-
语义分割 FCN-DenseNet 应用入门
1. 简介
在计算机视觉领域,语义分割指的是将数字图像细分为多个图像子区域的过程
语义分割的目的是简化或改变图像的表示形式,使得图像更容易理解和分析
语义分割通常用于定位图像中的物体和边界(线,曲线等)
更精确的,语义分割是对图像中的每个像素加标签的一个过程,
这一过程使得具有相同标签的像素具有某种共同视觉特性
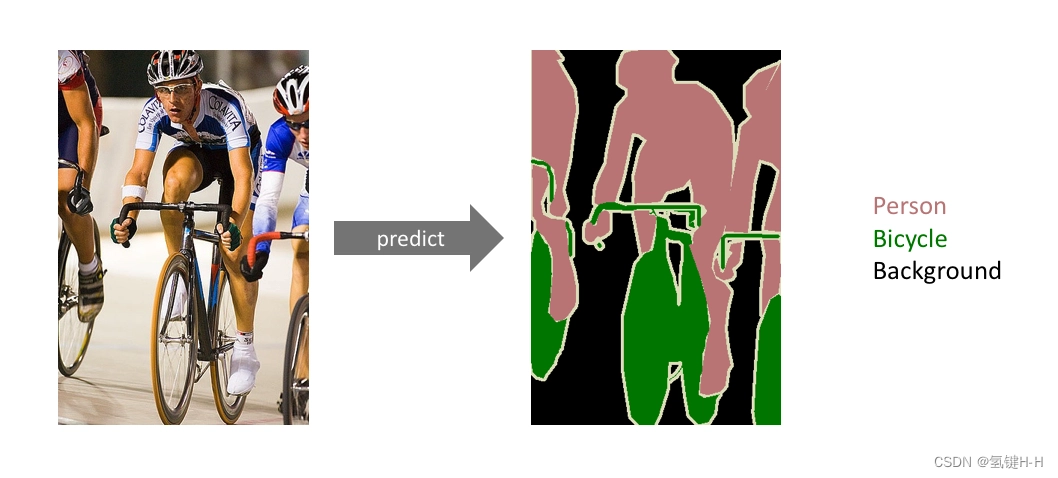
语义分割的领域非常多,无人车、地块检测、表计识别等等
2. 源码
根据GitHub上开源的代码 Sharpiless FCN-DenseNet 进行一些更改:
- 调整数据集分布
- 新增训练和检验过程可视化
- 新增数据集处理工具
- 新增预训练模型
- 新增少许自定义参数等
可以通过以下渠道下载:
3. 数据集
3.1 开源数据集
本案例使用飞桨里的一个例子的 Oxford-IIIT Pet数据集
里面包含了宠物照片和对应的标签数据
宠物图片在/images
标签数据在/annotations/trimaps
具体详情参考 飞桨官方文档说明

这边标签是灰度图,还需要在处理一下,利用tool_img2mask.py根据实际情况将所有标签图片转换为所需的格式
左边为原图标签,宠物为1,背景为2,边缘为3,这里处理后只保留宠物特征然后通过
tool_img2data.py将原图和标签打乱并按比例分配到新的地址成为训练集和测试集
原图训练集:/resources/images/data/train/img
标签训练集:/resources/images/data/train/mask
原图测试集:/resources/images/data/test/img
标签测试集:/resources/images/data/test/mask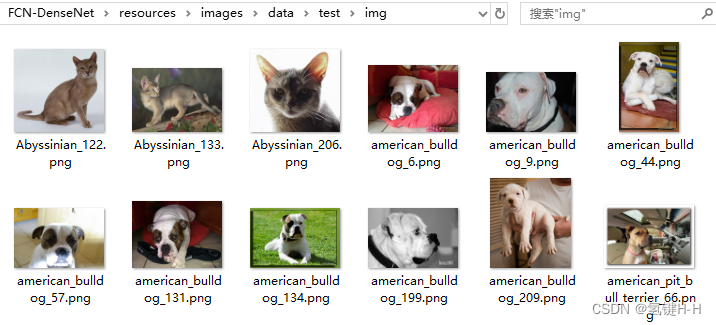
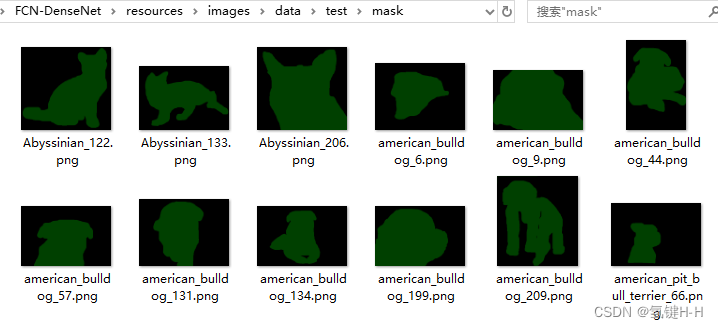
3.2 自定义数据集
3.2.1 建立数据集文件夹
在工程中新建文件夹
/resources/images/data_json,将所有数据原图均放置于此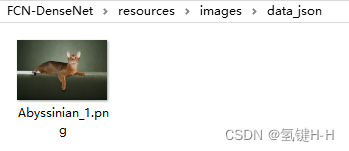
这里以Oxford-IIIT Pet数据集的第一张图片为例
3.2.2 标注
使用 开源的数据标注工具Labelme
安装也比较简单,版本不要太高了,后面用的时候会有问题:$ pip3 install labelme==3.16.2- 1
