-
指针进阶(三)之指针与数组笔试题
9.指针和数组笔试题解析
数组解析1
//一维数组 int a[] = {1,2,3,4}; printf("%d\n",sizeof(a)); printf("%d\n",sizeof(a+0)); printf("%d\n",sizeof(*a)); printf("%d\n",sizeof(a+1)); printf("%d\n",sizeof(a[1])); printf("%d\n",sizeof(&a)); printf("%d\n",sizeof(*&a)); printf("%d\n",sizeof(&a+1)); printf("%d\n",sizeof(&a[0])); printf("%d\n",sizeof(&a[0]+1));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果:

分析:
1.sizeof(数组名),数组名表示的整个数组,计算的是整个数组的大小,单位是字节
2.a没有单独放在sizeof内部,也没有取地址,所以a就是首元素的地址,a+0还是首元素的地址,地址的大小就是4/8个字节(a< = = >&a[0], a+0< ==>&a[0]+0)
3.这里的a就是首元素的地址,*a就是对首元素的地址解引用,找到首元素1,首元素的大小就是4个字节 ( *a<==> *&a[0])
4.这里的a就是首元素的地址,a+1就是第二个元素的地址,地址的大小就是4/8个字节
5.a[1]计算的是第二个元素的大小,4个字节
6.&a取出的是整个数组的地址,地址大小4/8个字节
7.&a拿到是数组的地址,类型是int (*)[4],为数组指针,数组指针解引用找到的是数组 ( *&a<==>a)
8.&a取出是整个数组的地址,&a+1是从数组a的地址向后跳过一个4个整形元素的数组的大小的地址
9.&a[0]取出的就是数组第一个元素的地址 (a<==>&a[0])
10.&a[0]+1是第二个元素的地址
数组解析2
//字符数组 char arr[] = {'a','b','c','d','e','f'}; //strlen是求字符串长度的,关注的是字符串中的\0,计算的是\0之前出现的字符个数 //strlen是库函数,只针对字符串 //sizeof只关注占用内存空间的大小,不在乎内存中存放的是什么 //sizeof是操作符 printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr+0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr+1)); printf("%d\n", sizeof(&arr[0]+1)); printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr+0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr+1)); printf("%d\n", strlen(&arr[0]+1));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果:

分析:
1.sizeof(数组名),同上
2.arr+0 是数组首元素的地址
3.*arr就是数组的首元素,大小一个字节 ( *arr --> arr[0] *(arr+0) --> arr[0])
4.arr[1]数组首元素大小,一个字节
5.&arr是数组的地址,地址4/8字节
6.&arr+1是数组后的地址
7.&arr[0]+1是第二个元素的地址
——————————————————
8.结果是随机值(大于等于6),strlen计算的是’\0’之前的元素个数,strlen函数会继续向下访问,直至遇到’\0’
9.arr+0还是arr的地址,同上
10.* arr是字符a,strlen函数的返回值类型是const char* string,'a’转化为ascll码值97,这个地址并未开辟,所以是野指针,程序报错
11.arr[1]是字符b,'b’转化为ascll码值98,地址是野指针
12.结果是随机值(大于等于6),&arr取出的是整个数组的地址,但是这个地址仍然是数组首元素的地址,所以和第8个结果一样
13.&arr+1跳过这个字符数组,是这个字符数组后的地址,所以结果是随机值-6
14.&arr[0]+1是这个数组第二个元素的地址,所以结果是随机值-1
数组解析3
char arr[] = "abcdef"; char arr[] = [a b c d e f \0] printf("%d\n", sizeof(arr)); printf("%d\n", sizeof(arr+0)); printf("%d\n", sizeof(*arr)); printf("%d\n", sizeof(arr[1])); printf("%d\n", sizeof(&arr)); printf("%d\n", sizeof(&arr+1)); printf("%d\n", sizeof(&arr[0]+1)); printf("%d\n", strlen(arr)); printf("%d\n", strlen(arr+0)); printf("%d\n", strlen(*arr)); printf("%d\n", strlen(arr[1])); printf("%d\n", strlen(&arr)); printf("%d\n", strlen(&arr+1)); printf("%d\n", strlen(&arr[0]+1));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果:

分析:
1.sizeof(数组名),注意常量字符串结尾默认有一个’\0’,被隐藏了,所以arr有7个元素
2.arr+0 是数组首元素的地址
3.*arr就是数组的首元素,大小一个字节 ( *arr --> arr[0] *(arr+0) --> arr[0])
4.arr[1]数组首元素大小,一个字节
5.&arr是数组的地址,地址4/8字节
6.&arr+1是数组后的地址
7.&arr[0]+1是第二个元素的地址
——————————————————
8.结果是6,字符串结尾默认存在’\0’
9.arr+0还是arr的地址,同上
10.&arr取出的是整个数组的地址,但是这个地址仍然是数组首元素arr的地址,所以和第8个结果一样
11.&arr+1跳过这个字符数组,是这个字符数组后的地址,strlen函数会继续向下访问,直至遇到’\0’, 所以结果是随机值
12.&arr[0]+1是这个数组第二个元素的地址,所以结果6-1=5
13.* arr是字符a,strlen函数的返回值类型是const char* string,'a’转化为ascll码值97,这个地址并未开辟,所以是野指针
14.arr[1]是字符b,'b’转化为ascll码值98,地址是野指针
指针解析1
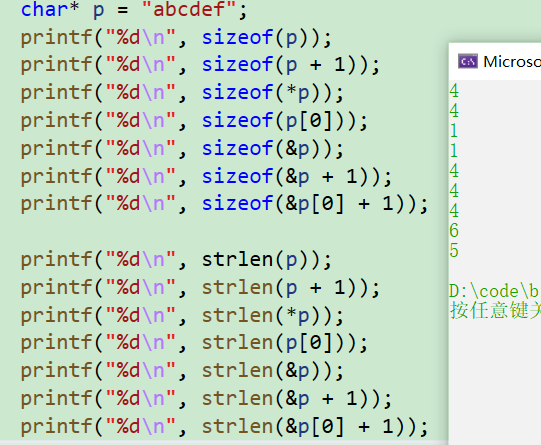
char *p = "abcdef"; printf("%d\n", sizeof(p)); printf("%d\n", sizeof(p+1)); printf("%d\n", sizeof(*p)); printf("%d\n", sizeof(p[0])); printf("%d\n", sizeof(&p)); printf("%d\n", sizeof(&p+1)); printf("%d\n", sizeof(&p[0]+1)); printf("%d\n", strlen(p)); printf("%d\n", strlen(p+1)); printf("%d\n", strlen(&p)); printf("%d\n", strlen(&p+1)); printf("%d\n", strlen(&p[0]+1)); printf("%d\n", strlen(*p)); printf("%d\n", strlen(p[0]));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果:
分析:
1.p是char* 类型的指针,p里面存放的是"abcdef"的首元素的地址,地址大小4/8个字节
2.p+1仍然是地址
3.p存放的是字符串首元素a的地址,*p找到a, a的大小是一个字节
4.p[0]<–>* (p+0)<–>*p ,同上
5.&p取出的是整个字符串的地址
6.&p+1是p跳过整个字符串后的地址
7.&p[0]+1是字符串中b的地址
——————————————————
8.p存放的是a的地址,从a到f六个元素,f后面隐藏了’\0’
9.p+1存放的是b的地址,结果为5
10.&p是指针变量p的地址,p的内存空间中存放的是字符串"abcdef",strlen函数会继续从p的地址向下访问,直至遇到’\0’,结果是随机值
11.&p+1是跳过字符串后的地址,结果是随机值,不同于10的随机值
12.&p[0]+1是字符串中b的地址,结果为5
13.*p等价于a,'a’的ascll码值为97,这个地址未开辟,是野指针
14.p[0]==a,同上
数组解析4
//二维数组 int a[3][4] = {0}; printf("%d\n",sizeof(a)); printf("%d\n",sizeof(a[0][0])); printf("%d\n",sizeof(a[0]));//a[i]表示第i+1行数组的数组名 printf("%d\n",sizeof(a[0]+1)); printf("%d\n",sizeof(*(a[0]+1))); printf("%d\n",sizeof(a+1)); printf("%d\n",sizeof(*(a+1))); printf("%d\n",sizeof(&a[0]+1)); printf("%d\n",sizeof(*(&a[0]+1))); printf("%d\n",sizeof(*a)); printf("%d\n",sizeof(a[3]));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果:

分析:
1.sizeof(数组名),a表示整个二维数组,结果就是3 *4 *4==48个字节
2.a[0] [0] 是第一行第一列的元素,类型为int ,结果4个字节
3.a[0]表示第一行这个一维数组的数组名,单独放在sizeof内部,sizeof(数组名),a[0]表示二维数组第一行的数组,结果4*4==16个字节
4.a[0]表示首元素的地址,就是第一行这个一维数组的第一个元素的地址,a[0]+1等价于&a[0] [0]+1,就是第一行第二个元素的地址
5.a[0]+1是第一行第二个元素的地址,*(a[0]+1)就是第一行第二个元素
6.a虽然是二维数组首元素的地址,二维数组的首元素是他的第一行,a就是第一行的地址,a+1就是跳过第一行,表示第二行的地址
7.*(a+1)是对第二行地址的解引用,拿到的是第二行, *(a+1)–>a[1]
8.&a[0]对第一行的数组名取地址,拿出的是第一行的地址,&a[0]+1得到的是第二行的地址
9.*(&a[0]+1)–> *(a+1)–>a[1], 拿到的是第二行
10.a是二维数组首元素的地址,也就是二位数组第一行的地址,*a拿到的是第一行
11.a[3]表示二维数组第4行的地址,我们知道sizeof只分析类型,就可算出他的字节大小,例如,sizeof(int)==4, int a = 10, sizeof(a)==4,这里sizeof(a)只是分析a的类型。a[3]虽然越界了,但是sizeof并不会实际访问a[3], 只是分析它的类型,计算他和[0]是一样的。
总结: 数组名的意义:
-
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
-
&数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
-
除此之外所有的数组名都表示首元素的地址。
10.指针笔试题
笔试题1
int main() { int a[5] = { 1, 2, 3, 4, 5 }; int *ptr = (int *)(&a + 1); printf( "%d,%d", *(a + 1), *(ptr - 1)); return 0; } //程序的结果是什么?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:&a取出的是整个数组的地址,&a的类型是int (*)[5],&a+1和&a的类型相同,&a+1取出的是跳过数组后的地址,将这个地址强制类型转化为int * 类型,然后把他赋值给int *类型的ptr, *ptr只能访问一个整型元素的空间。 *(a+1)中的a是数组首元素的地址,a+1是数组第二个元素的地址,ptr只有一个整型空间的访问权限,ptr-1得到数组最后一个元素的地址。

笔试题2
struct Test { int Num; char *pcName; short sDate; char cha[2]; short sBa[4]; }* p = (struct Test*)0x100000; //假设p 的值为0x100000。 如下表表达式的值分别为多少? //已知,结构体Test类型的变量大小是20个字节 int main() { printf("%p\n", p + 0x1); printf("%p\n", (unsigned long)p + 0x1); printf("%p\n", (unsigned int*)p + 0x1); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果:

分析:1. p的类型是struct Test*,p+1跳过一个结构体(20字节)空间的大小,20转化为16进制就14(0x100000+20==0x100014);
2. unsigned long 是无符号整形,p强制类型转化为unsigned long ,进行整形计算即可(0x100000+0x1==0x100001);
3. p强制类型转化为unsigned int *类型,此时p+1跳过4个字节大小(0x100000+4==0x1000004)。
笔试题3
int main() { int a[4] = { 1, 2, 3, 4 }; int *ptr1 = (int *)(&a + 1); int *ptr2 = (int *)((int)a + 1); printf( "%x,%x", ptr1[-1], *ptr2); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:&a取出的是整个数组的地址,&a的类型是int (*)[4],&a+1和&a的类型相同,&a+1取出的是跳过数组后的地址,将这个地址强制类型转化为int * 类型,然后把他赋值给int *类型的ptr, ptr只能访问一个整型元素的空间。a是数组首元素的地址,对a强转为int的整数,然后对a加1,在把a强转为int * 的地址,结果就是ptr2向后移动一个字节。ptr1[-1]==(ptr1-1),ptr1的类型为int *,加1跳过一个整形的大小。ptr2指向a[0]的第二个字节处,解引用向后访问一个整形的大小。“%x”是以十六进制的形式打印,且VS是小端存储,所以结果是0x 00 00 00 04,0x 02 00 00 00。前面的0省略不要。

笔试题4
int main() { int a[3][2] = { (0, 1), (2, 3), (4, 5) };//挖坑:逗号表达式 int *p; p = a[0]; printf( "%d", p[0]); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:这里最大的坑就是逗号表达式,a[0] 是a[0]首元素的地址,p[0]等价于*p, *p等于1。

