-
[iOS]-weak底层原理(sidetable相关,附带引用计数原理)
目录:
参考的博客:
iOS weak 底层实现原理(一):SideTable|s、weak_table_t、weak_entry_t 等数据结构
runtime(三) weak_table_t
runtime(二) SideTables
[iOS开发]weak底层原理
iOS底层原理:weak的实现原理Retain、release复习
我们在学习ARC的过程中了解了retain和release相关于sidetable的实现原理:
retain:
不支持Nonpointer isa 的处理:
去sidetable取出计数信息 执行加一操作支持Nonpointer isa的处理:
- 首先判断是否为标签指针类型 如果是 直接返回
- 进入do-while处理逻辑
- 先判断是否为 其一定支持Nonpointer isa的架构,但是isa没有额外信息
如果没有额外信息 那就和不支持意义一样(判断是否有优化) 引用计数存储在sidetable中,走sidetable的引用计数+1的流程 - 判断对象是否正在释放,如果正在释放则执行dealloc流程。
- 有存储额外信息,包含引用计数。我们尝试对isa中的extra_rc++加一进行测试
3.1 如果没有溢出越界的情况,我们将isa的值修改为extra_rc++之后的值
3.2 如果有溢出 将一半的计数存储到extra_rc,另一半存储到sidetable中去 设置设置标志位位true

release:
- 依旧是判断是否为taggedPointer,如果是,直接返回false,不需要dealloc
- 判断是否有优化 如果没有 就直接操作散列表,使引用计数-1
- 判断是引用计数为否为0 如果是0则执行dealloc流程
- 若isa有优化,则对象的isa位存储的引用计数减一,且通过carry判断是否向下溢出了 结果为负数(下图有点问题 应该是判断是有向下溢出),如果是,如果到-1 就放弃newisa改为old,并将散列表中一半引用计数取出来,然后将这一半引用计数减一在存到isa的extra_rc
- 如果sidetable的引用计数为0,对象进行dealloc流程

其实和retain一样 不过release操作变成-1 并且需要注意从sidetable中的一半减一放入
从上面我们知道了存储引用计数的方式有两种,一种是通过isa,另一种是通过sideTable
SideTable
下面我们先来了解两个概念:
HashMap (哈希表):
基于数组的一种数据结构,通过一定的算法,把key进行运算得出一个数字,用这个数字做数组下标,将value存入这个下标对应的内存之中。HashTon (哈希桶):
哈希算法算出的数字有可能会重复,对于哈希值重复的数据,如何存入哈希表呢?常用方法有闭散列和开散列等方式,其中采用开散列方式的哈希表称为哈希桶。开散列(哈希桶) :就是在哈希值对应的位置上,使用链表或数组,将哈希值冲突的数据存入这个链表或者数组中,提高查找效率
闭散列(即开放地址法):当发生哈希冲突时,如果该哈希表还没有被填满,那么就把该元素放到哈希表的下一个空闲的位置。为了管理所有对象的引用计数和
weak指针,苹果创建了一个全局的SideTables,名字后面有一个"s",但它其实不是一个数组,而是一个全局的Hash桶,里面的内容装的都是SideTable结构体。它用对象的内存地址当作key,来管理引用计数和weak指针。我们来看一下SideTable的源码实现:
struct SideTable { spinlock_t slock;//自旋锁 RefcountMap refcnts;//存放引用计数 weak_table_t weak_table;//weak_table是一个哈希表 后方代码省略...- 1
- 2
- 3
- 4
- 5
接着我们来看一下SideTable中的这三个成员变量:
spinlock_t slock 自旋锁
锁是线程同步时的一个重要工具
操作系统中有五大锁(操作系统还没有学到这地方,先写着基础概念,后续会有博客详细介绍):- 信号量:
- 整型信号量S,S<=0表示该资源已被占用,S>0表示该资源可用,pv操作进行访问
- 记录型信号量 s.value > 0 表示该资源可用的数目;< 0表示在等待链表中已经阻塞的数目
- AND型信号量,AND型信号量是指同时需要多个资源且每种占用一个资源时的信号量操作。
- 信号量集 对应有多种资源,相当于记录型的集合
