-
Cilium v1.12 功能原理解读:ServiceMesh 令人期待

在 7 月 20 日,cilium 发布了 v1.12 版本,该版本引入了众多的变化。
cilium v1.12 版本,主要包括了几个方面的功能变化:
-
Service Mesh
-
网络 policy
-
egress gateway
-
cluster mesh
-
bandwidth manager
通过 cilium 官方的版本 blog 文章和 github 仓库 PR 贡献,结合作者自己的一些浅显的理解,给出了这些功能的分享解读,也欢迎大家指正交流。
01 ServiceMesh
该功能是 cilium v1.12 中最大的一个亮点,cilium 在 2021 年底就开始造势和启动 Service Mesh beta 项目,经历半年多的等待,正式版本是千呼万唤始出来。
在 cilium 1.11 版本之前,cilium agent daemonset 中已经能够运行 envoy 实例,实现 L7 policy 的处理和网络观测。在 cilium 1.12 版本中,充分发挥该 envoy 实例的价值,加入了实现 Service Mesh 的能力,形成了 sidecar-free 的 per-node proxy 解决方案。
Cilium Service Mesh 区别于其它 ServiceMesh 项目的显著特点:
-
当前 Service Mesh 领域中, per-pod proxy (即 sidecar) 大行其道,继 traefik mesh
-
其它 Service Mesh 项目几乎都是借助 Linux 内核网络协议栈,而 cilium Service Mesh 基于 eBPF datapath,有着天生的加速效果。
-
Cilium Service Mesh 承载于 cilium CNI 的底座能力, cilium CNI 本身提供的 网络 policy、多集群 cluster mesh、eBPF 加速、观察性hubble 等能力,使得 cilium Service Mesh 不需要书写更多的代码,不需要借助其它开源项目,天然地打通了底层网络的水平和垂直领域的任督二脉,在后续的版本中,相信其功能会更加丰富。
设计理念

图片来源:https://isovalent.com/blog/post/cilium-service-mesh/
上图,是 cilium 官方版本给出的 Service Mesh 全景图,对于其设计思路可见一斑,不同于其它 Service Mesh 开源项目设计了很多 CRD 概念,cilium Service Mesh 当前专注实现了 mesh data plane,通过开放、包容的设计,能够对接其它 control plane,当前v1.12 版本已实现了对 envoy CRD 和 kubernetes ingress 的支持,在未来版本中,将会对 istio、spiffe、gateway API 实现支持。
具体可查看 cilium 版本 roadmap https://docs.cilium.io/en/v1.12/community/roadmap/#cilium-service-mesh
envoy CRD
Cilium 实现了 2个新的 CRD, CiliumEnvoyConfig 和 CiliumClusterwideEnvoyConfig,两者的写法和作用几乎相同,唯一区别是,CiliumEnvoyConfig 是 namespace scope,而 CiliumClusterwideEnvoyConfig 是 cluster scope 。
它们能能够设置 cilium agent 中的 envoy 代理,例如配置 envoy Listener 和 RouteConfiguration 等 ,具体可参考 github 仓库中的例子 https://github.com/cilium/cilium/blob/master/examples/kubernetes/servicemesh/envoy/envoy-traffic-management-test.yaml
值得注意的,该 CRD 的写法几乎就是 envoy 的配置语法,所以,如果是管理员手动书写 CRD 实例,是相对费劲的,并不友好,并且,当前的 cilium 版本并不能严格保证该 CRD 实例的创建校验,即使是写法错误,也会创建成功,最终只能在 cilium agent 中看错误日志来排障。我们看到 CiliumEnvoyConfig 和 CiliumClusterwideEnvoyConfig 体现了一种 envoy 原生配置的能力,通过它们,我们可以直接配置 envoy 的各种代理能力。
具体使用,可阅读 cilium 官方的使用文档 https://docs.cilium.io/en/latest/gettingstarted/servicemesh/l7-traffic-management/
ingress
