-
kubernetes之服务发现

目录
文章目录
1、服务发现
上面我们讲解了 Service 的用法,我们可以通过 Service 生成的 ClusterIP(VIP) 来访问 Pod 提供的服务。但是在使用的时候还有一个问题:我们怎么知道某个应用的 VIP 呢?比如我们有两个应用,一个是 api 应用,一个是 db 应用,两个应用都是通过 Deployment 进行管理的,并且都通过 Service 暴露出了端口提供服务。api 需要连接到 db 这个应用,我们只知道 db 应用的名称和 db 对应的 Service 的名称,但是并不知道它的 VIP 地址,我们前面的 Service 课程中是不是学习到我们通过 ClusterIP 就可以访问到后面的 Pod 服务,如果我们知道了 VIP 的地址是不是就行了?
⚠️ 注意:在实际工作应用中,我们很少去把访问地址用ip固定下来。我们要解决这种问题,一般有2种方法。
第一种:环境变量。
第二种:DNS。1.环境变量
为了解决上面的问题,在之前的版本中,Kubernetes 采用了环境变量的方法,每个 Pod 启动的时候,会通过环境变量设置所有服务的 IP 和 port 信息,这样 Pod 中的应用可以通过读取环境变量来获取依赖服务的地址信息,这种方法使用起来相对简单,但是有一个很大的问题就是依赖的服务必须在 Pod 启动之前就存在,不然是不会被注入到环境变量中的。
💘 实战:环境变量测试(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
无
1.部署Deployment,service资源
- 比如我们首先创建一个 Nginx 服务:(test-nginx.yaml)
[root@master1 ~]#vim test-nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service labels: name: nginx-service spec: ports: - port: 5000 targetPort: 80 selector: app: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 创建上面的服务并查看:
[root@master1 ~]#kubectl apply -f test-nginx.yaml deployment.apps/nginx-deploy created service/nginx-service created [root@master1 ~]#kubectl get po,deploy,svc -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/nginx-deploy-5d59d67564-7bzf7 1/1 Running 0 51s 10.244.2.210 node2 <none> <none> pod/nginx-deploy-5d59d67564-rdglk 1/1 Running 0 51s 10.244.1.89 node1 <none> <none> NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/nginx-deploy 2/2 2 2 51s nginx nginx:1.7.9 app=nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 42d <none> service/nginx-service ClusterIP 10.105.30.147 <none> 5000/TCP 51s app=nginx [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们可以看到两个 Pod 和一个名为 nginx-service 的服务创建成功了,该 Service 监听的端口是 5000,同时它会把流量转发给它代理的所有 Pod(我们这里就是拥有
app: nginx标签的两个 Pod)。2.部署一个普通pod
- 现在我们再来创建一个普通的 Pod,观察下该 Pod 中的环境变量是否包含上面的
nginx-service的服务信息:(test-pod.yaml)
[root@master1 ~]#vim test-pod.yaml
apiVersion: v1 kind: Pod metadata: name: test-pod spec: containers: - name: test-service-pod image: busybox:1.28.3 command: ["/bin/sh", "-c", "env"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 然后创建该测试的 Pod:
[root@master1 ~]#kubectl apply -f test-pod.yaml pod/test-pod created- 1
- 2
3.测试
- 等 Pod 创建完成后,我们查看日志信息:
[root@master1 ~]#kubectl logs test-pod KUBERNETES_PORT=tcp://10.96.0.1:443 KUBERNETES_SERVICE_PORT=443 HOSTNAME=test-pod SHLVL=1 HOME=/root NGINX_SERVICE_PORT_5000_TCP_ADDR=10.105.30.147 NGINX_SERVICE_PORT_5000_TCP_PORT=5000 NGINX_SERVICE_PORT_5000_TCP_PROTO=tcp KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin NGINX_SERVICE_SERVICE_HOST=10.105.30.147 NGINX_SERVICE_PORT_5000_TCP=tcp://10.105.30.147:5000 KUBERNETES_PORT_443_TCP_PORT=443 KUBERNETES_PORT_443_TCP_PROTO=tcp NGINX_SERVICE_SERVICE_PORT=5000 NGINX_SERVICE_PORT=tcp://10.105.30.147:5000 KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443 KUBERNETES_SERVICE_PORT_HTTPS=443 KUBERNETES_SERVICE_HOST=10.96.0.1 PWD=/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们可以看到打印了很多环境变量信息,其中就包括我们刚刚创建的 nginx-service 这个服务,有 HOST、PORT、PROTO、ADDR 等,也包括其他已经存在的 Service 的环境变量。现在如果我们需要在这个 Pod 里面访问 nginx-service 的服务,我们是不是可以直接通过
NGINX_SERVICE_SERVICE_HOST和NGINX_SERVICE_SERVICE_PORT就可以了。但是如果这个 Pod 启动起来的时候 nginx-service 服务还没启动起来,在环境变量中我们是无法获取到这些信息的。当然我们可以通过initContainer之类的方法来确保 nginx-service 启动后再启动 Pod,但是这种方法毕竟增加了 Pod 启动的复杂性,所以这不是最优的方法,局限性太多了。⚠️ 注意:kubernetes这个service这个是谁创建的?
[root@master1 ~]#kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 42d nginx-service ClusterIP 10.98.166.23 <none> 5000/TCP 5m57s- 1
- 2
- 3
- 4
这个
kubernetes主服务(service)是系统自己创建的,这个service是必须要有的,不能随便被删除的。相当与是我们集群内部的一些应用,他们要通过这个service去访问apiserver,这个其实就是去关联到我们的apiserver而已。我们可以去describe看下:
[root@master1 ~]#kubectl describe svc kubernetes Name: kubernetes Namespace: default Labels: component=apiserver provider=kubernetes Annotations: <none> Selector: <none> Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.96.0.1 IPs: 10.96.0.1 Port: https 443/TCP TargetPort: 6443/TCP Endpoints: 172.29.9.51:6443 #care Session Affinity: None Events: <none>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
可以看到这里的Endpoints,其实就是到我们的apiserver那里去的。
其实就是给我们集群内部的一些pod去使用这个apiserver的,因为一般来说 我们不太可能在集群内部去写上这个
172.29.9.51:6443地址。实验结束。😘
2.DNS
由于上面环境变量这种方式的局限性,我们需要一种更加智能的方案,其实我们可以自己思考一种比较理想的方案:那就是可以直接使用 Service 的名称,因为 Service 的名称不会变化(我们当然不会在线上随意更改这个名称了哈哈🤣),我们不需要去关心分配的 ClusterIP 的地址,因为这个地址并不是固定不变的,所以如果我们直接使用 Service 的名字,然后对应的 ClusterIP 地址的转换能够自动完成就很好了。我们知道名字和 IP 直接的转换是不是和我们平时访问的网站非常类似啊?他们之间的转换功能通过 DNS 就可以解决了,同样的,Kubernetes 也提供了 DNS 的方案来解决上面的服务发现的问题。
DNS 服务不是一个独立的系统服务,而是作为一种 addon 插件而存在,现在比较推荐的两个插件:kube-dns 和 CoreDNS,实际上在比较新点的版本中已经默认是 CoreDNS 了,因为 kube-dns 默认一个 Pod 中需要3个容器配合使用,CoreDNS 只需要一个容器即可,我们在前面使用 kubeadm 搭建集群的时候直接安装的就是 CoreDNS 插件:
[root@master1 ~]#kubectl get po -A -l k8s-app=kube-dns -owide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system coredns-7568f67dbd-2ztgw 1/1 Running 1 (8d ago) 17d 10.244.0.9 master1 <none> <none> kube-system coredns-7568f67dbd-9dls5 1/1 Running 1 (8d ago) 38d 10.244.0.8 master1 <none> <none> # 注意:这2个pod都是被调度到master节点上的,为啥呢??- 1
- 2
- 3
- 4
- 5
- 6
CoreDns 是用 GO 写的高性能,高扩展性的 DNS 服务,基于 HTTP/2 Web 服务 Caddy 进行编写的。CoreDns 内部采用插件机制,所有功能都是插件形式编写,用户也可以扩展自己的插件,以下是 Kubernetes 部署 CoreDns 时的默认配置:
➜ ~ kubectl get cm coredns -n kube-system -o yaml apiVersion: v1 data: Corefile: | #注意:你可以认为,下面{}里的每一行相当于一个插件!!! .:53 { errors # 启用错误记录 health # 启用健康检查检查端点,8080:health ready kubernetes cluster.local in-addr.arpa ip6.arpa { # 处理 k8s 域名解析 pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 # 启用 metrics 指标,9153:metrics forward . /etc/resolv.conf # 通过 resolv.conf 内的 nameservers 解析 cache 30 # 启用缓存,所有内容限制为 30s 的TTL (all的解析都有一个缓存的) loop # 检查简单的转发循环并停止服务 reload # 运行自动重新加载 corefile,热更新 loadbalance # 负载均衡,默认 round_robin } kind: ConfigMap metadata: creationTimestamp: "2019-11-08T11:59:49Z" name: coredns namespace: kube-system resourceVersion: "188" selfLink: /api/v1/namespaces/kube-system/configmaps/coredns uid: 21966186-c2d9-467a-b87f-d061c5c9e4d7- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
每个
{}代表一个 zone,格式是“Zone:port{}”, 其中"."代表默认zone -
{}内的每个名称代表插件的名称,只有配置的插件才会启用,当解析域名时,会先匹配 zone(都未匹配会执行默认 zone),然后 zone 内的插件从上到下依次执行(这个顺序并不是配置文件内谁在前面的顺序,而是core/dnsserver/zdirectives.go内的顺序),匹配后返回处理(执行过的插件从下到上依次处理返回逻辑),不再执行下一个插件
CoreDNS 的 Service 地址一般情况下是固定的,类似于 kubernetes 这个 Service 地址一般就是第一个 IP 地址
10.96.0.1,CoreDNS 的 Service 地址就是10.96.0.10。该 IP 被分配后,kubelet 会将使用--cluster-dns=参数配置的 DNS 传递给每个容器。DNS 名称也需要域名,本地域可以使用参数--cluster-domain =在 kubelet 中配置:➜ ~ cat /var/lib/kubelet/config.yaml ...... clusterDNS: - 10.96.0.10 clusterDomain: cluster.local #当然,这个可以改,但一般是不会去修改的,是约定俗成的。 ......- 1
- 2
- 3
- 4
- 5
- 6
⚠️注意:这里的解释如下。(这里的2点有点晦涩)
注意点1:
当我们去启动一个容器的时候,它会把这里的
clusterDNS地址给写入到我们容器的nameserver里面去,那么当我们容器里面的namesrver是这个地址,然后去做域名解析的时候,是不是都会进入到这个10.96.0.10里面去,而这个地址刚好是我们core dns的地址。所以最终解析,还是进入到这个coredns里面来做的。[root@master1 ~]#kubectl get svc -nkube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 49d metrics-server ClusterIP 10.106.125.106 <none> 443/TCP 27d- 1
- 2
- 3
- 4
注意点2:
文件
/var/lib/kubelet/config.yaml里的clusterDomain: cluster.local就相当于在我们k8s集群里面,就是我们service的一个域名后缀。all的以dns的形式访问service的时候,它的一个后缀都是cluster.local。我们前面说了如果我们建立的 Service 如果支持域名形式进行解析,就可以解决我们的服务发现的功能,那么利用 kubedns 可以将 Service 生成怎样的 DNS 记录呢?
-
普通的 Service:会生成
servicename.namespace.svc.cluster.local的域名,会解析到 Service 对应的 ClusterIP 上,在 Pod 之间的调用可以简写成servicename.namespace,如果处于同一个命名空间下面,甚至可以只写成servicename即可访问😘假如说我们有个svc叫做nginx-service: 那么,该service在dns里的域名可以按如下来写: nginx-service.default.svc.cluster.local nginx-service.default.svc nginx-service.default 如果你的Pod和nigx-service在同一个namesapce,也可以写成nginx-service- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
Headless Service:无头服务,就是把 clusterIP 设置为 None 的,会被解析为指定 Pod 的 IP 列表,同样还可以通过
podname.servicename.namespace.svc.cluster.local访问到具体的某一个 Pod。
💘 实战:coredns测试(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
无
1.部署一个测试pod
接下来我们来使用一个简单 Pod 来测试下 Service 的域名访问:
[root@master1 ~]#kubectl run -it --image busybox:1.28.3 test-dns --restart=Never --rm /bin/sh #这个--rm:退出后删除的意思 If you don't see a command prompt, try pressing enter. / # cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5 / #- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.测试
我们进入到 Pod 中,查看
/etc/resolv.conf中的内容,可以看到nameserver的地址10.96.0.10,该 IP 地址即是在安装 CoreDNS 插件的时候集群分配的一个固定的静态 IP 地址,我们可以通过下面的命令进行查看:[root@master1 ~]#kubectl get svc -nkube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 50d metrics-server ClusterIP 10.106.125.106 <none> 443/TCP 28d- 1
- 2
- 3
- 4
也就是说我们这个 Pod 现在默认的
nameserver就是kube-dns的地址。- 现在我们来访问下前面我们创建的 nginx-service 服务:
/ # wget -q -O- nginx-service.default.svc.cluster.local- 1
可以看到上面我们使用 wget 命令去访问 nginx-service 服务的域名的时候被 hang 住了,没有得到期望的结果,这是因为上面我们建立 Service 的时候暴露的端口是 5000:
- 加上端口后再次测试:
/ # wget -q -O- nginx-service.default.svc.cluster.local:5000 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> / #- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
加上 5000 端口,就正常访问到服务,再试一试访问:
nginx-service.default.svc、nginx-service.default、nginx-service,不出意外这些域名都可以正常访问到期望的结果。到这里我们是不是就实现了在集群内部通过 Service 的域名形式进行互相通信了,大家下去试着看看访问不同 namespace 下面的服务呢?
