-
【人脸生成】HiSD-通过层级风格解耦实现图到图的迁移
Image-to-image Translation via Hierarchical Style Disentanglement
- 厦大,西交,腾讯
- 清晰易读
- 用公布的模型在自有数据上实测不及预期,但仍是值得尝试的方法
这是我看的第一篇人脸生成相关的论文,对这个领域不熟悉,因此会更多关注该领域的问题,做法,套路。乍一看这个标题,可能是想把一张图里的风格(style)迁移到另一张图,把这些风格按层级划分,目的是解耦同一张图里的风格,这里的图指的是人脸,进一步你就能想到,人脸上有多种风格,解耦它们是为了可控地只迁移一种特定的风格,同时要维持其他风格不变。
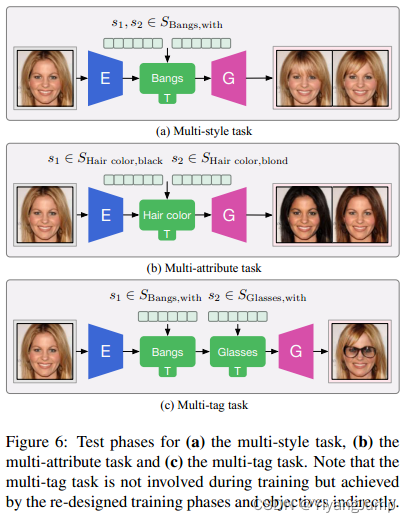
image-to-image translation图到图迁移领域, 一般要解决两个问题:根据多种label转换图片——multi-label task,和生成多种风格的丰富的的图片——multi-style task。
- multi-style: 目标是生成多种多样的tag相关的风格图片,如生成某人多种戴眼镜的图片,生成某人不同刘海的图片,在本论文里,风格用style code表述(风格编码,一组向量)可以是latent code随机生成的, 也可以是从参考图中抽取,分为两个子任务
- latent-guided task: latent code是GAN里的z向量,服从高斯分布的随机值,作用是帮助随机生成style code(风格编码), 如下图把戴眼镜这个风格迁移到input中来,生成同一人戴多种眼镜的随机图片。
- reference-guided task: 从参考图中提取指定tag的风格,如下图中把参考图里刘海的风格迁移到input上来,生成同一人多种刘海风格的图片。
- latent-guided task: latent code是GAN里的z向量,服从高斯分布的随机值,作用是帮助随机生成style code(风格编码), 如下图把戴眼镜这个风格迁移到input中来,生成同一人戴多种眼镜的随机图片。
- multi-label: 目的是把输入图片变成指定风格的图片,如把某人的头发变成金色,把给某人带上某款眼镜,头发梳成某种样式。分为两个子任务
- multi-attribute task: 将某tag下指定的多种属性的style迁移到input中来。比如下图把tag发色下属性为黑和棕色的风格迁移到input中来,生成同一人,发色tag下为某种属性的图片。
- multi-tag task: 将多种tag的风格迁移到input中来,如下图把横向参考图中的眼镜的风格,以及纵向参考图中刘海的风格迁移到input中来,生成的图片同时有眼镜和刘海的风格。
- multi-attribute task: 将某tag下指定的多种属性的style迁移到input中来。比如下图把tag发色下属性为黑和棕色的风格迁移到input中来,生成同一人,发色tag下为某种属性的图片。
对比SDIT, StarGANv2: SDIT的发色,眼镜,刘海共享一个编码空间,style code和目标label concat, 一起给到生成器去合成图片。StarGANv2学习混合的风格,再用目标label去索引style code, 它有一个多分支的mapping网络以latent code为输入,每个分支各输一个style code, 再根据目标label去索引用哪一个style code, 相应的,编码器,判别器都有多个分支。
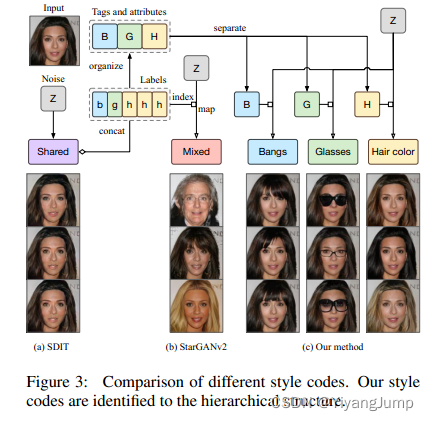
他们认为过去的迁移方法经常带来不必要的修改,如把人换了,或者改变背景。此外还不能独立地学习如刘海,眼镜,发色的风格。这种不可控的迁移严重制约了实际使用。于是他们- 层级地组织标签,分为相互独立的tags, 互斥的attributes
- 重新设计了模块,步骤,目标,一套适用层级风格标签的框架
从论文的图1看,他们把人脸图的原始label转化为层级的tags和attributes, 在标注上解耦了: 刘海,眼镜,发色的风格(他们用的CelebA-HQ数据集就只有这些标注)。
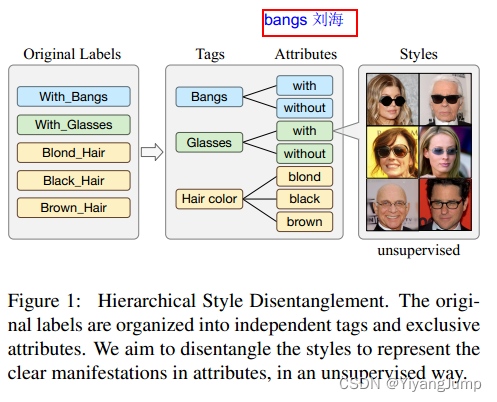
