-
【论文阅读】Distilling the Knowledge in a Neural Network
论文原地址:http://arxiv.org/abs/1503.02531
这篇文章是Hinton在2015发表的文章,是知识蒸馏(knowledge distillation)的开山之作。
知识蒸馏是一种教师-学生模型(Teacher-Student Model),其核心思想是,将复杂模型(教师模型)中的知识转移到一个简单模型(学生模型)中,使学生模型拥有能够媲美教师模型准确率的能力。1介绍
背景
机器学习的实际应用中分为两步,模型训练和部署。
在机器学习中,我们倾向于使用非常相似的模型进行训练(train)和部署(depolyment),尽管这两个阶段显然有不同的需求:
在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去(受限于推理速度,资源设备)暗知识
soft target和hard target
这里有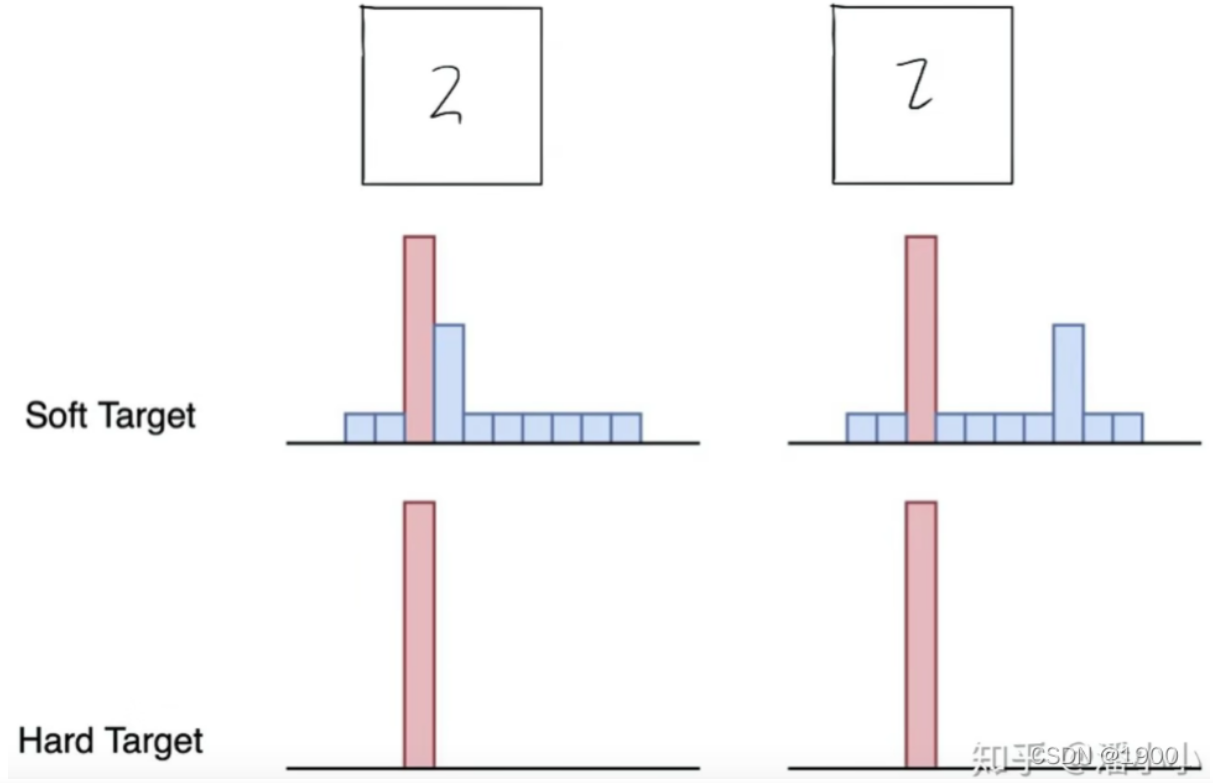
soft target的输出信息量要大于hard target的信息量。
例如这里的手写数字2,它的标签就是2,也就是说这个数字是2的概率为1,是其他数字的概率为0,我们把这种标签就称作hard targets。(后面也称真实标签,标记,ground truth)
但是对于soft target,此时2的概率最高,3的概率次之,其他相同,则我们可以知道错认为3会比错认为其他有更大的可能。这可能是因为3与2之间有跟多的相似之处值得注意的是 对于Mnist数据集中总是产生具有信心的正确结果,很多非正确数字的概率都是非常小的。