- 互斥量:和二元信号量类似,唯一不同的是,互斥量的获取和释放必须是在同一个线程中进行的。如果一个线程去释放一个不是其所占有的信号量是无效的。而信号量是可以由其他线程释放的。
- 临界区:并发执行的进程中,访问临界资源的必须互斥执行的程序段叫临界区
- 读写锁:解决读者写者问题产生的锁
- 条件变量:条件变量相当于一种通知机制。多个线程可以设置等待该条件变量,而一旦另外的线程设置了该条件变量(相当于唤醒条件变量)后,多个等待的线程就可以继续执行了
分离锁、分拆锁
对象引用计数相关操作应该是原子性的,不然如果多个线程同时去写一个对象的引用计数,那么就会造成数据混乱,也就失去了内存管理的意义。同时又应为内存中对象的数量也是很大的,需要非常频繁的操作SideTables,所以不能对整个Hash表加锁,否则就会非常影响效率,所以苹果采用了分离锁技术
- 分拆锁 (lock splitting) 和分离锁 (lock striping) 是降低线程请求锁的频率从而达到降低锁竞争的两种方式。相互独立的状态变量,应该使用独立的锁进行保护。但有时开发者会错误的使用一个锁保护所有的状态变量。对于这些锁需要仔细分配,以降低发生死锁的风险
- 如果一个锁守护多个相互独立的状态变量,你可能能够通过分拆锁,使每一个锁守护不同的变量。这样可以使每一个锁被请求的频率都变小了。分拆锁对于中等竞争强度的锁,能够有效的把它们大部分转化为非竞争的锁,使性能和可伸缩性都得到了提高。
- 分拆锁有时候可以被扩展,分成若干加锁块的集合,并且它们归属于相互独立的对象,这种情况就是分离锁。
我们将每个
SideTable里的每个对象的引用计数都加一把锁,这就是分拆锁,虽然安全,但是消耗很大。我们给每个
SideTable加上一把锁,只让某个SideTable不能多次访问,这就是分离锁相比之下,分拆锁管理的内容更加细微,而分离锁管理的内容更加广泛
自旋锁
说到自旋锁就要谈到互斥锁:
- 相同点:都能保证同一时间只有一个线程访问共享资源。都能保证线程安全。
- 不同点:
- 互斥锁:如果共享数据已经有其他线程加锁了,线程会进入休眠状态等待锁。一旦被访问的资源被解锁,则等待资源的线程会被唤醒。
- 自旋锁:如果共享数据已经有其他线程加锁了,线程会以死循环的方式等待锁,一旦被访问的资源被解锁,则等待资源的线程会立即执行。
- 自旋锁的效率高于互斥锁。但是我们要注意由于自旋时不释放CPU,因而持有自旋锁的线程应该尽快释放自旋锁,否则等待该自旋锁的线程会一直在哪里自旋,这就会浪费CPU时间。
- 在操作引用计数的时候对SideTable加锁,避免数据错误
苹果的选择
对于每个SideTable,中间都有自旋锁,同时也使用了分离锁为每个SideTable上锁,安全+效率非常合理
RefcountMap
来了解一下这个图:

以DisguisedPtr为key的hash表,用来存储OC对象的引用计数
DisguisedPtr就是我们想知道其引用计数的这个对象的地址,但是我们已经对retain中存储引用计数的方式十分清晰了,如果未开启isa优化 或 在isa优化情况下isa_t的extra_rc引用计数加一后向上溢出了,才会存入这个哈希表中。具体的引用计数表的查找和插入过程参考自该博客:runtime(二) SideTables
从中我们知道了SideTables实际上是一个全局的哈希桶:
static StripedMap<SideTable>& SideTables() { return *reinterpret_cast<StripedMap<SideTable>*>(SideTableBuf); }- 1
- 2
- 3
这个方法返回的是一个
StripedMap类型的引用:& template<typename T> class StripedMap { #if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR enum { StripeCount = 8 }; #else enum { StripeCount = 64 }; #endif struct PaddedT { T value alignas(CacheLineSize); }; PaddedT array[StripeCount]; ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
StripedMap 是一个模板类, 内部维护一个大小为 StripeCount 的数组, 数组的成员为结构体 PaddedT, PaddedT 结构体只有一个成员 value, value 的类型是 T.
