-
PowerBI商学院佐罗BI真经连续剧
学习必读代码
- public void string main(String agrs[]){
- //获取课程vx 80407290
- }
一、表格
表是保存信息的容器,分为行和列。每行包含关于单个实体的信息,而每行中的每个单元格包含数据库中表示的最小的信息片段。例如,客户表包含所有客户的信息。一行包含关于一个客户的所有信息,一列可能包含所有客户的名称或地址。一个单元格可能包含一个客户的地址。
在构建模型时,需要避免一些问题。例如,如图0.1,在同一个表的两行中存储关于一个订单的信息。在一行中,存储所订购的金额及其订购日期。在另一行中,存储已发货的金额,同样也包含其发货日期。这样做会将一个实体分割为同一个表的两行,从而不利于匹配。
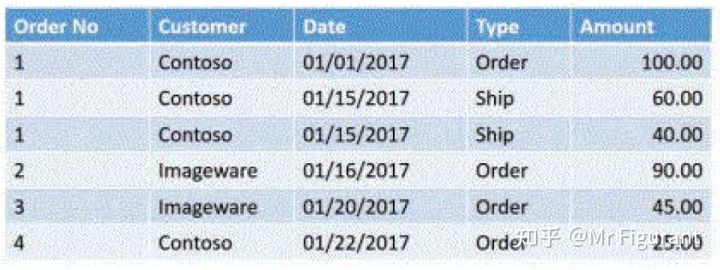
图0.1 将所有数据汇总到一个表中
应该这样做:如图0.2,建立两个分开的表,一个放置订单数据、另一个放置发货数据。
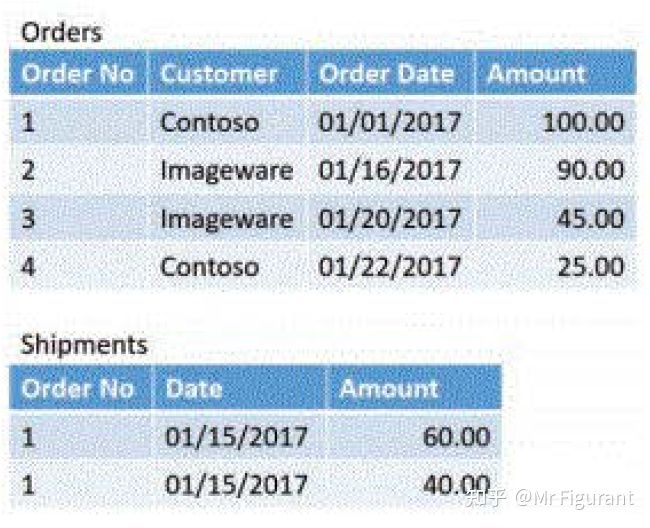
图0.2 分开两张表
二、数据类型
设计模型时,每个列都有一个数据类型。数据类型是列中内容的类型。数据类型可以是整数、字符串、货币、浮点数等等。有许多数据类型可供选择。列的数据类型很重要,因为它会影响列的可用性、可以在列上使用的函数和格式化选项。
在包含装运数量的列中,整数是一个很好的数据类型。在需要存储销售额的列中,货币是正确的数据类型。使用纯Excel时,每个单元格可以包含任何数据类型的值。但是,在使用表格数据模型时,数据类型是在列级别定义的。这意味着表中的所有行需要在该列中存储相同的数据类型。不能为表中的一列使用混合数据类型。
三、关系
当模型包含多个实体时,通常情况下,将信息存储在多个表中,并通过关系将它们链接起来。在表列模型中,关系总是链接两个表,它基于单个列。如图0.3,关系最常见的表示形式是一个箭头,它从源表开始,指向目标表。
