-
算法提升①
目录
一、求递归的时间复杂度
1、对递归的认识
递归其实就是一个压栈操作,将母问题规模不断分解,有点类似于二叉树后序遍历。
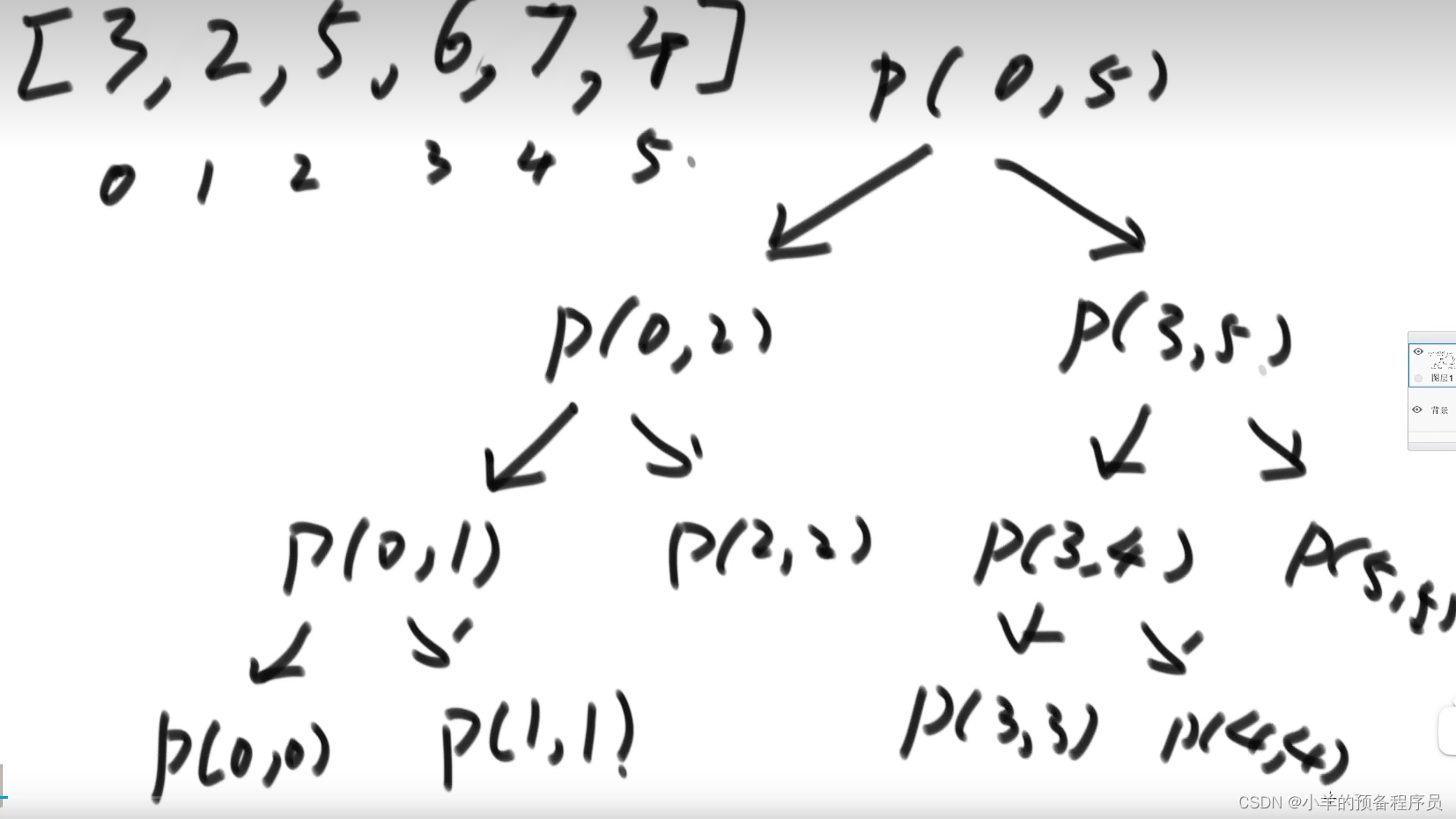
例如用递归方法找一个数组中的最大值。
求[3, 2, 5, 6, 7, 4]数组中的最大值
我需要找到数组0 - 5号位中的最大值,我需要先找到0 - 2号位和3 - 5号位的最大值
找0 - 2号位的最大值,我需要先找0 -1号位的最大值和1 - 2号位的最大值...