这里涉及到泛型相关知识, 结合起来理解, 就是说 SideTables() 返回的 StripedMap, 是一个 value 为 SideTable 的哈希桶(由于 SideTable 内部又在维护数组, 所以这是一个哈希桶结构), 哈希值由对象的地址计算得出.SideTables 结构图见下:

我们再来看一下SideTable的完整源码结构:struct SideTable { spinlock_t slock; //线程锁 RefcountMap refcnts; weak_table_t weak_table; // 构造函数,只做了一件事把 weak_table 的空间置为 0 SideTable() { // 把从 &weak_table 位置开始的长度为 sizeof(weak_table) 的内存空间置为 0 memset(&weak_table, 0, sizeof(weak_table)); } // 析构函数(不能进行析构) ~SideTable() { // 看到 SidetTable 是不能析构的,如果进行析构则会直接终止运行 _objc_fatal("Do not delete SideTable."); } // 三个函数正对应了 StripedMap 中模版抽象类型 T 的接口要求,三个函数的内部都是直接调用 slock 的对应函数 void lock() { slock.lock(); } void unlock() { slock.unlock(); } void forceReset() { slock.forceReset(); } // Address-ordered lock discipline for a pair of side tables. // HaveOld 和 HaveNew 分别表示 lock1 和 lock2 是否存在, // 表示 __weak 变量是否指向有旧值和目前要指向的新值。 // lock1 代表旧值对象所处的 SideTable // lock2 代表新值对象所处的 SideTable // lockTwo 是根据谁有值就调谁的锁,触发加锁 (C++ 方法重载), // 如果两个都有值,那么两个都加锁,并且根据谁低,先给谁加锁,然后另一个后加锁 template<HaveOld, HaveNew> static void lockTwo(SideTable *lock1, SideTable *lock2); // 同上,对 slock 解锁 template<HaveOld, HaveNew> static void unlockTwo(SideTable *lock1, SideTable *lock2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
接着我们言归正传,看一下RefcountMap的定义:
typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap;- 1
其中DenseMap 又是一个模板类:
template<typename KeyT, typename ValueT, bool ZeroValuesArePurgeable = false, typename KeyInfoT = DenseMapInfo<KeyT> > class DenseMap : public DenseMapBase<DenseMap<KeyT, ValueT, ZeroValuesArePurgeable, KeyInfoT>, KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable> { ... BucketT *Buckets; unsigned NumEntries; unsigned NumTombstones; unsigned NumBuckets; ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
比较重要的成员有这几个:
- ZeroValuesArePurgeable 默认值是 false, 但 RefcountMap 指定其初始化为 true. 这个成员标记是否可以使用值为 0 (引用计数为 1) 的桶. 因为空桶存的初始值就是 0, 所以值为 0 的桶和空桶没什么区别. 如果允许使用值为 0 的桶, 查找桶时如果没有找到对象对应的桶, 也没有找到墓碑桶, 就会优先使用值为 0 的桶.
- Buckets 指针管理一段连续内存空间, 也就是数组, 数组成员是 BucketT 类型的对象, 我们这里将 BucketT 对象称为桶(实际上这个数组才应该叫桶, 苹果把数组中的元素称为桶应该是为了形象一些, 而不是哈希桶中的桶的意思). 桶数组在申请空间后, 会进行初始化, 在所有位置上都放上空桶(桶的 key 为 EmptyKey 时是空桶), 之后对引用计数的操作, 都要依赖于桶.
