-
计算机体系结构第四章实验——cache模拟器实验
本次实验的主要目的是熟悉cache的原理。加深对cache的映像规则、替换方法、cache命中与缺失的理解。通过实验对比分析映像规则对cache性能的影响。
实验内容一:熟悉模拟程序
阅读给出的cache模拟程序(cachesimulator.cpp),理解其中的主要参数与功能。修改代码,随机生成N个访存地址,运行程序观察并分析结果(例如,可分析其中命中次数,不命中次数,替换次数)。熟悉cache系统的执行过程(可举例详细分析一次命中/不命中/替换过程)。
实验完成情况:
首先,在课程平台下载模拟程序,并阅读之后打开程序进行编译,一开始直接编译存在的问题有以下几点:
1.程序是void main,在VS和Dev-C++中,都不能直接进行编译,需要修改为int类型的主函数。
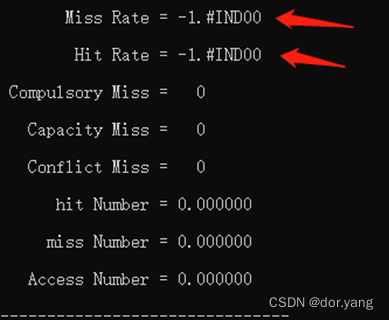
2.在程序中,用户查找内存时候的信息(每次找的块号)是在这个程序的目录上一级中的一个叫project的文件里的,因为相对路径是“…/project.txt”。但是这里是没有的,所以会出现的一个情况就是在完成了对于cache的一些参数的定义之后,发现下图中箭头所示的情况,就是因为无法进行该计算(除数为0)。
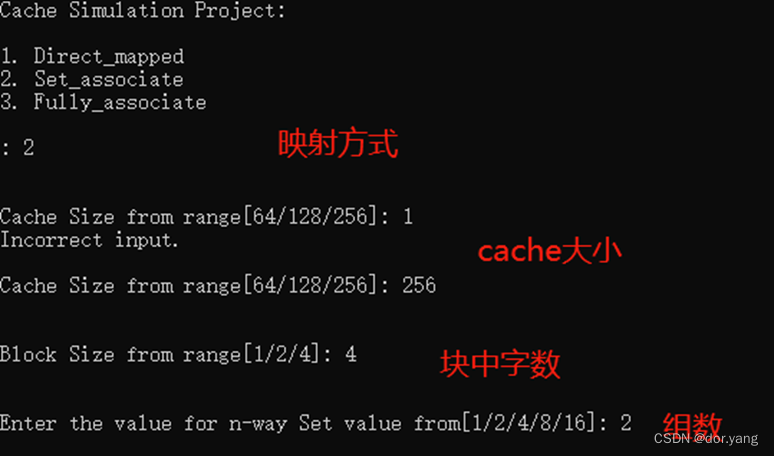
接下来,将程序简单调整之后,执行程序,并且开始理解程序中的一些主要参数含义如下:
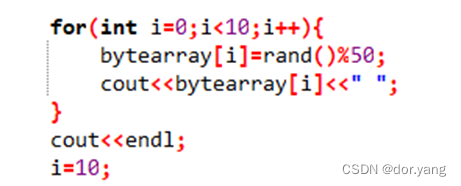
这里对于函数进行了修改,因为在原代码中的project文件读取也只是获得用户访问内存的块号,所以结合题目要求,直接对存储相关信息的数组bytearray进行随机数的赋值,并且进行输出,另外注释掉了读取文件的部分,其中,块数N=10和取随机数后的求余运算都是可以进行替换的,这里对随机数进行求余运算,主要是怕产生的随机数偏差过于大,导致不好找到命中的情况,这里只是一个例子,主要是为了取一些小数据,后面便于分析:
并且,将每次地址对应的子地址,块地址,index和tag输出出来,也是便于后面分析:

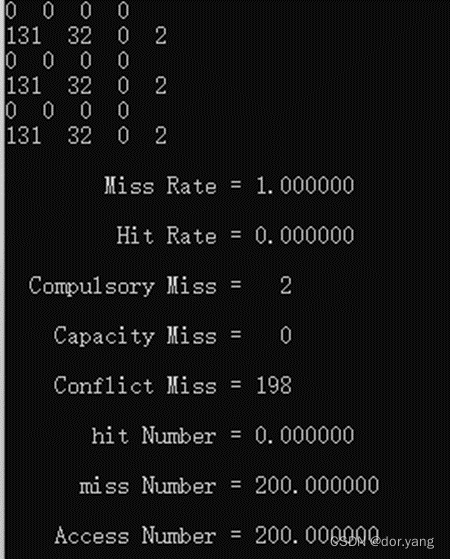
采用了cache大小为64块,每块大小为一个字的直接映像(因为是直接映像,所以不用理会组数,合法即可)运行程序之后的结果如下图所示:
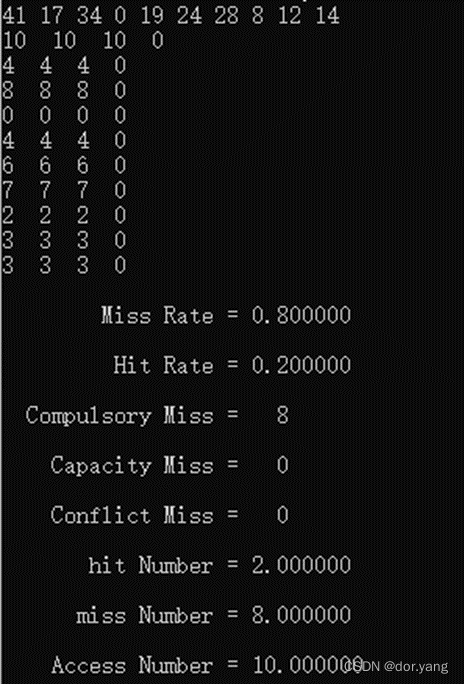
对程序结果进行分析,本次的结果总计发生了两次命中和八次miss,其中八次miss全是第一次用到cache对应位置的强制失效。从输出的index(第三列)中可以看出,命中的分别是第五次和第十次,因为在第二次和第九次访问内存的时候,4号字和3号字就因为17号字节和12号字节的访问miss,调用了替换功能(虽然第一次没有从cache中换出去东西)。所以后续访问中index和tag位都对上了,得到的结果就是命中了。此时cache中对应的2,3,4,6,7,8,10号块都已经有对应tag位=0的字存在这里了。至于替换次数,一般就是miss的次数。