在
/resources/images/data_json启动 Labelme$ labelme- 1

保存为 json 格式,并在同一地址,后续方便转换处理
3.2.3 转化
此时再通过
tool_json2dataset.py转化所有文件并生成原图和标签图片
此时所有可以利用的数据均在/resources/images/dataset文件夹中然后同样通过
tool_dataset2data.py将 dataset 中的原图和标签打乱并按比例分配到新的地址成为训练集和测试集
原图训练集:/resources/images/data/train/img
标签训练集:/resources/images/data/train/mask
原图测试集:/resources/images/data/test/img
标签测试集:/resources/images/data/test/mask
4. 训练
为了有足够强大的数据,这里使用处理过的Oxford-IIIT Pet数据集
根据自己电脑硬件合理调整参数进行训练,执行train.py文件
默认每5次迭代验证并保存最优的模型于parameters_densenet121文件夹parser.add_argument('--svae_interval', type=int, default=5) # svae interval- 1
5. 验证
执行
test.py文件
可以在resources/images/data/test看到分割的效果图:
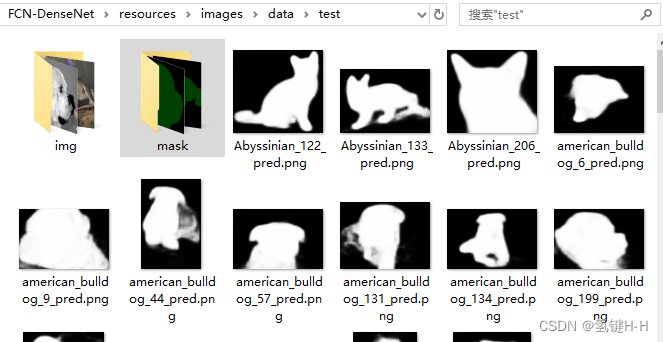
抽取mask里的图片出来对比效果:
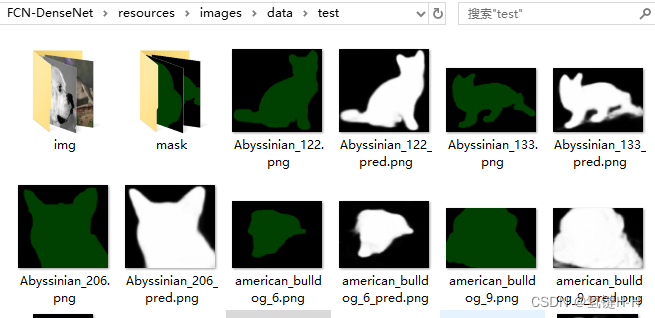
还是可以的
谢谢
-
相关阅读:
【Android 屏幕适配】屏幕适配通用解决方案 ③ ( 自定义组件解决方案 | 获取设备状态栏高度 | 获取设备屏幕数据 )
Fourier变换中的能量积分及其详细证明过程
Redis分布式锁(下篇)
Python基础(二):不同系统安装Python3
Java 华为真题-出租车计费
apache中的ab压测
web-logic-ssrf内网渗透
快解析DDNS 无需公网ip 安全高效
【Python】自动化办公之路:word自动化实战宝典!
大语言模型RAG-将本地大模型封装为langchain的chat model(三)
- 原文地址:https://blog.csdn.net/qq_32618327/article/details/125654652