-
(一)从rnn attention 到 attention withouot rnn 再到transformer
参考:https://www.youtube.com/watch?v=aButdUV0dxI&list=PLvOO0btloRntpSWSxFbwPIjIum3Ub4GSC
1、attention for seq2seq model

seq2seq包含一个encoder和一个decoder。encoder类似于rnn,deocder类似于文本生成器。
attention机制如何引入?
在计算decoder的每一个step生成时,会用到attention,那么其中的Q、K、V如何去理解?
首先,我们想得到每个step的生成c,c肯定是由权重乘积再相加得来的。那么权重参数以及与它相乘的数肯定是与encoder有关的。
1)对于encoder的每一个step的状态h,分别乘以W(k) W(v),得到key value ,所有的step的key value组成大矩阵K V。
2)K与decoder的当前step的状态s 进行softmax操作,得到权重矩阵 A。
3)A再与V值进行加权求和得到当前step的结果c。
2、attention without rnn

1)得到Q K V,去掉rnn之后,直接用输入的词向量去得到K V,与之前的相比,不同的是用词向量去代替RNN的每一个step得到的隐状态h。

2)得到权重矩阵A .
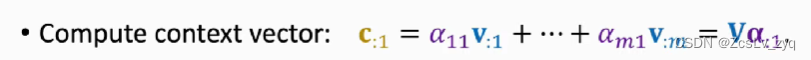
3) 加权求和得到当前step的输出c
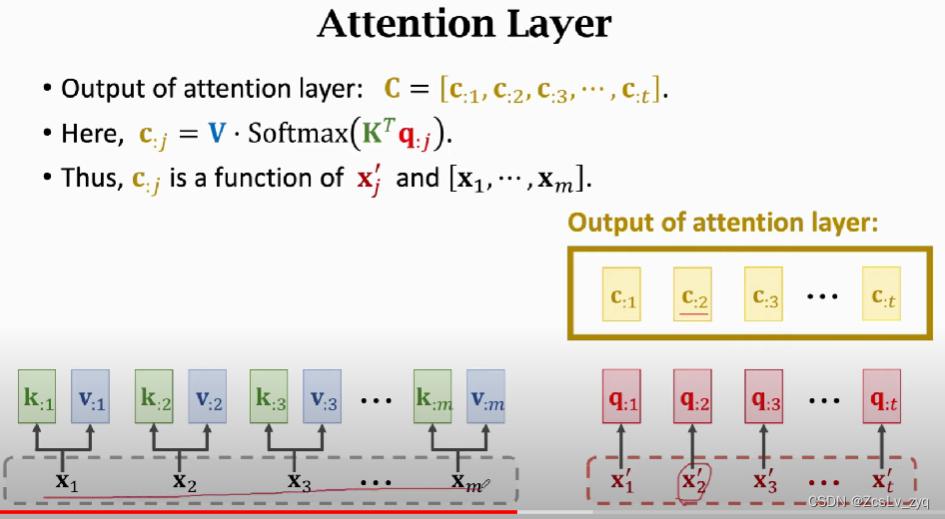
4) 重复步骤3)即可得到所有的step的输出。由c的公式可知,每个step的输出c不仅与当前step的输入x有关,更与encoder所有的step的k、v有关,因此它能用到encoder所有的信息。

