-
研究性学习专题 3_LL(1)语法分析设计原理与实现
1.实验内容
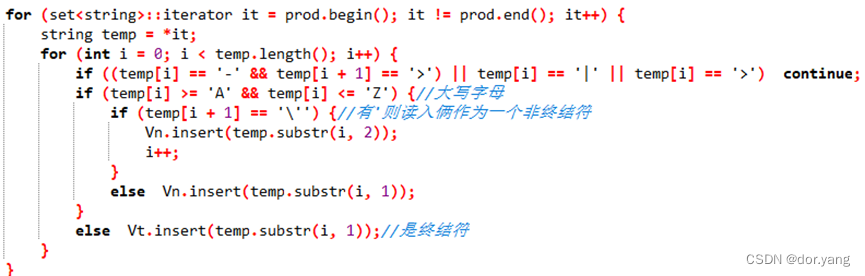
实现 LL(1)分析中控制程序(表驱动程序);完成以下描述赋值语句的 LL(1)文法的 LL(1)分析过程。重点 LL(1)分析方法和 LL(1)分析器的实现。G[S]:
S→ V=E
E→ TE’
E’→ ATE’ | e
T→ FT’
T’→ MFT’ | E
F→ (E) | i
A→ + | -
M→ * | /
V→ i
设计说明:终结符号 i 为用户定义的简单变量,即标识符的定义。2 实验要求
(1)输入串应是词法分析的输出二元式序列,即某算术表达式“专题 1”的输出结果,输出为输入串是否为该文法定义的算术表达式的判断结果;
(2)LL(1)分析过程应能发现输入串出错;
(3)设计两个测试用例(尽可能完备,正确和出错),并给出测试结果;(4)考虑根据 LL(1)文法编写程序构造 LL(1)分析表,并添加到你的 LL(1)分析程序中。3 实验环境
编译环境:Dev-C++
运行环境:win114.实验功能设计
4.1 根据读取的文法文件,拆分产生式并判断输出终结符号和非终结符号:

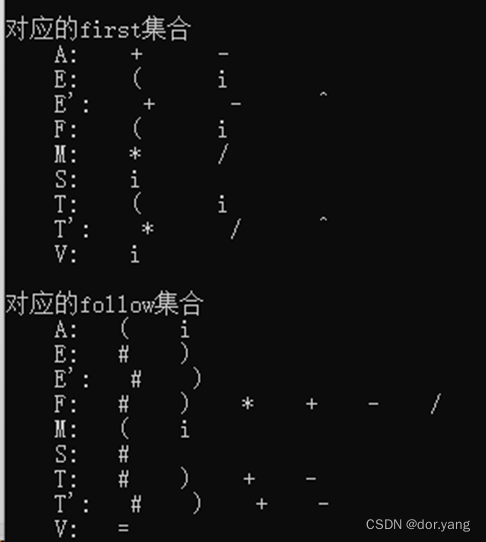
4.2 根据读取的文法,获取非终结符号的first集合和follow集合(注:为了便于读取和判断,空符号用^符号代替了):
4.3 根据计算完成的first集合和follow集合,结合产生式,输出分析表:

4.4 读取程序一输出出来的二元式文件,获取要输入Lab3的表达式:

4.5 在二元式文件的读取过程中,将读取到的标识符变量用i代替:
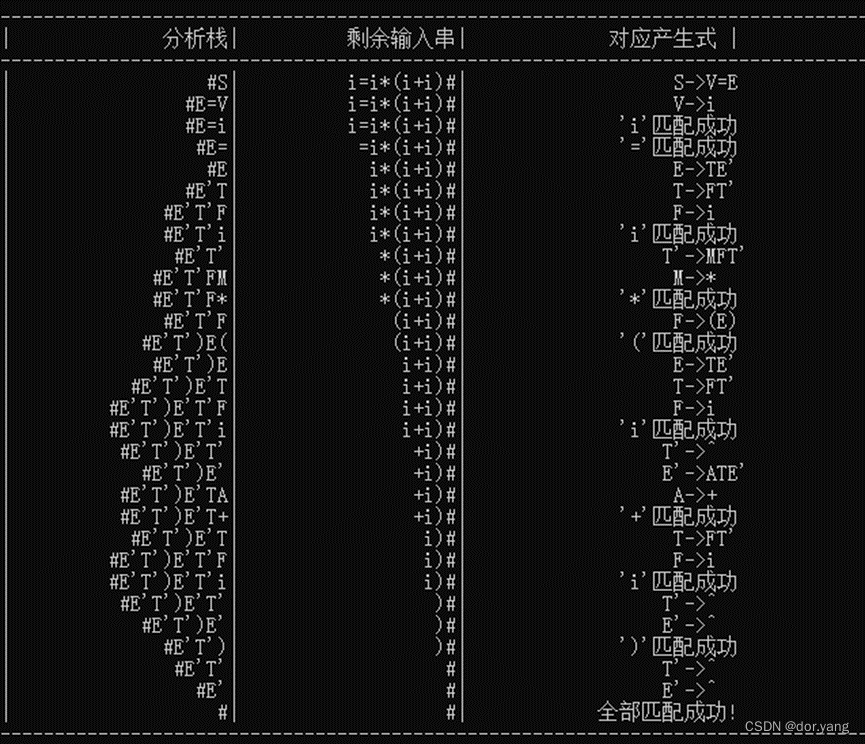
4.6 最后,对表达式进行LL(1)分析:
5. 程序结构
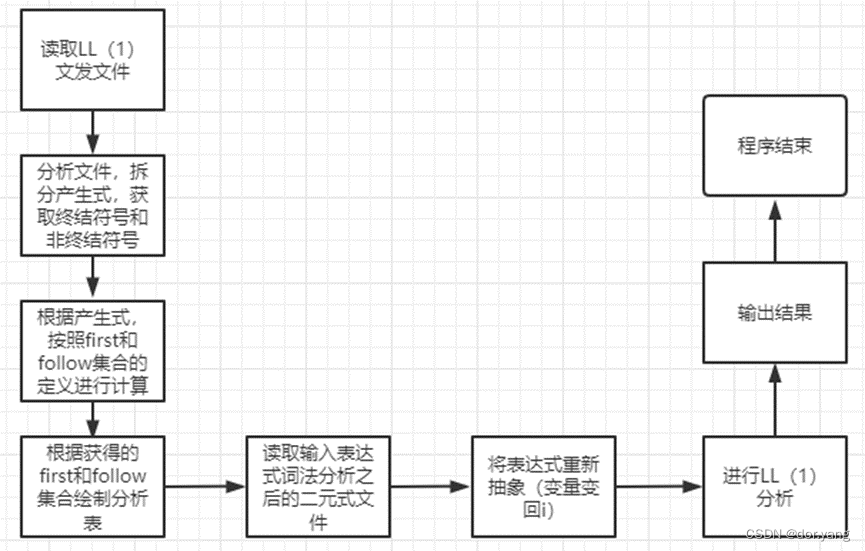
5.1总的程序结构流程图:
5.2 LL(1)文法文件的读取和拆解
主要就是用到了string中的find和substr函数功能,在切分字符串上很好用

5.3 first集合的计算
计算原理如下:
- 如果X是一个终结符号,那么FIRST(X) = X。
- 如果X是一个非终结符号,且X -> Y1Y2 …Yk是一个产生式,其中k ≥ 1,那么如果对于某个i , a 在FIRST(Yi)中且ε在所有的FIRST(Y1)、FIRST(Y2)、….、FIRST(Yi-1)中,就把a加入到FIRST(X)中。也就是说,Y1…Yi-1 =>* ε。如果多于所有的j = 1,2,3,…,k , ε在FIRST(Yj)中,那么将 ε 加入到FIRST(X)中。比如,FIRST(Y1)中的所有符号一定在FIRST(X)中。如果Y1 不能推导出 ε ,那么,我们就不会再向FIRST(X)中加入任何符号,但是如果Y1 =>* ε ,那么我们就加上FIRST(Y2),以此类推。
- 如果X -> ε 是一个产生式,那么将ε 加入到FIRST(X)中。