笔试题5
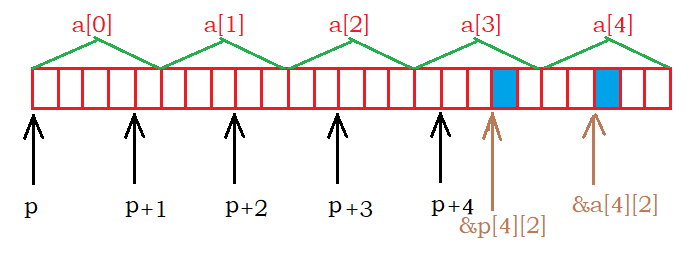
int main() { int a[5][5]; int(*p)[4]; p = a; printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:a表示首元素的地址,即a的第一行(一维数组)的地址。a的类型是int( * )[5],p的类型是int(*)[4],把a的地址赋值给p,两者类型不同,但是也能强行赋值。p和a都指向数组第一行第一个元素的地址。&a[4] [2]很好找,就是二维数组第5行第3列的地址。 p[4] [2]可以转化为 *( *(p+4)+2),因为p的类型于a的不同,所以p+4跳过16个字节。 *(p+4)就是p+4地址往后的4块空间, *( *(p+4)+2)就是这4块空间中的第二块空间的值,&[4] [2]就是取出这块空间的地址。不好意思,忘记调了,VS是X64平台,多了8个F,在X86平台下是如下结果。

笔试题6
int main() { int a[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; int *ptr1 = (int *)(&a + 1); int *ptr2 = (int *)(*(a + 1)); printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1)); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:&a+1取出的是跳过整个二维数组后的地址,a+1是第二行首元素的地址。

笔试题7
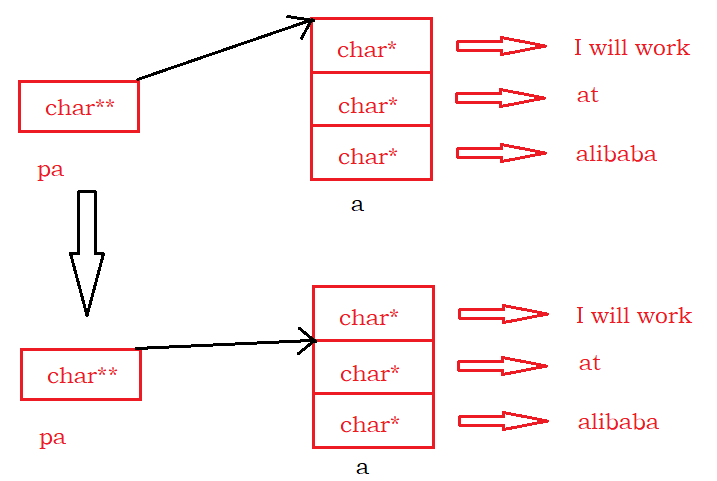
int main() { char *a[] = {"work","at","alibaba"}; char**pa = a; pa++; printf("%s\n", *pa); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
结果:

分析:a是一个指针数组,它里面的每个元素类型都是char*。我们把每个字符串的首地址放到数组里面。类比char *p = “abcdef”;
把a的首元素地址放到pa里面。pa++后,pa指向数组的第二个地址。pa的类型char**的理解:第二个 *告诉我们pa是指针,char *
告诉我们pa指向的元素类型为char*。
笔试题8之压轴重头戏
int main() { char *c[] = {"ENTER","NEW","POINT","FIRST"}; char**cp[] = {c+3,c+2,c+1,c}; char***cpp = cp; printf("%s\n", **++cpp); printf("%s\n", *--*++cpp+3); printf("%s\n", *cpp[-2]+3); printf("%s\n", cpp[-1][-1]+1); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果:

这里有些问题要注意:
-
++cpp,会将cpp自身的值改变;而cpp+1不会改变cpp本身;注意不要混淆。
-
关于这些运算符的优先级:()>++>–>+
-
为了便于计算和理解,尽量把cpp[]操作改成*(cpp)
原始的内存分析图:
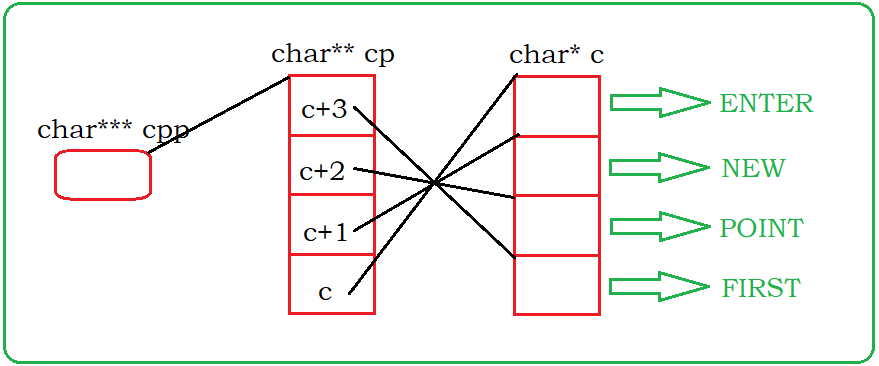
分析情况1:++cpp,cpp指向cp的第二块空间的地址,*cpp得到了地址c+2,地址c+2指向c的第三块空间,再 *cpp找到了这块空间中的字符串的首地址。

