-
3天精通nginx第二天-负载均衡upstream配置

负载均衡
现在有一堆砖需要搬运,一个老板雇佣了一个程序员进行搬运,这样的模式就是单节点,随着业务的增加运来的砖越来越多,一个程序员搬不过来了,这时候老板又雇佣了两个程序员,让他们三一起搬运,这样就能够及时的将砖搬完,这样的模式就是集群模式。
nginx负载均衡器
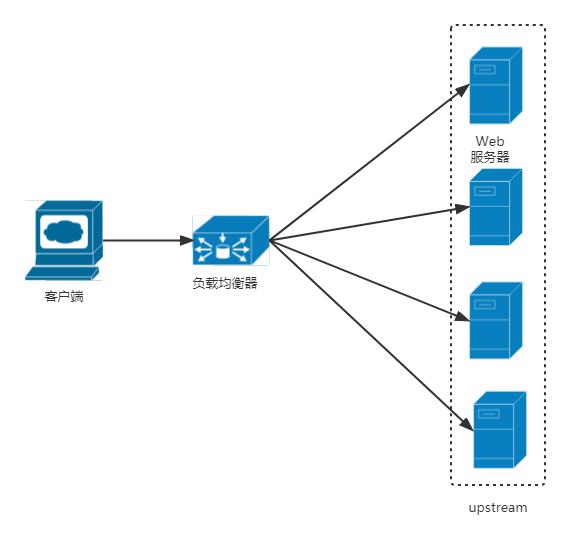
Nginx通过反向代理可以实现服务的负载均衡,避免了服务器单节点故障,把请求按照一定的策略转发到不同的服务器上,达到负载的效果
upstream配置
Directives Syntax: upstream name { ... } Default: — Context: http- 1
- 2
- 3
- 4
定义一组服务器。服务器可以监听不同的端口。此外,监听TCP和UNIX域套接字的服务器可以混合使用。
示例:
upstream backend { server 192.168.110.102:8081 weight=5; server 192.168.110.102:8082; server 192.168.110.102:8083; server 192.168.110.102:8084 backup; server 192.168.110.102:8085 backup; } server { location / { proxy_pass http://backend; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
默认情况下,使用加权轮训方法在服务器之间分配请求。在上面的例子中,每7个请求将按如下方式分配:5个请求分配给192.168.110.102:8081并且向第二和第三服务器中的每一个发送一个请求。如果在与服务器通信的过程中出现错误,请求将被传递到下一个服务器,依此类推,直到所有正常工作的服务器都被尝试过。如果无法从任何服务器获得成功的响应,客户端将收到与最后一个服务器通信的结果。
nginx负载均衡的5种策略
- 轮训(默认)【重要程度:★★★★】
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。轮训其实为weight=1
upstream backend { server 192.168.110.102:8081; server 192.168.110.102:8082; }- 1
- 2
- 3
- 4
- weight【重要程度:★★★★】
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的 情况。
upstream backend { server 192.168.110.102:8081 weight=3; server 192.168.110.102:8082 weight=7; }- 1
- 2
- 3
- 4
权重越高,在被访问的概率越大,如上例,分别是30%,70%。
- ip_hash【重要程度:★★★】
上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。 我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。 每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream backend { ip_hash; server 192.168.110.102:8081; server 192.168.110.102:8082; }- 1
- 2
- 3
- 4
- 5
- fair(第三方)【重要程度:★★★】
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream backend { server 192.168.110.102:8081; server 192.168.110.102:8082; fair; }- 1
- 2
- 3
- 4
- 5
- url_hash(第三方)【重要程度:★★★】
按访问url的hash结果来分配请求,使每个url定向到同一个(对应的)后端服务器,后端服务器为缓存时比较有效。
upstream backend { server 192.168.110.102:8081; server 192.168.110.102:8082; hash $request_uri; hash_method crc32; }- 1
- 2
- 3
- 4
- 5
- 6
其他指令
-
最大连接数:max_conns=number【重要程度:★★】
max_conns属性是用来限制同时连接到upstream负载上的单个服务器的最大连接数,作用是可以对单个服务器进行限流,防止服务器超负荷运转.默认值为0,则表示没有限制
upstream backend { server 192.168.110.102:8081 max_conns=2; }- 1
- 2
- 3
-
最大失败次数(默认1次):max_fails=number 【重要程度:★★★★】
-
失败时间(默认10s):fail_timeout=time
在失败时间内请求某一server失败达到最大失败次数后,则认为该server已经挂了或者宕机了,随后的失败时间之内不会有新的请求到达刚刚挂掉的节点上,而是会请求到正常运作的server,失败时间后会再有新请求尝试连接挂掉的server,如果还是失败,重复上一过程,直到恢复
upstream backend { server 192.168.110.102:8081 max_fails=2 fail_timeout=15s; server 192.168.110.102:8082; server 192.168.110.102:8083; }- 1
- 2
- 3
- 4
- 5
-
down【重要程度:★★】
将服务器标记为永久不可用
upstream backend { server 192.168.110.102:8081 down; # 将服务器标记为永久不可用 }- 1
- 2
- 3
-
keepalive connections【重要程度:★★★★】
长连接数是为了解决在高延迟网络上建立tcp连接的延迟问题,适当的配置长连接数,能够增加吞吐量及响应速度。
这
connections参数设置每个工作进程的缓存中保留的到上游服务器的最大空闲keepalive连接数。当超过这个数量时,最近最少使用的连接将被关闭。应该特别注意的是
keepalive指令不限制nginx工作进程可以打开的上游服务器连接的总数。这connections参数应该设置为一个足够小的数字,以便上游服务器也能处理新的传入连接。upstream backend { server 192.168.110.102:8081; keepalive 16; # 这个配置值应尽量保持小一些 } server { ... location /http/ { proxy_pass http://backend; proxy_http_version 1.1; # 对于HTTP来说proxy_http_version指令应设置为1.1 proxy_set_header Connection ""; # 清除“连接”头字段 ... } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