桶的数据类型实际上是 std::pair, 类似于 swift 中的元祖类型, 就是将对象地址和对象的引用计数(这里的引用计数类似于 isa, 也是使用其中的几个 bit 来保存引用计数, 留出几个 bit 来做其它标记位)组合成一个数据类型.
BucketT 的定义如下:
typedef std::pair<KeyT, ValueT> BucketT;- 1
- NumEntries 记录数组中已使用的非空的桶的个数.
- NumTombstones, Tombstone 直译为墓碑, 当一个对象的引用计数为0, 要从桶中取出时, 其所处的位置会被标记为 Tombstone. NumTombstones 就是数组中的墓碑的个数. 后面会介绍到墓碑的作用.
- NumBuckets 桶的数量, 因为数组中始终都充满桶, 所以可以理解为数组大小.
inline uint64_t NextPowerOf2(uint64_t A) { A |= (A >> 1); A |= (A >> 2); A |= (A >> 4); A |= (A >> 8); A |= (A >> 16); A |= (A >> 32); return A + 1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这是对应 64 位的提供数组大小的方法, 需要为桶数组开辟空间时, 会由这个方法来决定数组大小. 这个算法可以做到把最高位的 1 覆盖到所有低位. 例如 A = 0b10000, (A >> 1) = 0b01000, 按位与就会得到 A = 0b11000, 这个时候 (A >> 2) = 0b00110, 按位与就会得到 A = 0b11110. 以此类推 A 的最高位的 1, 会一直覆盖到高 2 位、高 4 位、高 8 位, 直到最低位. 最后这个充满 1 的二进制数会再加 1, 得到一个 0b1000…(N 个 0). 也就是说, 桶数组的大小会是 2^n.
RefcountMap 的工作逻辑(代码分析在最后)
- 通过计算对象地址的哈希值, 来从 SideTables 中获取对应的 SideTable. 哈希值重复的对象的引用计数存储在同一个 SideTable 里.
- SideTable 使用 find() 方法和重载 [] 运算符的方式, 通过对象地址来确定对象对应的桶. 最终执行到的查找算法是 LookupBucketFor().
- 查找算法会先对桶的个数进行判断, 如果桶数为 0 则 return false 回上一级调用插入方法. 如果查找算法找到空桶或者墓碑桶, 同样 return false 回上一级调用插入算法, 不过会先记录下找到的桶. 如果找到了对象对应的桶, 只需要对其引用计数 + 1 或者 - 1. 如果引用计数为 0 需要销毁对象, 就将这个桶中的 key 设置为 TombstoneKey
value_type& FindAndConstruct(const KeyT &Key) { BucketT *TheBucket; if (LookupBucketFor(Key, TheBucket)) return *TheBucket; return *InsertIntoBucket(Key, ValueT(), TheBucket); }- 1
- 2
- 3
- 4
- 5
- 6
- 插入算法会先查看可用量, 如果哈希表的可用量(墓碑桶+空桶的数量)小于 1/4, 则需要为表重新开辟更大的空间, 如果表中的空桶位置少于 1/8 (说明墓碑桶过多), 则需要清理表中的墓碑. 以上两种情况下哈希查找算法会很难查找正确位置, 甚至可能会产生死循环, 所以要先处理表, 处理表之后还会重新分配所有桶的位置, 之后重新查找当前对象的可用位置并插入. 如果没有发生以上两种情况, 就直接把新的对象的引用计数放入调用者提供的桶里.
