-
SVM支持向量机
目录
概述
SVM是通过寻找超平面,用于解决二分类问题的分类算法,核心思想是样本点到超平面的距离越远越好,是对感知机的优化。SVM又分为线性可分支持向量机、线性支持向量机和非线性支持向量机,分别对应着硬间隔、软间隔和应用核函数的支持向量机。本文将详述支持向量机的原理和公式推导
拉格朗日函数
假设函数为
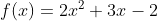 ,要求函数取的最小值时x的值,我们可以很轻易对函数进行求导,令导数为0,求得
,要求函数取的最小值时x的值,我们可以很轻易对函数进行求导,令导数为0,求得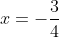 。假设有约束条件x>=0,在此我们知道x=0处可以取到最优解,但是如何统一的将有约束条件优化为题转化为无约束条件优化问题进行求解,就需要用到拉格朗日函数。
。假设有约束条件x>=0,在此我们知道x=0处可以取到最优解,但是如何统一的将有约束条件优化为题转化为无约束条件优化问题进行求解,就需要用到拉格朗日函数。设有约束的优化问题:

拉格朗日函数可以将以上的有约束问题转化成如下的无约束问题,其中
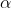 和
和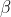 是拉格朗日乘子:
是拉格朗日乘子: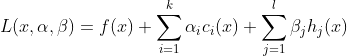
则问题转化为:
![\min_{x}\max_{\alpha\geq 0,\beta} [f(x) + \sum_{i=1}^{k}\alpha_i c_i(x) + \sum_{j=1}^{l}\beta_j h_j(x)]{\quad}{\quad}{\quad}(1)](https://1000bd.com/contentImg/2022/08/02/224207571.gif)
拉格朗日对偶问题:
![\max_{\alpha\geq 0,\beta}\min_{x} [f(x) + \sum_{i=1}^{k}\alpha_i c_i(x) + \sum_{j=1}^{l}\beta_j h_j(x)]{\quad}{\quad}(2)](https://1000bd.com/contentImg/2022/08/02/224209055.gif)
当
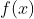 和
和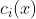 是凸函数,
是凸函数,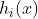 是仿射函数时,(1)式和(2)式具有相同的解
是仿射函数时,(1)式和(2)式具有相同的解KKT条件:
硬间隔SVM