测试结束。😋
⚠️ 注意:我这里的现象和老师的有些不同:测试过程如下
不加Port直接会报错的,但老师当时是直接卡主了的。。。
/ # wget -q -O- nginx-service.default.svc.cluster.local wget: can't connect to remote host (10.98.166.23): Connection refused- 1
- 2
- 测试域名:
#nslookup测试域名 / # nslookup nginx-service.default.svc.cluster.local Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: nginx-service.default.svc.cluster.local Address 1: 10.98.166.23 nginx-service.default.svc.cluster.local / # nslookup nginx-service.default.svc Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: nginx-service.default.svc Address 1: 10.98.166.23 nginx-service.default.svc.cluster.local / # nslookup nslookup nginx-service.default Server: 10.98.166.23 Address 1: 10.98.166.23 / # nslookup nginx-service.default Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: nginx-service.default Address 1: 10.98.166.23 nginx-service.default.svc.cluster.local / # nslookup nginx-service Server: 10.96.0.10 Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local Name: nginx-service Address 1: 10.98.166.23 nginx-service.default.svc.cluster.local #或使用ping测试: / # ping nginx-service PING nginx-service (10.98.166.23): 56 data bytes 64 bytes from 10.98.166.23: seq=0 ttl=64 time=0.134 ms 64 bytes from 10.98.166.23: seq=1 ttl=64 time=0.141 ms ^C --- nginx-service ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.134/0.137/0.141 ms / # ping nginx-service.default PING nginx-service.default (10.98.166.23): 56 data bytes 64 bytes from 10.98.166.23: seq=0 ttl=64 time=0.101 ms ^C --- nginx-service.default ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.101/0.101/0.101 ms / # ping nginx-service.default.svc PING nginx-service.default.svc (10.98.166.23): 56 data bytes 64 bytes from 10.98.166.23: seq=0 ttl=64 time=0.108 ms ^C --- nginx-service.default.svc ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.108/0.108/0.108 ms / # ping nginx-service.default.svc.cluster.local PING nginx-service.default.svc.cluster.local (10.98.166.23): 56 data bytes 64 bytes from 10.98.166.23: seq=0 ttl=64 time=0.146 ms ^C --- nginx-service.default.svc.cluster.local ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.146/0.146/0.146 ms / #- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 当然在节点直接测试也是没问题的:
[root@master1 ~]#kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 50d nginx-service ClusterIP 10.98.166.23 <none> 5000/TCP 8d [root@master1 ~]#curl 10.98.166.23:5000 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
实验结束。😘
2、Pod 添加 DNS 记录
我们都知道 StatefulSet 中的 Pod 是拥有单独的 DNS 记录的,比如一个 StatefulSet 名称为 etcd,而它关联的 Headless SVC 名称为 etcd-headless,那么 CoreDNS 就会为它的每个 Pod 解析如下的记录:
etcd-0.etcd-headless.default.svc.cluster.local etcd-1.etcd-headless.default.svc.cluster.local ......- 1
- 2
- 3
那么除了 StatefulSet 管理的 Pod 之外,其他的 Pod 是否也可以生成 DNS 记录呢?
如下所示,我们这里只有一个 Headless 的 SVC,并没有 StatefulSet 管理的 Pod,而是 ReplicaSet 管理的 Pod,我们可以看到貌似也生成了类似于 StatefulSet 中的解析记录。
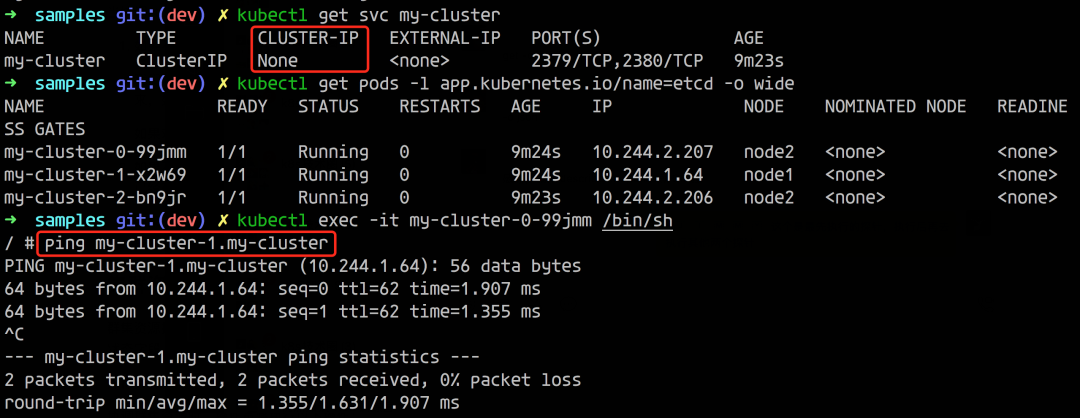
这是怎么做到的呢?按照我们常规的理解会认为这是一个 StatefulSet 管理的 Pod,但其实这里是不同的 ReplicaSet 而已。这里的实现其实是因为 Pod 自己本身也是可以有自己的 DNS 记录的,所以我们是可以去实现一个类似于 StatefulSet 的 Pod 那样的解析记录的。
💘 实战:给 Pod 添加 DNS 记录(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
无
1.部署Deployment 资源
首先我们来部署一个 Deployment 管理的普通应用,其定义如下:
[root@master1 ~]#vim nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
部署后创建了两个 Pod:
[root@master1 ~]#kubectl apply -f nginx.yaml deployment.apps/nginx created [root@master1 ~]#kubectl get po -l app=nginx -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-5d59d67564-lcjw8 1/1 Running 0 29s 10.244.2.215 node2 <none> <none> nginx-5d59d67564-nxnbv 1/1 Running 0 29s 10.244.2.216 node2 <none> <none>- 1
- 2
- 3
- 4
- 5
- 6
2.部署Headless Service资源
然后定义如下的 Headless Service:
[root@master1 ~]#vim service.yaml
apiVersion: v1 kind: Service metadata: name: nginx spec: clusterIP: None ports: - name: http port: 80 protocol: TCP selector: app: nginx type: ClusterIP- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
创建该 service:
[root@master1 ~]#kubectl apply -f service.yaml service/nginx created [root@master1 ~]#kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 51d nginx ClusterIP None <none> 80/TCP 10s- 1
- 2
- 3
- 4
- 5
- 6
3.尝试解析 service DNS
在宿主机上下安装下dig命令:
yum install -y bind-utils- 1
dig命令测试:
[root@master1 ~]#dig @10.96.0.10 nginx.default.svc.cluster.local ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.8 <<>> @10.96.0.10 nginx.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41513 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;nginx.default.svc.cluster.local. IN A ;; ANSWER SECTION: nginx.default.svc.cluster.local. 30 IN A 10.244.2.215 nginx.default.svc.cluster.local. 30 IN A 10.244.2.216 ;; Query time: 1 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Dec 21 19:43:55 CST 2021 ;; MSG SIZE rcvd: 154 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
然后我们对 nginx 的 FQDN 域名进行 dig 操作,可以看到返回了多条 A 记录,每一条对应一个 Pod。上面 dig 命令中使用的 10.96.0.10 就是 kube-dns 的 cluster IP,可以在 kube-system namespace 中查看:
[root@master1 ~]#kubectl get svc kube-dns -nkube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 51d- 1
- 2
- 3
4.在 service 名字前面加上 Pod 名字交给 kube-dns 做解析
接下来我们试试在 service 名字前面加上 Pod 名字交给 kube-dns 做解析:
[root@master1 ~]#dig @10.96.0.10 nginx-5d59d67564-lcjw8.nginx.default.svc.cluster.local ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.8 <<>> @10.96.0.10 nginx-5d59d67564-lcjw8.nginx.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 48912 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;nginx-5d59d67564-lcjw8.nginx.default.svc.cluster.local. IN A ;; AUTHORITY SECTION: cluster.local. 30 IN SOA ns.dns.cluster.local. hostmaster.cluster.local. 1640086465 7200 1800 86400 30 ;; Query time: 2 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Dec 21 19:47:33 CST 2021 ;; MSG SIZE rcvd: 176 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
可以看到并没有得到解析结果。
⚠️ 官方文档中有一段
Pod’s hostname and subdomain fields说明:1.Pod 规范中包含一个可选的 hostname 字段,可以用来指定 Pod 的主机名。当这个字段被设置时,它将优先于 Pod 的名字成为该 Pod 的主机名。举个例子,给定一个 hostname 设置为 “my-host” 的 Pod, 该 Pod 的主机名将被设置为 “my-host”。
2.Pod 规约还有一个可选的 subdomain 字段,可以用来指定 Pod 的子域名。举个例子,某 Pod 的 hostname 设置为 “foo”,subdomain 设置为 “bar”, 在名字空间 “my-namespace” 中对应的完全限定域名为 “foo.bar.my-namespace.svc.cluster-domain.example”。