对于一张图, x i , j x_{i,j} xi,j表示它是带有tag i下属性j的图片. s i , j s_{i,j} si,j 表示该属性的style code。
他们的框架由以下模块组成- Mapper module (M): 风格映射器,作用是随机产生指定风格的style code。给定latent code z ∼ N ( 0 , 1 ) z \sim N(0,1) z∼N(0,1), 以及tagi下的属性j, mapper生成style code s i , j = M i , j ( z ) s_{i,j}=M_{i,j}(z) si,j=Mi,j(z),这里i,j是M的下标,而非输入,表明根据i,j被用来索引使用哪个风格映射器,有的用于随机生成金发风格,有的用于随机生成斜刘海风格。
- Extractor module (F): 风格提取器,作用是从图片种抽取指定的风格,比如一个发色为金色的图片,通过发色风格提取器后,提取出发色为金色的style code。给定图片 x i , j x_{i,j} xi,j和tag i, extractor从图片种抽取出tagi的风格 s i , j = F i ( x i , j ) s_{i,j}=F_{i}(x_{i,j}) si,j=Fi(xi,j),这里的F以i为下标,也表明有多个风格提取器,有的用于提取发色的风格,有的用于提取刘海的风格。
- Encoder module (E): 图片编码器,作用是把图片转为编码,以便于用转换器T去修改图片风格, e = E ( x ) e=E(x) e=E(x),e所在的空间才是可以修改风格的空间。
- Translator module (T): 风格转换器,它以图片编码e和风格编码s为输入,把图片修改为对应风格的编码, e ~ = T i ( e , s i , j ) \tilde{e}=T_i(e,s_{i,j}) e~=Ti(e,si,j),T是可以作用多次的,修改多个风格。这里的T以i为下标,也表明有多个风格转换器,有的用来转换眼镜风格,有的用于转换刘海风格。
- Generator module (G): 图像生成器,它以图片编码(包括修改后的)为输入,生成风格被修改后的图像, x ~ = G ( e ~ ) \tilde{x}=G(\tilde{e}) x~=G(e~)
- Discriminator module (D): 图像判别器,它对图像是否为真实图像分类,目的是促进对抗训练生成逼真的图像。
这些模块被独立优化,训练时随机采样tag i, 原始属性j, 目标属性 j ~ \tilde{j} j~, 给定原始图片 x i , j x_{i,j} xi,j, 该框架的训练阶段包括
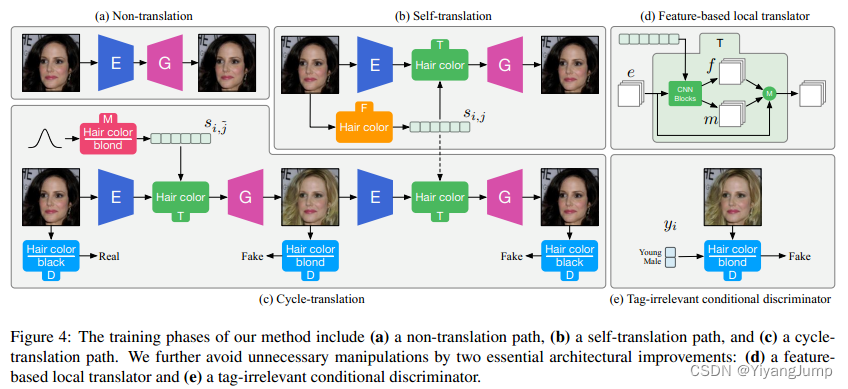
- Non-translation path: 非迁移路径,希望图像编码后还能再生成原图,得到第一张重建图像
- x i , j ′ = G ( E ( x i , j ) ) x'_{i,j}=G(E(x_{i,j})) xi,j′=G(E(xi,j))
- Self-translation path: 自迁移路径,希望在图像编码上使用自身的风格编码修改后还能生成原图,得到第二张重建图像
- s i , j = F i ( x i , j ) s_{i,j}=F_i(x_{i,j}) si,j=Fi(xi,j)
- x i , j ′ ′ = G ( T ( E ( x i , j ) , s i , j ) ) x''_{i,j}=G(T(E(x_{i,j}), s_{i,j})) xi,j′′=G(T(E(xi,j),si,j))
- Cycle-translation path: 循环迁移路径,希望图像风格被修改后再改回来原风格还能生成原图,得到第三张重建图像
- s i , j ~ = M i , j ~ ( z ) s_{i,\tilde{j}}=M_{i,\tilde{j}}(z) si,j~=Mi,j~(z)
- x i , j ~ = G ( T ( E ( x i , j ) , s i , j ~ ) ) x_{i,\tilde{j}}=G(T(E(x_{i,j}),s_{i,\tilde{j}})) xi,j~=G(T(E(xi,j),si,j~))
