-
程序是如何运行的?
程序的开发流程
以c语言为例,常规开发流程如下:
首先写一份helloworld.c:
#includeint main() { printf("HelloWorld!\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
然后使用gcc生成可执行文件hello:
gcc -o hello helloworld.c- 1
最后在终端运行hello:
./hello #HelloWorld!- 1
- 2
从可执行文件反推计算机的运行原理
首先介绍一下术语:
helloworld.c叫程序;
hello叫可执行文件;
稍后会介绍进程;从程序到执行文件,gcc帮我们做了预处理,编译和链接三个过程。
预处理就是一次文本替换。为什么需要预处理呢?
因为c语言相对于汇编语言是高级语言,高级语言的目的就是为了让人能像写文字一样写机器代码。
为什么需要像写文字一样写机器代码呢?
因为计算机运行时执行的是指令,指令是由0和1组成的二进制构成的,一条指令如下:
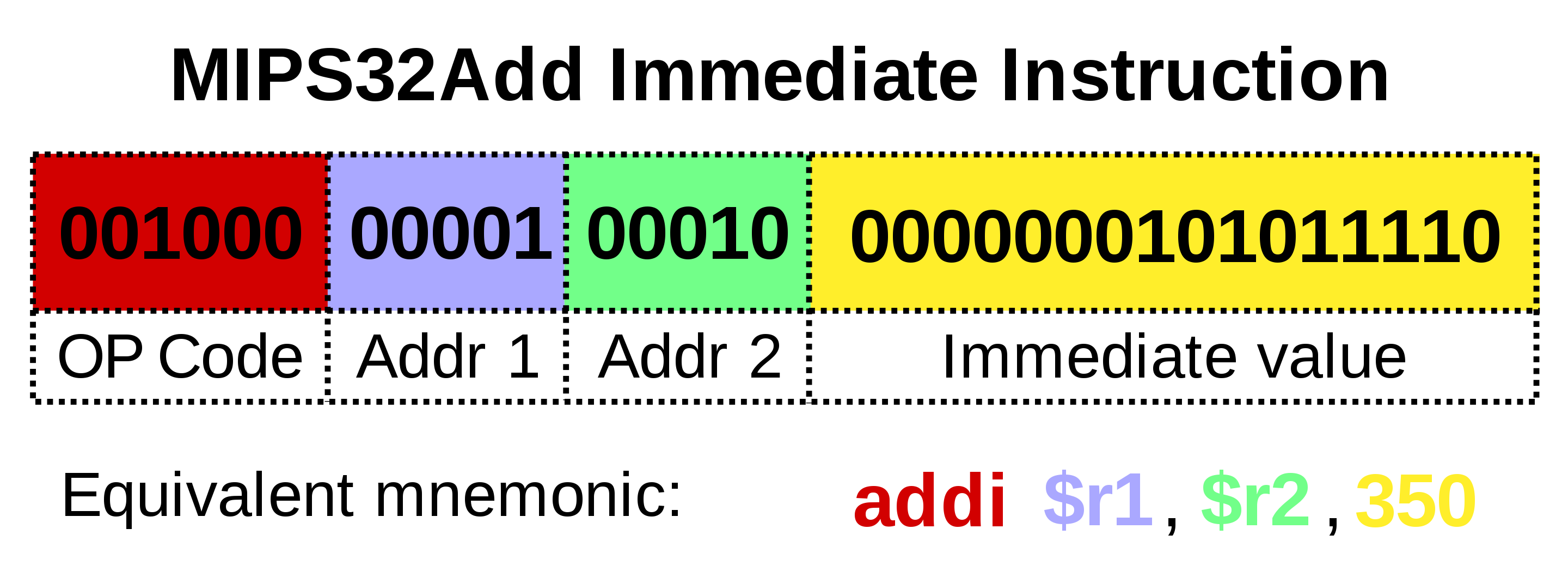
那汇编和指令集又是什么呢?
首先解释指令集和微架构的概念。指令就是告诉计算运行哪些部件,从简单的加法器开始,到计算图形的GPU,各种元器件层出不穷,指令集的作用就是屏蔽这些元器件的构造方式,用概念来描述行为。比如,加法器可以用电磁铁来实现,也可以用晶体管来实现,但其实他们作用是相同的,都是做加法运算的。基于模块化思维,从硬件层抽象出了指令集的概念,指令集是一套协议,就是一套规则,是字面描述,而微架构就是电路的制造工艺、以及布线方式等等。举个例子,赋值是x86指令集中的一个指令,用于将寄存器或者内存的位置存上某个值,这就是认为抽象出的概念,那么完成MOV可能需要加法器等,那么这个硬件加法器就是微架构,因为制作工艺不同,因此加法器的实现方式也不同。因此,指令集不是硬件,是概念,而微架构是硬件,是制作工艺,一条指令可能要调动多个元器件。但此时的指令还是用0和1来描述的。由于指令的长度是不等的,且CPU又有不同的指令集,包括x86指令集、ARM指令集、MIPS指令集、RSC-V指令集等,因此,在指令的基础上又抽象出汇编的概念。汇编是为了屏蔽各种指令集中指令的差异而抽象出的概念,比如x86的赋值指令可能需要8位来描述,而ARM的赋值指令可能需要4位来描述,但大家又都是赋值,因此出现了汇编,使用
MOV来表示赋值指令,具体是x86的指令还是ARM的指令,由实现者去完成。因此说汇编是一种助记符,而不是语言。但其实c语言也是类似实现的,c语言在各个平台的语法和接口都是一样的,屏蔽了底层的实现差异,但c语言是c语言创作者实现的,而汇编不是指令集的创造者,只是辅助者,因此,汇编是助记符,c语言是编程语言。
话说,语言的本质是? 交流!为什么计算机只能识别0和1呢?