5.编辑一下 nginx.yaml 并加上 subdomain 测试
现在我们编辑一下 nginx.yaml 加上 subdomain 测试下看看:
vim nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: subdomain: nginx containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
更新部署再尝试解析 Pod DNS:
[root@master1 ~]#kubectl apply -f nginx.yaml deployment.apps/nginx configured [root@master1 ~]#kubectl get po -l app=nginx -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-78f58d8bcb-498sp 1/1 Running 0 15s 10.244.1.91 node1 <none> <none> nginx-78f58d8bcb-4pfxk 1/1 Running 0 14s 10.244.2.217 node2 <none> <none> [root@master1 ~]#dig @10.96.0.10 nginx-78f58d8bcb-498sp.nginx.default.svc.cluster.local ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.8 <<>> @10.96.0.10 nginx-78f58d8bcb-498sp.nginx.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 12912 ;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;nginx-78f58d8bcb-498sp.nginx.default.svc.cluster.local. IN A ;; AUTHORITY SECTION: cluster.local. 30 IN SOA ns.dns.cluster.local. hostmaster.cluster.local. 1640088249 7200 1800 86400 30 ;; Query time: 0 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Dec 21 20:04:54 CST 2021 ;; MSG SIZE rcvd: 176 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
可以看到依然不能解析。
6.测试官方文档中的例子
那就试试官方文档中的例子 ,不用 Deployment 直接创建 Pod 吧。
[root@master1 ~]#vim individual-pods-example.yaml
# individual-pods-example.yaml apiVersion: v1 kind: Service metadata: name: default-subdomain spec: selector: name: busybox clusterIP: None ports: - name: foo # Actually, no port is needed. port: 1234 targetPort: 1234 --- apiVersion: v1 kind: Pod metadata: name: busybox1 labels: name: busybox spec: hostname: busybox-1 subdomain: default-subdomain containers: - image: busybox:1.28 command: - sleep - "3600" name: busybox --- apiVersion: v1 kind: Pod metadata: name: busybox2 labels: name: busybox spec: hostname: busybox-2 subdomain: default-subdomain containers: - image: busybox:1.28 command: - sleep - "3600" name: busybox- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 部署然后尝试解析 Pod DNS (注意这里 hostname 和 pod 的名字有区别,中间多了减号):
[root@master1 ~]#kubectl apply -f individual-pods-example.yaml service/default-subdomain created pod/busybox1 created pod/busybox2 created [root@master1 ~]#kubectl get po -l name=busybox -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES busybox1 1/1 Running 0 79s 10.244.2.218 node2 <none> <none> busybox2 1/1 Running 0 79s 10.244.1.92 node1 <none> <none> [root@master1 ~]#dig @10.96.0.10 busybox-1.default-subdomain.default.svc.cluster.local ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.8 <<>> @10.96.0.10 busybox-1.default-subdomain.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33058 ;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;busybox-1.default-subdomain.default.svc.cluster.local. IN A ;; ANSWER SECTION: busybox-1.default-subdomain.default.svc.cluster.local. 30 IN A 10.244.2.218 ;; Query time: 0 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Dec 21 20:10:23 CST 2021 ;; MSG SIZE rcvd: 151 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
现在我们看到有 ANSWER 记录回来了,hostname 和 subdomain 二者都必须显式指定,缺一不可。一开始我们的截图中的实现方式其实也是这种方式。
7.现在我们修改一下之前的 nginx deployment 加上 hostname,重新解析
[root@master1 ~]#vim nginx.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: subdomain: nginx hostname: nginx containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
[root@master1 ~]#kubectl apply -f nginx.yaml deployment.apps/nginx configured [root@master1 ~]#kubectl get po -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-6ffdd87d4d-42m7q 1/1 Running 0 13s 10.244.2.223 node2 <none> <none> nginx-6ffdd87d4d-5cdh2 1/1 Running 0 11s 10.244.2.224 node2 <none> <none> [root@master1 ~]#dig @10.96.0.10 nginx.nginx.default.svc.cluster.local ; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.8 <<>> @10.96.0.10 nginx.nginx.default.svc.cluster.local ; (1 server found) ;; global options: +cmd ;; Got answer: ;; WARNING: .local is reserved for Multicast DNS ;; You are currently testing what happens when an mDNS query is leaked to DNS ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46249 ;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; WARNING: recursion requested but not available ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;nginx.nginx.default.svc.cluster.local. IN A ;; ANSWER SECTION: nginx.nginx.default.svc.cluster.local. 30 IN A 10.244.2.223 nginx.nginx.default.svc.cluster.local. 30 IN A 10.244.2.224 ;; Query time: 0 msec ;; SERVER: 10.96.0.10#53(10.96.0.10) ;; WHEN: Tue Dec 21 20:19:11 CST 2021 ;; MSG SIZE rcvd: 172 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
可以看到解析成功了,但是因为 Deployment 中无法给每个 Pod 指定不同的 hostname,所以两个 Pod 有同样的 hostname,解析出来两个 IP,跟我们的本意就不符合了。
不过知道了这种方式过后我们就可以自己去写一个 Operator 去直接管理 Pod 了,**给每个 Pod 设置不同的 hostname 和一个 Headless SVC 名称的 subdomain,这样就相当于实现了 StatefulSet 中的 Pod 解析。**😋
最后,我们来看下注释
[root@master1 ~]#kubectl explain pod.spec
hostname <string> Specifies the hostname of the Pod If not specified, the pod's hostname will be set to a system-defined value. subdomain <string> If specified, the fully qualified Pod hostname will be ". . If not specified, the pod will not have a domainname at all.. .svc. " - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实验结束。😘
3、Pod 的 DNS 策略
DNS 策略可以单独对 Pod 进行设定,目前 Kubernetes 支持以下特定 Pod 的 DNS 策略。这些策略可以在 Pod 规范中的
dnsPolicy字段设置:-
Default: 有人说 Default 的方式,是使用宿主机的方式,这种说法并不准确。这种方式其实是让 kubelet 来决定使用何种 DNS 策略。而 kubelet 默认的方式,就是使用宿主机的
/etc/resolv.conf(可能这就是有人说使用宿主机的 DNS 策略的方式吧)。但是,kubelet 是可以灵活来配置使用什么文件来进行DNS策略的,我们完全可以使用 kubelet 的参数–resolv-conf=/etc/resolv.conf来决定你的 DNS 解析文件地址。[root@master1 ~]#kubelet --help|grep resolv --resolv-conf string Resolver configuration file used as the basis for the container DNS resolution configuration. (default "/etc/resolv.conf") (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.) [root@master1 ~]#- 1
- 2
- 3
-
ClusterFirst: 这种方式,表示 Pod 内的 DNS 使用集群中配置的 DNS 服务,简单来说,就是使用 Kubernetes 中 kubedns 或 coredns 服务进行域名解析。如果解析不成功,才会使用宿主机的 DNS 配置进行解析。
-
ClusterFirstWithHostNet:在某些场景下,我们的 Pod 是用 HostNetwork 模式启动的,一旦用 HostNetwork 模式,表示这个 Pod 中的所有容器,都要使用宿主机的
/etc/resolv.conf配置进行 DNS 查询,但如果你还想继续使用 Kubernetes 的DNS服务,那就将 dnsPolicy 设置为ClusterFirstWithHostNet。 -