目标函数
硬间隔SVM的思想是:能正确分类的点,距离超平面越远越好。点到超平面的距离公式为
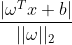 ,假设点都能被正确分类,故而
,假设点都能被正确分类,故而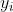 和
和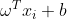 是同号,进而可写成
是同号,进而可写成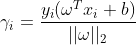 。距离超平面越远越好可表达为:
。距离超平面越远越好可表达为: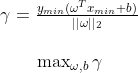
且所有的样本点到超平面的距离都要大于最小距离,函数距离可表达为
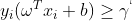 ,由于一组
,由于一组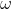 和b可以确定一个超平面,一个超平面可以对应无数组和b(就好比
和b可以确定一个超平面,一个超平面可以对应无数组和b(就好比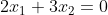 和
和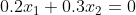 确定的是同一条直线),求出一组 和b即可,故而令
确定的是同一条直线),求出一组 和b即可,故而令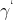 =1,最终可得目标函数为:
=1,最终可得目标函数为: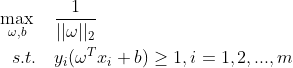
又由于求
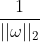 的极大,相当于求
的极大,相当于求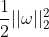 的极小,所以目标函数表示为:
的极小,所以目标函数表示为: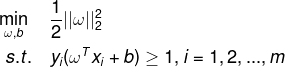
函数求解
构建拉格朗日函数:
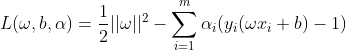
原有的有约束问题转化为无约束问题:
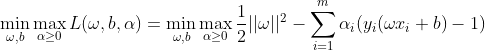
对偶问题:
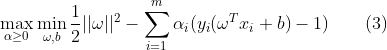
对拉格朗日函数分别对
和b求偏导,同时令偏导等于o,求极小: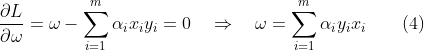
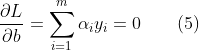
将(4)和(5)代入(3):
去掉负号,极大变极小整理得:
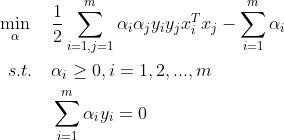
可通过SMO算法求得一组
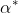 使得函数最优化,再通过
使得函数最优化,再通过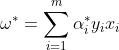 可得
可得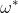
依据KKT条件:
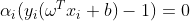 ,
,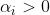 则
则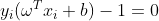 ,找出一个对应的
,找出一个对应的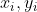 代入即可得到
代入即可得到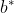 。(对应的点就是支持向量)
。(对应的点就是支持向量)软间隔SVM
目标函数
软间隔SVM是在硬间隔SVM的基础上添加松弛变量
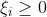 ,每个样本对应一个松弛变量,
,每个样本对应一个松弛变量,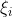 代表样本点嵌入间隔面的深度,之前的硬间隔不可分体现在不能满足约束条件,将约束条件放松修改为
代表样本点嵌入间隔面的深度,之前的硬间隔不可分体现在不能满足约束条件,将约束条件放松修改为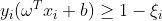 ,但是不能是无穷大,如果是无穷大,任意的和b都满足,故而在目标函数上增加惩罚项,目标函数整理如下:
,但是不能是无穷大,如果是无穷大,任意的和b都满足,故而在目标函数上增加惩罚项,目标函数整理如下: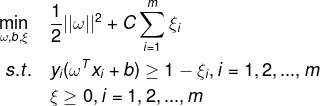
函数求解
构造拉格朗日函数:
![L(\omega,b,\xi,\alpha,\beta)=\frac{1}{2}||\omega||^2+C\sum_{i=1}^{m}\xi_i-\sum_{i=1}^{m}\alpha_i[y_i(\omega^Tx_i+b)+\xi_i-1]-\sum_{i=1}^{m}\beta_i\xi_i](https://1000bd.com/contentImg/2022/08/02/224314579.gif)
原有的有约束问题转化为无约束问题:
![\min_{\omega,b,\xi}\max_{\alpha\geq 0,\beta\geq 0}\frac{1}{2}||\omega||^2+C\sum_{i=1}^{m}\xi_i-\sum_{i=1}^{m}\alpha_i[y_i(\omega^Tx_i+b)+\xi_i-1]-\sum_{i=1}^{m}\beta_i\xi_i](https://1000bd.com/contentImg/2022/08/02/224316797.gif)
对偶问题:
![\max_{\alpha\geq 0,\beta\geq 0}\min_{\omega,b,\xi}\frac{1}{2}||\omega||^2+C\sum_{i=1}^{m}\xi_i-\sum_{i=1}^{m}\alpha_i[y_i(\omega^Tx_i+b)+\xi_i-1]-\sum_{i=1}^{m}\beta_i\xi_i{\quad}{\quad}(6)](https://1000bd.com/contentImg/2022/08/02/224318335.gif)
对拉格朗日函数分别对
、b、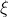 求偏导,同时令偏导等于o,求极小:
求偏导,同时令偏导等于o,求极小:
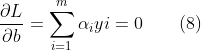
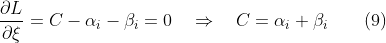
将(7)(8)(9)式代入(6)式:
去掉负号,极大变极小整理得:
(10)(11)(12)式整理:
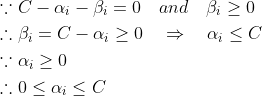
最终对偶问题为:

仍然可以通过SMO算法求得一组
使得函数最优化,、和硬间隔SVM的、的求法一致判别函数另一种表现形式
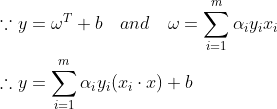
结论
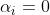 ,点被正确分类
,点被正确分类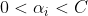 ,该点是位于软边界上的点
,该点是位于软边界上的点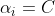 :
:
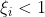 ,点被正确分类
,点被正确分类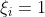 ,点位于超平面上
,点位于超平面上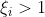 ,点未被正确分类
,点未被正确分类
非线性SVM
当数据线性不可分我们可以通过升维的方式使样本在高维的空间线性可分,如上可知SVM的最优化问题为:
升维的优化问题为:
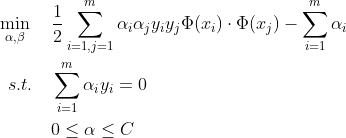
问题:这样升维带来一些问题,假设用多项式回归进行升维,对于(
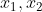 )二维升维的结果是(
)二维升维的结果是(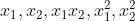 ),共5维,如果是3维数据,升维后就会有19维,以此类推,将会导致维度爆炸。升维后还需要做内积运算,时间(内积运算)和空间(升维之后的数据存储)的消耗将是恐怖的
),共5维,如果是3维数据,升维后就会有19维,以此类推,将会导致维度爆炸。升维后还需要做内积运算,时间(内积运算)和空间(升维之后的数据存储)的消耗将是恐怖的核函数升维
核函数的思想是不计算
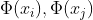 的中间结果,令
的中间结果,令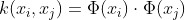 ,直接计算出结果,节省时间和空间,优化问题变为:
,直接计算出结果,节省时间和空间,优化问题变为: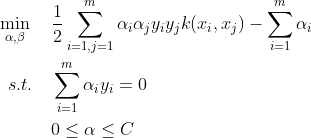
判别函数:
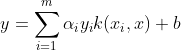
常用核函数
- 线性核函数(没有升维)
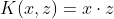
- 多项式核函数
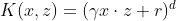
- 高斯核函数
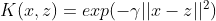
- sigmoid核函数
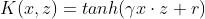
SVM的合页损失函数
合页损失函数图像:

我们知道,函数间隔
 是被正确分类的点,故而当不满足条件时会产生损失,svm的损失函数其实合页损失函数加上L2正则化项:
是被正确分类的点,故而当不满足条件时会产生损失,svm的损失函数其实合页损失函数加上L2正则化项:![\min_{\omega,b}\sum_{i=1}^{m}[1-y_i(\omega^Tx_i+b)]_++\lambda||\omega||^2](https://1000bd.com/contentImg/2022/08/02/224413993.gif)
合页损失函数在代码中的可用
![max(0,[1-y_i(\omega^Tx_i+b)])](https://1000bd.com/contentImg/2022/08/02/224415798.gif) 来表达,可以通过梯度下降来求解最优解
来表达,可以通过梯度下降来求解最优解SVM实现鸢尾花数据集的分类
- from sklearn.datasets import load_iris
- from sklearn.svm import SVC
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.model_selection import train_test_split, GridSearchCV
- from sklearn.metrics import accuracy_score
- # 加载数据
- iris = load_iris()
- X = iris['data']
- y = iris['target']
- # 数据集分割
- X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
- '''
- kernel 核函数,默认高斯核(rbf)
- gamma 对应核函数中的gamma
- C 对应软间隔目标函数中的惩罚项系数C
- coef0 对应核函数中的r,仅对多项式核函数和sigmoid核函数有效
- '''
- svc = SVC()
- param_grid = {
- 'C': [1.0, 1.1, 1.2, 2],
- 'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
- 'decision_function_shape' : ['ovo', 'ovr']
- }
- grid_search = GridSearchCV(svc, param_grid=param_grid, cv=3, n_jobs=-1)
- grid_search.fit(X_train, y_train)
- best_model = grid_search.best_estimator_
- print('the best params is {}'.format(grid_search.best_params_))
- # 模型评估
- y_predict = best_model.predict(X_test)
- acc = accuracy_score(y_test, y_predict)
- print('accuracy is {}'.format(acc))

-
相关阅读:
C语言实现快速排序算法
pytest+allure生成测试报告
JVM是什么?Java程序为啥需要运行在JVM中?
原型模式:复制对象的技巧
C/C++轻量级并发TCP服务器框架Zinx-游戏服务器开发004:游戏核心消息处理 - 玩家类的实现
css实现不同设备适配
编程架构演化史:远古时代,从打孔卡(Punched Card)开始
Spring常见问题解决 - @PathVariable 解析带 / 的参数值报404
【STM32HAL库】外部中断
模拟器抓HTTP/S的包时如何绕过单向证书校验(XP框架)
- 原文地址:https://blog.csdn.net/IT142546355/article/details/126077216
