-
ElasticSearch浅谈
了解ELK
ELK是ElasticSearch、Logstash 、 Kibana三大开源框架首字母大写简称。
了解ElasticSearch
ElasticSearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
下载安装
下载elasticsearch-7.6.1
下载elasticsearch-head-master
启动elasticsearch.bat启动可能会报错 , 报错需要在elasticsearch-7.6.1\config\elasticsearch.yml这个文件中配置
xpack.ml.enabled: false
通过head连接elasticSarch会报错跨域
跨域解决 , 在elasticsearch-7.6.1\config\elasticsearch.yml配置文件中配置http.cors.enabled: true http.cors.allow-origin: "*"- 1
- 2
了解Kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibnan,可以通过各种图表进行高级数据分析展示。
安装Kibana
下载后解压就可以
解压后运行bin目录下面的 .bat文件
浏览器访问即可打开是英文界面 , 这时我们就需要汉化 , 那么怎么汉化呢
在kibana-7.6.1-windows-x86_64\config目录下的kibana.yml配置文件最后加上下面的那行代码
i18n.locale: "zh-CN"- 1
ES的核心概念
- ElasticSearch是面向文档的
- ElasticSearch的几个概念
- 索引: 相当于关系型数据库的数据库
- types: 相当于关系型数据库的表 , 被遗弃了
- 文档:相当于关系型数据库的行
- 字段: 相当于关系型数据库的列
ElasticSearch在后台把每个索引划分成多个分片 , 每个分片可以在集群中的不同服务器间迁移
一个也是集群 , 默认集群名称就是ElasticSearch
Ik分词器
- 下载:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.3.2
- 解压到elasticsearch-7.6.1\plugins这个目录下
- 重启ElasticSearch
- 可以通过 命令
elasticsearch-plugin list来查看插件是否安装成功 - 使用Kibana调试
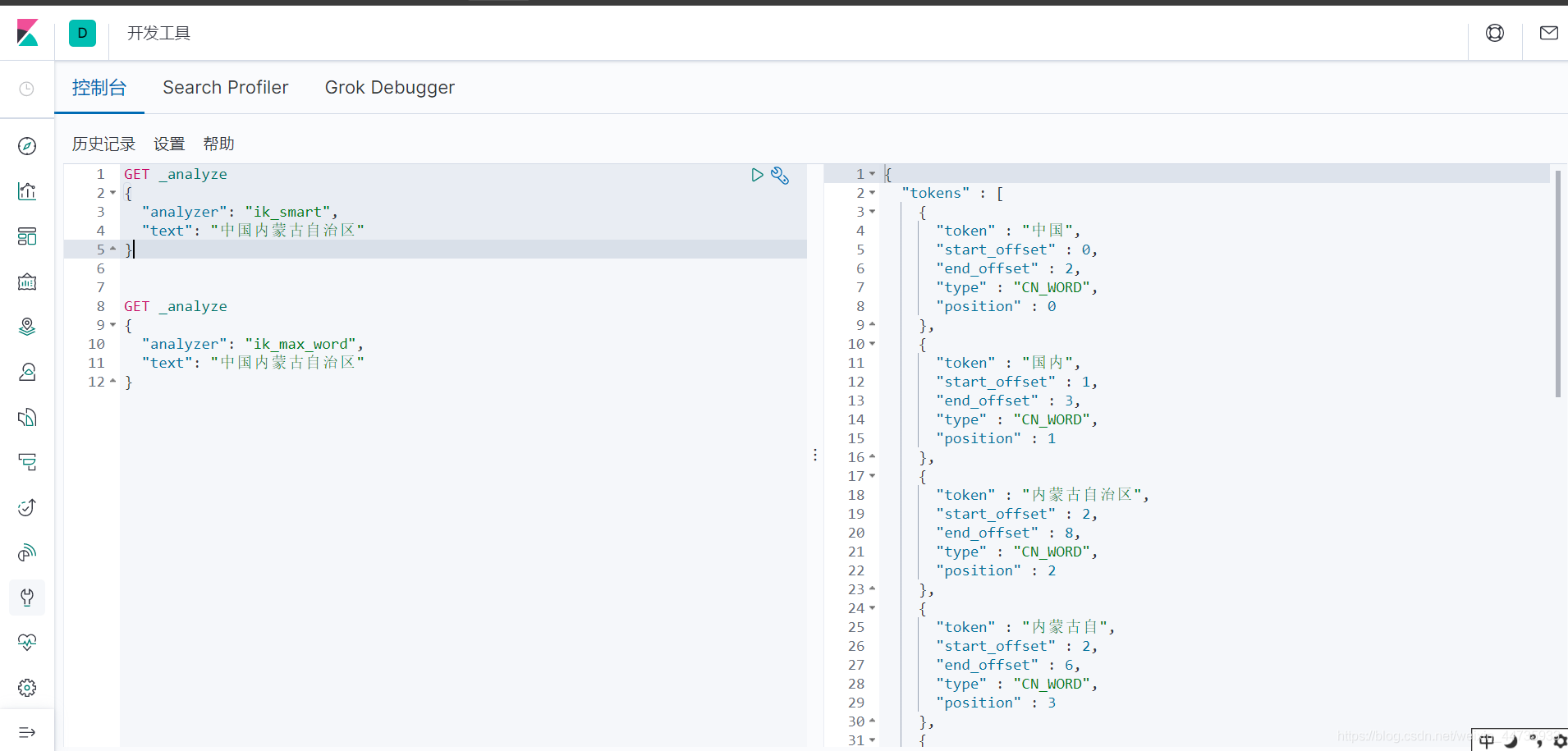
IK分词器提供了两个分词算法:ik_smart 和 ik_max_word
其中的ik_smart为最少切分 , ik_max_word为最细粒度划分
使用Kinban测试
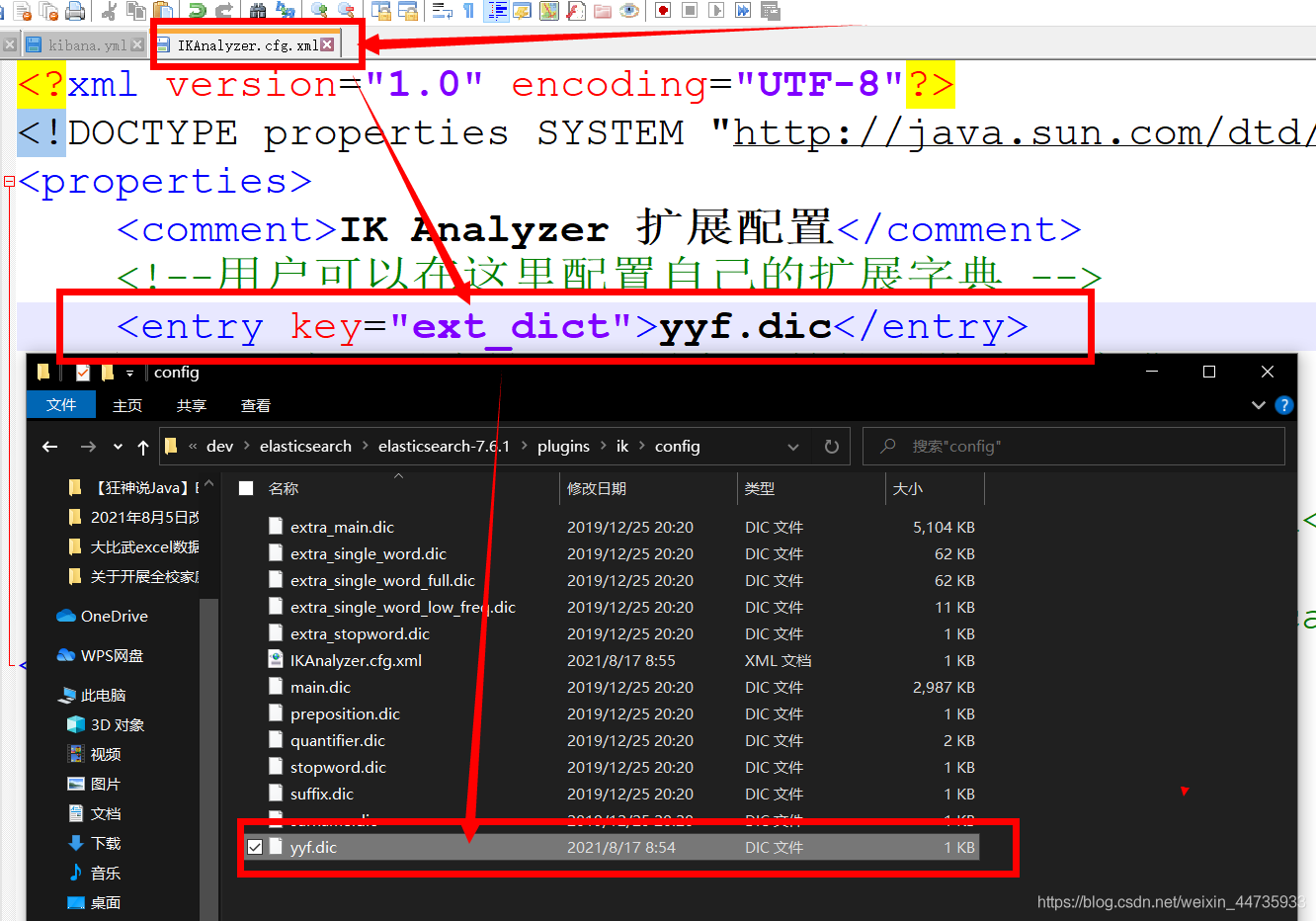