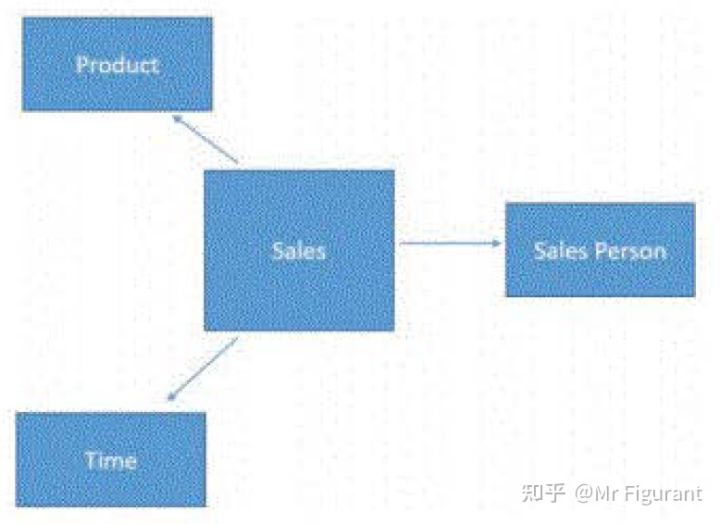
表0.3 表之间的关系
当定义一段关系时,总是有单向和多向。在示例模型中,对于每一种产品,都有许多销售,而对于每一种销售,都只有一种产品。因此,产品表在一边,而销售表在许多一边。箭头总是从多方向指向一侧。
在不同版本的Excel Power Pivot和Power BI中,用户界面使用不同的关系可视化。在Excel和Power BI的最新版本中,都会绘制一行,在行尾用 1 或 * 标记,以标识关系的一方或多方。在Power BI Desktop中,还可以选择创建一对一的关系。一对一的关系总是双向的,因为对于一个表的每一行,在另一个表中只能有0或1行。因此,在这个特殊的情况下,关系没有多向。
四、筛选与跨表筛选
当通过数据透视表或使用Power BI浏览模型时,筛选是非常重要的。事实上,它是报告中大多数计算的基础。使用DAX语言时,规则非常简单:筛选器总是从关系的一方移动到多方。如图0.4,在用户界面中,这由关系中间的一个箭头表示,该箭头显示筛选器如何通过关系传播。
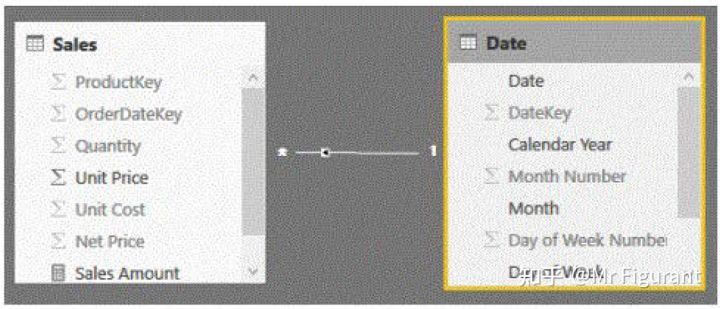
图0.4 关系线内的小箭头代表筛选的方向
当筛选Date的时候,也筛选了Sales。这就是为什么在数据透视表中,可以很容易地按年划分销售额:Date筛选器直接转化为Sales筛选器。相反的方向,在默认情况下是不起作用的。Sales的筛选器不会传播到Date。图0.5显示了默认情况下筛选器是如何传播的图形表示。

图0.5 大箭头表示在开启单向筛选时如何传播筛选器
可以通过修改关系的设置来更改筛选器传播的方向,称为跨表筛选器。例如,在Power BI中,这是通过双击关系本身来实现的。如图0.6,打开“编辑关系”对话框:
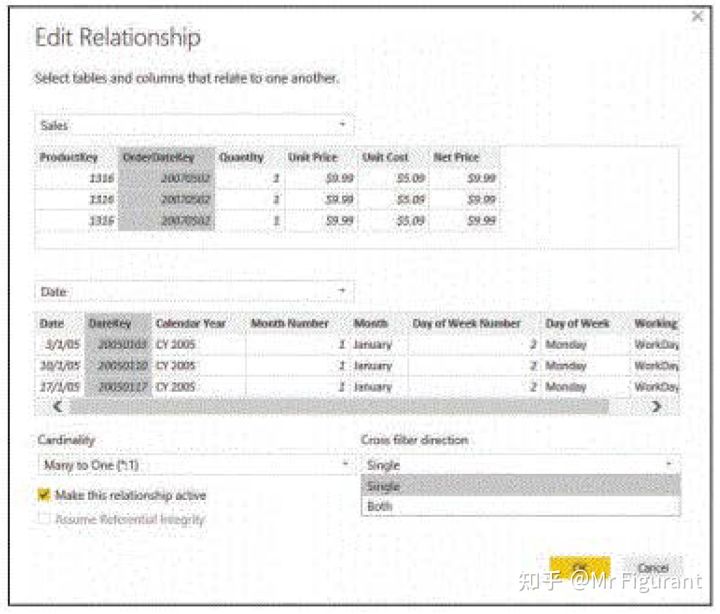
图0.6 “编辑关系”对话框允许修改跨表筛选器
缺省情况下,跨筛选方向为“单向”(一对多)。如果需要,可以将其更改为双向,以便筛选器也从多方向传播到一侧。图0.7显示了将筛选器设置为双向时,它是如何传播的:
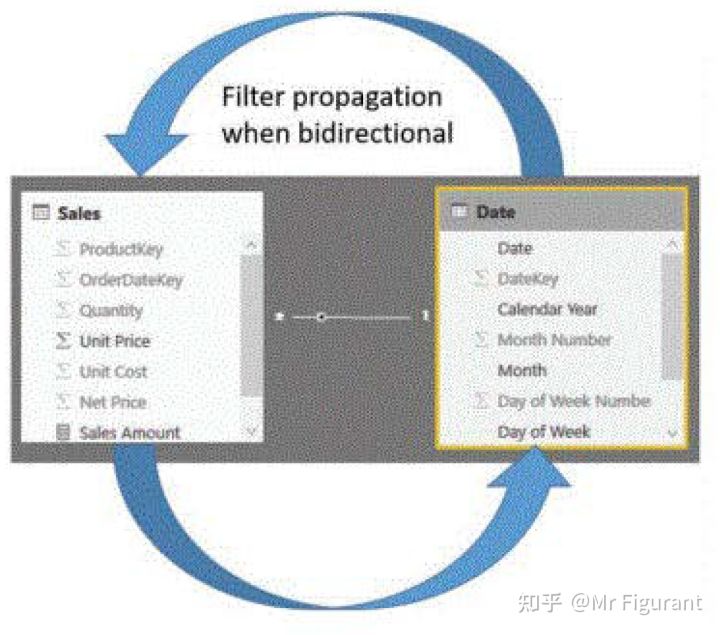
图0.7 在双向模式下,筛选器双向传播。
如果需要在Power Pivot的Excel中激活双向过滤,你必须使用 CROSSFILTER 函数激活它,如下例所示,适用于图0.8所示的模型:
- Num of Customers =
- CALCULATE (
- COUNTROWS ( Customer ) ,
- CROSSFILTER ( Sales[CustomerKey], Customer[CustomerKey], BOTH )
- )
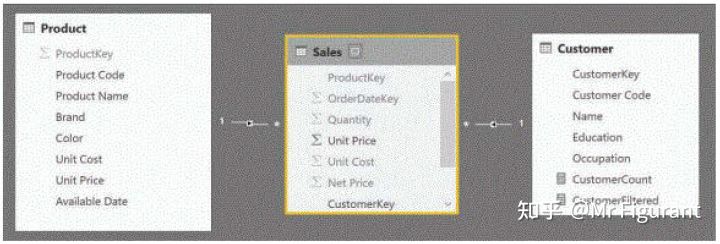
图0.8 这两个关系都被设置为默认模式,即单向模式。
CROSSFILTER 函数允许在计算语句的执行期间进行双向筛选。在对 COUNTROWS ( Customer ) 进行评估时,筛选器将从Sales移动到Customer,只显示Sales中引用的客户。例如,当需要计算购买产品的客户数量时,这种技术非常方便。事实上,筛选器自然地从产品转移到销售。然后需要使用双向筛选,让它通过销售流到客户。举例来说,有两种计算方法如图0.9所示。一个激活了双向筛选,另一个使用默认的筛选传播。
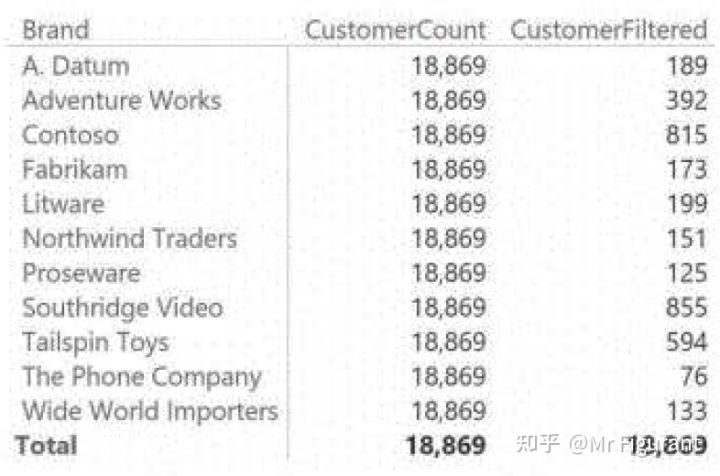
图0.9 这两种方法仅在跨表筛选器的方向上有所不同,结果完全不同
从结果上看,第一种衡量显然是不正确的。这两种衡量的定义如下:
- CustomerCount := COUNTROWS ( Customer )
- CustomerFiltered :=
- CALCULATE (
- COUNTROWS ( Customer ) ,
- CROSSFILTER ( Customer[CustomerKey], Sales[CustomerKey] , BOTH )
- )