不幸的是 CiliumEnvoyConfig 和 CiliumClusterwideEnvoyConfig 书写不友好,不能像 istio 的 VirtualService、ServiceEntry 等一样书写简化,但是,幸运的是,cilium 支持通过上层的 kubernetes ingress 来实现自动化配置。
作为 Service Mesh 控制面的重要构成版图,cilium v1.12 版本首先支持了 kubernetes ingress ,这也意味着,cilium 在完全实现了 kube proxy replacement 的 4 层负载均衡能力后,迈出了完成了 ingress L7 负载均衡能力的重要一步。
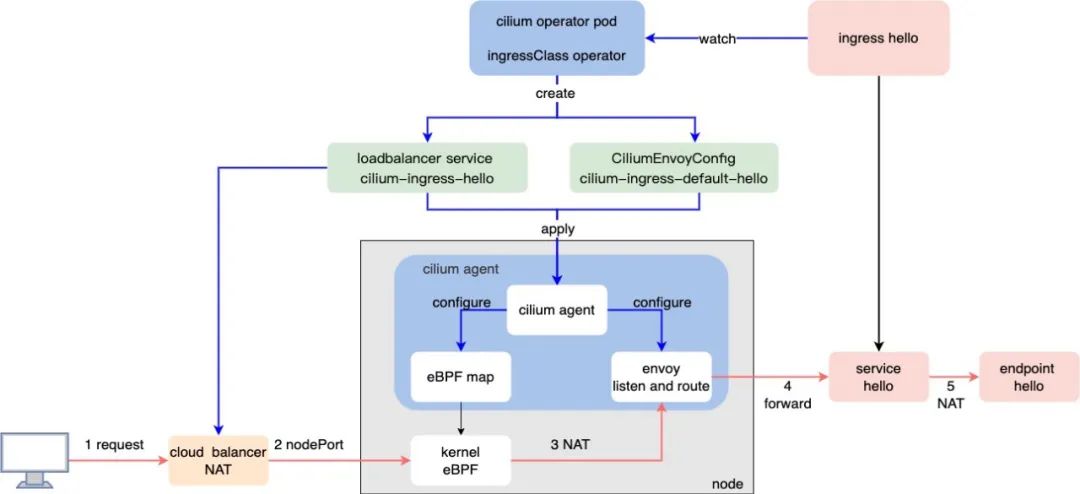
结合作者绘制的以上简图,来说明下实现 ingress 的实现原理:
Cilium 安装后,在集群中自动创建了名为 “cilium” 的 ingressClass 实例,在 cilium operator pod 中,会启动 ingressClass 控制器。
当管理员创建了一个基于 " spec.ingressClassName = cilium " 的 ingress 对象时,cilium operator pod 会自动 为其创建 3 个对象实例:
1. 一个类型为 loadbalancer 类型的 service 实例 ,位于 ingress 对象同租户下,该 service 实例名为 cilium-ingress-${ingresName} 。因此,cilium 要求集群中必须安装了能实现 loadbalancer service 的组件。
2. 同 ingress 配置相关的 CiliumEnvoyConfig 实例,其会生效到 cilium agent 内的 envoy 代理,告诉 envoy 如何监听和路由流量到后端真实服务。
3. 一个 dummy endpoint ,其 IP 是固定的 "192.192.192.192:9999"
这里就有一个值得思考的问题,为什么 cilium 需要为应用再次创建一个 loadbalancer 类型的 service ?应用自身不是已经具备 service 实例了么?
答案是这样的:该 loadbalancer 类型的 service 其实没有 select 任何 endpoint,与后端真实的 endpoint 没有任何直接联系。因为 cilium agent 本身没有任何生效 VIP ,那集群北向的 ingress 入口怎么高可用?它的创建,一方面是为了借助 cloud balancer 实现集群北向的高可用入口。其次,该流量经过 cloud balancer 解析到 nodePort 后,该 service 让 eBPF 解析转发到 envoy 的监听端口上,也因此,cilium 文档中提到,ingress 的实现必须依赖开启 kube proxy replacement。
经过以上问题的说明,结合原理图,我想读者对于整个数据流的转发路径 已经了然于胸了。
另外,为什么还建立了一个 dummy endpoint ?作者先卖个关子,关于 cilium Service Mesh 的内容,以上文字还是相对简单的,关于其设计解读和深层原理,文字篇幅较多,会在后续再做一个专题文章来分享。
另外,对于微服务间的 mtls 认证,可能会在 cilium 1.13 版本中可用。
总体而言,我们看到 cilium Service Mesh 的设计还是比较巧妙、包容和开放的,即暴露了底层 envoy 的可配置能力,也向上支持 kubernetes、istio 等项目的控制面设计,作为软件从业者,这些产品定位、架构设计能力值得学习和借鉴。
02 Bandwidth Manager
在新版本中, bandwidth manager 功能进入了稳定状态,它在宿主机网卡上实现能对于 pod 的 egress 流量的限流。有趣的是,在实施 bandwidth manager 代码中,还引入了 TCP BBR 算法支持。

图片来源:https://isovalent.com/blog/post/cilium-release-112/
我们来了解下 BBR 算法使用场景:
Internet 公网网络不同于数据中心私网,其丢包率、时延、带宽都难以得到保证,更容易产生丢包、数据包乱序、高延时等问题。BBR 算法针对这种场景,有比较好的性能改善,包括能够提升数据吞吐量、降低延时。
那 BBR 算法为什么能够改进性能呢?引用一段 cilium 官方release note 中的原文,可以精确的说明
Standard TCP congestion tends to send as much traffic as possible and adjust its rate when it detects some loss which often causes TCP to significantly reduce its rate. It can also lead to severe “bufferbloat” issues, where packets are waiting on network devices with very deep queues.