None: 表示空的 DNS 设置,这种方式一般用于想要自定义 DNS 配置的场景,往往需要和
dnsConfig配合一起使用达到自定义 DNS 的目的。(下面会讲到的)
⚠️ 注意:
Default并不是默认的 DNS 策略,如果未明确指定 dnsPolicy,则使用ClusterFirst。注意:[root@master1 ~]#kubectl explain pod.spec
dnsPolicy <string> Set DNS policy for the pod. Defaults to "ClusterFirst". Valid values are 'ClusterFirstWithHostNet', 'ClusterFirst', 'Default' or 'None'. DNS parameters given in DNSConfig will be merged with the policy selected with DNSPolicy. To have DNS options set along with hostNetwork, you have to specify DNS policy explicitly to 'ClusterFirstWithHostNet'.- 1
- 2
- 3
- 4
- 5
- 6
💘 实战:Pod的DNS策略(测试成功)-2022.7.30
下面的示例显示了一个 Pod,其 DNS 策略设置为
ClusterFirstWithHostNet,因为它已将 hostNetwork 设置为 true。实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
无
1.部署pod资源
- 编写资源清单文件:
[root@master1 ~]#vim pod.yaml
apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - image: busybox:1.28.3 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always hostNetwork: true dnsPolicy: ClusterFirstWithHostNet- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.进入到pod查看nameserver
- 部署并进入到pod查看nameserver:
[root@master1 ~]#kubectl apply -f pod.yaml pod/busybox created [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE busybox 1/1 Running 0 7s [root@master1 ~]#kubectl exec busybox -- cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 10.96.0.10 options ndots:5 [root@master1 ~]#kubectl get svc kube-dns -nkube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 51d- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到,当pod里使用了
hostNetwork模式,且dnsPolicy配置为ClusterFirstWithHostNet的之后,此时容器里的nameserver使用的是Kubernetes 的DNS服务。3.把dnsPolicy配置为
ClusterFirst但此时,若把dnsPolicy配置为
ClusterFirst,按理说,此时的容器里的nameserver应该使用的是宿主机的/etc/resolv.conf配置进行 DNS 查询,我们来测试下:[root@master1 ~]#vim pod.yaml apiVersion: v1 kind: Pod metadata: name: busybox1 #这里改个名称! namespace: default spec: containers: - image: busybox:1.28.3 command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always hostNetwork: true dnsPolicy: ClusterFirst #将上面的ClusterFirstWithHostNet修改为ClusterFirst。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
修改完后,重新部署并观察现象:
[root@master1 ~]#kubectl apply -f pod.yaml pod/busybox1 created [root@master1 ~]#kubectl get po busybox1 NAME READY STATUS RESTARTS AGE busybox1 1/1 Running 0 7s [root@master1 ~]#kubectl exec busybox1 -- cat /etc/resolv.conf nameserver 223.6.6.6 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以发现,此时的容器里的nameserver应该使用的是宿主机的
/etc/resolv.conf配置进行 DNS 查询,符合预期效果,测试结束。实验结束。😘
4.查看kube-proxy pod的DNS策略
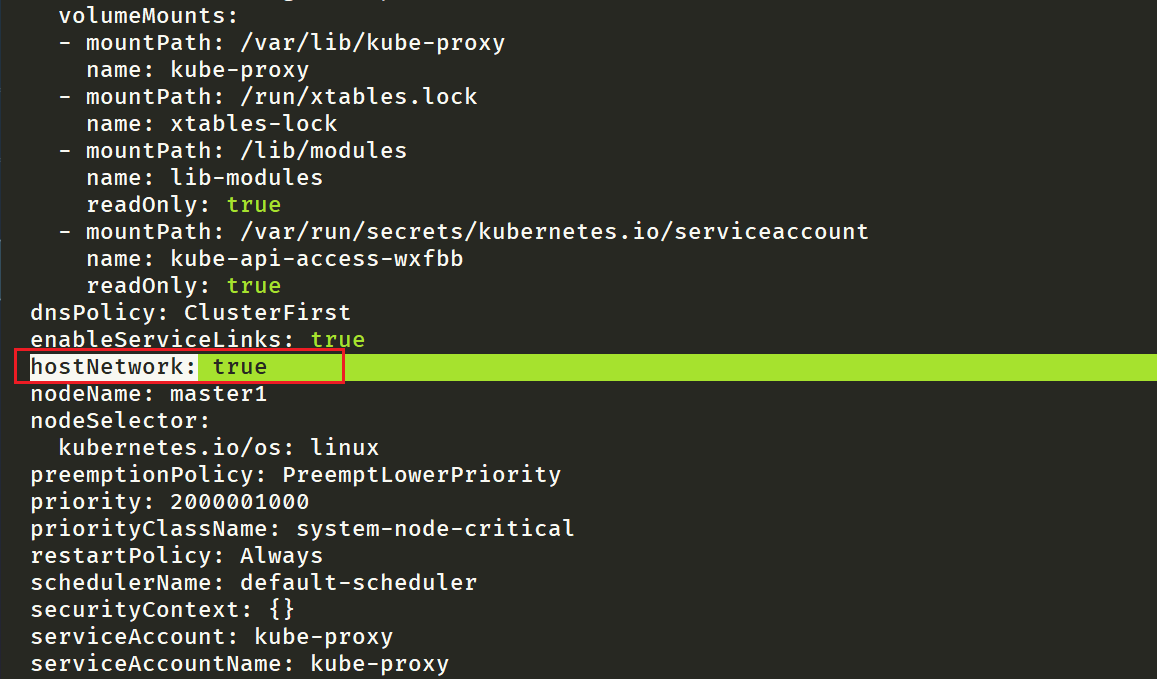
⚠️ 注意
我们的k8s集群的
kube-proxy组件,它开启了hostNetwork:true,但是它的的dnsPolicy却是ClusterFirst,难道这里的kube-proxy pod不使用coredns服务吗?而是直接使用的宿主机的dns服务,这个自己有些疑问?—是的🤣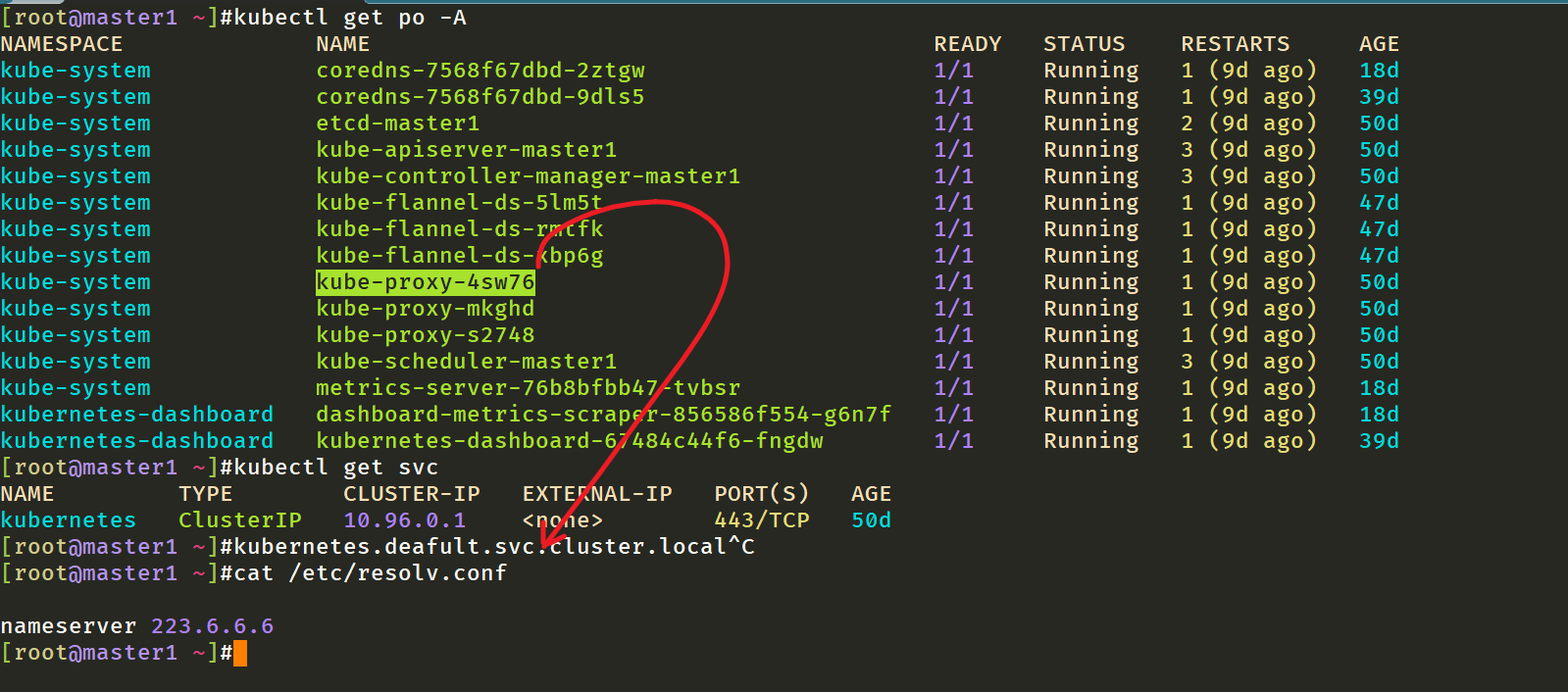

4、Pod 的 DNS 配置
Pod 的 DNS 配置可让用户对 Pod 的 DNS 设置进行更多控制。
dnsConfig字段是可选的,它可以与任何dnsPolicy设置一起使用。 但是,当 Pod 的 dnsPolicy 设置为 “None” 时,必须指定 dnsConfig 字段。用户可以在 dnsConfig 字段中可以指定以下属性:
- nameservers:将用作于 Pod 的 DNS 服务器的 IP 地址列表。 最多可以指定 3 个 IP 地址。当 Pod 的 dnsPolicy 设置为 “None” 时,列表必须至少包含一个 IP 地址,否则此属性是可选的。所列出的服务器将合并到从指定的 DNS 策略生成的基本名称服务器,并删除重复的地址。
- searches:用于在 Pod 中查找主机名的 DNS 搜索域的列表。此属性是可选的。 指定此属性时,所提供的列表将合并到根据所选 DNS 策略生成的基本搜索域名中。重复的域名将被删除,Kubernetes 最多允许 6 个搜索域。
- options:可选的对象列表,其中每个对象可能具有 **name 属性(必需)**和 value 属性(可选)。此属性中的内容将合并到从指定的 DNS 策略生成的选项。重复的条目将被删除。
💘 实战:Pod的DNS设置(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
无
1.部署pod资源
以下是具有自定义 DNS 设置的 Pod 示例:
[root@master1 ~]#vim dnsconfig.yaml
apiVersion: v1 kind: Pod metadata: namespace: default name: dns-example spec: containers: - name: test image: nginx dnsPolicy: "None" dnsConfig: nameservers: - 1.2.3.4 searches: - ns1.svc.cluster-domain.example - my.dns.search.suffix options: - name: ndots value: "2" - name: edns0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.测试
创建上面的 Pod 后,容器 test 会在其
/etc/resolv.conf文件中获取以下内容:[root@master1 ~]#kubectl apply -f dnsconfig.yaml pod/dns-example created [root@master1 ~]#kubectl get po ]NAME READY STATUS RESTARTS AGE dns-example 1/1 Running 0 40s [root@master1 ~]#kubectl exec dns-example -- cat /etc/resolv.conf search ns1.svc.cluster-domain.example my.dns.search.suffix nameserver 1.2.3.4 options ndots:2 edns0 [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
符合预期效果。
实验结束。😘
- 注意:可以看下
dnsConfig的帮助信息。
[root@master1 ~]#kubectl explain pod.spec
dnsConfig <Object> Specifies the DNS parameters of a pod. Parameters specified here will be merged to the generated DNS configuration based on DNSPolicy.- 1
- 2
- 3
[root@master1 ~]#kubectl explain pod.spec.dnsConfig KIND: Pod VERSION: v1 RESOURCE: dnsConfig <Object>: DESCRIPTION: Specifies the DNS parameters of a pod. Parameters specified here will be merged to the generated DNS configuration based on DNSPolicy. PodDNSConfig defines the DNS parameters of a pod in addition to those generated from DNSPolicy. FIELDS: nameservers <[]string> A list of DNS name server IP addresses. This will be appended to the base nameservers generated from DNSPolicy. Duplicated nameservers will be removed. options <[]Object> A list of DNS resolver options. This will be merged with the base options generated from DNSPolicy. Duplicated entries will be removed. Resolution options given in Options will override those that appear in the base DNSPolicy. searches <[]string> A list of DNS search domains for host-name lookup. This will be appended to the base search paths generated from DNSPolicy. Duplicated search paths will be removed.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
5、LocalDNS
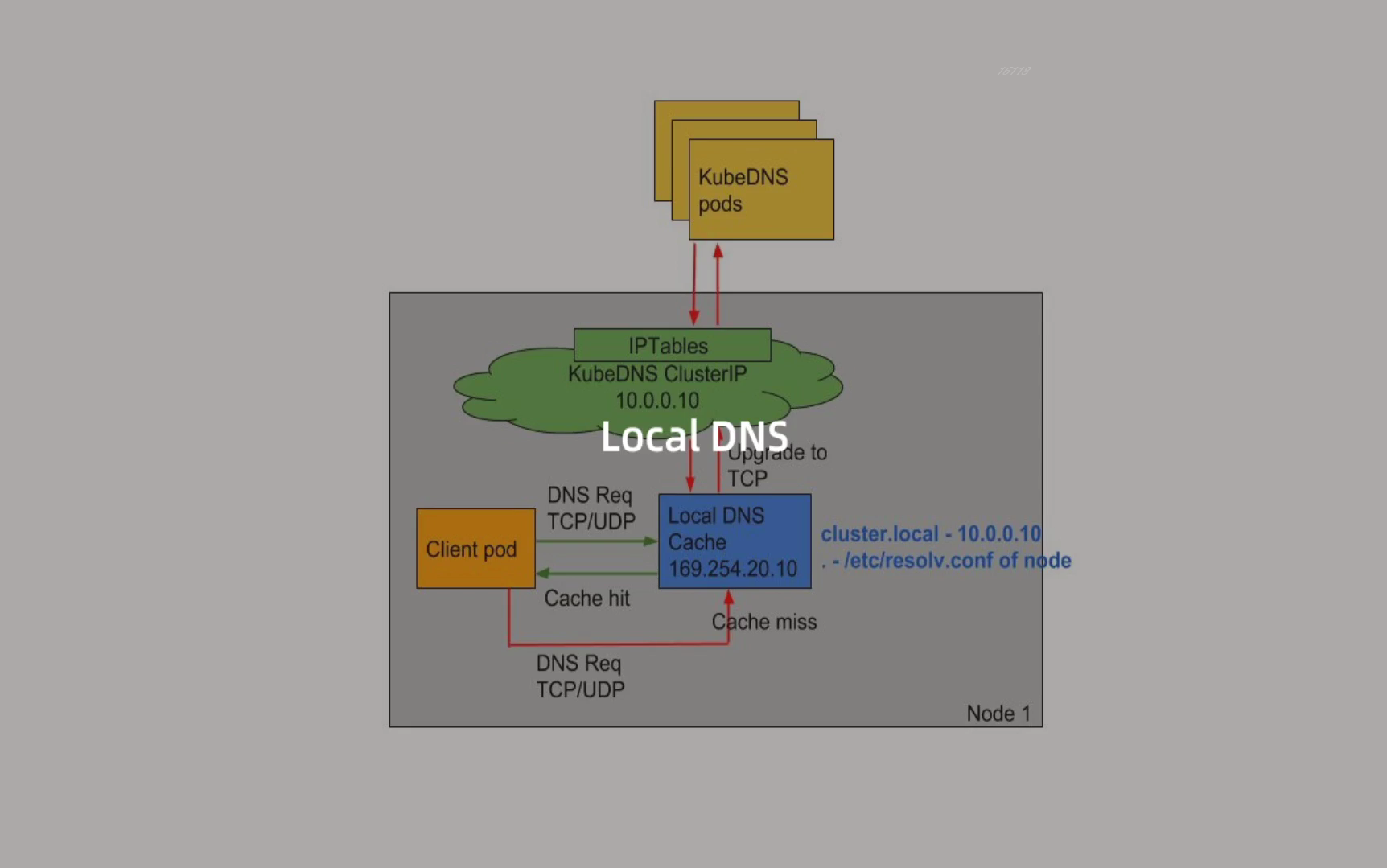
1.DNS 优化
前面我们讲解了在 Kubernetes 中我们可以使用 CoreDNS 来进行集群的域名解析,但是如果在集群规模较大并发较高的情况下我们仍然需要对 DNS 进行优化,典型的就是大家比较熟悉的 **CoreDNS 会出现超时5s**的情况。
2.超时原因
⚠️ 老师说这里的超时5s故障不是很好去复现,这里解释下超时原因。
在 iptables 模式下(默认情况下,但实际在ipvs下,也是解决不了这个超时问题的!),每个服务的 kube-proxy 在主机网络名称空间的 nat 表中创建一些 iptables 规则。
比如在集群中具有两个 DNS 服务器实例的 kube-dns 服务,其相关规则大致如下所示:

额,自己对iptables的知识不是很熟悉啊。。。😥😥,硬着头皮看下把。。
(1) -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES <...> (2) -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU <...> (3) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-LLLB6FGXBLX6PZF7 (4) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRVEW52VMYCOUSMZ <...> (5) -A KUBE-SEP-LLLB6FGXBLX6PZF7 -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.6:53 <...> (6) -A KUBE-SEP-LRVEW52VMYCOUSMZ -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.7:53 #说明: -j代表跳转- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们知道每个 Pod 的
