-
一文带你了解推荐系统常用模型及框架
可以看KDD会议,最新推荐系统论文。
推荐系统概述
传统推荐模型Old school Model
协同过滤模型
通过对用户之间的关系,用户对物品的评价反馈一起对信息进行筛选过滤,从而找到目标用户感兴趣的信息。

用户—商品的评分矩阵(该矩阵很可能是稀疏的)
用户\物品 x x x x x x 行向量表示每个用户的喜好,列向量表明每个物品的属性
基于评分矩阵(行列)计算相似度,以下是计算相似度的一些方法:
- 余弦相似度
- 皮尔逊相关系数
- 欧氏距离
- 曼哈顿距离
主要有基于用户的协同过滤与基于物品的协同过滤。
矩阵分解模型
矩阵分解为两个低秩的矩阵的乘积,通过分解后的两矩阵内积,来填补缺失的数据。
优点:思路简单,可以方便完成预测;
缺点:很难增量训练(当样本激增时,可能要重新搭建矩阵),特征融合难;
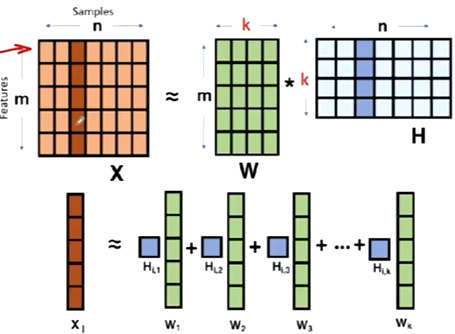
这里k是个隐因子,相当于是一个超参数。
逻辑回归模型
对预测用户是否会“点击商品”进行分类。转成一个分类模型。
ϕ ( x ) = w 0 + w 1 x 1 + ⋯ + w n x n = w 0 + ∑ i = 1 n w i x i ϕ(x)=w0+w1x1+⋯+wnxn=w0+n∑i=1wixi
ϕ(x)=w0+w1x1+⋯+wnxn=w0+i=1∑nwixi优点:模型简单,可解释性强,训练速度快(SGD梯度下降);
缺点:模型建模能力有限(没有考虑特征之间的相关性,以及特征之间的交叉),需要人工特征工程;
特征交叉模型
PLOY2
ϕ ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n w i j x i x j \phi(x) = w_{0}+\sum_{i = 1}^{n} w_{i} x_{i}+\sum_{i = 1}^{n-1} \sum_{j = i+1}^{n} w_{i j} x_{i} x_{j} ϕ(x)=w0+∑i=1nwixi+∑i=1n−1∑j=i+1nwijxixj
在逻辑回归基础上加入了暴力二阶特征交叉。
优点:加入二阶特征,建模能力增强;
缺点:时间复杂度高 n − − > n 2 n-->n^2 n−−>n2;
Factorization Machine
ϕ ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j \phi(x)=w_{0}+\sum_{i=1}^{n} w_{i} x_{i}+\sum_{i=1}^{n-1} \sum_{j=i+1}^{n}\left\langle v_{i}, v_{j}\right\rangle x_{i} x_{j} ϕ(x)=w0+∑i=1nwixi+∑i=1n−1∑j=i+1n⟨vi,vj⟩xixj
为每个特征加入隐含权重(两个向量之间的内积),作为特征交叉的权重。
优点∶相比于PLOY2降低了模型参数量( n 2 − − > n K n^2-->nK n2−−>nK),自动特征工程
缺点︰特征交叉度有限(二阶)
GBDT+LR
GBDT:作为特征编码器;主要用于输入数据的特征筛选以及特征编码,生成离散的特征向量
LR(逻辑回归)︰利用编码结果进行训练

优点︰灵活,适合新增特征(用树模型作特征组合)
缺点:树模型复杂度高
深度推荐模型
深度协同过滤(Neural CF )
将用户对物品的打分当做分类问题。
使用全连接层学习用户与物品的交互。
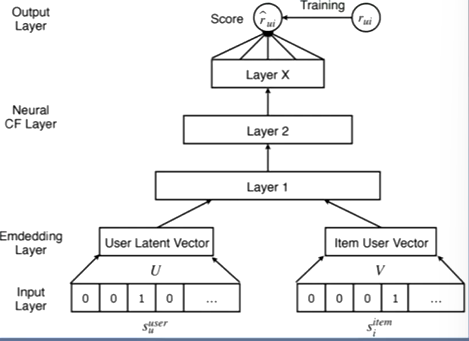
用多层的神经网络代替矩阵分解的操作
用全连接网络可能会比乘法更加高效一点。
Wide & Deep
基本淘汰
Wide为线性模型,Deep为深度模型
浅层模型(记忆能力)和深层模型模型(泛化能力),