到这里SideTables管理引用计数的过程就基本结束了。
下面放上大佬博客中的图解助于快速理解:

接下来就体现了墓碑的作用:- 如果 c 对象销毁后将下标 2 的桶设置为空桶而不置为墓碑桶的话, 此时为 e 对象增加引用计数, 根据哈希算法查找到下标为 2 的桶时, 就会直接插入, 无法为已经在下标为 4 的桶中的 e 增加引用计数,但是我们正常的流程中c 对象销毁后下标 2的桶将会被置为墓碑桶,这样的话,在对e对象增加引用计数的时候,根据哈希算法找到下标为2的桶时,就会将2跳过,往后继续查找,直至找到e对象所对应的桶为止,或者直至找到空桶新建一个存e对象的桶
- 如果此时初始化了一个新的对象 f, 根据哈希算法查找到下标为 2 的桶时发现桶中放置了墓碑, 此时会记录下来下标 2. 接下来继续哈希算法查找位置, 查找到空桶时, 就证明表中没有对象 f, 此时 f 使用记录好的下标 2 的墓碑桶而不是查找到的空桶, 就可以利用到已经释放的位置,保证哈希表中前面部分都是被利用或者待利用的状态。
查找某对象对应桶的源码如下:
bool LookupBucketFor(const LookupKeyT &Val, const BucketT *&FoundBucket) const { ... if (NumBuckets == 0) { //桶数是0 FoundBucket = 0; return false; //返回 false 回上层调用添加函数 } ... unsigned BucketNo = getHashValue(Val) & (NumBuckets-1); //将哈希值与数组最大下标按位与 unsigned ProbeAmt = 1; //哈希值重复的对象需要靠它来重新寻找位置 while (1) { const BucketT *ThisBucket = BucketsPtr + BucketNo; //头指针 + 下标, 类似于数组取值 //找到的桶中的 key 和对象地址相等, 则是找到 if (KeyInfoT::isEqual(Val, ThisBucket->first)) { FoundBucket = ThisBucket; return true; } //找到的桶中的 key 是空桶占位符, 则表示可插入 if (KeyInfoT::isEqual(ThisBucket->first, EmptyKey)) { if (FoundTombstone) ThisBucket = FoundTombstone; //如果曾遇到墓碑, 则使用墓碑的位置 FoundBucket = FoundTombstone ? FoundTombstone : ThisBucket; return false; //找到空占位符, 则表明表中没有已经插入了该对象的桶 } //如果找到了墓碑 if (KeyInfoT::isEqual(ThisBucket->first, TombstoneKey) && !FoundTombstone) FoundTombstone = ThisBucket; // 记录下墓碑 //这里涉及到最初定义 typedef objc::DenseMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
向某对象的引用计数桶插入代码如下
BucketT *InsertIntoBucketImpl(const KeyT &Key, BucketT *TheBucket) { unsigned NewNumEntries = getNumEntries() + 1; //桶的使用量 +1 unsigned NumBuckets = getNumBuckets(); //桶的总数 if (NewNumEntries*4 >= NumBuckets*3) { //使用量超过 3/4 this->grow(NumBuckets * 2); //数组大小 * 2做参数, grow 中会决定具体数值 //grow 中会重新布置所有桶的位置, 所以将要插入的对象也要重新确定位置 LookupBucketFor(Key, TheBucket); NumBuckets = getNumBuckets(); //获取最新的数组大小 } //如果空桶数量少于 