分析情况2:注意情况1已经改变了cpp的指向,这里再++cpp,cpp此时指向cp的第三块空间的地址,*cpp得到地址c+1,再进行前置–操作,地址变成了c,地址c指向c的第一块空间的地址,再进行解引用就得到了字符串’ENTER’的首字符的地址,最后+3,得到了E的地址。
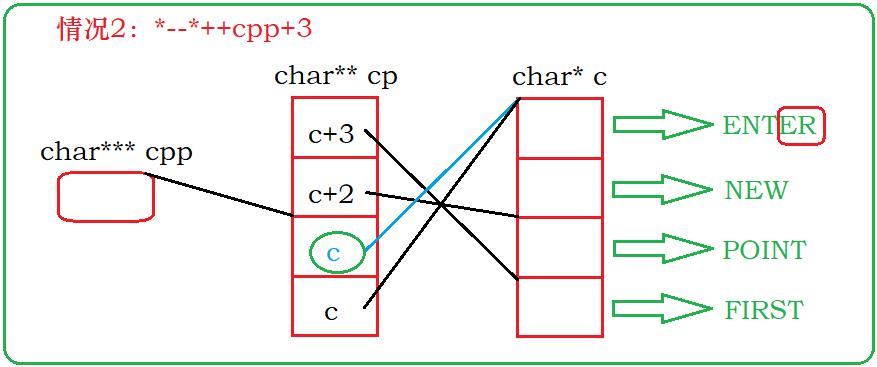
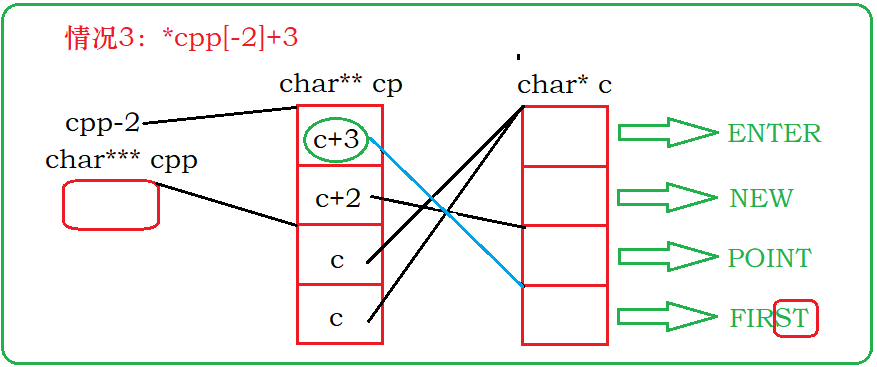
分析情况3:这里的cpp-2并没有改变cpp,cpp[-2]等价于*(cpp-2)。cpp-2指向cp的第一块空间的的地址, *(cpp-2)得到了地址c+3,*cpp[-2]得到了c的第四块空间的值,字符串’FIRST’的首地址,+3得到了S的地址。
分析情况4:cpp[-1] [-1]等价于* ( * (cpp-1)-1),cpp-1指向cp的第二块空间的地址,解引用得到c+2的地址,再-1得到c+1的地址,再次解引用得到字符串’NEW’的首地址,+1跳过一个字节,得到E的地址。

-
相关阅读:
信号和电源隔离的有效设计技术
SpringBoot-02-springBoot介绍及程序创建
webSocket 有哪些安全问题?
Kafka的docker安装
python进阶练习
云原生中间件 -- MongoDB Operator 篇
计算机毕业设计Javaweb家庭财务管理系统(源码+系统+mysql数据库+lw文档)
如何将枯燥的大数据进行可视化处理?
分布式消息队列RocketMQ介绍
Java集合-HashMap源码分析
- 原文地址:https://blog.csdn.net/m0_64224788/article/details/126092708
