {}:在中间为命令区块的组合
数据流重定向
数据流重定向是将某个命令执行后要出现在屏幕的数据,给他传输到其他地方。
- 标准输入(stdin):代码为0,使用<或<<
- 标准输出(stdout):代码为1,上使用>或>>
- 标准错误输出(stderr):代码为2,使用2>或2>>
stdout和stderr:
将本来要输出到屏幕的数据重定向到文件里,>是覆盖,>>是累加。
如ll / > ~/rootfile将/目录的数据都重定向到~/rootfile文件中,如果该文件不存在会新建一个,如果存在该文件,>会清空该文件,>>则不会。
2>或2>>是将错误的信息重定向,如find /home -name .bashrc > list_right 2> list_error,将正确的结果和错误的信息分别写入到list_right和list_error文件中、
/dev/null垃圾桶黑洞文件,可以吃掉任导向这个设备的信息,可以将错误信息导向这个文件。
如果想让正确和错误信息都写入同一个文件则使用如下两种特殊写法:
- find / -name my >file_list 2>&1:将查找到的正确数据和错误信息都重定向到file_list文件
- find / -name my &> file_list :同上
stdin:
将原本需要由键盘输入的数据,改用文件内容来替换。
如使用cat命令可以输入字符:

<<的意思是【结束的输入字符】,他并不是重定向文件,而是还是原来的键盘输入,如

最后的结果不包括eof。
命令执行的判断根据;、&&、||
;就是一次执行多个命令。
&&和||的判定依据就是上面说的?变量,如果上一次的命令执行成功$?为0,否则就是失败。
- &&表示前一个命令执行成功才会执行后面的命令,如果前一个执行失败后一个命令不会执行
- ||表示前一个命令执行成功后一个命令就不会执行,前一个命令执行失败才会执行后一个命令
如ls -d tempdir && touch temdir/aaa.txt 表示tempdir这个目录存在才会建立aaa.txt文件
ls -d tempdir || mkdir tempdir 表示tempdir不存在就会创建tempdir目录
ls -d tempdir || mkdir tempdir && touch tempdir/aaa.txt 是不论如何都创建aaa.txt文件
管道命令
如ls -al /etc | less:使用less插看ls命令得到的结果
管道命令【|】仅能处理经由前一个命令传来的正确数据,不能处理错误的信息。在每个管道后面接的第一个数据必定是命令,而且这个命令必须能够接收标准输入的数据才行,这样的命令称为管道命令。
选取命令:cut、grep
所谓选取就是将得到的数据取出我们想要的数据,选取信息通常都是针对【一行一行】来分析的。
cut -d '分隔字符' -f 分隔出来的哪几段:以某一个字符为分隔,可以去出每一段的数据
cut -c 分隔区间:以字符为单位截取
如:- [lxc@com ~]$ echo $PATH
- /usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/lxc/.local/bin:/home/lxc/bin
- [lxc@com ~]$ echo $PATH | cut -d ':' -f 2,5
- /bin:/usr/sbin
如:
export|cut -c 12-不显示export得出的数据的前12个字符,因为12-后面省略的当做无穷
grep:
分析一行信息,如果有我们想要的就将该行拿出。
- -v:反向查找
- -i:忽略大小写
- -E:可使用扩展正则表达式,同egrep
- -c:仅仅计算找到的次数
- -n:显示行号
- -A:after ,后面接数字表示除了改行,后序的n行也列出来
- -B:before
排序命令:sort、wc、uniq
sort :以各种形式进行排序
- -f:忽略大小写的差异
- -b:忽略最前面的空格字符部分
- -n:以纯数字进行排序,默认是以文字排序的
- -r:反向排序
- -t:分隔符号,可以以第几栏开始排序
- -k:以哪个区间开始排序的意思,配合-t