- x i , j ~ ′ ′ ′ = G ( T ( E ( x i , j ~ ) , s i , j ~ ) ) x'''_{i,\tilde{j}}=G(T(E(x_{i,\tilde{j}}),s_{i,\tilde{j}})) xi,j~′′′=G(T(E(xi,j~),si,j~))
该框架的损失函数包含
- 对抗损失:从希望生成的图片能以假乱真的角度看,判别器尽量分错,第2,3项用到了第2,3张重建图,如果它们逼真,代表提取器F, 映射器M, 转换器T能学习的比较好。
- L a d v = 2 E i , j , x [ log ( D i , j ( x i , j ) ) ] L_{adv}=2\mathbb{E}_{i,j,x}[\log({D_{i,j}(x_{i,j})})] Ladv=2Ei,j,x[log(Di,j(xi,j))]
- + E i , j , x , j ~ , z [ log ( 1 − D i , j ~ ( x i , j ~ ) ) ] +\mathbb{E}_{i,j,x,\tilde{j},z}[\log(1-{D_{i,\tilde{j}}(x_{i,\tilde{j}})})] +Ei,j,x,j~,z[log(1−Di,j~(xi,j~))]
- + E i , j , x , j ~ , z [ log ( 1 − D i , j ( x ~ i , j ′ ′ ′ ) ) ] +\mathbb{E}_{i,j,x,\tilde{j},z}[\log(1-{D_{i,j}(\tilde{x}'''_{i,j})})] +Ei,j,x,j~,z[log(1−Di,j(x~i,j′′′))]
- 重建损失,希望每张重建图都和原图保持一致性:
- L r e c = E i , j , x [ ∣ ∣ x i , j ′ − x i , j ∣ ∣ 1 ] L_{rec}=\mathbb{E}_{i,j,x}[||x'_{i,j}-x_{i,j}||_1] Lrec=Ei,j,x[∣∣xi,j′−xi,j∣∣1]
- + E i , j , x [ ∣ ∣ x i , j ′ ′ − x i , j ∣ ∣ 1 ] +\mathbb{E}_{i,j,x}[||x''_{i,j}-x_{i,j}||_1] +Ei,j,x[∣∣xi,j′′−xi,j∣∣1]
- + E i , j , x , j ~ , z [ ∣ ∣ x i , j ′ ′ ′ − x i , j ∣ ∣ 1 ] +\mathbb{E}_{i,j,x,\tilde{j},z}[||x'''_{i,j}-x_{i,j}||_1] +Ei,j,x,j~,z[∣∣xi,j′′′−xi,j∣∣1]
- 风格损失,希望从修改风格后的图提取风格,和我们期望的风格一致:
- L s t y = E i , j , x , j ~ , z [ ∣ ∣ F i ( x i , j ~ ) − s i , j ~ ∣ ∣ 1 ] L_{sty}=\mathbb{E}_{i,j,x,\tilde{j},z}[||F_i(x_{i,\tilde{j}})-s_{i,\tilde{j}}||_1] Lsty=Ei,j,x,j~,z[∣∣Fi(xi,j~)−si,j~∣∣1]
- 总优化目标:
- m i n E , G , T , F , M m a x D L a d v + λ r e c L r e c + λ s t y L s t y \underset{E,G,T,F,M}{min} \underset{D}{max}{L_{adv}+\lambda_{rec}L_{rec}+\lambda_{sty}L_{sty}} E,G,T,F,MminDmaxLadv+λrecLrec+λstyLsty
为了避免对图片进行全局的修改,希望修改只专注于表征风格的局部特征上,
测试时的流程如下, 先生成风格编码,代表你要给图片带来什么风格。style code可以来自latent code, 通过风格映射器M映射到style code的空间,得到很多随机的style code, 也可以从图片中使用风格提取器F抽取
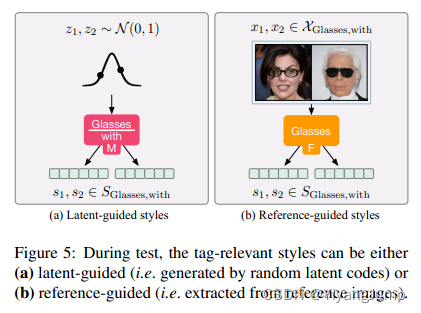