例如,对于正确的2来说,被分类为3的概率为 1 0 − 6 10^{-6} 10−6 ,被分类为7的概率为 1 0 − 9 10^{-9} 10−9 。在这种情况下soft target的帮助就很小,所以Caruana在其文章中使用log函数解决这一问题。本文利用蒸馏解决这个问题(蒸馏会使得target变得更加平滑)
蒸馏温度T
原softmax公式:
q i = e x p ( z i ) ∑ j e x p ( z j ) q_{i}=\frac {exp({z_i})}{\sum_jexp(z_j)} qi=∑jexp(zj)exp(zi)加入温度系数T后的公式:
q i = e x p ( z i / T ) ∑ j e x p ( z j / T ) q_{i}=\frac {exp({z_i}/{T})}{\sum_jexp(z_j/T)} qi=∑jexp(zj/T)exp(zi/T)
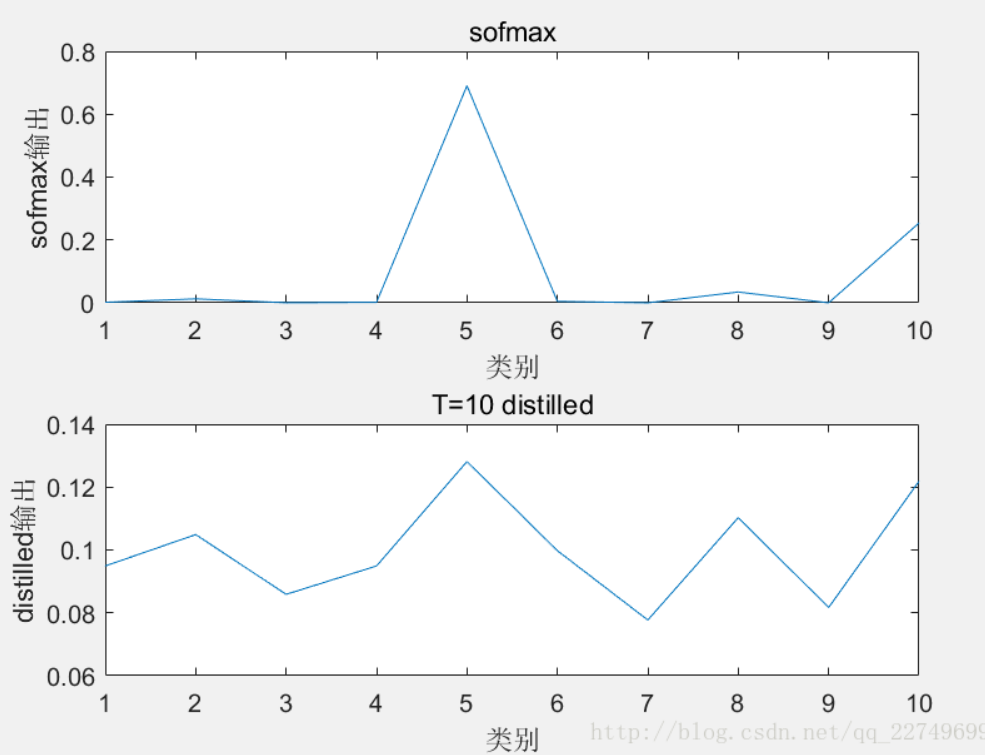
在加入T之后的softmax的概率分布更加平滑,作为soft target时简易(student)网络能学到更多东西。
步骤
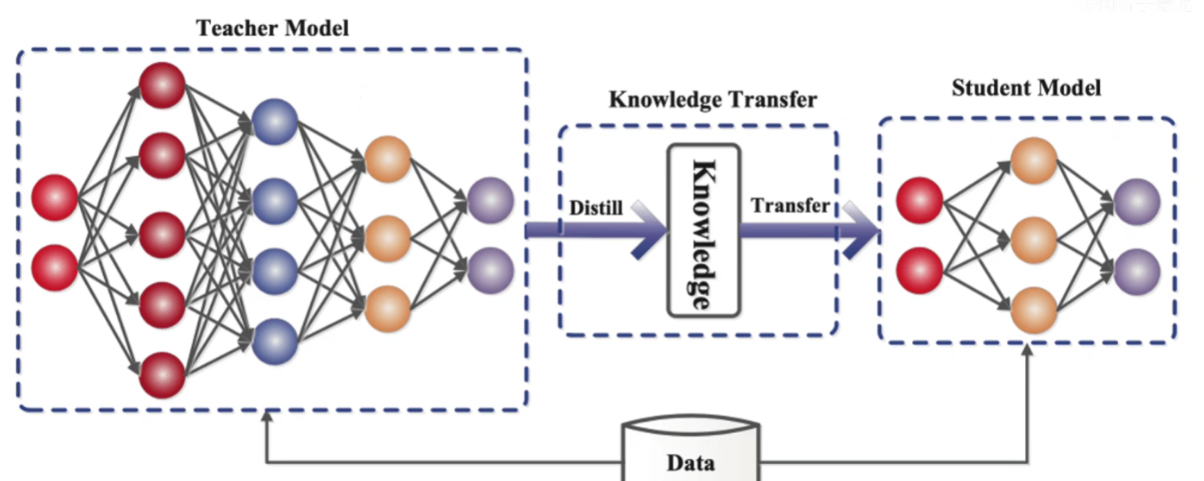
1.教师模型的训练,这一步通过带有标签的数据集对复杂模型进行训练。最终我们得到了一个已经训练好的教师网络。
2.通过教师模型对学生模型的训练,这里我们就引入了超参数T改进后的Softmax函数
3.学生模型单独做预测
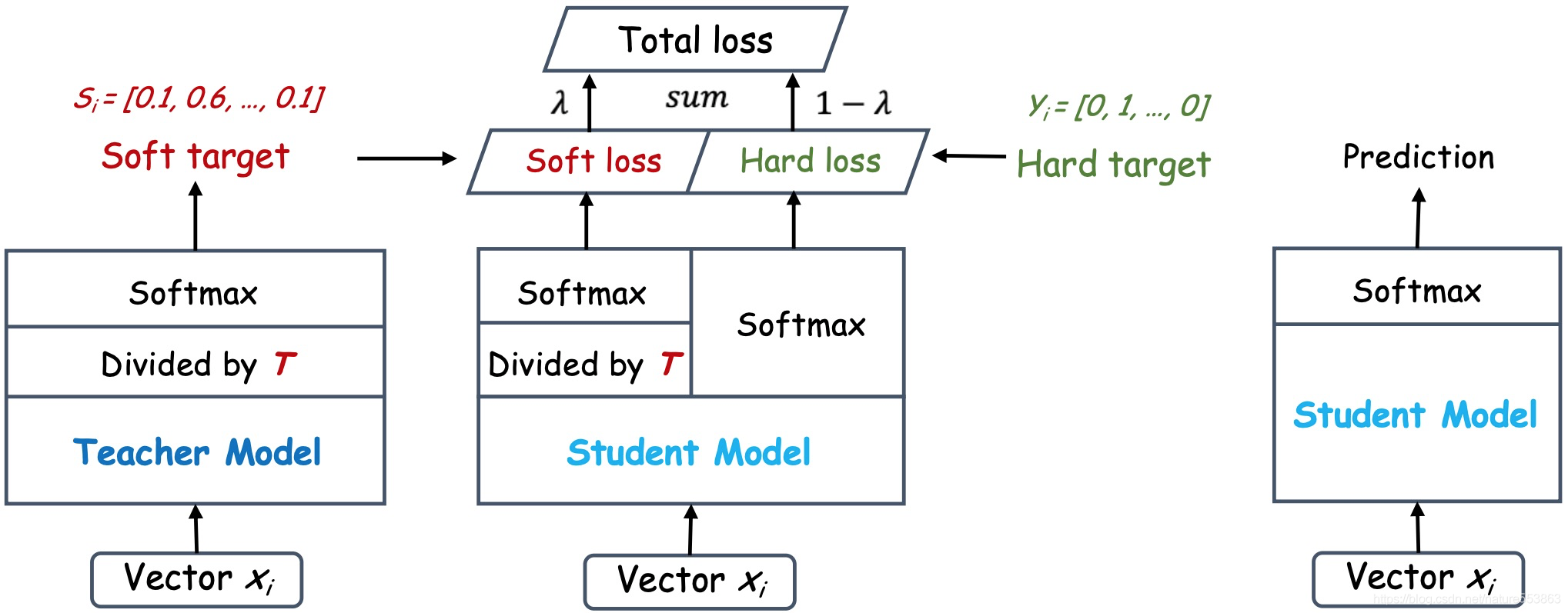
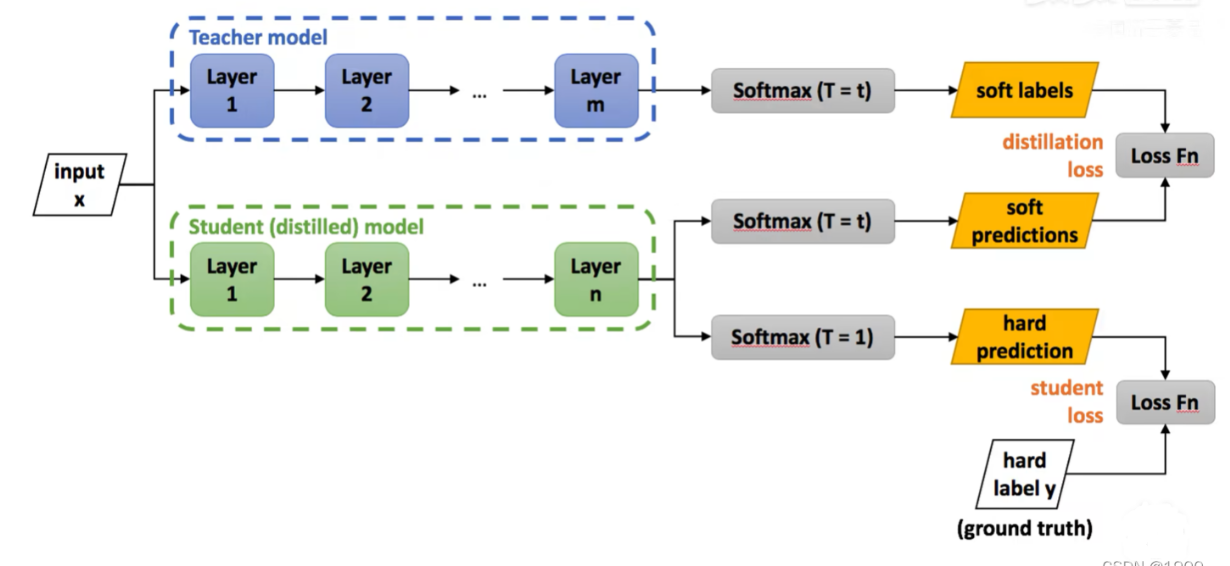