基于上面的执行结果,分析一下cache系统的执行过程:
不命中的情况:第一种是valid位为0,如果查看到这类情况,可以直接判断为是未命中,将对应cache表中位置的valid位置1,然后将块内容填入cache表即可,在上述的执行过程中,miss的情况都是这类。
实际上不命中的情况还有一种就是cache表的index对上了,tag位没有对上,但是要满足这个需求需要把指令访存块号增大,增加访存次数才比较容易出现,在实现后面的实验要求的时候,我发现了stride=131的情况就是此类,所以直接拿来使用了,这里可以看到输出出来的分别是字地址,块地址,index,tag,而131和0的index位是一致的,不过tag位不一样,所以也是不命中:
命中的情况:首先计算好index,查看cache表中的对应的位置,先查看valid位,再查看tag位,都对上了,就说明命中,在上述的执行过程中,第五次和第十次的查询都命中了。
替换的过程:在miss的情况下,需要对cache块进行调整,将访问的内容放到cache表中,这样做的原理是程序的空间局限性,访问过的内存有较大的概率在未来再次被访问,可以有效提高访存的效率,不过这里一是因为访存次数有限,二是因为随机访存,所以cache的优点没有体现出来。
这里程序模拟结果中发生了两次命中和八次miss,但是这里的miss全是因为cache初始化,没有内容带来的强制失效,结合cache的具体空间相对于10次访存较大,同时访问的字节号进行求余运算之后,虽然方便,但是tag位可以看到都是0,所以可以考虑放宽访问字节号,增加访问次数,进行如下修改。可以看到,在访存次数足够大并且访存块数足够多的情况下,cache的命中数:

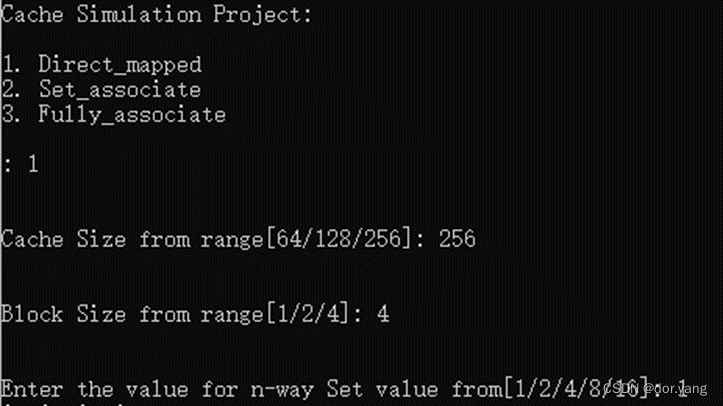
实验内容二:利用该模拟程序仿真课后习题4.1,并得出结果。
习题4.1:The following C program is run (with no optimizations) on a machine with a cache that has four-word (16-byte) blocks and holds 256 bytes of data:
inti, j, c, stride, array[256]; for (i=0;i<10000;i++) for (j=0;j<256;j=j+stride) c = array[j]+5;- 1
- 2
- 3
- 4
If we consider only the cache activity generated by references to the array and we assume that integers are words.