随后流程都是一样的,编码 -> 修改 -> 生成,比如生成多个刘海图片,用刘海映射器M(i=刘海,j=有)生成很多风格编码喂给转换器T。要生成黑发棕发也只需把相应的风格编码喂给T。要生成带有不同tag的风格图像时,需要不同tag的风格编码,分别使用对应tag的风格转换器,分多次修改编码。
为了避免全局修改,使修改只作用在感兴趣的局部,而不改变背景光照等,比如戴眼镜只作用在眼睛部位,他们引入了基于特征的局部转换器(Feature-based Local Translator), Translator除了输出修改后的特征e外,还会输出同样大小的m,f, 其中m用于产生注意力的mask, f的作用尚不清楚,转换后的最终输出为
σ ( m ) ⋅ e + ( 1 − σ ( m ) ) ⋅ f \sigma(m) \cdot e + (1-\sigma(m)) \cdot f σ(m)⋅e+(1−σ(m))⋅f另一方面,他们觉得在不同性别,年龄这些和tag无关的标签下,tag的属性是不平衡的,他们把这些和tag无关的标签作为判别器的参数,使判别器注意到这种不平衡,并激励转换器不要修改tag无关的条件(????不懂)
L a d v ′ = 2 E ∗ i , j , x [ log ( D ∗ i , j ( x i , j , y i ) ) ] L'_{adv}=2\mathbb{E}*{i,j,x}[\log({D*{i,j}(x_{i,j},y_i)})] Ladv′=2E∗i,j,x[log(D∗i,j(xi,j,yi))]
+ E ∗ i , j , x , j ~ , z [ log ( 1 − D ∗ i , j ~ ( x i , j ~ , y i ) ) ] +\mathbb{E}*{i,j,x,\tilde{j},z}[\log(1-{D*{i,\tilde{j}}(x_{i,\tilde{j}},y_i)})] +E∗i,j,x,j~,z[log(1−D∗i,j~(xi,j~,yi))]
+ E ∗ i , j , x , j ~ , z [ log ( 1 − D ∗ i , j ( x ~ i , j ′ ′ ′ , y i ) ) ] +\mathbb{E}*{i,j,x,\tilde{j},z}[\log(1-{D*{i,j}(\tilde{x}'''_{i,j},y_i)})] +E∗i,j,x,j~,z[log(1−D∗i,j(x~i,j′′′,yi))]
他们评价这个工作的好坏,考虑三个方面

- 真实性(Realism FID):如对每张不带刘海的测试图,用随机生成的5个带刘海的style code(for latent-guided task)或随机从5张带刘海的图片中抽取style code(for reference-guided task)转化为带刘海的图片,计算这些图片和真实带刘海图片的FID(Frechet inception distance, 它Inception网络来提取特征,然后使用高斯模型对特征空间进行建模,再去求解两个特征之间的距离,较低的FID意味两组图片的特征分布越接近), FID越小说明生成的刘海图片越像真的刘海图片。
- 多样性(Diversity User Study%):他们使用用户调查的方式评价多样性
- 解耦(Disentanglement FID):如转换无刘海的年轻男性图片成有刘海的,并用这些转换图片和真实的有刘海的年轻男性图片计算FID. 如果转换后的图片的tag无关属性,如性别变化了,那么FID就会很高
-
相关阅读:
设备通过国标GB28181接入EasyCVR平台,出现断流情况该如何解决?
Transferrin-PEG-PMMA 转铁蛋白-聚乙二醇-聚甲基丙烯酸甲酯,F-PEG-PBA/PAE/PPS
idea远程debug调试
2.10 PE结构:重建重定位表结构
2022年全球及中国工程机械行业头部企业市场占有率及排名调研报告
MindSpore是一种适用于端边云场景的新型开源深度学习训练/推理框架
基于5G网关的风力发电远程监测方案优势
C语言加密字符(ZZULIOJ1064:加密字符)
M1通讯层的校验-尾块
Java中Integer的最大值和最小值
- 原文地址:https://blog.csdn.net/q1w2e3r4470/article/details/125978619