1/8, 哈希查找会很难定位到空桶的位置 if (NumBuckets-(NewNumEntries+getNumTombstones()) <= NumBuckets/8) { //grow 以原大小重新开辟空间, 重新安排桶的位置并能清除墓碑 this->grow(NumBuckets); LookupBucketFor(Key, TheBucket); //重新布局后将要插入的对象也要重新确定位置 } assert(TheBucket); //找到的 BucketT 标记了 EmptyKey, 可以直接使用 if (KeyInfoT::isEqual(TheBucket->first, getEmptyKey())) { incrementNumEntries(); //桶使用量 +1 } else if (KeyInfoT::isEqual(TheBucket->first, getTombstoneKey())) { //如果找到的是墓碑 incrementNumEntries(); //桶使用量 +1 decrementNumTombstones(); //墓碑数量 -1 } else if (ZeroValuesArePurgeable && TheBucket->second == 0) { //找到的位置是 value 为 0 的位置 TheBucket->second.~ValueT(); //测试中这句代码被直接跳过并没有执行, value 还是 0 } else { // 其它情况, 并没有成员数量的变化(官方注释是 Updating an existing entry.) } return TheBucket; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
weak部分
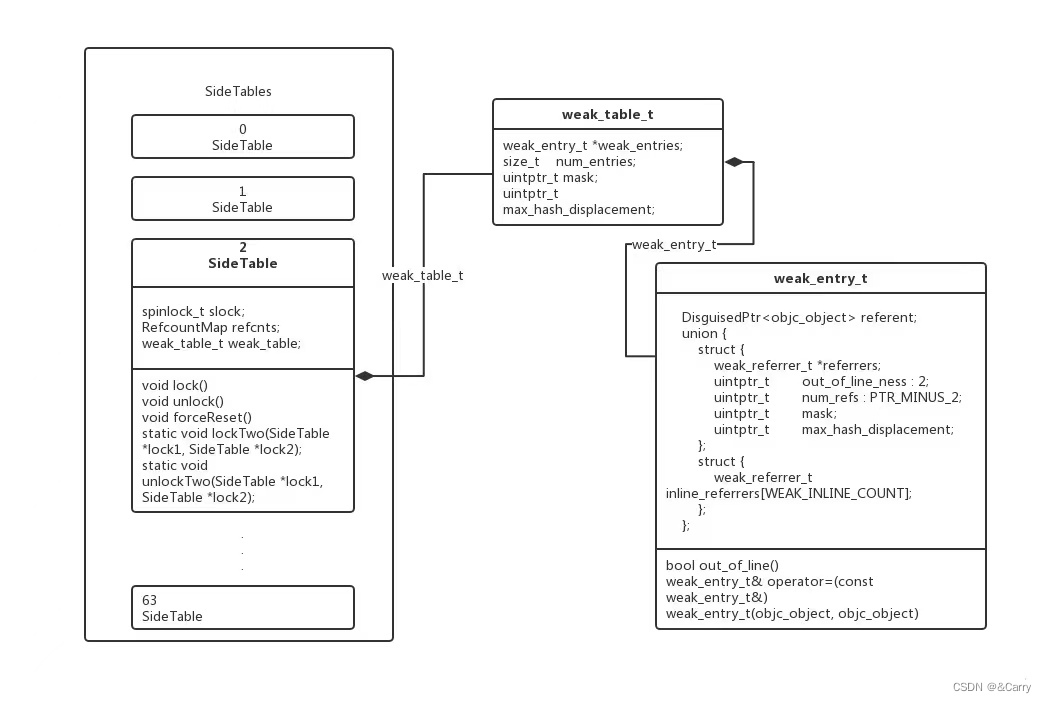
weak_table_t
weak_table_t在SideTable结构体中,储存对象弱引用指针的Hash表,weak功能实现的核心数据结构首先我们来看一下weak_table_t结构体的源码:
struct weak_table_t { weak_entry_t *weak_entries;//连续地址空间的头指针,数组 size_t num_entries;//数组中已占用位置的个数 uintptr_t mask;//数组下标最大值(即数组大小 -1) uintptr_t max_hash_displacement;//最大哈希偏移值 };- 1
- 2
- 3
- 4
- 5
- 6
weak_table是一个哈希表的结构, 根据weak指针指向的对象的地址计算哈希值, 哈希值相同的对象按照下标+1的形式向后查找可用位置, 是典型的闭散列算法. 最大哈希偏移值即是所有对象中计算出的哈希值和实际插入位置的最大偏移量, 在查找时可以作为循环的上限.weak_entry_t 的成员
源码如下:
struct weak_entry_t { DisguisedPtr<objc_object> referent; //对象地址 union { //这里又是一个联合体, 苹果设计的数据结构的确很棒 struct { // 因为这里要存储的又是一个 weak 指针数组, 所以苹果继续选择采用哈希算法 weak_referrer_t *referrers; //指向 referent 对象的 weak 指针数组 uintptr_t out_of_line_ness : 2; //这里标记是否超过内联边界, 下面会提到 uintptr_t num_refs : PTR_MINUS_2; //数组中已占用的大小 uintptr_t mask; //数组下标最大值(数组大小 - 1) uintptr_t max_hash_displacement; //最大哈希偏移值 }; struct { //这是一个取名叫内联引用的数组 weak_referrer_t inline_referrers[WEAK_INLINE_COUNT]; //宏定义的值是 4 }; }; // weak_entry_t 的赋值操作,直接使用 memcpy 函数拷贝 other 内存里面的内容到 this 中, // 