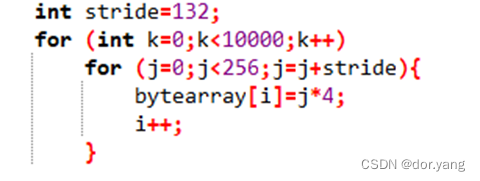
1) What is the expected miss rate when the cache is direct-mapped and stride=132? How about if stride=131?
预期的miss率为:2/(2*10000)=0.0001,在第一次执行j循环的时候,cache为空,发生了j=0和j=132两次强制失效,此时cache中会存有array数组中0,1,2,3;132,133,134,135这两组八个数据。后续的话都是命中的。
可以用表格进行一下当前cache的情况的说明:
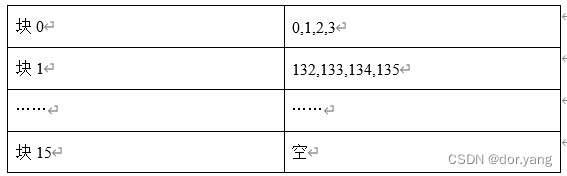
因为这两个块之间没有竞争关系,所以后续循环里面是不会发生冲突的,都会命中,只有一开始的两个是强制失效。
使用软件的执行结果来验证预测:
在执行程序的时候发现问题:存储访存块号,块地址等数据的数组容量为500,无法实现上述程序段中访问20000次的需求,所以对程序中数组的大小进行了扩充:

接下来,将循环中的访存信息存进对应的数组(因为数组的单位是字,所以这里要*4转换成对应的字节地址)
最后查看程序运行的结果:

和预期结果一致。
将stride修改为131页情况可就不一样了,因为当j=131的时候,他所对应的cache块在发生miss之后,会将128,129,130,131这四个字的内容一起读进cache里面,如果用表格来进行表示的话,那么此时的cache的情况应该是:
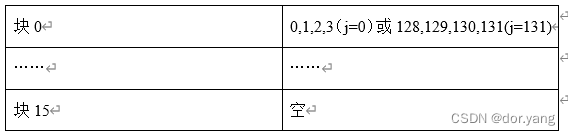
所以这个时候,进行循环,除开第一次属于强制失效之外,后续也会因为不断的在两个块的内容之间反复替换,导致在整个循环的过程中一直是miss的状态。缺失率为100%。
同样执行程序,查看预测结果的正确性:
修改stride=131。
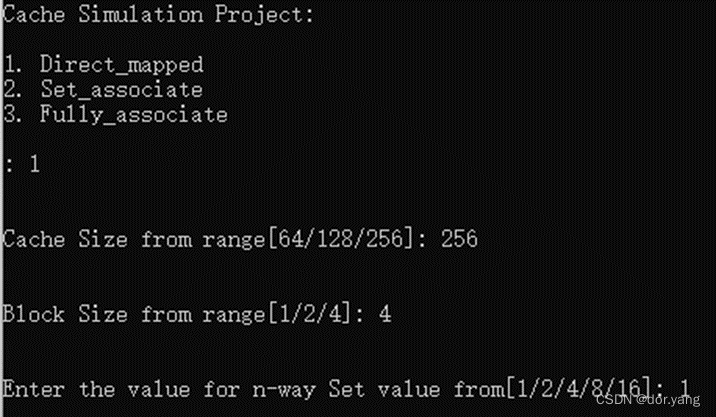
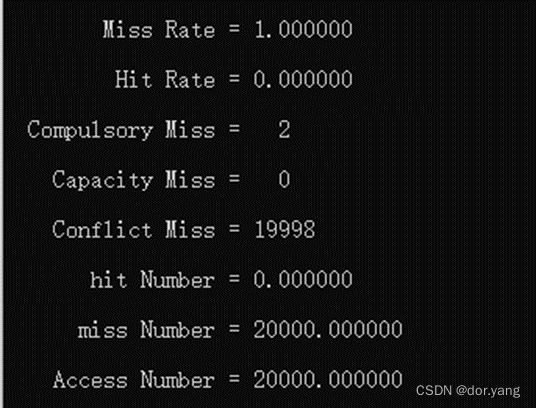
Miss率为100%,和我们的预期结果相一致。
2) Would either of these changes if the cache were two-way set associative?