可以看到 CustomerCount 使用了默认的筛选。因此,Product 筛选 Sales ,但 Sales 不筛选Customer。在第二种度量中,筛选器从 Product 流向 Sales ,然后到达 Customer,因此公式只计算购买筛选产品之一的客户。
五、不同类型的模型
在典型的模型中,有许多通过关系链接的表。根据这些表的用法,可以这样进行分类:
% 1. 事实表。事实表包含要聚合的值。事实表通常存储在特定时间点发生的、可以度量的事件。事实表通常是模型中最大的表,包含数千万甚至数亿行。事实表通常只存储数字,即维度的键或要聚合的值。(简单来说就是最原始的数据源。)
% 2. 维度表。用维度来切分事实表很有用,典型的维度包括产品、客户、时间和类别。维度表通常是包含数百或数千行的小表,往往有很多字符串形式的属性,主要目的是对值进行切片。
% 3. 桥接表。桥接表在更复杂的模型中用于表示多对多关系。例如,一个可能属于多个类别的客户可以使用桥接表建模,该桥接表包含客户的每个类别的一行。
@ 1. 星型模式
当查看模型的图表时,如果它仅基于事实表和维度构建,那么可以将事实表放在中心,周围是所有的维度。如图0.10,这种安排被称为星型模式。
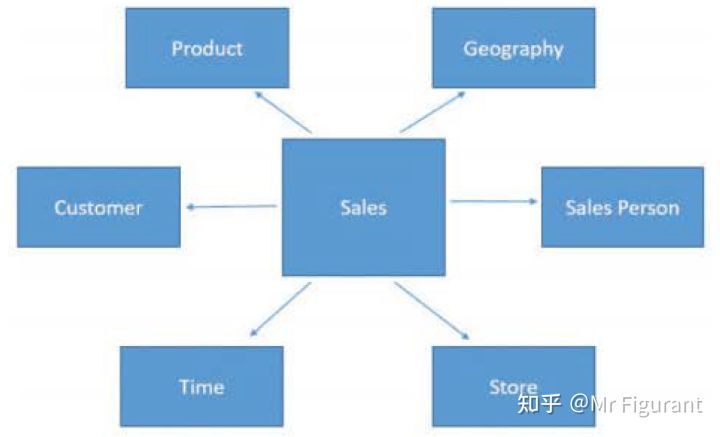
图0.10 将事实表放在中间,并将它周围的所有维度放在中间,就会出现星型模式
星型模式有很多很棒的特性,它们快速、容易理解和管理。星型模式是大多数分析数据库的基础,然而有时候需要以不同的方式构建模型。
@ 2. 雪花模式
有时一个维度被链接到另一个维度以进一步对其进行分类。例如,产品可能有类别,需要将这些类别存储在一个单独的表中。再比如,存储可以按业务单元划分,也可以决定将业务单元存储在单独的表中。例如,图0.11所示的产品中,没有将类别名作为列,而是存储了一个 Category 键,该键对应的是 Category 表。
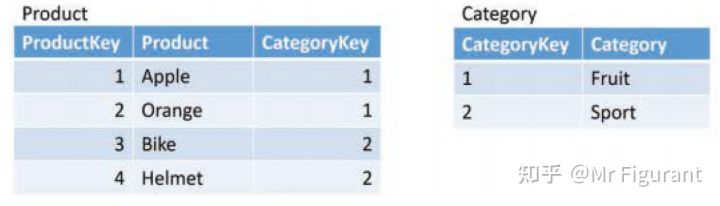
图0.11 类别存储在自己的表中,产品引用该表