/etc/resolv.conf文件中都有填充的nameserver 10.96.0.10这个条目。所以来自 Pod 的 DNS 查找请求将发送到10.96.0.10,这是 kube-dns 服务的 ClusterIP 地址。由于
(1)请求进入KUBE-SERVICE链,然后匹配规则(2),最后根据(3)的 random 随机模式,跳转到 (5) 或 (6) 条目,将请求 UDP 数据包的目标 IP 地址修改为 DNS 服务器的实际IP 地址,这是通过DNAT完成的。其中10.32.0.6和10.32.0.7是我们集群中 CoreDNS 的两个 Pod 副本的 IP 地址。(1)内核中的 DNAT
DNAT的主要职责是同时更改传出数据包的目的地,响应数据包的源,并确保对所有后续数据包进行相同的修改。后者严重依赖于连接跟踪机制,也称为conntrack,它被实现为内核模块。conntrack会跟踪系统中正在进行的网络连接。conntrack(相当于一张表)中的每个连接都由两个元组表示,一个元组用于原始请求(IP_CT_DIR_ORIGINAL),另一个元组用于答复(IP_CT_DIR_REPLY)。对于 UDP,每个元组都由源 IP 地址,源端口以及目标 IP 地址和目标端口组成,答复元组包含存储在src 字段中的目标的真实地址。例如,如果 IP 地址为
10.40.0.17的 Pod 向 kube-dns 的 ClusterIP 发送一个请求,该请求被转换为10.32.0.6,则将创建以下元组:原始:src = 10.40.0.17 dst = 10.96.0.10 sport = 53378 dport = 53 回复:src = 10.32.0.6 dst = 10.40.0.17 sport = 53 dport = 53378- 1
- 2
通过这些条目内核可以相应地修改任何相关数据包的目的地和源地址,而无需再次遍历 DNAT 规则。此外,它将知道如何修改回复以及应将回复发送给谁。创建
conntrack条目后,将首先对其进行确认,然后如果没有已确认的conntrack条目具有相同的原始元组或回复元组,则内核将尝试确认该条目。conntrack创建和 DNAT 的简化流程如下所示:下面这个,理解起来有些模糊😥😥

(2)问题
😥o,shift,自己这一块的知识点也是盲区啊。
DNS 客户端 (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议,connect 时并不会创建
conntrack表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,这时它们源 Port 相同,当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 CoreDNS 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个具体的 Pod IP,当两个包被 DNAT 成同一个 IP,最终它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 DNS 的 Pod 副本只有一个实例的情况就很容易发生,现象就是 DNS 请求超时,客户端默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 DNS 请求有 5s 的延时。具体原因可以参考 weave works 总结的文章 Racy conntrack and DNS lookup timeouts。
- 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
- glibc、musl(alpine linux 的 libc 库)都使用
parallel query, 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃 - 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
3.解决方法
要彻底解决这个问题最好当然是内核上去 FIX 掉这个 BUG,除了这种方法之外我们还可以使用其他方法来进行规避,我们可以避免相同五元组 DNS请求的并发。
在
resolv.conf中就有两个相关的参数可以进行配置:single-request-reopen:发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。single-request:避免并发,改为串行发送 A 类型和 AAAA 类型请求。没有了并发,从而也避免了冲突。
要给容器的
resolv.conf加上 options 参数,有几个办法:-
在容器的
ENTRYPOINT或者CMD脚本中,执行/bin/echo 'options single-request-reopen' >> /etc/resolv.conf(不推荐) -
在 Pod 的 postStart hook 中添加:(不推荐)
lifecycle: postStart: exec: command: - /bin/sh - -c - "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
使用
template.spec.dnsConfig配置:template: spec: dnsConfig: options: - name: single-request-reopen- 1
- 2
- 3
- 4
- 5
-
使用 ConfigMap 覆盖 Pod 里面的
/etc/resolv.conf:# configmap apiVersion: v1 data: resolv.conf: | nameserver 1.2.3.4 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 single-request-reopen timeout:1 kind: ConfigMap metadata: name: resolvconf --- # Pod Spec spec: volumeMounts: - name: resolv-conf mountPath: /etc/resolv.conf subPath: resolv.conf # 在某个目录下面挂载一个文件(保证不覆盖当前目录)需要使用subPath -> 不支持热更新 ... volumes: - name: resolv-conf configMap: name: resolvconf items: - key: resolv.conf path: resolv.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上面的方法在一定程度上可以解决 DNS 超时的问题,但更好的方式是使用本地 DNS 缓存,容器的 DNS 请求都发往本地的 DNS 缓存服务,也就不需要走 DNAT,当然也不会发生
conntrack冲突了,而且还可以有效提升 CoreDNS 的性能瓶颈。4.性能测试
💖 实战:性能测试(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
2021.12.28-实验软件-nodelocaldns- 1
链接:https://pan.baidu.com/s/1cl474vfrXvz0hPya1EDIlQ
提取码:lpz1
1.构建测试程序
这里我们使用一个简单的 golang 程序来测试下使用本地 DNS 缓存的前后性能。代码如下所示:
// main.go package main import ( "context" "flag" "fmt" "net" "sync/atomic" "time" ) var host string var connections int var duration int64 var limit int64 var timeoutCount int64 func main() { flag.StringVar(&host, "host", "", "Resolve host") flag.IntVar(&connections, "c", 100, "Connections") flag.Int64Var(&duration, "d", 0, "Duration(s)") flag.Int64Var(&limit, "l", 0, "Limit(ms)") flag.Parse() var count int64 = 0 var errCount int64 = 0 pool := make(chan interface{}, connections) exit := make(chan bool) var ( min int64 = 0 max int64 = 0 sum int64 = 0 ) go func() { time.Sleep(time.Second * time.Duration(duration)) exit <- true }() endD: for { select { case pool <- nil: go func() { defer func() { <-pool }() resolver := &net.Resolver{} now := time.Now() _, err := resolver.LookupIPAddr(context.Background(), host) use := time.Since(now).Nanoseconds() / int64(time.Millisecond) if min == 0 || use < min { min = use } if use > max { max = use } sum += use if limit > 0 && use >= limit { timeoutCount++ } atomic.AddInt64(&count, 1) if err != nil { fmt.Println(err.Error()) atomic.AddInt64(&errCount, 1) } }() case <-exit: break endD } } fmt.Printf("request count:%d\nerror count:%d\n", count, errCount) fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
首先配置好 golang 环境,然后直接构建上面的测试应用:
go build -o testdns .- 1
至于,如何构建自己的go环境,请查看另外一片文章:Go软件安装-已成功测试-20210413,Vscode构建Go编程环境-已成功测试-20210413
2.部署Deployment资源
构建完成后生成一个 testdns 的二进制文件,然后我们将这个二进制文件拷贝到任意一个 Pod 中去进行测试:
首先这里我部署一个nginx.yaml:
[root@master1 ~]#vim nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx replicas: 2 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 [root@master1 ~]#kubectl apply -f nginx.yaml deployment.apps/nginx created [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE nginx-5d59d67564-k9m2k 1/1 Running 0 14s nginx-5d59d67564-lbkwx 1/1 Running 0 14s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 拷贝完成后进入这个测试的 Pod 中去:
[root@master1 go]#kubectl cp testdns nginx-5d59d67564-k9m2k:/root/ [root@master1 go]#kubectl exec -it nginx-5d59d67564-k9m2k -- bash root@nginx-5d59d67564-k9m2k:/# ls -l /root/testdns -rwxr-xr-x 1 root root 2903854 Dec 28 07:18 /root/testdns root@nginx-5d59d67564-k9m2k:/#- 1
- 2
- 3
- 4
- 5
3.部署service资源
我们再部署一个svc:
[root@master1 ~]#vim service.yaml apiVersion: v1 kind: Service metadata: name: nginx-service spec: ports: - name: http port: 5000 protocol: TCP targetPort: 80 #相当于给上面那个nginx暴露服务 selector: app: nginx type: ClusterIP #默认为ClusterIP模式 [root@master1 ~]#kubectl apply -f service.yaml service-service/nginx created [root@master1 ~]#kubectl get svc nginx-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx-service ClusterIP 10.106.35.68 <none> 5000/TCP 58s [root@master1 ~]#curl 10.106.35.68:5000 #可以简单来测试下 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html> [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