backup:其它所有的非backup机器down或者忙的时候,请求backup机器
upstream upstream {
server 192.168.110.102:8081 backup; (其它所有的非backup机器down或者忙的时候,请求backup机器)
}
实战配置-代理后台服务
#user nobody; worker_processes 8; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 10240; } http { include mime.types; default_type application/octet-stream; log_format main '[$upstream_addr] - $remote_addr - $remote_user [$time_local] - [$request_time] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; #(close log) #access_log logs/access.log /dev/null; access_log logs/access.log main; #access_log off; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 90; keepalive_requests 600; proxy_http_version 1.1; gzip on; # 设置是否开启gzip模块,减少带宽的开销,提高传输效率、渲染效率 gzip_min_length 1k; #最小压缩文件大小 gzip_comp_level 2; #gzip 压缩级别,1-9,数字越大压缩的越好,也越占用CPU时间 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png application/vnd.ms-fontobject font/ttf font/opentype font/x-woff image/svg+xml; #压缩类型,默认就已经包含textml,所以下面就不用再写了,写上去也不会有问题,但是会有一个warn。 gzip_vary on; # 是否在http header中添加Vary: Accept-Encoding,建议开启 #------------------------------------------------------------- upstream myipconfig1{ server localhost:8081; server localhost:8082; #ip_hash; } # server { listen 28010; server_name 127.0.0.1; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; proxy_pass http://myipconfig1; proxy_redirect off; proxy_set_header Host $host; #使用CDN自定义IP头来获取 proxy_set_header X-Real-IP $remote_addr; #后端的Web服务器可以通过X-Forwarded-For获取用户真实IP proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; #允许客户端请求的最大单文件字节数 client_max_body_size 10m; #缓冲区代理缓冲用户端请求的最大字节数, #如果把它设置为比较大的数值,例如256k,那么,无论使用firefox还是IE浏览器,来提交任意小于256k的图片,都很正常。如果注释该指令,使用默认的client_body_buffer_size设置,也就是操作系统页面大小的两倍,8k或者16k,问题就出现了。 #无论使用firefox4.0还是IE8.0,提交一个比较大,200k左右的图片,都返回500 Internal Server Error错误 client_body_buffer_size 128k; #后端服务器连接的超时时间_发起握手等候响应超时时间 #nginx跟后端服务器连接超时时间(代理连接超时) proxy_connect_timeout 300; #后端服务器数据回传时间(代理发送超时) #后端服务器数据回传时间_就是在规定时间之内后端服务器必须传完所有的数据 proxy_send_timeout 300; #连接成功后,后端服务器响应时间(代理接收超时) #连接成功后_等候后端服务器响应时间_其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间) proxy_read_timeout 300; #设置代理服务器(nginx)保存用户头信息的缓冲区大小 #设置从被代理服务器读取的第一部分应答的缓冲区大小,通常情况下这部分应答中包含一个小的应答头,默认情况下这个值的大小为指令proxy_buffers中指定的一个缓冲区的大小,不过可以将其设置为更小 proxy_buffer_size 4k; #proxy_buffers缓冲区,网页平均在32k以下的设置 #设置用于读取应答(来自被代理服务器)的缓冲区数目和大小,默认情况也为分页大小,根据操作系统的不同可能是4k或者8k proxy_buffers 4 32k; #高负荷下缓冲大小(proxy_buffers*2) proxy_busy_buffers_size 64k; #设置在写入proxy_temp_path时数据的大小,预防一个工作进程在传递文件时阻塞太长 #设定缓存文件夹大小,大于这个值,将从upstream服务器传 proxy_temp_file_write_size 64k; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
如果感觉这篇文章对您有帮助,可以给博主点赞、评论、收藏,这样是对博主最大的鼓励,谢谢。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
-
相关阅读:
1.一分钟用esp32-cam实现局域网视频监控
暑假打工 2 个 月,让我明白了 Keepalived 高可用的三种路由方案
SQL基础知识笔记
简单了解一下国产操作系统
设计模式之状态模式
[网鼎杯 2020 青龙组]notes(Undefsafe原型链污染)
web3-引言之读取账户地址
垃圾回收 -标记清除算法
(附源码)ssm考务管理系统 毕业设计 221504
微软在2022年Gartner云计算AI开发者服务魔力象限中被评为“领导者”
- 原文地址:https://blog.csdn.net/emgexgb_sef/article/details/126097934