The reason BBR is so effective at increasing throughput and reducing latency is that it determines the bottleneck’s capacity and monitors the packet RTT (hence its name). BBR can then optimize how much traffic is sent and can pace data packets, while minimizing delays due to packets being stuck in a queue.
使用限制:
BBR 算法中依赖 TCP 数据包中的 timestamps 字段,从而完成 RTT 的计算。但是,在 Linux 内核中,数据包穿越网络命名空间过程中, 数据包的 timestamps 字段未得到保留,云原生场景下的pod 数据包就无法实施 BBR 算法。因此,在 linux 5.18内核版本中,加入了一个 PR , 保留了timestamps 字段,使得 cilium BBR 功能得以实施,换言之,该功能至少需要 linux 5.18+ 的高内核。
在 GCP 的一文中,很好说明了 BRR 算法和其性能 https://cloud.google.com/blog/products/networking/tcp-bbr-congestion-control-comes-to-gcp-your-internet-just-got-faster
在 KubeConf Europe 2022 上,就有相关的 topic 详细说明了 cilium BBR ,具体可参考 https://static.sched.com/hosted_files/kccnceu2022/08/KubeCon_EU_Better_Bandwidth_Management_with_eBPF.pdf
关于该功能的具体使用说明,可参考官方文档 https://docs.cilium.io/en/latest/gettingstarted/bandwidth-manager/#bbr-for-pods
03 BGP Control Plane
在 v1.11 版本前,cilium 引入了 metallb 组件,来实现对 loadbalancer service 的支持,metallb 能帮助 cilium 向外部发布 loadbalancer ip 和 pod CIDR 的 BPG 路由。
但是,该方案存在问题:
-
不能实现复杂的 BPG 拓扑。例如,不同的 node 实现差异化的 BPG peer 策略,以满足数据中心复杂的 BPG ASN 区域规划
-
cilium 集成的 metallb 版本,不支持 BPG IPv

图片来源:https://isovalent.com/blog/post/cilium-release-112/
因此,在 v1.12 版本中,cilium 引入了新的 CiliumBGPPeeringPolicy CRD,基于 gobpg package 单独开发了一个 BPG 模块,在 cilium agent 中实现了 BPG 实例,从而解决之前版本中的 2 个问题。
但是值得留意的是,作者本人暂未找到该 CiliumBGPPeeringPolicy 支持传播 clusterIP CIDR 的信息,也许会在后续版本中支持?
CiliumBGPPeeringPolicy 的具体使用方法,可参考 https://docs.cilium.io/en/latest/gettingstarted/bgp-control-plane/#ciliumbgppeeringpolicy-crd
04 Dynamic allocation of pod CIDRs
Cilium 的 IPAM 模式有很多种,具体可参考官方文档 https://docs.cilium.io/en/stable/concepts/networking/ipam/
私有化部署场景下,主要可使用 “cluster-pool” 和 “kubernetes” 模式。而在新版本中,引入了新模式 “cluster-pool-v2beta”,它有什么不同呢?