uniq:排序完成后将重复的数据仅列出一个显示
- -c:进行计数

wc:打印出数据的【行、字数、字符数】
- -l :仅列出行
- -w:仅列出多少字
- -m:多少字符
双向重定向tee
可以将数据流分送到屏幕与文件。
-a:以累加的方式将数据加到文件当中
如 last | tee last.list
这样的话屏幕输出的内容也会保存到文件中
字符转换命令:tr、col、expand
tr:删除一段信息中的文字,或者进行文字信息的替换 ,如tr [a-z] [A-Z] :小写转大写
- -d删除信息当中的某些字符 如:tr -d \r 删除所有的\r,可以把windows的文本变为linux的
- -s去重
col:
- -x:将tab键转为对应的空格键
expand:也是将tab转为空格键,unexpand将空格键转为tab键
划分命令:spilt
split [-bl] file PREFIX(划分的文件前缀名)
- -b:接预划分成的文件大小,可加单位 b、k、m等
- -l:以行进行划分
如spilt -b 300k /etc/services services,将该文件划分成多个300k的小文件,文件名为servicesaa,servicesab等
cat services* >> servicesback 将小文件又合成大文件
减号-的用途
-号可以代替文件名
如tar -cvf - /home | tar -xvf - -C /tmp
参数代换xargs:
产生某个命令的参数,适合不支持管道的命令。
xargs [-0epn] command
- -n:接次数,每次command命令执行时,使用多少个参数
- -e:后面接一个字符,当xargs分析到这个字符时,就会停止工作
- -0:特殊字符还原为一般字符
sed工具
sed [-nefr] [操作]
- -n:使用安静模式,只有经过sed特殊处理的那一行才会被列出来
- -i:直接修改文件的内容
- -r:使用扩展的正则表达式
- -e:同时执行多个命令
- -f:sed指定文件
操作说明 :[n1[,n2]] function
n1,n2代表选择进行操作的行数,如果省略则是全部行,其中[2,$]中$代表最后一行
sed后面的操作必须有单引号
function如下:
- a:新增,下一行开始插入,sed '2a 123' ,在下一行插入123
- c:替换,sed '2,5c 123',把2-5行的内容变为123
- d:删除,sed '2,5d' 删除2-5行
- i:插入,在上一行开始插入
- p:打印,sed '2,5p' -n,打印2-5行
- s:替换,sed 's/要被替换的字符/新的字符/g'
- g可不加,g是将所有的都替换,如果不加默认只替换第一个
- 还可以把g替换为数字,就是值替换第几个匹配的
可以使用/ /开启匹配模式,如sed '/i am head/ahi' :i am head是文件某一行的开头,在这一行后面插入一个hi
扩展正则表达式
+ 重复一个或一个以上的前一个字符 ? 零个或一个的前一个字符 | or ( ) 找出群组字符串,'g(la|oo)d' ( )+ 多个重复群组 printf
printf '打印格式' 实际内容
awk
awk倾向于一行当中分成段来处理。
awk [options] '[BEGIN]条件类型1{操作1} 条件类型2{操作2}……[END]' filename
条件类型:
> 、< 、>=、 <= 、== 、!=
变量:
$0代表【一整行数据】,$1代表第一栏数据……
- NF:每一行拥有的字段总数,$NF即最后一列
- NR:当前正在处理第几行数据
- FS:分隔字符,默认是空格键
cat /etc/passwd |awk 'BEGIN{FS=":"} $3<10{print $1 "\t" $3}'
awk中可以使用循环如awk '{for(i=1;i<=NF;i++){res[$i]+=1}}END{for(k in res){print k" "res[k]} }' words.txt | sort -nr -k2
-
相关阅读:
springboot自动装配
Qt多文本编辑器项目实战
如何用画图将另一个图片中的成分复制粘贴?
AI 编程探索- iOS动态标签控件
【Redis精通之路】数据类型(2)
【C++ Primer Plus】第10章 对象和类
交换部分 VLAN
WebGL 绘制圆形的点
ubuntu安全扩展交换内存swap memory
Facebook干货丨个人账号和企业账号篇
- 原文地址:https://blog.csdn.net/weixin_45902285/article/details/122667937