默认分词器中的分词效果不够 , 像姚云峰这样的词实际上是一个词 , 但是分词器却没能识别 , 把姚云峰三个字也全部都分开了 , 这样情况下我们该怎么办?Ik分词器增加自己的配置
关于索引的操作
创建索引
PUT /索引名/类型名/文档id
{请球体}
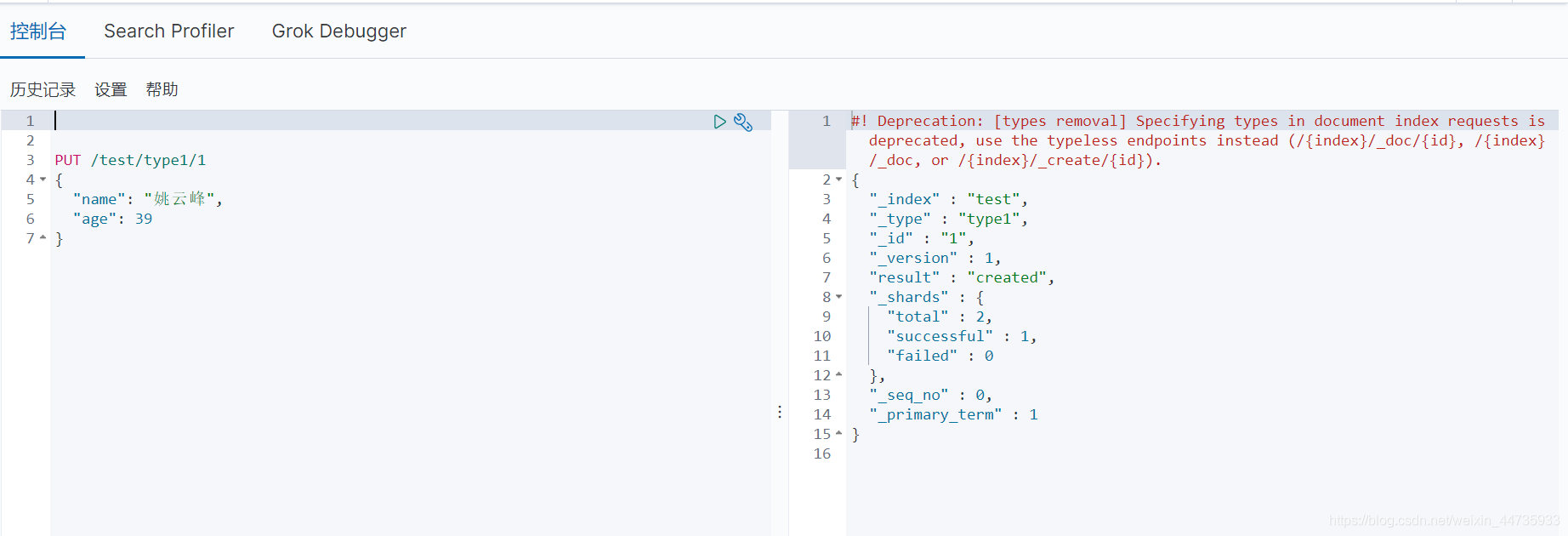
Put的索引的类型- 字符串类型
- text 、 keyword
- 数值类型
- long 、 integer 、 short 、 byte 、 double 、 float 、 half 、 float 、 scaled 、 float
- 日期类型
- date
- 布尔值类型
- boolean
- 二进制类型
- binary
指定字段类型,创建索引的具体规则
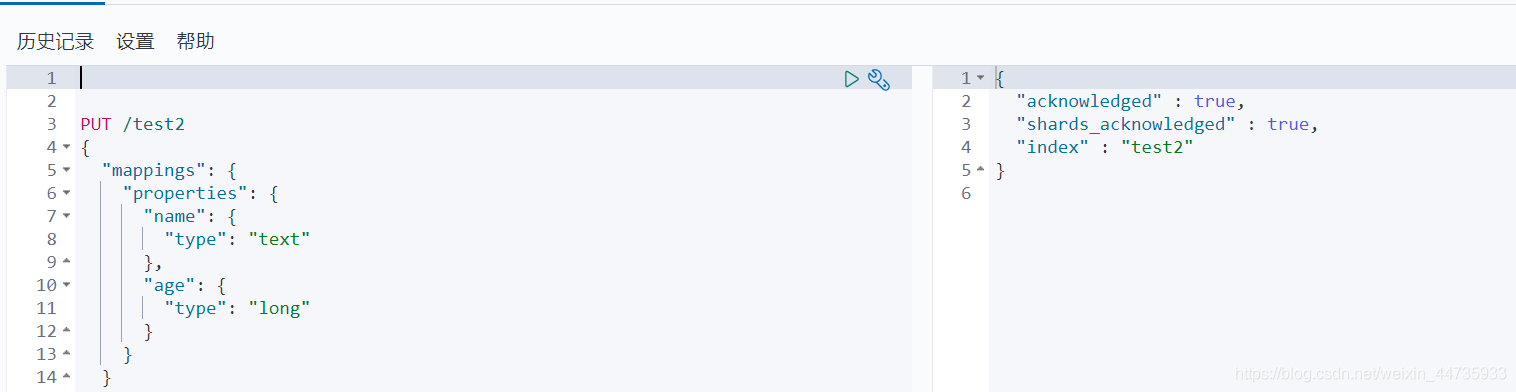
PUT /test2 { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "long" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
获取索引规则
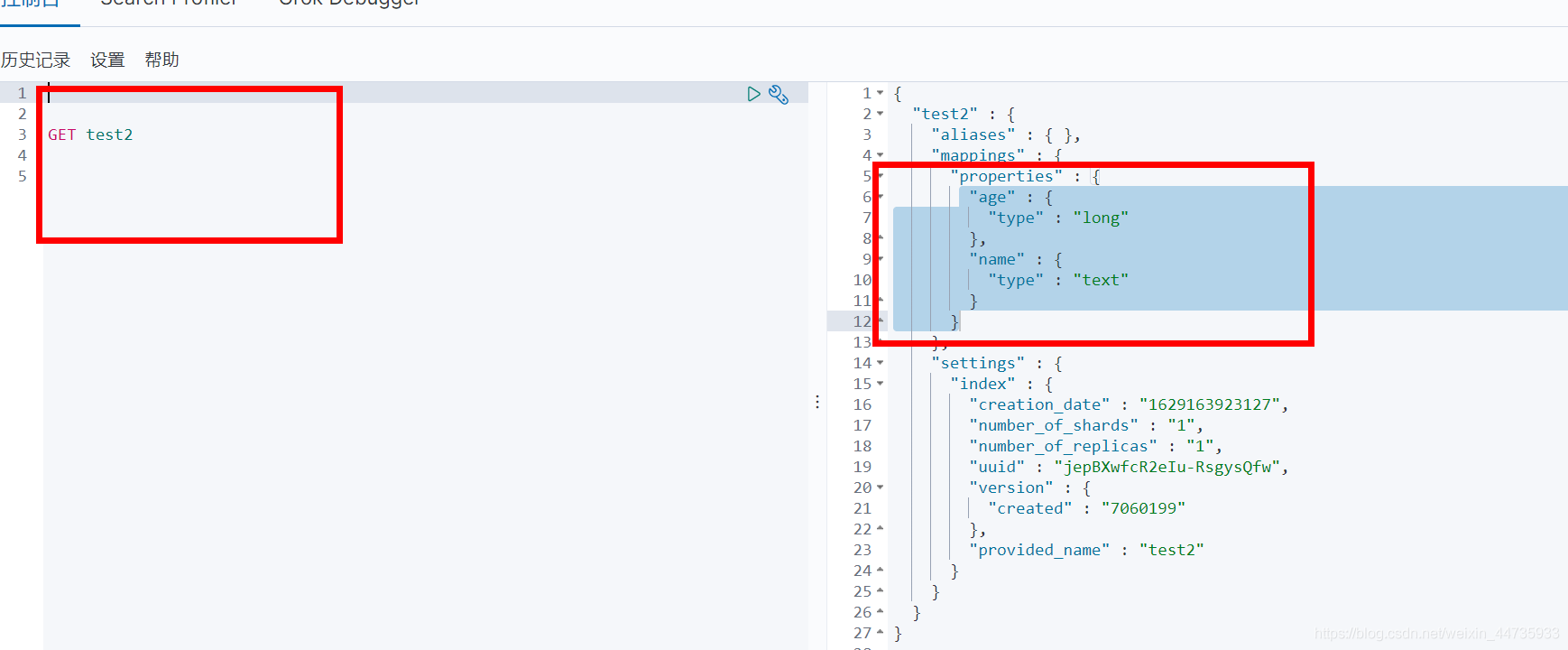
get 索引名如果自己的文档没有指定 , 那么ES就会给我们默认配置字段类型
通过