其背后设计的初衷,是这样的:
不同的 node 可能有不同的规格,能够运行的 pod 最大数量能力各不相同;pod 资源开销各不相同,所以最终每个 node 上运行的 pod 数量也各不相同 ..... 因此,不同 node 上的 IP 资源开销或多或少,如何让每个 node 上更加合理地按需分配 IP 资源呢?这就是 “cluster-pool-v2beta” 模式的设计初衷。
“cluster-pool-v2beta” 模式,是在 “cluster-pool” 模式的原理基础上,增强了按需分配 CIDR 的能力,使得 IP 资源分配得更加高效。
apiVersion: cilium.io/v2kind: CiliumNodemetadata:name: worker-node-3spec:ipam:podCIDRs:- 10.0.0.0/26- 10.0.1.64/26- 10.0.2.192/26status:ipam:pod-cidrs:10.0.0.0/26:status: in-use10.0.1.64/26:status: depleted10.0.2.192/26:status: released引用如上 CiliumNode yaml,简单来说,每个 node 会根据 IP 消耗的需求,分配到一个或者多个 pod CIDR,记录在 CiliumNode.status 中,而 cilium operator 会对使用的 每个 CIDR 进行状态标记,在 pod CIDR 中的 IP 用量 触发相关阈值时,会尝试给 node 分配新的 pod CIDR,或者回收 当前已分配 pod CIDR,因此,使得集群整体更加 “节约” 的分配 IP。
具体可参考官方的使用文档 https://docs.cilium.io/en/stable/concepts/networking/ipam/cluster-pool/#cluster-pool-v2-beta
05 其他
以下功能,设计初衷和使用相对易于理解:
-
多集群进行 cluster mesh 联通建立,除了使用 cilium CLI 方式外,额外支持了 helm 方式配置
-
在 v1.11 之前的版本中,kube proxy replacement 能够完成流量在多个集群间的 service 实现负载均衡,但是,并不能感知 topology 。因此,在 v1.12 版本中,对于多集群间共享的 service,可以给其打上 annotation "io.cilium/service-affinity",实现亲和性访问,实现 “就近本地集群” 或者 “亲和远端集群” 的访问。具体可参考官方使用文档 https://docs.cilium.io/en/stable/gettingstarted/clustermesh/affinity/#enabling-global-service-affinity
-
支持接入 lightweight Kubernetes clusters (e.g. k3s),可参考官方使用文档 https://docs.cilium.io/en/latest/gettingstarted/external-workloads/
-
支持了第三方的 IPAM 插件,可参考PR https://github.com/cilium/cilium/pull/19219
-
数据包 masquerading 功能,对于出口网卡上的源 IP 选择,有了优化:之前的版本使用了 firstGlobalV4Addr() 算法, v1.12 版本 改为了 “优先选择 k8s node IP” ,具体可参考 https://github.com/cilium/cilium/pull/16849
-
Cilium agent daemonset 支持运行在 非特权模式下, 可避免 因为被攻击 后 产生的 安全风险
-
网络 policy 的增强:在之前的版本中,网络 policy 不支持对 ICMP 和 ICMPv6 协议的过滤。在本次版本中,得到了支持,使用方法可参考官方的文档 https://docs.cilium.io/en/stable/policy/language/#limit-icmp-icmpv6-types
-
作为可使用在数据中心边缘的 standalone L4LB 组件,支持了 NAT46 和 NAT64 负载均衡,帮助单栈应用实现提供了可双栈访问的解决方案,具体可见 PR https://github.com/cilium/cilium/pull/18779
-
对于 AWS、AKS 等公有云场景下,得到更多的支持和能力增强
-
对于已经 deleted pod ,如果还有Clients尝试访问,其实是得不到响应的,但是,tcp_syn_retries的机制,导致clients 还会进行无效的建链尝试,产生额外的开销。新版本对这种场景进行了优化,cilium 会安装 unreachable 路由,使得访问这些已经不存在的pod ip 时,clients能够第一时间得到 ICMP 不可达响应,避免无效的 tcp 握手尝试,细节可参考 PR https://github.com/cilium/cilium/pull/18505
-
Egress Gateway 功能成为 stable,值得注意的是,废弃了老版本中的 CiliumEgressNATPolicy CRD,重新设计了增强版的 CiliumEgressGatewayPolicy CRD,其可以指定哪些node作为gateway node,且可指定 node 上的流量出口网卡。注意的是,当前 Egress Gateway 只支持 IPv4 ,还不支持 IPv6,希望 cilium 后续能补足这个拼图。具体可参考官方的使用文档 https://docs.cilium.io/en/latest/gettingstarted/egress-gateway/
-
为了对接集群外部的 VTEP ,实现 vxlan 隧道的打通,解决对接包括 F5 BIG-IP 等产品,cilium v1.12 出了一个有趣的功能,能够实现对接集群外部的 VTEP,在 overlay 网络层面实现联通后,外部就可以直接访问集群的 pod ip 了。具体可参考官方使用文档 https://docs.cilium.io/en/latest/gettingstarted/vtep/
本文作者 :蓝潍洲 云原生研究院院长
-
-
相关阅读:
Lambda 表达式
SpringMVC工作流程(八股速记)
Selenium环境+元素定位大法
计算机网络 套接字函数 | socket、bind、listen、accept、connect
全民阅读营造良好氛围 助力培养孩子阅读习惯
【C++】类和对象——下
Unity 雷达项目分析(更新ing)
轻量级CI/CD发布部署环境搭建及使用_01_基本介绍
发明专利转让需要多久
Vue2 01 前端核心分析、HelloVue
- 原文地址:https://blog.csdn.net/DaoCloud_daoke/article/details/126098509