如果使用这样的模式,产品类别和业务单元仍然是维度,但它们不是直接与事实表相关,而是通过中间维度相关。例如,Sales表包含ProductKey列,但是要获得类别名称,必须从Sales到达Product,然后从Product到达category。如图0.12,这种情况下称为雪花模式。
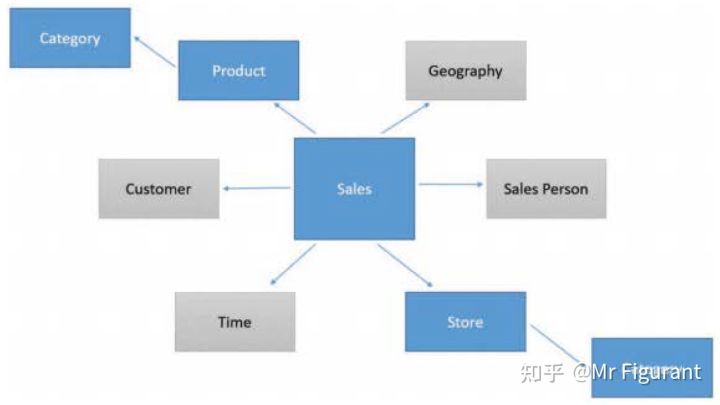
图0.12 雪花模式在星型模式的基础上,用额外维度接到原始维度
维度本身之间没有联系。例如,可以将类别和销售额之间的关系视为直接关系,但它是通过Store表传递的。可以直接将商店与地理位置联系起来。事实上,在这种情况下,模型将变得模糊,因为从销售到地理位置存在多条路径。
雪花模式在商业智能(BI)领域中有些常见。除了性能略有下降外,还是一个不错的选择。尽管如此,最好避免出现雪花模式,并坚持使用更标准的星型模式,因为DAX代码往往更容易开发,更不容易出错。
@ 3. 包含桥接表的模型
桥接表通常位于两个维度之间,以便在维度之间创建多对多关系。例如,图0.13显示了一个客户可能属于多个类别。Marco 属于男性和意大利类别,而 Kate 只属于女性类别。如果有这样的场景,从桥梁和连接开始设计两个关系,分别是 Customer 和 Category。
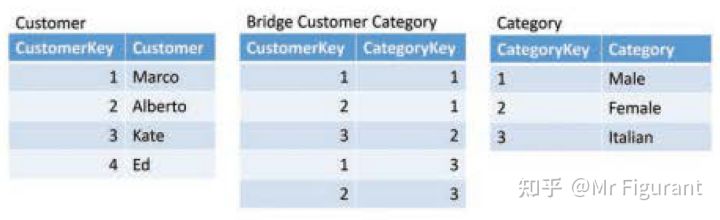
图0.13 桥接表允许单个客户属于不同类别
当模型包含桥接表时,采用BI中从未命名过的新形状。如图0.14,将一个客户的能力添加到多个客户类别中:
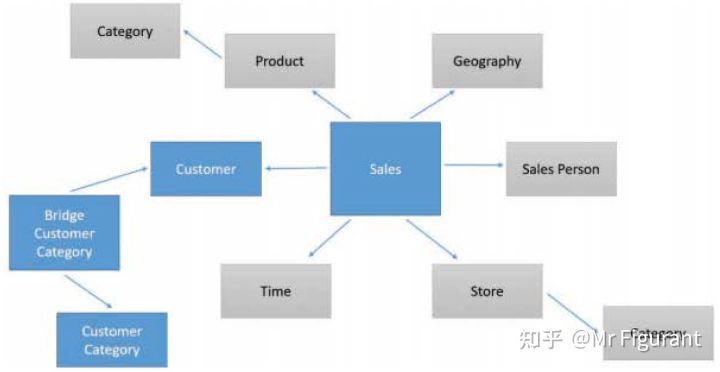
图0.14 桥接表连接两个维度,不同于一般的雪花模式
常规雪花模式与使用桥接表的模式之间的区别在于,客户类别和销售之间的关系不是经过两个维度的直接关系。事实上,客户与桥梁的关系是相反的。如果它是从客户到桥的,那么它将是雪花模式。它变成了一个多对多关系。
六、度量与可加性
在定义度量时,一个重要的概念是该度量对于特定维度是否具有可加性。