Wide部分可以记住id,以此做一个建模。类似于LR。
Deep可以视为一个全连接网络,类似于NCF。
DeepFM
DeepFM包含FM和DNN两部分,两部分共享输入特征。使用FM替换wide & Deep中的wide部分。
DeepFM:一阶特征+二阶特征+深度特征
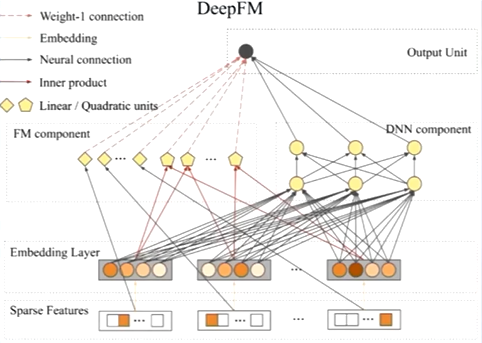
抛弃之前的单Wide部分,用FM代替,加强浅层特征的组合能力,用一阶和二阶替代。
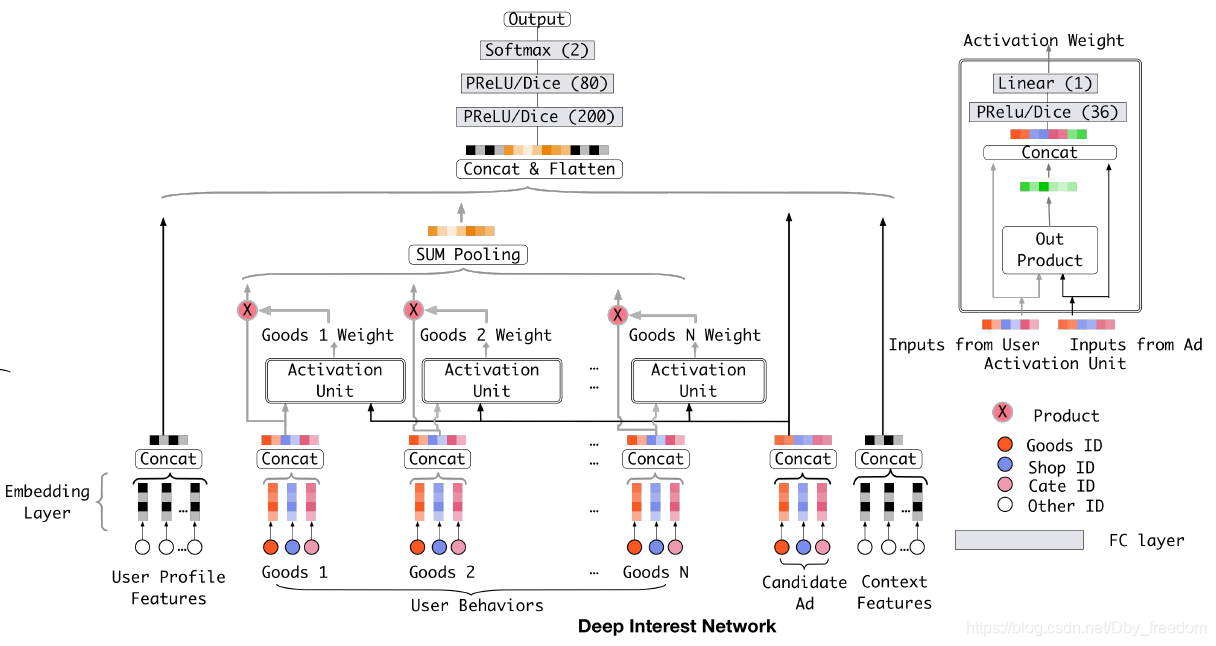
DIN
首个加入Attention机制
根据用户和物品调整权重
推荐系统框架&工具
DeepCTR
https://github.com/shenweichen/DeepCTR
https://github.com/shenweichen/DeepCTR-Torch
https://deepctr-torch.readthedocs.io/en/latest/Quick-Start.html
实现了经典的推荐算法模型,支持Keras和Pytroch。
对模型和输出处理封装的比较好,适合比赛用。xlearn
https://github.com/aksnzhy/xlearn
https://xlearn-doc-cn.readthedocs.io/en/latest/
LR、FM、FFM的高效实现,适合离线建模使用。
RecBole
伯乐,一个统一、全面、高效的推荐系统代码库
https://recbole.io/cn/
支持72个模型,28个数据集,适合学术用途

文本编码方法Text Encoding
-
Count:统计文本字符个数、单词个数
-
LabelEncoder:统一进行标签编
-
Multi One-Hot:进行多值标签编码(例如one-hot编码后相加)
AB : 011 BC : 110 AC : 101
One-Hot:eg:A: 0 0 1 B:010 C:100
-
CounterVector:与Multi One-Hot,但加入次数统计
-
TfidfVectorizer: 次数 和 词频统计
-
Word2Vec:词向量映射,然后聚合
-
相关阅读:
hutool工具类常用API整理
零难度!台式电脑如何连接蓝牙耳机?简单几步完成
达标进度条
HK WEB3 MONTH & Polkadot Hong Kong 火热报名中!
使用clip-path将 GIF 绘制成跳动的字母
区块链实训教程(1)--相关概念
4D 语义分割——SpSequenceNet
游戏电竞蓝牙耳机推荐
了解“预训练-微调”,看这一篇就够了
【MATLAB教程案例28】图像的边缘提取——canny、sobel、Laplacian以及图像亚像素级边缘提取
- 原文地址:https://blog.csdn.net/m0_52316372/article/details/126092633