4.进行压力测试
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
⚠️当然,做dns的压力测试,线上应该会有很多的程序的。😋,本次使用老师go写的代码来进行压测。
下面这个为老师提供的笔记里面的数据:
# 对 nginx-service.default 这个地址进行解析 root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host request count:12533 error count:5 request time:min(5ms) max(16871ms) avg(425ms) timeout(475n) root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host request count:10058 error count:3 request time:min(4ms) max(12347ms) avg(540ms) timeout(487n) root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 lookup nginx-service.default on 10.96.0.10:53: no such host lookup nginx-service.default on 10.96.0.10:53: no such host request count:12242 error count:2 request time:min(3ms) max(12206ms) avg(478ms) timeout(644n) root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:11008 error count:0 request time:min(3ms) max(11110ms) avg(496ms) timeout(478n) root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:9141 error count:0 request time:min(4ms) max(11198ms) avg(607ms) timeout(332n) root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:9126 error count:0 request time:min(4ms) max(11554ms) avg(613ms) timeout(197n)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
我们可以看到大部分平均耗时都是在 500ms 左右,这个性能是非常差的,而且还有部分解析失败的条目。接下来我们就来尝试使用
NodeLocal DNSCache来提升 DNS 的性能和可靠性。😂注意:自己本次测试现象数据
root@nginx:~# chmod 777 testdns
root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000 request count:34609 error count:0 request time:min(4ms) max(5191ms) avg(166ms) timeout(2n) root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000 request count:31942 error count:0 request time:min(3ms) max(1252ms) avg(183ms) timeout(0n) root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000 request count:31311 error count:0 request time:min(4ms) max(1321ms) avg(187ms) timeout(0n) root@nginx-5d59d67564-k9m2k:~# #我们可以看到大部分平均耗时都是在 160ms 左右,但是没有看到有看到解析失败的条目 #并发数改为1000再次测试: root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 1000 -d 30 -l 5000 request count:24746 error count:0 request time:min(7ms) max(7273ms) avg(1138ms) timeout(52n) root@nginx-5d59d67564-k9m2k:~#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
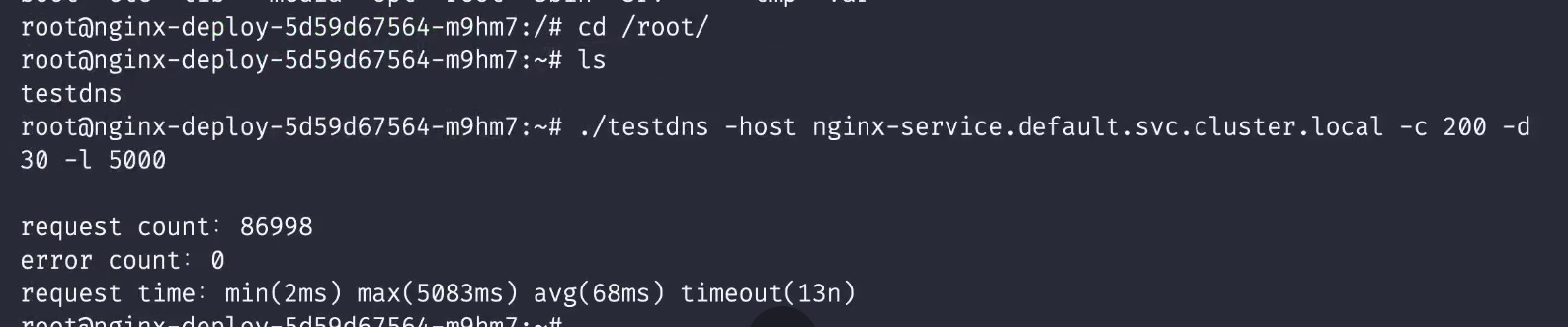
😘 注意:老师本次测试的现象数据

这个i/o timeout 可能在你的线上环境出现,因为你线上的业务并发可能都是很高的。
-
注意:dns压力测试不一定能测试成功,主要还和你的环境有关系。
-
注意:-l参数含义,应该是超过5s的话,有点模糊不清。。。
测试结束。😘
5.NodeLocal DNSCache
**
NodeLocal DNSCache通过在集群节点上运行一个 DaemonSet 来提高集群 DNS 性能和可靠性。**处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点。通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。在集群中运行
NodeLocal DNSCache有如下几个好处:- 如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用
NodeLocal DNSCache后,拥有本地缓存将有助于改善延迟。 - 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的5s超时问题就是这个原因造成的)
注意:这里改成TCP的话,也是可以有效果的 - 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时过后(默认
nfconntrackudp_timeout是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)
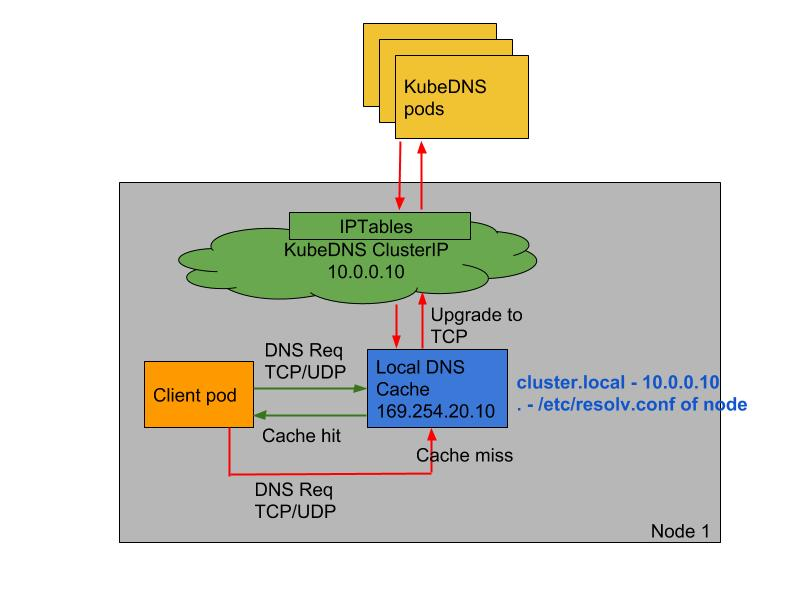
💘 实战:NodeLocal DNSCache(测试成功)-2022.7.30
实验环境
实验环境: 1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点 k8s version:v1.22.2 containerd://1.5.5- 1
- 2
- 3
- 4
- 5
实验软件
2021.12.28-实验软件-nodelocaldns- 1
链接:https://pan.baidu.com/s/1cl474vfrXvz0hPya1EDIlQ
提取码:lpz11.获取NodeLocal DNSCache的资源清单
要安装
NodeLocal DNSCache也非常简单,直接获取官方的资源清单即可:wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml [root@master1 ~]#wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml --2021-12-28 16:38:36-- https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml Resolving github.com (github.com)... 20.205.243.166 Connecting to github.com (github.com)|20.205.243.166|:443... connected. HTTP request sent, awaiting response... 302 Found Location: https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml [following] --2021-12-28 16:38:36-- https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.111.133, 185.199.109.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 5334 (5.2K) [text/plain] Saving to: ‘nodelocaldns.yaml’ 100%[===================================================================>] 5,334 --.-K/s in 0.1s 2021-12-28 16:38:37 (51.4 KB/s) - ‘nodelocaldns.yaml’ saved [5334/5334] [root@master1 ~]#ll nodelocaldns.yaml -rw-r--r-- 1 root root 5334 Dec 28 16:38 nodelocaldns.yaml [root@master1 ~]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
有可能因为网络问题下载失败,这里可以稍微等待下再次尝试。
该资源清单文件中包含几个变量值得注意,其中:
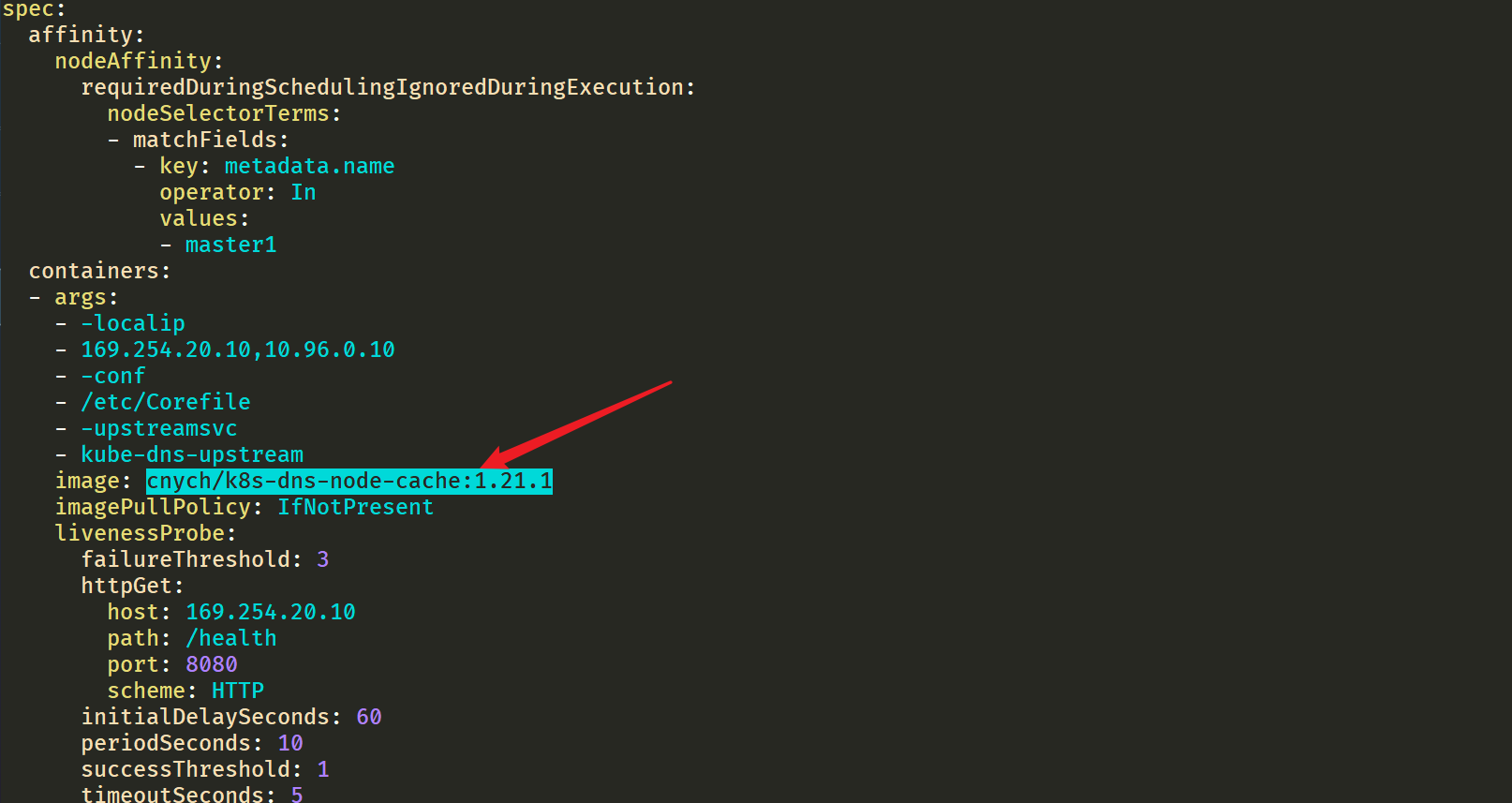
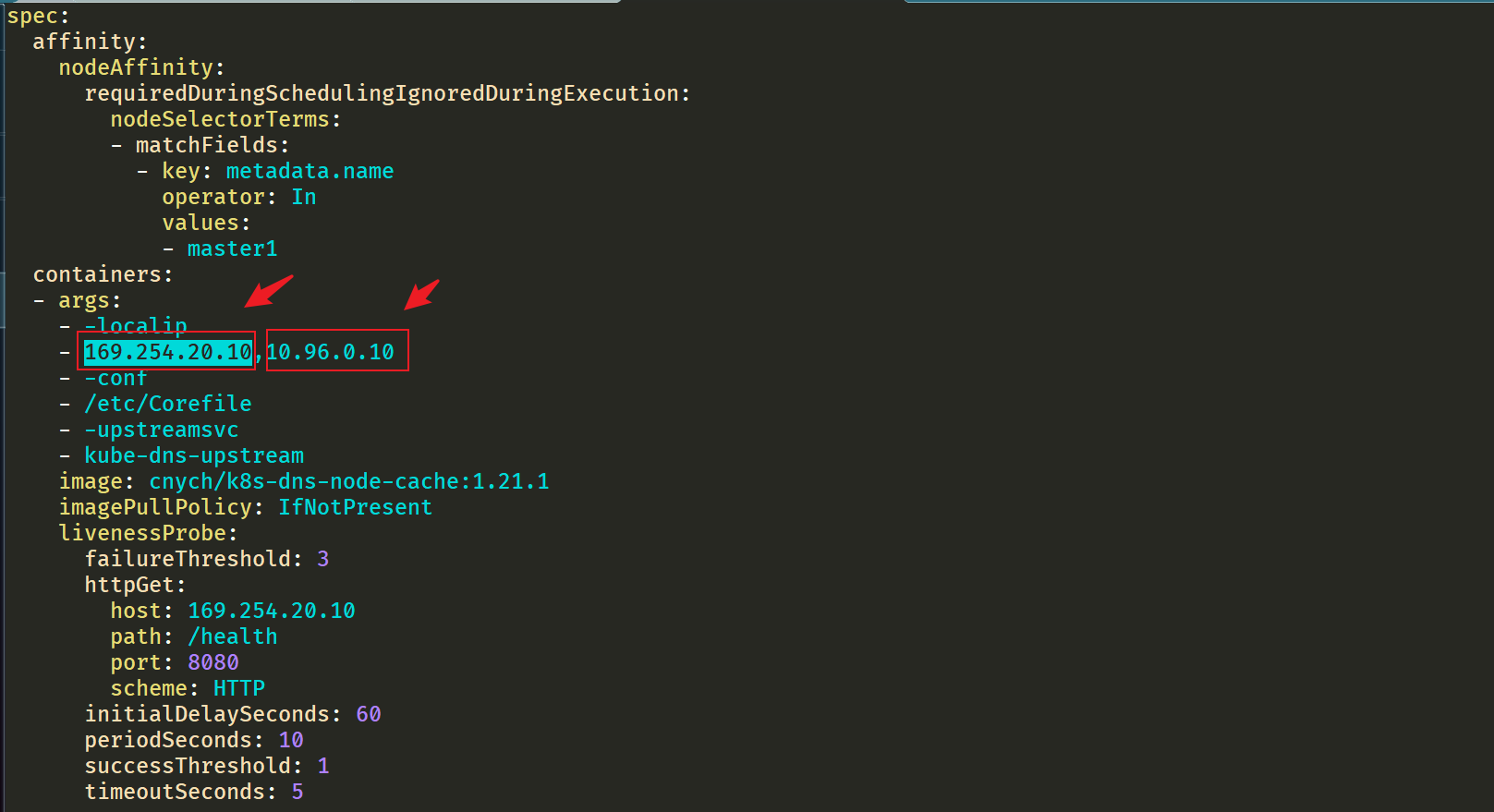
__PILLAR__DNS__SERVER__:表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令kubectl get svc -n kube-system | grep kube-dns | awk'{ print $3 }'获取(我们这里就是10.96.0.10)__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为169.254.20.10__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local
另外还有两个参数
__PILLAR__CLUSTER__DNS__和__PILLAR__UPSTREAM__SERVERS__,这两个参数会通过镜像 1.21.1 版本去进行自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的Upstream Server配置。2.部署资源
直接执行如下所示的命令即可安装:
$ sed 's/k8s.gcr.io\/dns/cnych/g s/__PILLAR__DNS__SERVER__/10.96.0.10/g s/__PILLAR__LOCAL__DNS__/169.254.20.10/g s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml | kubectl apply -f - #注意:这个使用的是老师的镜像中转地址cnych。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 可以通过如下命令来查看对应的 Pod 是否已经启动成功:
[root@master1 ~]#kubectl get po -nkube-system -l k8s-app=node-local-dns -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-local-dns-2tbfz 1/1 Running 0 100s 172.29.9.51 master1 <none> <none> node-local-dns-7xv6x 1/1 Running 0 100s 172.29.9.53 node2 <none> <none> node-local-dns-rxhww 1/1 Running 0 100s 172.29.9.52 node1 <none> <none>- 1
- 2
- 3
- 4
- 5
3.测试
- 我们导出来一个pod看下情况:
[root@master1 ~]#kubectl get po node-local-dns-2tbfz -nkube-system -oyaml- 1
可以看到镜像地址被修改过来了:
这里可以看到显示从169.254.20.10解析地址,如果没有再去找10.96.0.10的。
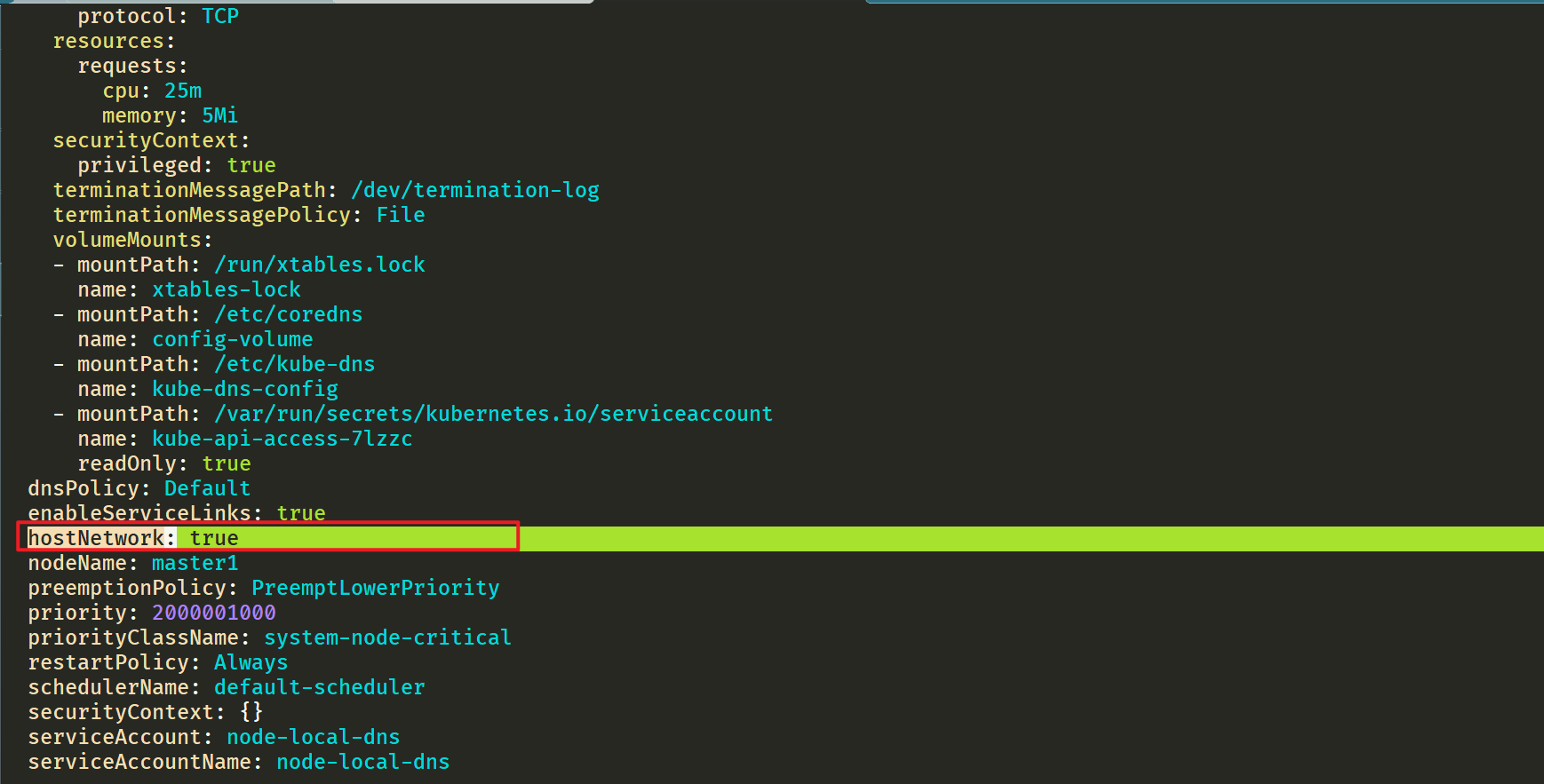
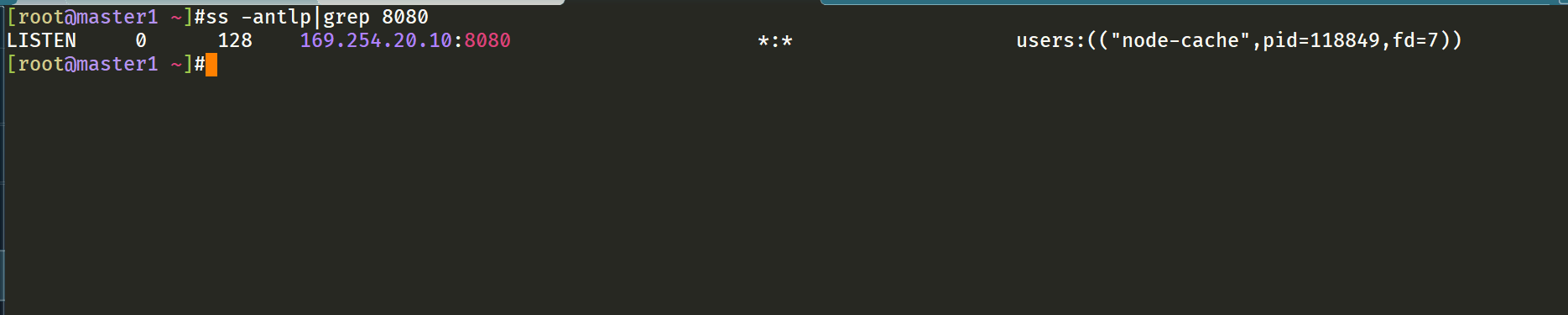
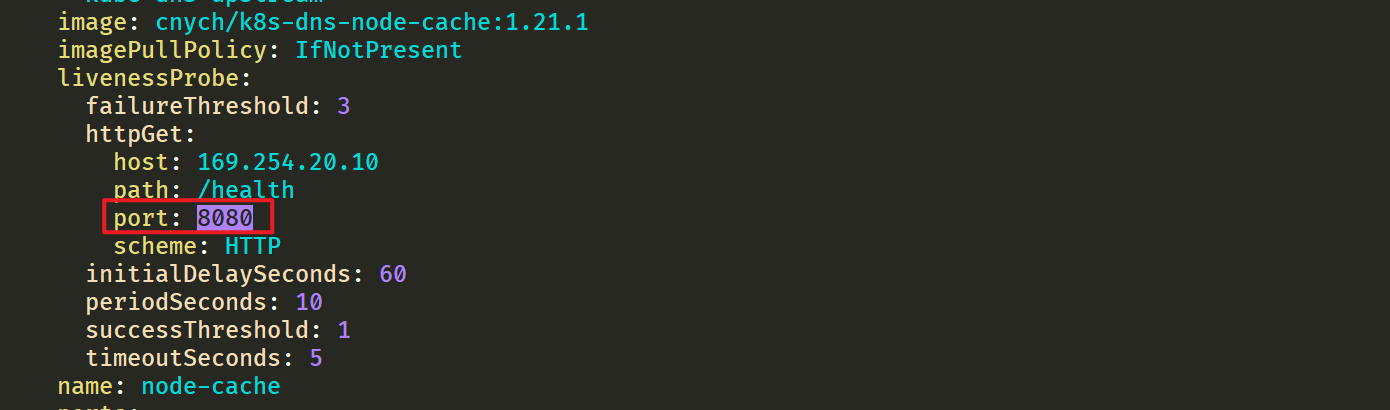
⚠️ 需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了
hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。4.修改 kubelet 的
--cluster-dns参数先来确认下当前kube-proxy组件使用的模式是什么?