 2、master公式的使用
2、master公式的使用能使用master公式的前提:子问题的递归规模是母问题的O(N/b),并且能拆分成多个同样规模的子问题加上一个规模O(N^b)的问题。
当a,b,d三个参数确定,那么母问题递归的时间复杂度就已经确定了
 例如用递归方法找一个数组中的最大值。
例如用递归方法找一个数组中的最大值。- int getMax(int arr[], int length)
- {
- return process(arr, 0, length - 1);
- }
- int process(int arr[], int L, int R)
- {
- //范围只有一个数,直接返回
- if(L == R)
- {
- return arr[L];
- }
- int mid = L + ((R - L)>>1); //中点,可以防止int溢出
- int leftMax = process(arr, L, mid);
- int rightMax = process(mid + 1, R);
- return leftMax > rightMax ? leftMax : rightMax;
- }
上面实现的递归算法子问题是两次规模是母问题一半的递归O(N/2)(寻找中点左边范围的最大值和寻找重点右边范围的最大值),再加上一次左边的最大值和右边的最大值比较得到最大值的一个O(N^0)的问题
满足master公式,其中a = 2,b = 2,d = 0;
并且loga b > d,所以该递归方法的时间复杂度为O(N^loga b),O(N)。
二、归并排序
(1)整体就是一个简单递归,左边排好序、右边排好序、让整体有序
(2)让其整体有序的过程里用了外排序方法
(3)利用master公式来求解时间复杂度
(4)归并排序的实质
时间复杂度O(N*logN),额外空间复杂度O(N)
- //归并排序
- //1、给中点左边和右边排序
- //2、归并
- void merge(int arr[], int L, int Mid, int R)
- {
- //arr1是临时数组
- int* arr1 = new int[R - L + 1];
- int i = 0;
- int p1 = L;
- int p2 = Mid + 1;
- //先排完一边
- while (p1 <= Mid && p2 <= R)
- {
- arr1[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
- }
- //剩下的直接放在临时数组
- while (p1 <= Mid)
- {
- arr1[i++] = arr[p1++];
- }
- while (p2 <= R)
- {
- arr1[i++] = arr[p2++];
- }
- //将有序数组拷贝回原数组
- for (i = 0; i < R - L + 1; i++)
- {
- arr[L + i] = arr1[i];
- }
- delete [] arr1;
- }
- void process(int arr[], int L, int R)
- {
- if (L == R)
- {
- return;
- }
- int mid = L + ((R - L) >> 1);
- process(arr, L, mid);
- process(arr, mid + 1, R);
- merge(arr, L, mid, R);
- }
- void merge_sort(int arr[], int length)
- {
- return process(arr, 0, length - 1);
- }
- int main()
- {
- int arr[10] = { 5, 4, 6, 2, 1, 3, 7, 8, 9, 10 };
- merge_sort(arr, 10);
- for (int i = 0; i < 10; i++)
- {
- printf("%d ", arr[i]);
- }
- system("pause");
- return 0;
- }
归并排序符合master公式,整个排序的时间复杂度为O(N*logN)
思考:为什么冒泡排序和插入等算法时间复杂度为O(N^2)?他们差在哪里
因为他们浪费大量的比较行为,冒牌排序等O(N^2)的算法在0 - N -1 范围的比较只确定了一个数的位置,而归并排序并没有浪费比较行为,归并的时候两个指针将信息通过空间传递下来了,变成了一个整体有序的部分,然后通过递归,整体有序的部分不断变成更大的整体有序的部分,所以归并排序算法做到了时间复杂度为O(N*logN)。
归并排序的扩展
小和问题和逆序对问题
小和问题
在一个数组中,每一个数左边比当前数小的数累加起来,叫做这个数组的小和。求一个数组的小和。
例子:[1,3,4,2,5]1左边比1小的数,没有;3左边比3小的数,1;4左边比4小的数,1、3;2左边比2小的数,1;5左边比5小的数,1、3、4、2;所以小和等于1+1+3+1+1+3+4+2=16
暴力求解:每到数组一个位置,遍历比较前面的数字求和,时间复杂度为O(N^2)
利用归并排序:小和问题不妨转化思路,找左边比当前数小,等价于找右边有多少个数比当前数大,例如上述例子1的右边有四个数比1大,就会产生4个1;3的右边有两个数比3大,就会产生2个3;4的右边有一个数比4大;就会产生1个4;2的右边有一个数比2大,就会产生一个2;5的右边没有数比他大,就不会产生5;所以小和等于4*1+2*3+1*4+1*2=16;这个过程在归并排序的时候可以直接使用,具体代码如下:
- int merge(int arr[], int l, int mid, int r)
- {
- //与归并排序的不同是求小和当指针指向的元素相等的时候,先拷贝右边的元素
- int* help = new int[r - l + 1];
- int i = 0;
- int p1 = l;
- int p2 = mid + 1;
- int res = 0;
- while(p1 <= mid && p2 <= r)
- {
- res += arr[p1] < arr[p2] ? (r - p2 + 1) * arr[p1] : 0;
- help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
- }
- while (p1 <= mid)
- {
- help[i++] = arr[p1++];
- }
- while (p2 <= r)
- {
- help[i++] = arr[p2++];
- }
- //将排好序的数组拷贝回原数组
- for (i = 0; i < r - l + 1; i++)
- {
- arr[l + i] = help[i];
- }
- delete[] help;
- return res;
- }
- //归并的过程既要排序也要求小和
- int process(int arr[], int l, int r)
- {
- if (l == r)
- {
- return 0;
- }
- //求中点,写成这个形式是防止整形溢出的情况
- int mid = l + ((r - l) >> 1);
- return process(arr, l, mid)
- + process(arr, mid + 1, r)
- + merge(arr, l, mid, r);
- }
- int smallSum(int arr[], int length)
- {
- if (arr == NULL || length < 2)
- {
- return 0;
- }
- return process(arr, 0, length - 1);
- }
- int main()
- {
- int arr[5] = { 1, 3, 4, 2, 5 };
- int res = smallSum(arr, 5);
- cout << "res = " << res << endl;
- system("pause");
- return 0;
- }
逆序对问题
在一个数组中,左边的数如果比右边的数大,则这两个数构成一个逆序对,请找到逆序对的数量
- class Solution {
- public:
- int reversePairs(vector<int>& nums) {
- //归并实现逆序对
- if(nums.size() < 2)
- {
- return 0;
- }
- return mergeSort(nums, 0, nums.size() - 1);
- }
- private:
- int mergeSort(vector<int>& nums, int L, int R)
- {
- if(L == R)
- {
- return 0;
- }
- int mid = L + ((R - L)>>1);
- return mergeSort(nums, L, mid)
- + mergeSort(nums, mid + 1, R)
- + merge(nums, L, mid, R);
- }
- int merge(vector<int>& nums, int L, int mid, int R)
- {
- //准备一个临时数组
- int* help = new int[R - L + 1];
- int i = 0;
- int p1 = L;
- int p2 = mid + 1;
- int res = 0;
- while(p1 <= mid && p2 <= R)
- {
- if(nums[p1] <= nums[p2])
- {
- help[i++] = nums[p1++];
- }
- else
- {
- help[i++] = nums[p2++];
- res += mid - p1 + 1;
- }
- }
- while(p1 <= mid)
- {
- help[i++] = nums[p1++];
- }
- while(p2 <= R)
- {
- help[i++] = nums[p2++];
- }
- //将排序完的数组拷贝回原数组
- for(int i = 0; i < R - L + 1; i++)
- {
- nums[L + i] = help[i];
- }
- delete[] help;
- return res;
- }
- };
三、荷兰国旗问题
1、问题1
给定一个数组arr,和一个数num,请把小于等于num的数放在数组的左边,大于num的数放在数组
的右边。要求额外空间复杂度0(1),时间复杂度0(N)
2、问题2(荷兰国旗问题)
给定一个数组arr,和一个数num,请把小于num的数放在数组的左边,等于num的数放在数组的中
间,大于num的数放在数组的右边。要求额外空间复杂度0(1),时间复杂度0(N)
3、利用荷兰国旗问题优化快排
优化1