GET _cat/indices?v命令查看ES当前的一些信息更新索引
POST调用或PUT调用PUT调用 , 创建和原来索引一样的索引进行覆盖
PUT /test3/_doc/1 { "name": "张三", "age": 13 } PUT /test3/_doc/1/ { "name": "李四", "age": 15 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
POST修改索引
PUT /test3/_doc/1 { "name": "张三", "age": 13 } POST /test3/_doc/1/_update { "doc": { "name": "55", "age": 26 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
删除索引的名称
DELETE 索引名称- 1

文档的基本操作
基本操作
给文档添加元素
PUT /yyf/user/1 { "name": "张三", "age": 69 } PUT /yyf/user/2 { "name": "李四", "age": 80 } PUT /yyf/user/3 { "name": "王五", "age": 32 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
获取文档的值
GET /yyf/user/1- 1
更新文档的值
POST /yyf/user/1/_update { "doc": { "name": "车厘子", "age": 64 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
简单的条件查询 , q=关键字:值
GET /yyf/user/_search?q=name:王五- 1
复杂的操作查询(排序、分页、高亮、模糊查询、精准查询)
GET /yyf/user/_search { "query": { "match": { "name": "王五" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
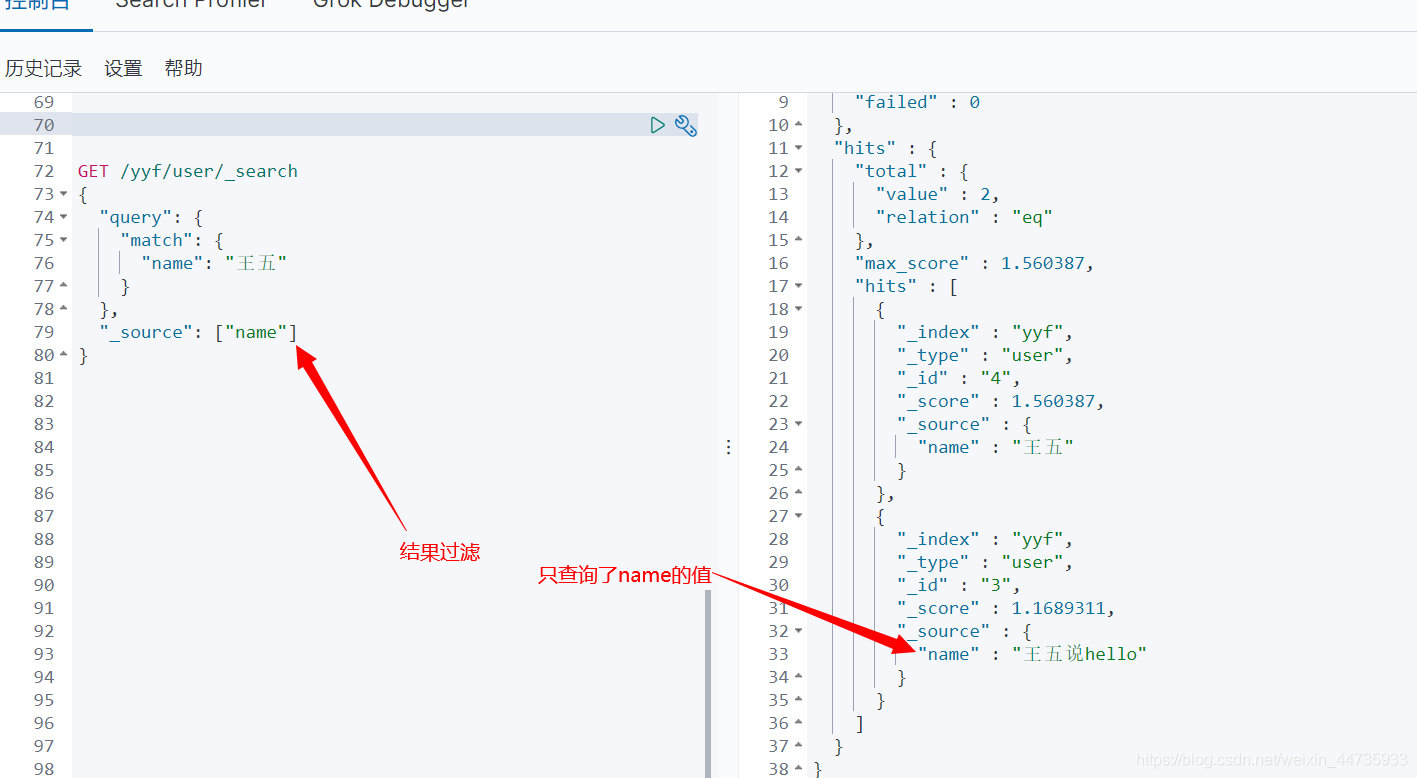
结果过滤:
GET /yyf/user/_search { "query": { "match": { "name": "王五" } }, "_source": ["name"] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
排序: desc 降序 , asc : 升序
GET /yyf/user/_search { "query": { "match": { "name": "王五" } }, "_source": ["name"], "sort": [ { "age": { "order": "desc" } } ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