使用组相联映射不会改变stride=132的结果,也是两次强制失效,因为在j循环里面仅两次执行,虽然访问的0和132对应的块是一组的,但是因为一组有两块,彼此之间也不会有什么影响和冲突。不会影响最后的结果。
执行程序查看结果:
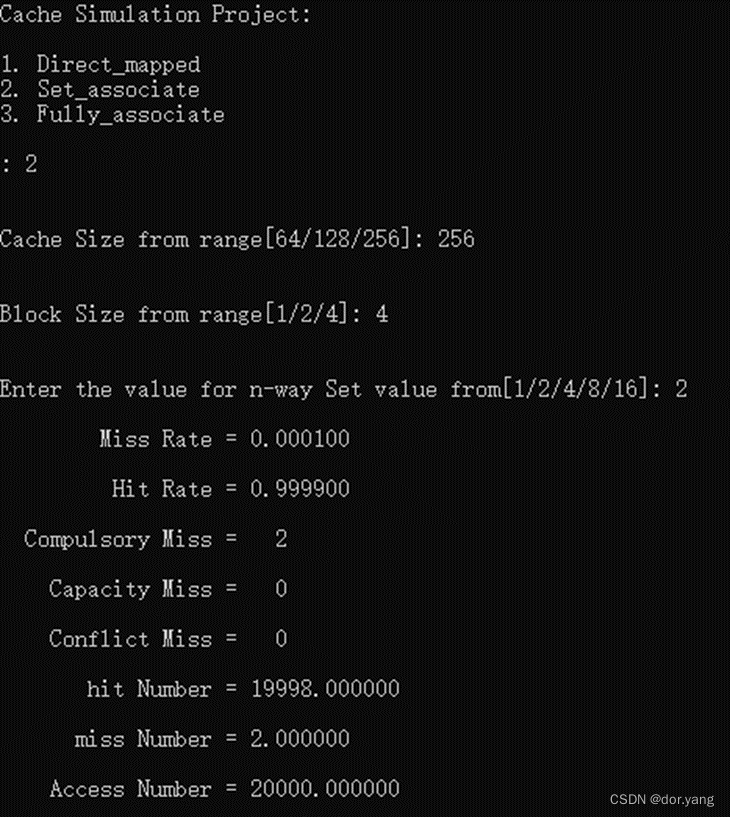
和预期结果一致。
但是使用组相联映射会改变stride=131的结果,因为在上一阶段中,发生100% 的miss率的主要原因还是在于两个块之间存在竞争关系,他们在cache中只有一个对应块,这就导致后面每次访问miss之后,都要将cache中的块替换掉。而使用了组相联映射之后,两个快对应一个组,而一组两块,就很好的解决了这个问题,除开两次强制失效之外,都会命中。所以对应的命中率的预测为:2/20000=0.0001
此时的cache情况可以表示为:
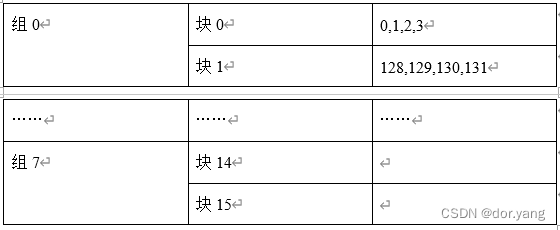
执行程序查看结果:
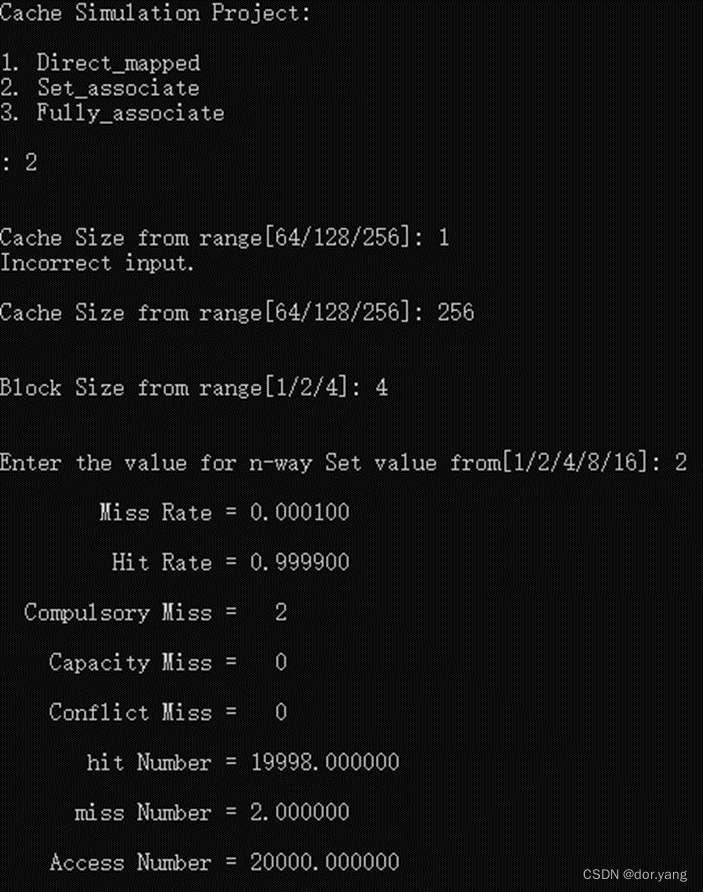
和预期计算结果相一致。
(理论分析该试题,得出上述两问的结果。利用cache模拟程序仿真该程序的cache执行过程,核实实验结果是否与理论分析计算结果一致。)3) 对于每个miss,标注是哪种miss(compulsory,conflict,capacity)。(该内容目前课上还没讲到,有能力的同学可自学后完成。或者等到上课讲完该知识点后再完成。)