快排基础版本和问题1类似,选择最后一个数作为基准,把数组划分为两个区域,一个大于区,一个小于区,最后将该数与大于区第一个交换,然后你所选取的该数就在整个数组中已经排好序了,最后利用递归分别对大于区和小于区进行排序,但是本质上一次排序只搞定了确定大于区和小于区和确定一个数的位置,利用荷兰国旗问题,可以搞定一堆等于该数据的数的位置,所以比普通快排速度更快更优,但是普通快排和优化后的快排的时间复杂度都是0(N^2),因为如果数组是[1,2,3,4,5,6,7,8,9],就会遇到最坏情况,因为划分值太偏了,所以可以继续优化
优化2
因为选取数据的问题,就有可能人为制造出最差情况,不妨随机选一个数,然后让你选取的数与数组最后一个数交换位置,然后利用优化1版本再去快排。这样出来的时间复杂度为O(N*logN),为什么是O(N^2)呢,不妨假设你选取的数据在1/5,2/5,3/5...位置,这些数据出现的概率都是等概率时间,根据master公式可以分别计算出每一个位置的时间复杂度,然后通过概率时间相加对概率求数学期望求出时间复杂度为O(N*logN),具体证明比较复杂,就不写上。直接看优化代码如下:
四、堆排序
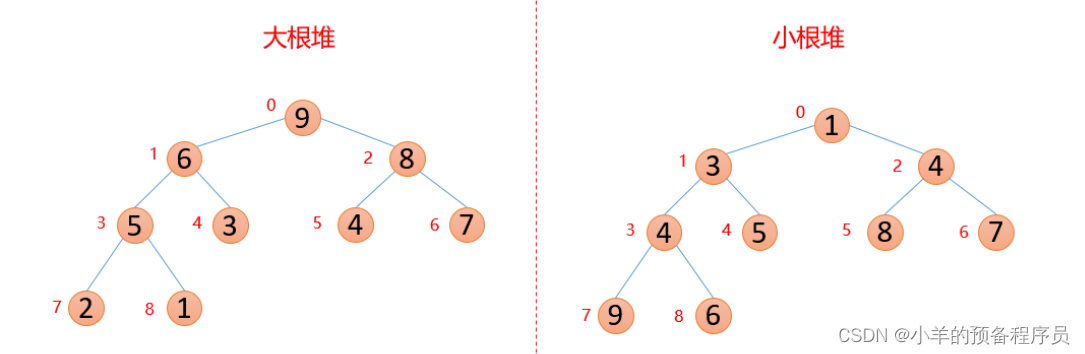
堆的结构可以分为大根堆和小根堆,是一个完全二叉树,而堆排序是根据堆的这种数据结构设计的一种排序,下面先来看看什么是大根堆和小根堆
1、大根堆和小根堆
性质:每个结点的值都大于其左孩子和右孩子结点的值,称之为大根堆;每个结点的值都小于其左孩子和右孩子结点的值,称之为小根堆。如下图
还有一个基本概念:查找数组中某个数的父结点和左右孩子结点,比如已知索引为i的数,那么
1.父结点索引:(i-1)/2(这里计算机中的除以2,省略掉小数)
2.左孩子索引:2*i+1
3.右孩子索引:2*i+2
2、基本思想
1.首先将待排序的数组构造成一个大根堆,此时,整个数组的最大值就是堆结构的顶端
2.将顶端的数与末尾的数交换,此时,末尾的数为最大值,剩余待排序数组个数为n-1
3.将剩余的n-1个数再构造成大根堆,再将顶端数与n-1位置的数交换,如此反复执行,便能得到有序数组
代码实现如下:
- void swap(int arr[], int pos1, int pos2)
- {
- int temp = arr[pos1];
- arr[pos1] = arr[pos2];
- arr[pos2] = temp;
- }
- //某个数在index位置,能否往上移动
- void heapInsert(int arr[], int index)
- {
- while (arr[index] > arr[(index - 1) / 2])
- {
- swap(arr, index, (index - 1) / 2);
- index = (index - 1) / 2;
- }
- }
- //某数在index位置,能否往下移动
- void heapify(int arr[], int index, int heapSize)
- {
- int left = index * 2 + 1;//左孩子下标
- while (left < heapSize)
- {
- //下方还有孩子的时候
- //两个孩子中,谁的值大,把下标给largest
- int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
- //父和孩子之间,谁的值最大,把下标给largest
- largest = arr[largest] > arr[index] ? largest : index;
- if (largest == index)
- {
- break;
- }
- swap(arr, largest, index);
- index = largest;
- left = index * 2 + 1;
- }
- }
- void heapSort(int arr[], int length)
- {
- if (arr == NULL && length < 2)
- {
- return;
- }
- for (int i = 0; i < length; i++)
- {
- heapInsert(arr, i);//O(logN)
- }
- int heapSize = length;
- swap(arr, 0, --heapSize);
- while (heapSize > 0)
- {
- //O(N)
- heapify(arr, 0, heapSize);//O(logN)
- swap(arr, 0, --heapSize);//O(1)
- }
- }
- int main()
- {
- int arr[10] = { 1, 2, 4, 5, 7, 8, 3, 9, 10, 6 };
- heapSort(arr, 10);
- for (int i = 0; i < 10; i++)
- {
- printf("%d ", arr[i]);
- }
- system("pause");
- return 0;
- }
-
相关阅读:
[黑马程序员SpringBoot2]——基础篇1
mybatis-plus使用BaseTypeHandler实现数据库字段加密
国际结算名词解释
2023 ICCV和 CVPR论文集合
Cobbler
项目经理如何进行项目汇报才能让项目顺利进行,让领导一看就喜欢?
同花顺_代码解析_技术指标_M
SpringBoot集成Mybatis——基于SpringBoot和Vue的后台管理系统项目系列博客(五)
RabbitMQ初步到精通-第四章-RabbitMQ工作模式-PUB/SUB
MySQL高级篇知识点——索引优化与查询优化
- 原文地址:https://blog.csdn.net/qq_51654808/article/details/126055410