总结:attention layer。
seq2seq输入是两个序列X,X'
3、self-attention layer
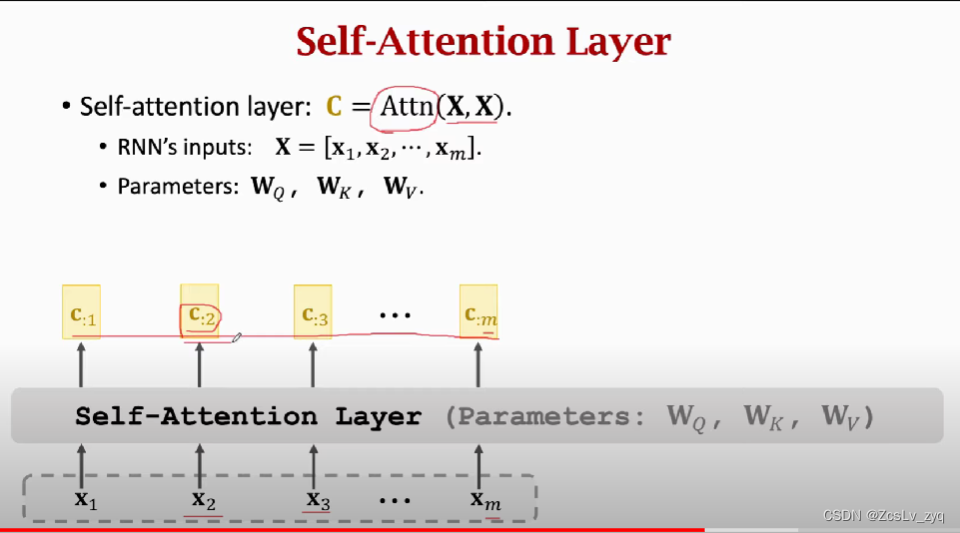 与attention layer不同的是,它输入序列只有一个X,但每一个输出的c与所有的输入x有关,而不是当前step的x
与attention layer不同的是,它输入序列只有一个X,但每一个输出的c与所有的输入x有关,而不是当前step的x步骤:
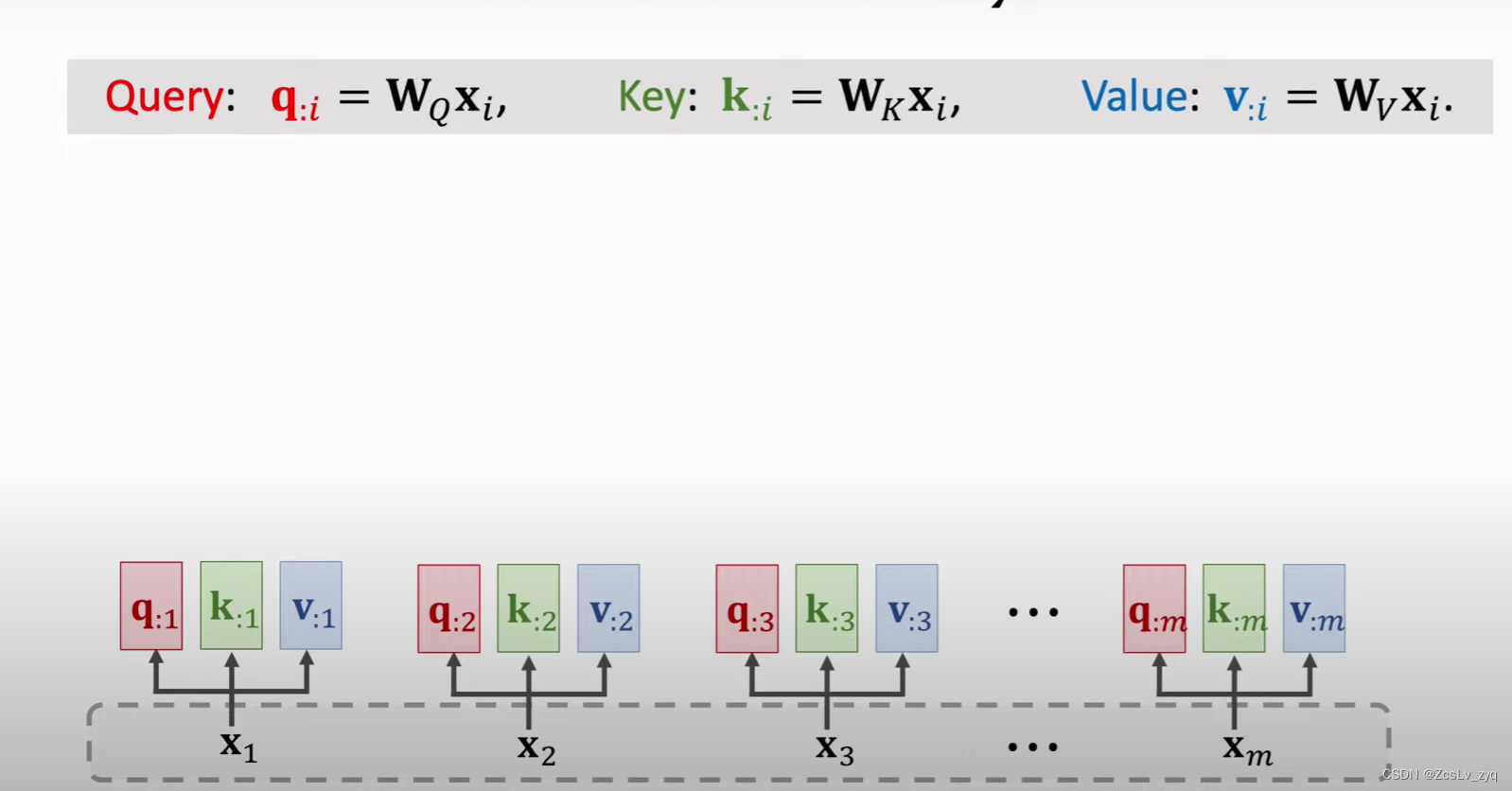
1)得到Q K V,与之前不同的是,Q也来源于x
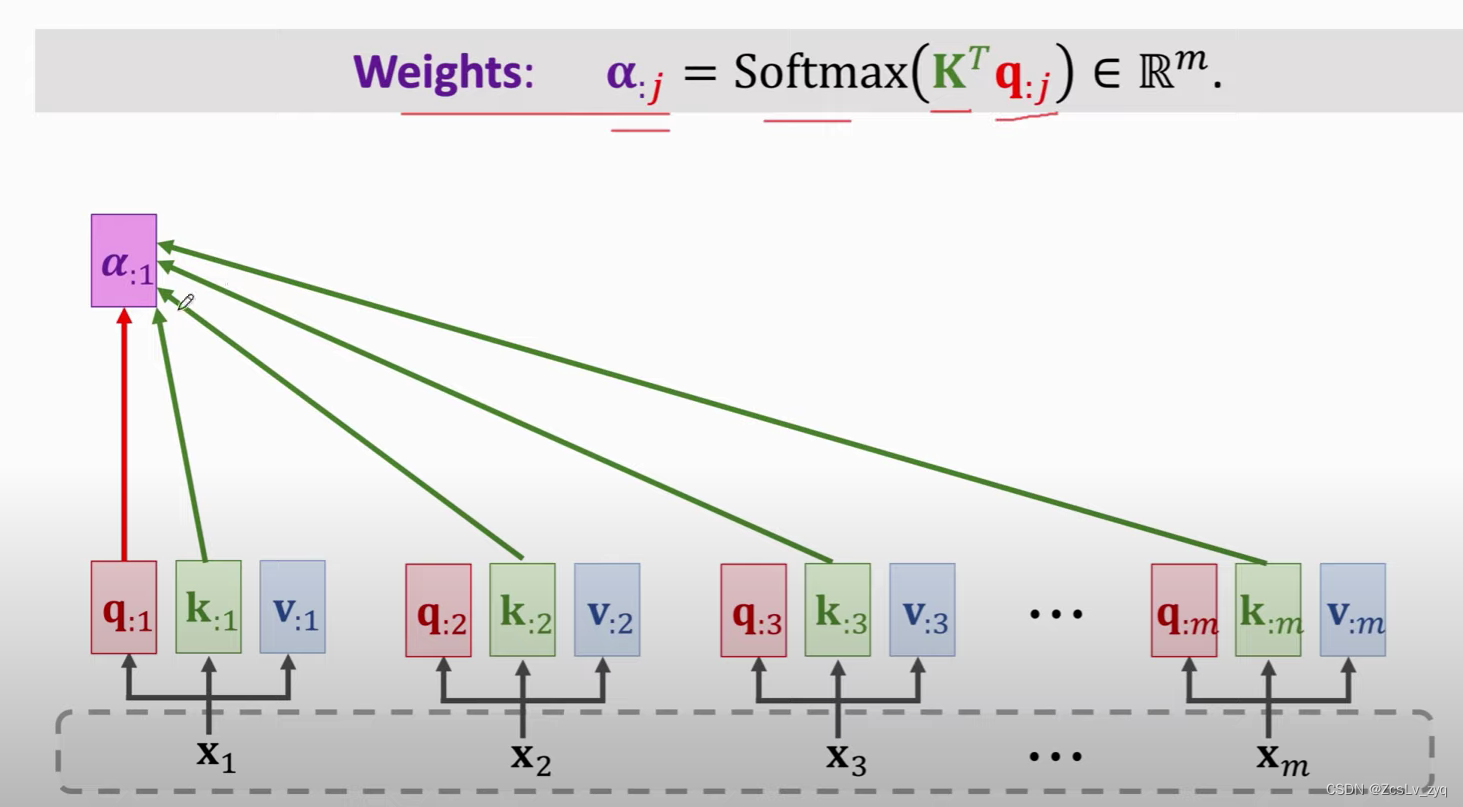
2) 得到权重矩阵A
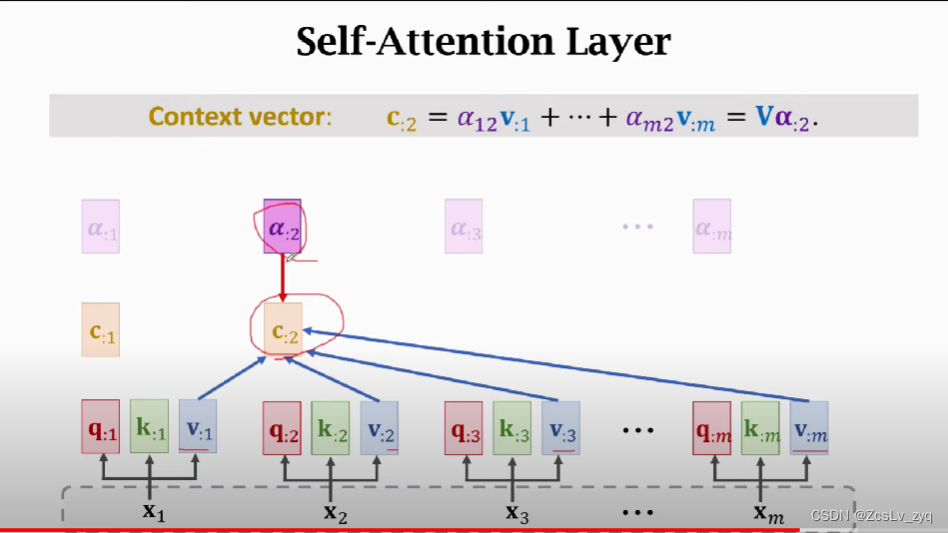
3) 加权求和得到当前step的输出c

4) 总结
attention可以用在seq2seq上,也可以脱离seq2seq、rnn,独立开来,这样就称为self-attention。
-
相关阅读:
postgresql基于postgis常用空间函数
基于SSM的医院在线挂号预约系统的设计与实现
Vite3+Vue3+JypeScript:搭建企业级轻量框架实践
高颜值跨平台终端Windterm
远程调试为何要亲历现场,也许也可以这样解决
Gitlab 降级(reconfigure 失败)
java对象传递给前端vue表格从上插入的效果
算法-递增三元组
网络安全进阶学习第十八课——业务逻辑漏洞(附录:不同行业业务逻辑的漏洞)
【Hack The Box】windows练习-- Resolute
- 原文地址:https://blog.csdn.net/ZcsLv_zyq/article/details/126095152