Miss标注:
在第一问的直接映像中,stride=132的情况下,总共有两次miss,都是强制缺失,因为那是第一次访存,是一定找不到的。在stride=131的情况下,总共有20000次miss,其中,前两次和上面的情况一样,也是强制缺失,而之后的19998次,则是冲突失效,是因为两个块竞争同一个cache的位置,彼此替换竞争导致的miss。这里我一开始是有一个疑问的,就是因为j=0,131两个情况下,对应的是一个cache块,一开始cache为空的时候应该只有一次,为什么会有两次强制缺失。在上网查询之后了解到,强制缺失指的是对一个地址的第一次访问。所以这里应该该是2次。
在第二问的组相联中, stride=132,131所对应的情况都是,只有两次miss,是强制缺失。
-
相关阅读:
(二)什么是Vite——Vite 和 Webpack 区别(冷启动)
excel表导出
【Kafka】Java整合Kafka
C语言第十二课(中):操作符详解【单目、关系、逻辑、条件操作符】
iOS查看汇编代码
JVM(2)
css实现动画效果 animation: showLayer 0.2s linear both
力扣刷题 数据结构与算法(十)
新手怎么做短剧推广和小说推文 授权渠道
左旋氧氟沙星/载纳米雄黄磁性/As2O3磁性Fe3O4/三氧化二砷白蛋白纳米球
- 原文地址:https://blog.csdn.net/weixin_51529433/article/details/126091615