具体来说,
①在将大模型生成的logits送入输出层softmax之前,除以一个比较大的值T=
t,得到更加平滑的概率分布作为soft target(软目标、软标签)。这个概率分布在0~1之间,取值分布缓和tip:T数值越大,分布越缓和;而T数值减小,容易放大错误分类的概率, 引入不必要的噪声。针对较困难的分类或检测任务,T通常取1, 确保教师网络中正确预测的贡献。- 1
- 2
- 3
②学生模型会有两个softmax函数,一个T=t,一个T=1。
学生模型经过T=t的softmax函数后会产生soft prediction,此时soft target和soft prediction计算交叉熵损失,这个损失称为蒸馏损失(distillation loss)。通过其来减小soft target和soft prediction之间的差别。
学生模型经过T=1的softmax函数后产生的hard prediction与硬目标hard target
计算交叉熵损失,这个损失称为学生损失(student loss),这个就是传统的损失计算。 这里的硬目标则是样本的真实标注,可以用One-hot矢量表示。总损失Total loss设计为软目标与硬目标所对应的交叉熵的加权平均,公式如下
L o s s = λ L s + ( 1 − λ ) L h Loss=λL_{s}+(1−λ)L_{h} Loss=λLs+(1−λ)Lh
其中, L s L_{s} Ls表示蒸馏损失, L h L_{h} Lh表示蒸馏损失, λ表示系数,软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,通常初始Ls权重更高,之后慢慢减小这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。
作用:
蒸馏损失:保证小模型和大模型的结果一致性
学生损失:保证小模型的结果与实际类别标签一致性参考
Distilling the Knowledge in a Neural Network[论文阅读笔记]
如何理解soft target这一做法?
【知识蒸馏】Distilling the Knowledge in a Neural Network
【论文阅读】Distilling the Knowledge in a Neural Network -
相关阅读:
基于SqlSugar的开发框架循序渐进介绍(20)-- 在基于UniApp+Vue的移动端实现多条件查询的处理
MapStructPlus 1.4.0 发布,体积更轻量!性能更强!
Mysql5.7二级等保配置项示例
【云原生】Docker镜像、容器、仓库、配置等常见问题汇总(面试必看)
SpringSecurity系列 - 10 传统Web项目表单认证: UsernamePasswordAuthenticationFilter 过滤器
解决 Vue3 + Element Plus 树形表格全选多选以及子节点勾选的问题
RK3399 Android7.1电脑端adb devices检测不到设备
docker学习-1CentOS安装Docker CE
机器学习-特征选择:如何使用交叉验证精准选择最优特征?
ClickHouse 学习之基础入门(一)
- 原文地址:https://blog.csdn.net/weixin_45592399/article/details/125990939