5.4 follow集合的计算
计算原理如下:
- 将 # 放到FOLLOW(S)中,其中S是开始符号,而 $ 是输入右端的结束标记。
- 如果存在一个产生式 A -> αBβ , 那么FIRST(β)中除 ε之外的所有符号都在FOLLOW(B)中。
- 如果存在一个产生式A -> αB,或存在产生式 A -> αBβ 且 FIRST(β)包含 ε ,那么FOLLOW(A)中的所有符号都在FOLLOW(B)中。

5.5 LL(1)分析表的构造
设计原理如下:
给定文法 G,对于产生式 A→α,α ∈ V*,则可选集 SELECT(A→α) 有:
(1) 若 α ≠ ε,且 α ≠+> ε,则 SELECT(A→α) = FIRST(α)
(2) 若 α ≠ ε,但 α =+> ε,则 SELECT(A→α) = FIRST(α) ∪ FOLLOW(A)
(3) 若 α = ε,则 SELECT(A→α) = FOLLOW(A)
对文法 G 的每个产生式 A->α 执行以下步骤:
(1) 若 a∈SELECT (A->α), 则把 A->α 加至 M[A,a] 中;
(2) 把所有无定义的 M[A,a] 标上“出错标志”。

5.6 对表达式进行LL(1)分析
设计原理如下:
控制程序在任何时候都是按分析栈栈顶符号 X 和当前的输入符号 a 行事的。对于任何(X,a),总控程序每次都执行下述三个动作之一:
i. 若 X=a=‘ # ’,则分析成功。
ii. 若 X=a≠‘ # ’,则把 X 从栈顶弹出,让 a 指向下一个输入符号。
iii. 若 X 为一非终结符,则查分析 表M。若 M[X,a] 中为A—产生式,将 A 自栈顶弹出,将产生式右部符号串按逆序逐一推入栈中;当产生式为 A 时,则只将 A→ε弹出即可。若 M[X,a] 中为空,则调用出错处理程序。
因为程序段相对较大,不进行截图。6. 程序测试
这里也是按照要求,设计了两个测试样例,一个正确一个错误。
首先是LL(1)文法,这点因为是已经给定了的,所以不会变:

因为文法是可以确定的,所以不论正确样例还是错误样例,程序的前半部分的输出都应该是对于给定文法的Vt,Vn,first集合和follow集合的计算结果:

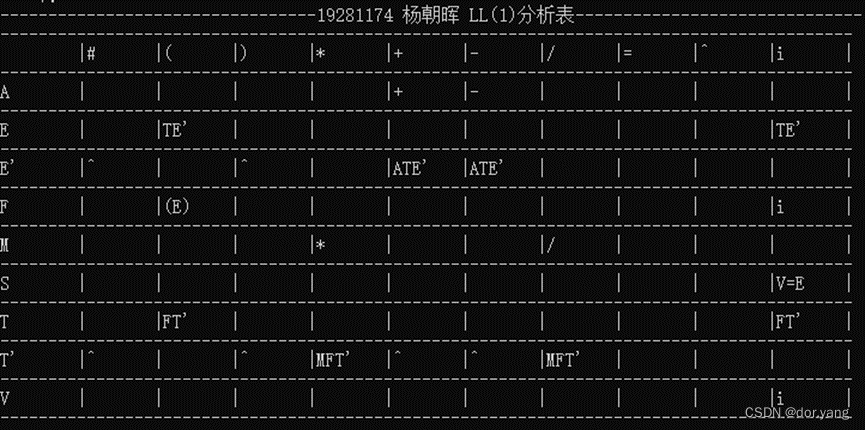
以及结合文法绘制的LL(1)分析表:
接下来是正确的文法的输入表达式,和Lab2的一样,这里为了在判定标识符的时候的方便,所以对Lab1的程序输出进行了一下小的修改,将标识符修改成了1,其余输出不变,也是为了方便之后的使用和修改:

因为在前面介绍程序功能的部分的时候已经分开细致进行了说明,所以在这里直接放程序的执行结果:

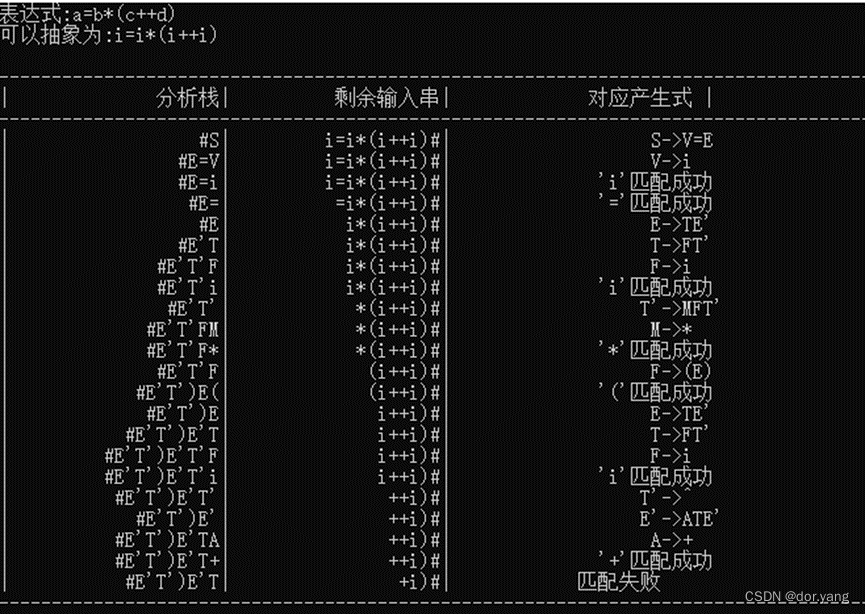
然后是错误样例,这次相比于上次做了一个小的调整,将输入的表达式修改为了a=b*(c++d):

7.实验总结
通过本次实验我对LL(1)预测分析有了深刻的领悟。在编程过程中,对文法的分析是最关键的。在网络上学习相关的代码思路的时候也收获了很多,并且因为读取的是文件,所以对于文件的切分也掌握的更加娴熟,本次实验实在实验一的分析结果上继续进行分析,我对实验一的程序进行了一定的修改和更正,比如一开始为了便于查看,输出的词法分析类别都是使用的中文,但是这样会导致程序很难判别,所以就对一些类别输出进行了调整与修改,使得两次实验可以尽量衔接。能够感受到实验之间的联系,期待最后整合为一个小型编译器。当然,我的代码还有一些不成熟的地方,在接下来的实验中,我会努力提高自己的实践能力
-
相关阅读:
学俄语来柯桥泓畅,与金钱——деньги有关的谚语/口语表达你都了解多少呢?
C Primer Plus(6) 中文版 第9章 函数 9.1 复习函数
Short read or OOM loading DB. Unrecoverable error, aborting now
高品质建筑红模板与耐久黑色覆膜清水模板:建筑质量的双重守护者
想要精通算法和SQL的成长之路 - 可以攻击国王的皇后
立体视觉四十二章经第01章:世界坐标系及不同坐标系的转换
Web上的推箱子游戏Sokoban
[题] 改革春风吹满地 #图论 #多边形面积
Java并发编程之ReentrantLock重入锁原理解析
Golang 变量作用域陷阱 误用短声明导致变量覆盖
- 原文地址:https://blog.csdn.net/weixin_51529433/article/details/126091315