[root@master1 NodeLocalDnsCache]#kubectl get cm kube-proxy -nkube-system -oyaml|grep mode mode: ipvs- 1
- 2
⚠️
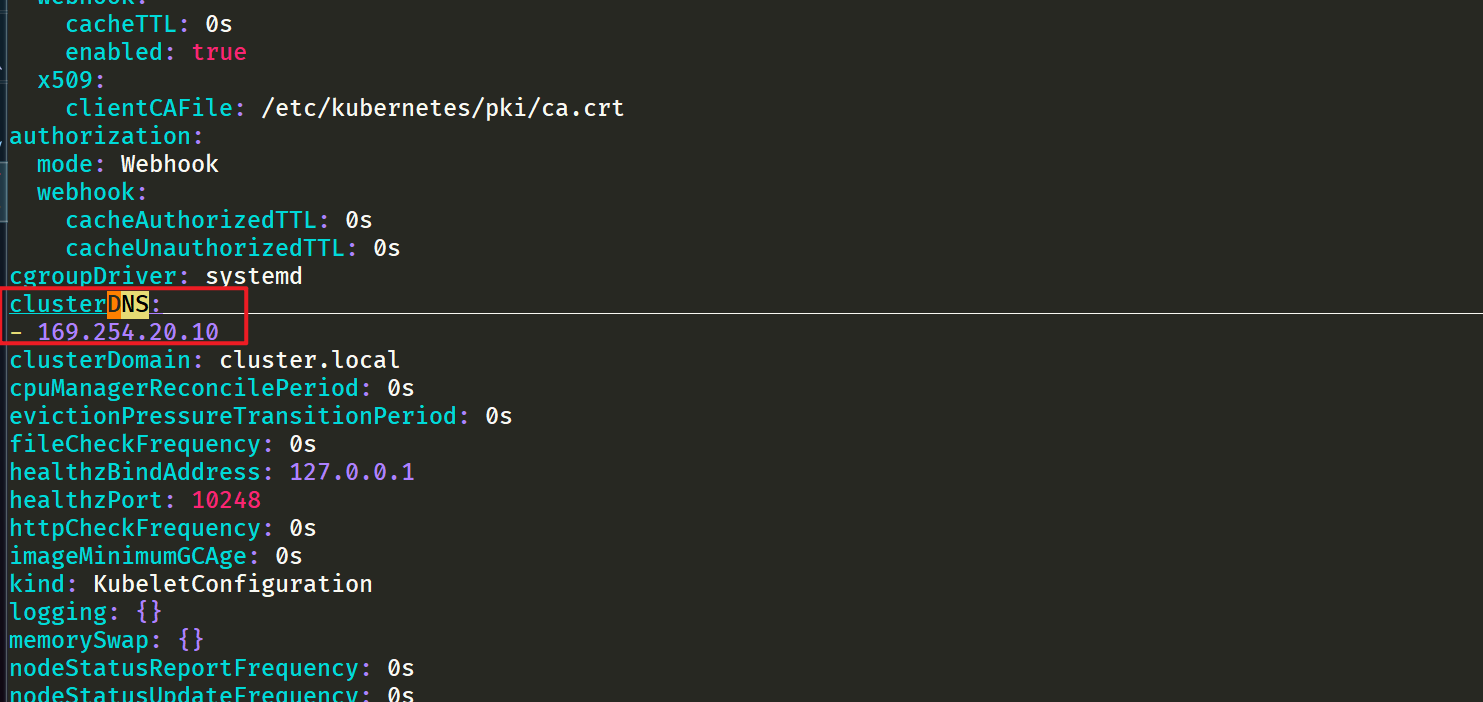
但是到这里还没有完,如果 kube-proxy 组件使用的是 ipvs 模式的话我们还需要修改 kubelet 的
--cluster-dns参数,将其指向169.254.20.10,Daemonset 会在每个节点创建一个网卡来绑这个 IP,Pod 向本节点这个 IP 发 DNS 请求,缓存没有命中的时候才会再代理到上游集群 DNS 进行查询。iptables 模式下 Pod 还是向原来的集群 DNS 请求,节点上有这个 IP 监听,会被本机拦截,再请求集群上游 DNS,所以不需要更改--cluster-dns参数。⚠️如果担心线上环境修改
--cluster-dns参数会产生影响,我们也可以直接在新部署的 Pod 中通过 dnsConfig 配置使用新的 localdns 的地址来进行解析。由于我这里使用的是 kubeadm 安装的 1.22 版本的集群,所以我们只需要替换节点上
/var/lib/kubelet/config.yaml文件中的 clusterDNS 这个参数值,然后重启即可:sed -i 's/10.96.0.10/169.254.20.10/g' /var/lib/kubelet/config.yaml systemctl daemon-reload && systemctl restart kubelet- 1
- 2
注意:all节点均要配置:💖
5.验证
待 node-local-dns 安装配置完成后,我们可以部署一个新的 Pod 来验证下:
[root@master1 ~]#vim test-node-local-dns.yaml
# test-node-local-dns.yaml apiVersion: v1 kind: Pod metadata: name: test-node-local-dns spec: containers: - name: local-dns image: busybox command: ["/bin/sh", "-c", "sleep 60m"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 直接部署:
[root@master1 ~]#kubectl apply -f test-node-local-dns.yaml pod/test-node-local-dns created [root@master1 ~]#kubectl exec -it test-node-local-dns -- sh / # cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 169.254.20.10 options ndots:5 / #- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们可以看到 nameserver 已经变成
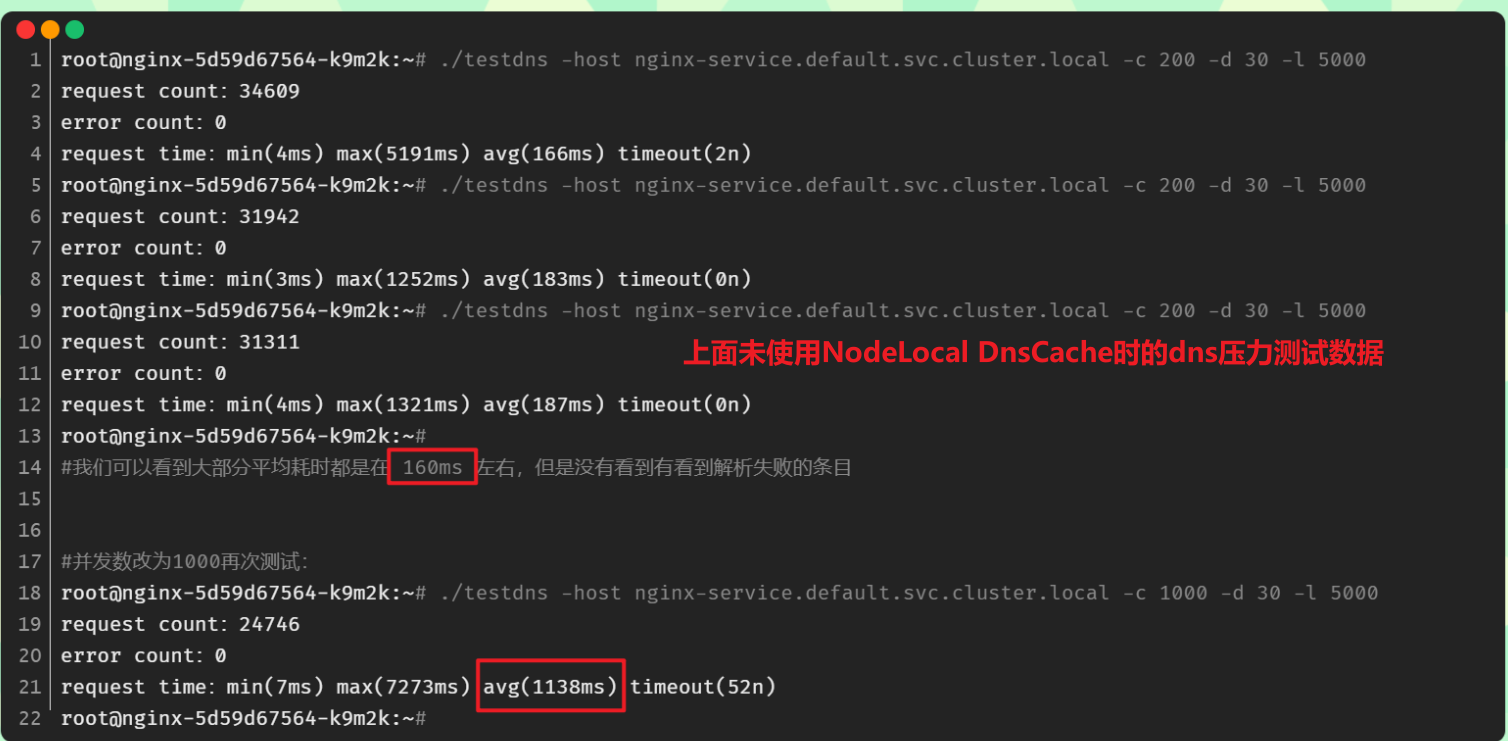
169.254.20.10了,当然对于之前的历史 Pod 要想使用 node-local-dns 则需要重建。6.重建前面压力测试 DNS 的 Pod
接下来我们重建前面压力测试 DNS 的 Pod,重新将 testdns 二进制文件拷贝到 Pod 中去:
[root@master1 ~]#kubectl delete -f nginx.yaml deployment.apps "nginx" deleted [root@master1 ~]#kubectl apply -f nginx.yaml deployment.apps/nginx created [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE nginx-5d59d67564-kgd4q 1/1 Running 0 22s nginx-5d59d67564-lxnt2 1/1 Running 0 22s test-node-local-dns 1/1 Running 0 5m50s [root@master1 ~]#kubectl cp go/testdns nginx-5d59d67564-kgd4q:/root [root@master1 ~]#kubectl exec -it nginx-5d59d67564-kgd4q -- bash root@nginx-5d59d67564-kgd4q:/# cd /root/ root@nginx-5d59d67564-kgd4q:~# ls testdns root@nginx-5d59d67564-kgd4q:~# cat /etc/resolv.conf search default.svc.cluster.local svc.cluster.local cluster.local nameserver 169.254.20.10 options ndots:5 root@nginx-5d59d67564-kgd4q:~# #自己本次的测试数据 #再次压测 #先来个200个并发,测试三次 root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:47344 error count:0 request time:min(1ms) max(976ms) avg(125ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:49744 error count:0 request time:min(1ms) max(540ms) avg(118ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:55929 error count:0 request time:min(2ms) max(463ms) avg(105ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# root@nginx-5d59d67564-kgd4q:~# #再来个1000个并发,测试三次 root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000 request count:42177 error count:0 request time:min(16ms) max(2627ms) avg(690ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000 request count:45456 error count:0 request time:min(29ms) max(2484ms) avg(650ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000 request count:45713 error count:0 request time:min(3ms) max(1698ms) avg(647ms) timeout(0n) root@nginx-5d59d67564-kgd4q:~# #注意:这个1000并发测试效果就很明显了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
😘 老师笔记的测试数据:
# 拷贝到重建的 Pod 中 $ kubectl cp testdns svc-demo-546b7bcdcf-b5mkt:/root $ kubectl exec -it svc-demo-546b7bcdcf-b5mkt -- /bin/bash root@svc-demo-546b7bcdcf-b5mkt:/# cat /etc/resolv.conf nameserver 169.254.20.10 # 可以看到 nameserver 已经更改 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 root@svc-demo-546b7bcdcf-b5mkt:/# cd /root root@svc-demo-546b7bcdcf-b5mkt:~# ls testdns # 重新执行压力测试 root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:16297 error count:0 request time:min(2ms) max(5270ms) avg(357ms) timeout(8n) root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:15982 error count:0 request time:min(2ms) max(5360ms) avg(373ms) timeout(54n) root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:25631 error count:0 request time:min(3ms) max(958ms) avg(232ms) timeout(0n) root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000 request count:23388 error count:0 request time:min(6ms) max(1130ms) avg(253ms) timeout(0n)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
7.总结
从上面的结果可以看到无论是最大解析时间还是平均解析时间都比之前默认的 CoreDNS 提示了不少的效率,所以我们还是非常推荐在线上环境部署
NodeLocal DNSCache来提升 DNS 的性能和可靠性的。唯一的缺点就是由于 LocalDNS 使用的是 DaemonSet 模式部署,所以如果需要更新镜像则可能会中断服务(不过可以使用一些第三方的增强组件来实现原地升级解决这个问题,比如 openkruise-阿里云开源的一个增强套件。)。阿里云也是比较推荐线上去部署这个的。
测试结束。😘
6、必知必会,7 张图轻松理解 K8S 集群内服务通信
原文链接
原文:
https://medium.com/codex/east-west-communication-in-kubernetes-how-do-services-communicate-within-a-cluster-310e9dc9dd53
国内可访问链接:
https://mp.weixin.qq.com/s/weUQp1iwTVvGOtYkfCskfg
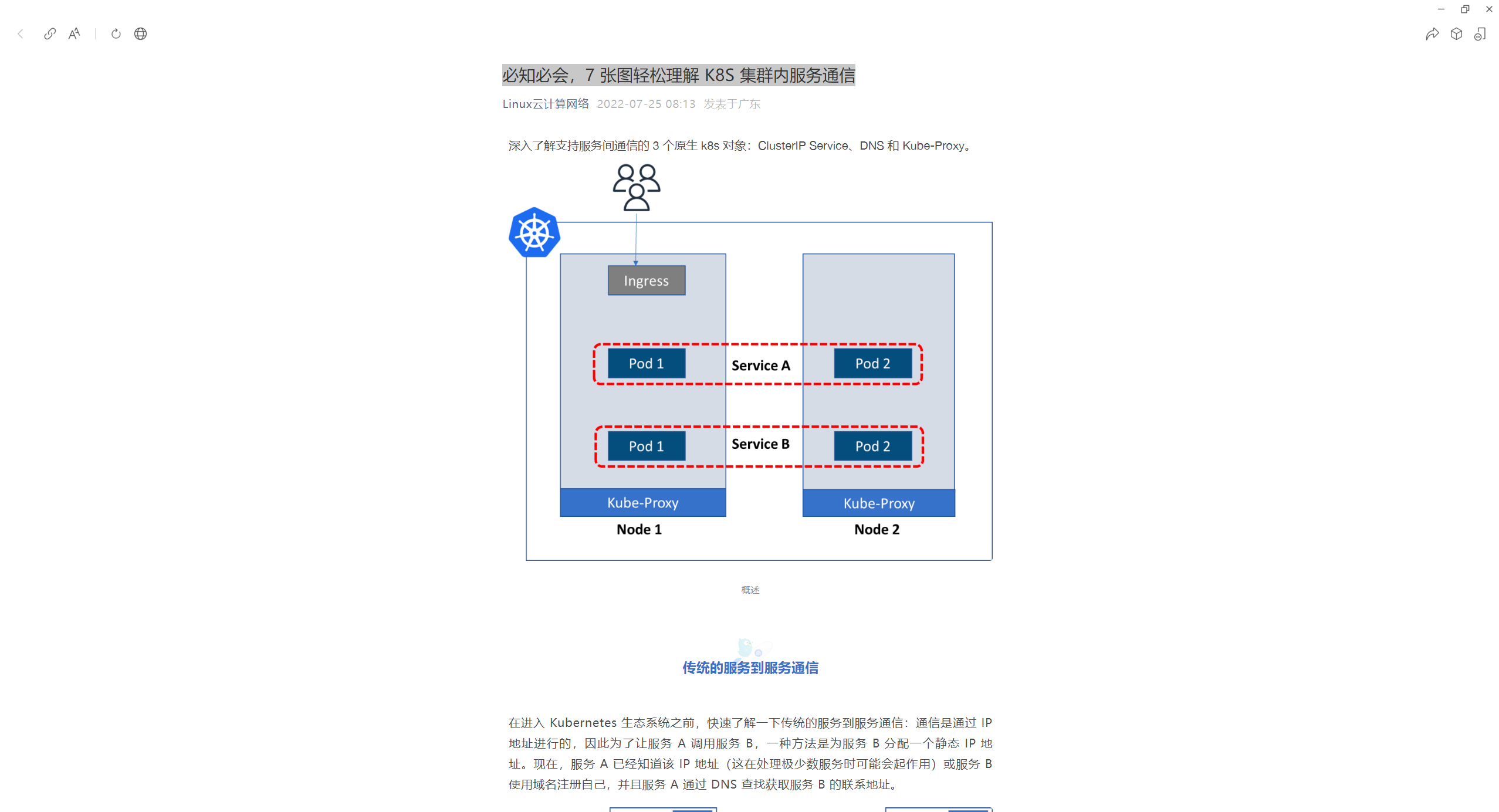
深入了解支持服务间通信的 3 个原生 k8s 对象:ClusterIP Service、DNS 和 Kube-Proxy。
传统的服务到服务通信
在进入 Kubernetes 生态系统之前,快速了解一下传统的服务到服务通信:通信是通过 IP 地址进行的,因此为了让服务 A 调用服务 B,一种方法是为服务 B 分配一个静态 IP 地址。现在,服务 A 已经知道该 IP 地址(这在处理极少数服务时可能会起作用)或服务 B 使用域名注册自己,并且服务 A 通过 DNS 查找获取服务 B 的联系地址。

Kubernetes 网络模型
现在在 Kubernetes 集群中,我们拥有构成集群管理组件和一组工作机器(称为节点)的控制平面。这些节点托管 Pod,这些 Pod 将后端微服务作为容器化服务运行。
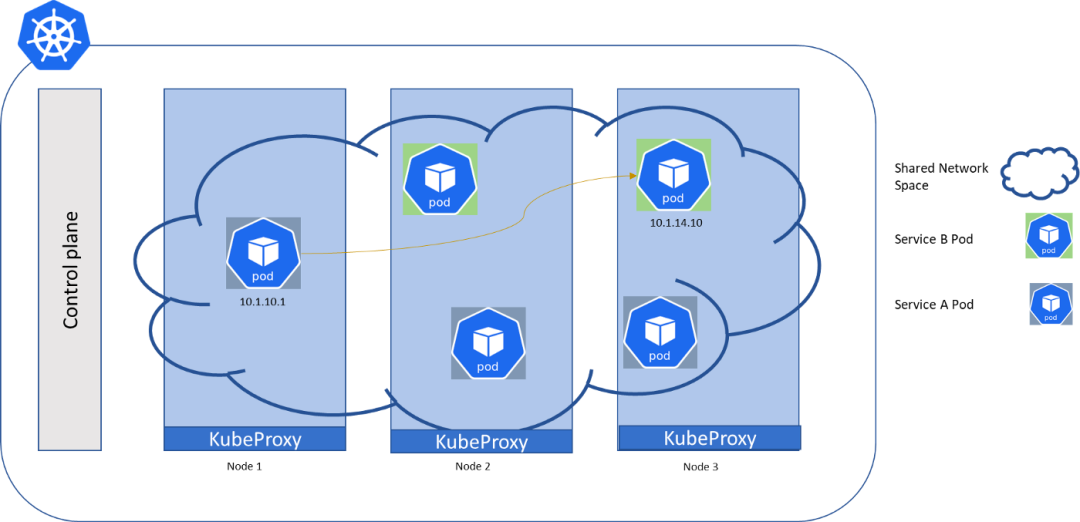
根据 Kubernetes 网络模型:
- 集群中的每个 pod 都有自己唯一的集群范围 IP 地址
- 所有 pod 都可以与集群内的每个 pod 通信
- 通信在没有 NAT 的情况下发生,这意味着目标 pod 可以看到源 pod 的真实 IP 地址。Kubernetes 认为容器网络或在其上运行的应用程序是可信的,不需要在网络级别进行身份验证。
ClusterIP 服务 ~ 基于 Pod 的抽象
既然集群中的每个 pod 都有自己的 IP 地址,那么一个 pod 与另一个 pod 通信应该很容易吧?