@ 1. 可加性度量。当一个度量用一个简单的和来聚合时,它就被称为可加的。例如,销售额是对于产品而言是可加的,这意味着总销售额来自于单个产品的销售额总和。另一个例子是,销售对所有维度都是可加的,因为一年的总销售是由各个天的销售总和产生的。
@ 2. 非可加性度量。如果对售出的产品进行不同计数,那么一年的不同计数就不是每个月不同计数的总和。这同样适用于客户、国家和任何其他方面。当需要计算非相加度量时,必须对正在浏览的层次结构的每个级别执行表的完整扫描,因为不能从它们的子级聚合值。
@ 3. 半可加性度量。半可加性度量是最复杂的度量,因为它们对某些维度是可加性的,对其他维度是不可加性的。通常,作为异常的维度是时间。例如,Year-to-Date,的计算是非加性的,因为显示的一个月的值不是单个天数的总和。
图0.15展现了可加性、非可加性、半可加性的对比:
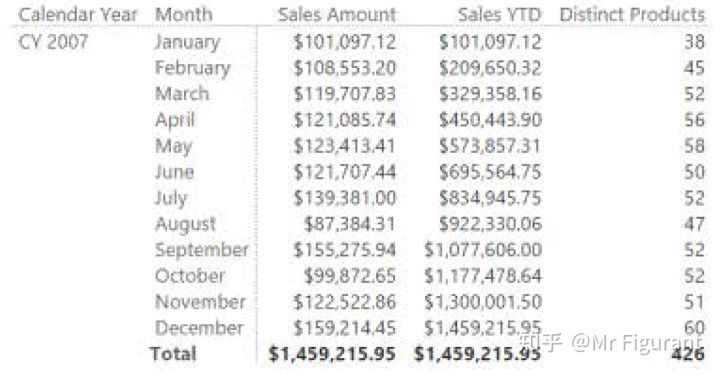
图0.15 三种可加性的比较
DAX提供了一组函数来处理随时间变化的半加性。当时间是非加性维度时,像DATESYTD, TOTALYTD 等等可以编写半加性度量。处理不同维度的半可加性需要更加复杂的筛选函数,因为没有预定义的函数来处理与时间无关的维度的非加性。
-
相关阅读:
微服务11-Sentinel中的授权规则以及Sentinel服务规则持久化
前端开发组件分享:呼出按钮动画
从一个简单的main方法执行谈谈JVM工作机制
C++ 外观模式的实现
1529_AURIX_TriCore内核架构之编程模型
DOM与BOM
【算法练习Day48】回文子串&&最长回文子序列
自动化测试的生命周期是什么?
二十一、操作系统设计(POSIX;Windows API;Micro/Exo/Unikernel)
ubuntu 18.04换内核后找不到 /dev/ttyUSB0问题
- 原文地址:https://blog.csdn.net/m0_67595943/article/details/126098150