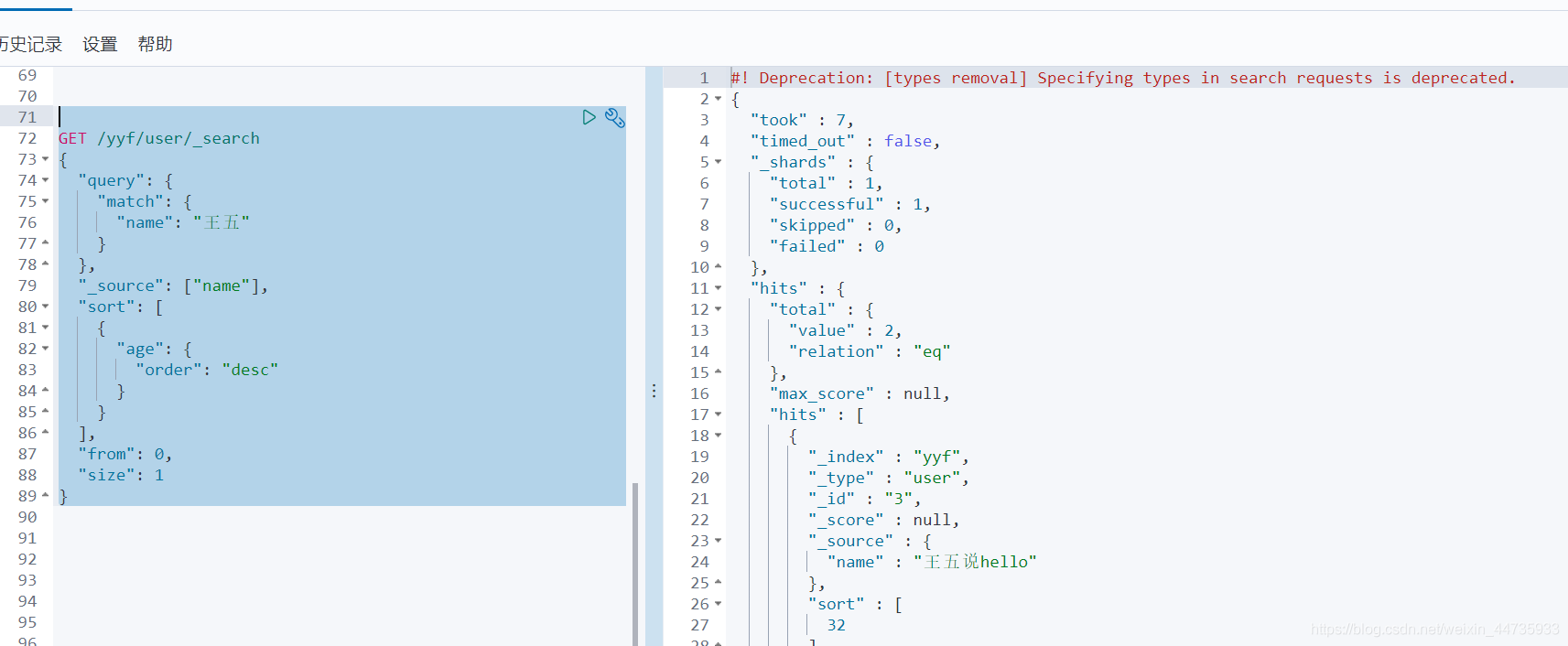
分页查询
from : 从第几条数据开始 , 默认从零开始
size:返回多少数据(单页面数据)GET /yyf/user/_search { "query": { "match": { "name": "王五" } }, "_source": ["name"], "sort": [ { "age": { "order": "desc" } } ], "from": 0, "size": 1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
多条件查询
must相当于mysql中的and , 要求必须都匹配
查询name是王五且age是32的值GET /yyf/user/_search { "query": { "bool": { "must": [ { "match": { "name": "王五" } }, { "match": { "age": 32 } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
should相当于mysql中的or