不,因为 Pod 是易变的,每次创建 pod 时都会获得一个新的 IP 地址。所以客户端服务必须以某种方式切换到下一个可用的 pod。
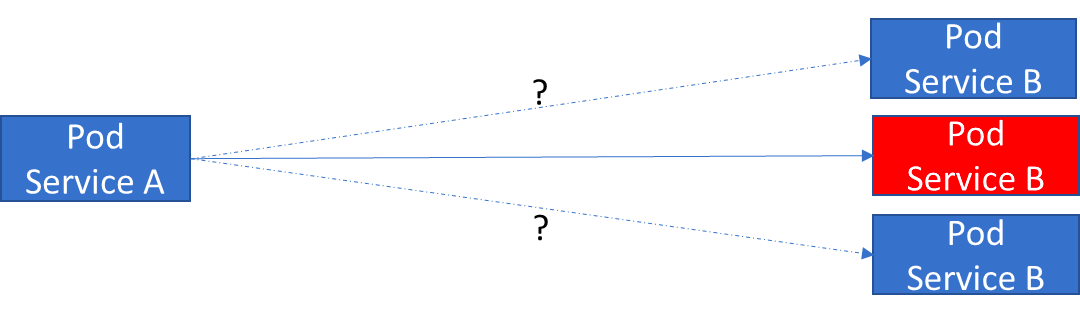
Pod 直接相互交谈的问题是另一个目标 Pod 的短暂性(随时可能销毁),其次是发现新 Pod IP 地址。
因此 Kubernetes 可以在一组 Pod 之上创建一个层,该层可以为该组提供单个 IP 地址并可以提供基本的负载平衡。
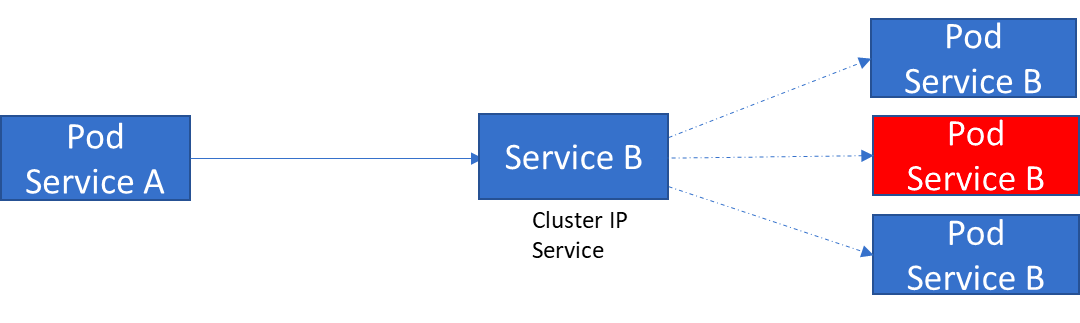
通过持久 IP 地址上的 ClusterIP 服务公开的 Pod,客户端与服务对话,而不是直接与 Pod 对话。
这种抽象是由 Kubernetes 中一个名为ClusterIP service的服务对象提供的。它在多个节点上产生,从而在集群中创建单个服务。它可以接收任何端口上的请求并将其转发到 pod 上的任何端口。
因此,当应用服务 A 需要与服务 B 对话时,它会调用服务 B 对象的 ClusterIP 服务,而不是运行该服务的单个 pod。
ClusterIP 使用 Kubernetes 中标签和选择器的标准模式来不断扫描匹配选择标准的 pod。Pod 有标签,服务有选择器来查找标签。使用它,可以进行基本的流量拆分,其中新旧版本的微服务在同一个 clusterIP 服务后共存。
CoreDNS ~ 集群内的服务发现
现在服务 B 已经获得了一个持久的 IP 地址,服务 A 仍然需要知道这个 IP 地址是什么,然后才能与服务 B 通信。
Kubernetes 支持使用 CoreDNS 进行名称解析。服务 A 应该知道它需要与之通信的 ClusterIP 的名称(和端口)。
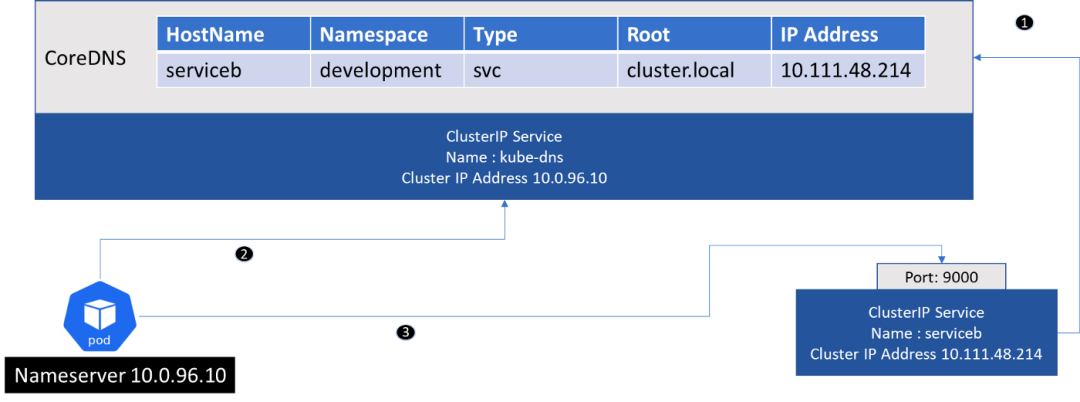
- CoreDNS 扫描集群,每当创建 ClusterIP 服务时,它的条目就会添加到 DNS 服务器(如果已配置,它还会为每个 pod 添加一个条目,但它与服务到服务的通信无关)。
- 接下来,CoreDNS 将自己暴露为 cluster IP 服务(默认称为 kube-dns),并且该服务被配置为 pod 中的 nameserver。
- 发起请求的 Pod 从 DNS 获取 ClusterIP 服务的 IP 地址,然后可以使用 IP 地址和端口发起请求。
Kube-proxy 打通 Service 和后端 Pod 之间(DNAT)
到目前为止,从本文来看,似乎是 ClusterIP 服务将请求调用转发到后端 Pod。但实际上,它是由 Kube-proxy 完成的。
Kube-proxy 在每个节点上运行,并监视 Service 及其选择的 Pod(实际上是 Endpoint 对象)。
- 当节点上运行的 pod 向 ClusterIP 服务发出请求时,kube-proxy 会拦截它。
- 通过查看目的 IP 地址和端口,可以识别目的 ClusterIP 服务。并将此请求的目的地替换为实际 Pod 所在的端点地址。
如何协同工作?
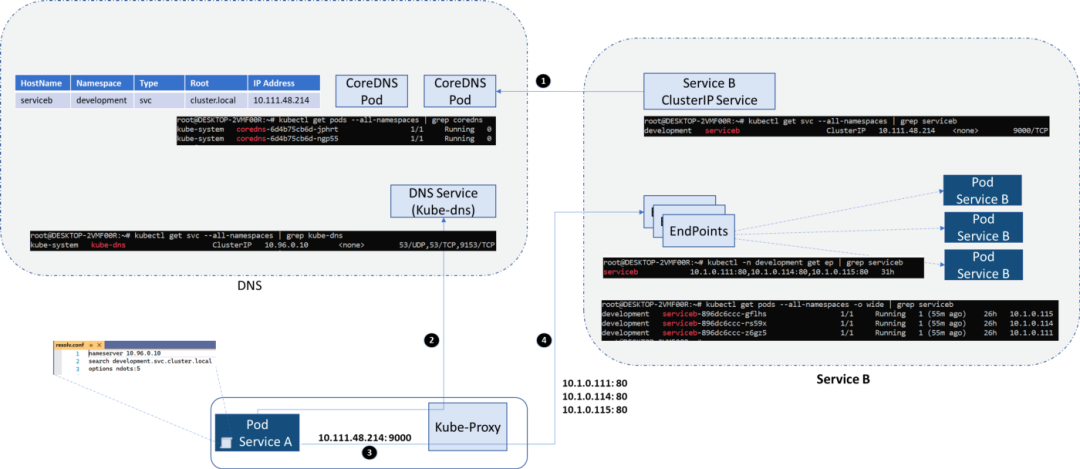
- 目标的 ClusterIP 服务在 CoreDNS 中注册
- DNS 解析:每个 pod 都有一个 resolve.conf 文件,其中包含 CoreDNS 服务的 IP 地址,pod 执行 DNS 查找。
- Pod 使用它从 DNS 收到的 IP 地址和它已经知道的端口来调用 clusterIP 服务。
- 目标地址转换:Kube-proxy 将目标 IP 地址更新为服务 B 的 Pod 可用的地址。
概述
通过本文,我们看到了使服务到服务通信成为可能的原生 Kubernetes 对象,这些细节对应用程序层是隐藏的。
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。
🍀 微信公众号
《云原生架构师实战》🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 博客
www.onlyyou520.com
🍀 知乎
https://www.zhihu.com/people/foryouone

🍀 语雀
https://www.yuque.com/books/share/34a34d43-b80d-47f7-972e-24a888a8fc5e?# 《云笔记最佳实践》

最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
-
相关阅读:
FPGA HLS stream与dataflow
jmeter监听每秒点击数(Hits per Second)
Verdi 基础介绍
【Netty 从成神到升仙系列 四】让我们一起探索 Netty 中的零拷贝
WPF性能优化:Freezable 对象
基于PySide6的数据处理及可视化分析软件开发
《深度探索C++对象模型》阅读笔记 第七章 站在对象模型的尖端
技术分享 oracle中fm的作用
向前看!JavaScript 正则表达式进阶指南
小迪安全34WEB 攻防-通用漏洞&文件上传&黑白盒审计&逻辑&中间件&外部引用
- 原文地址:https://blog.csdn.net/weixin_39246554/article/details/126082267