这要从信息论说起,其实计算机可以用任何进制实现,除了1进制,因为1进制没法表示变化。那么我们可以想象,灯泡的开、关,灯塔的亮、灭,电压的高、低,电磁体的有磁性和无磁性,二极管的导通和阻塞,万事万物,能表示两种状态的东西太多了,因此二进制是实现最简单的方式。自然而然的,不用二进制的原因是我们想用十进制,十进制用啥表示呢,用什么能表示10种状态呢,10种电压?还是有啥?很少很少。
至此,可以知道,是为了信息能够有效的传输和储存,我们选择的二进制!编译和链接
书接上回:
从程序到执行文件,gcc帮我们做了预处理,编译和链接三个过程。
预处理就是一次文本替换。预处理就是将.c文件中所有带井号#的语句都处理一遍,把#define语句中前后进行文本替换,把#if 0的段落都删掉,把注释语句全删掉…
所以c语言作为高级语言,为了能让人像写文字一样和机器交流,背后做了很多工作。那么这些工作是谁来做的呢?就是c语言运行时!c语言运行时内知道了每个c语言实现的操作系统中,因此我们感觉不到他,但他和java语言一样,是因为有运行时帮助我们处理文件,管理运行状态,这些语言才能起作用的,不然就只能靠汇编了,就算汇编也需要汇编器。
预处理完成后,是删减和修改.c文件后的最简状态,存为.i文件。编译,编译就是将.i文件生成.o文件,.o文件已经是可执行文件格式了,只是其中的外部函数和变量的地址都是占位符,不是真实的地址。为什么会这样呢?因为这是为了避免修改一处代码,所有文件都要编译的现象。如果让所有文件都单独编译,那么修改一个文件,就只需要编译一个文件就好了。因此文件a中需要引用文件b中的函数或变量,一定要在文件a中有定义,但可以没有实现,这样才能写上占位符,以便链接用。链接,链接就是将各种.o文件合成一个可执行文件,将.o文件中的占位符通过查找其他文件中的地址,写上真实地址,此时所有需要执行的命令和数据都在这个可执行文件中,所有内存地址也都是真实内存地址。这样一个可执行文件就生成了,在Linux下知可行文件是elf格式。可执行文件格式
我们写程序时是按自然逻辑写的,比如全局变量写在main函数上边。
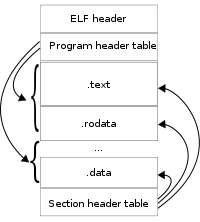
但是可执行文件不是这样存储的,可执行文件elf将代码重组,分成了代码段(.text)、数据段(.data)、堆栈等多个段。
代码段存放所有代码,数据段存放所有数据,为什么分开放还能正常运行呢?因为所有操作依赖的都是内存地址,每个变量和函数都有地址,且指令记录的也是内存地址,因此,分开放也不影响。
运行程序
elf文件介绍后,我们来介绍执行elf文件:
./hello- 1
这一步做的是,将elf文件加载到内存,然后cpu定位到内存中hello的主函数main,开始执行。
这是程序最开始的样子,现代的加载方式包括了虚拟内存、写时复制等技术,下面表述。
因此,放在硬盘上的helloworld.c是源码,放在硬盘上的可执行程序hello是程序,通过命令行加载到内存的elf文件是进程,可以理解为“进行中的程序?”,最后进程结构体是描述一个进程的核心数据格式。程序在内存中的存储方式
什么是
内存模型?
本文中,内存模型指的是数据在内存中存储和读取方式。在elf文件中,数据段分为:静态数据和动态数据,分别存在静态存储区和动态存储区。
静态存储区用于存储全局变量和静态变量(static声明的);
动态存储区分为堆和栈,栈是从内存高地址向内存低地址增长的,堆是从内存低地址向内存高地址增长的,当然除了栈,其他内存模型都是从内存低地址向内存高地址增长。
栈是用于存放函数调用的,不存函数外的变量哦,函数外的变量存在静态存储区。
栈存放的数据包括,函数的参数、返回值和局部变量,这些入栈和出栈的操作由系统管理,因此会自动释放局部变量。
画个图~
堆,是为了突破自动管理变量限制,让程序员能手动管理变量声明周期而设计的,堆也是后进先出?但是其释放时间由程序员用delete管理。 -
相关阅读:
MyBatis(五)动态Sql
你说,难倒项目经理的流程管理到底怎么做?
WPF 常用功能整合
OpenHarmony藏头诗应用
ATFX汇市:美国5月PCE数据来袭,EURUSD或迎剧烈波动
python如何将代码制作成可以pip的库,将自己的python代码打包成库,让别人pip安装调用?
【C++】类和对象(中)
Vite创建Vue项目后遇到的问题
第二部分:聚合根
记一次使用NetworkManager管理Ubuntu网络无效问题分析
- 原文地址:https://blog.csdn.net/weixin_39759247/article/details/126085559