age是32 或者name是王五的元素GET /yyf/user/_search { "query": { "bool": { "should": [ { "match": { "name": "王五" } }, { "match": { "age": 32 } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
must not过滤掉字段中满足条件的数据
不是王五且不等于三十二的 GET /yyf/user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "王五" } }, { "match": { "age": 32 } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
过滤查询
查询name是王五 ,且age满足从32到35岁的数据 , 包含32和35
gt : >
gte: >=
lt: <
lte:<=GET /yyf/user/_search { "query": { "bool": { "must": [ { "match": { "name": "王五" } } ], "filter": { "range": { "age": { "gte": 32, "lte": 35 } } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
匹配多个条件
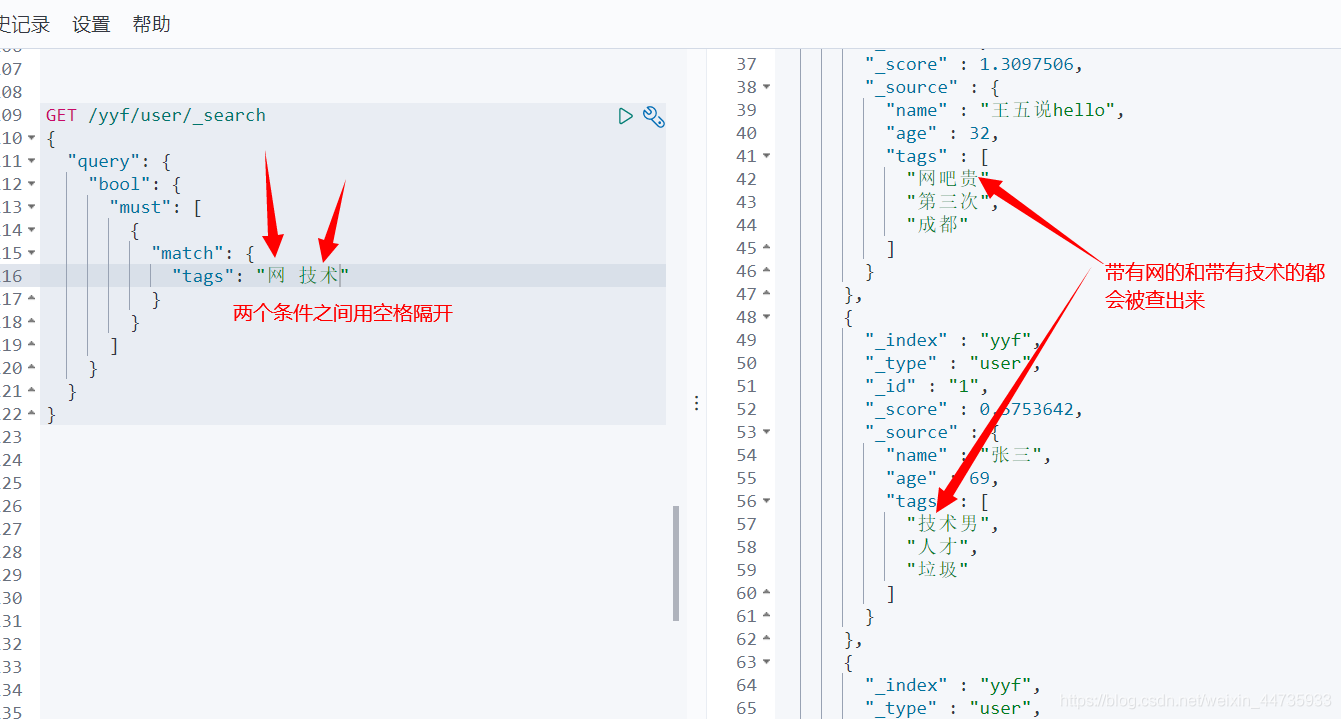
must类似于and where id = 1 and name = xxx
should 类似于or where id = 1 or name = xxx
must_not 相当于不等于
精确查询
term查询是直接通过倒排索引指定的词条进行精确查找的
- term是精确查找
- match , 会使用分词解析(先分析文档 , 然后通过分析的文档进行查询)
两个类型:test keyword
keyword字段类型不会被分词器解析 -
相关阅读:
[资源推荐]看到一篇关于agent的好文章
01背包的变形-最后一块石头重量。
IT创业网赚项目 - 越垂直越赚钱,这个思维价值连城。
【2023年11月第四版教材】第24章《法律法规与标准规范》(合集篇)
Mybatis-plus 自定义模板生成代码DTO、VO等
基于神经网络的图像识别,人工神经元网络的特点
【深入浅出玩转FPGA学习2----设计技巧(基本语法)】
生物活化量子点纳米载体/离子/功能化量子点修饰细胞膜/纳米颗粒修饰细胞膜荧光探针的制备
openGauss学习笔记-89 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用查询原生编译
css高阶技巧(2)
- 原文地址:https://blog.csdn.net/weixin_44735933/article/details/119715527