而不是用复制构造函数什么的形式实现,应该也是为了提高效率考虑的... weak_entry_t& operator=(const weak_entry_t& other) { memcpy(this, &other, sizeof(other)); return *this; } // 返回 true 表示使用 referrers 哈希数组 false 表示使用 inline_referrers 数组保存 weak_referrer_t bool out_of_line() { return (out_of_line_ness == REFERRERS_OUT_OF_LINE); } // weak_entry_t 的构造函数 // newReferent 是原始对象的指针, // newReferrer 则是指向 newReferent 的弱引用变量的指针。 // 初始化列表 referent(newReferent) 会调用: DisguisedPtr(T* ptr) : value(disguise(ptr)) { } 构造函数, // 调用 disguise 函数把 newReferent 转化为一个整数赋值给 value。 weak_entry_t(objc_object *newReferent, objc_object **newReferrer) : referent(newReferent) { // 把 newReferrer 放在数组 0 位,也会调用 DisguisedPtr 构造函数,把 newReferrer 转化为整数保存 inline_referrers[0] = newReferrer; // 循环把 inline_referrers 数组的剩余 3 位都置为 nil for (int i = 1; i < WEAK_INLINE_COUNT; i++) { inline_referrers[i] = nil; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
我们通过对象的地址, 可以在
weak_table_t中找到对应的weak_entry_t,weak_entry_t中保存了所有指向这个对象的weak指针苹果在
weak_entry_t中又使用了一个共用体, 第一个结构体中out_of_line_ness占用2bit,num_refs在64位环境下占用了62bit, 所以实际上两个结构体都是32 字节, 共用一段地址. 当指向这个对象的weak指针不超过4个, 则直接使用数组inline_referrers, 省去了哈希操作的步骤, 如果weak指针个数超过了4个, 就要使用第一个结构体中的哈希表.先放上
weak_table_t的工作逻辑(后面再放上源码实现,这样便于理解):- 在
ARC下, 编译器会自动添加管理引用计数的代码,weak指针赋值的时候, 编译器会调用storeWeak来赋值, 若weak指针有指向的对象, 那么会先调用weak_unregister_no_lock()方法来从原有的表中先删除这个weak指针, 然后再调用weak_register_no_lock()来向对应的表中插入这个weak指针 - 查找时先用被指向对象的地址来计算哈希值, 从
SideTables()中找到对应的SideTable, 再进一步使用这个对象地址来从SideTable的weak_table中找到对应的weak_entry_t. 最终要进行操作的就是这个weak_entry_t. - 如果这个对象的
weak指针不超过4个, 则直接操作inline_referrers数组, 否则会为referrers数组申请内存, 采用哈希算法来管理表. - 删除旧的
weak指针时, 会使用原本指向的对象的地址来查找对应的weak_entry_t, 从中删除这个weak指针. 如果删除之后weak指针数组为空, 则销毁这个weak_entry_t, 原有位置置空, 原本被指向对象的isa指针的weak引用标记位0. - 添加新的
weak指针时, 如果查找到对应的weak_entry_t, 则将weak指针插入到referrers数组中. 如果没找到则创建一个weak_entry_t配置好后插入weak_table_t的数组中.
到这里
weak_table_t中比较重要的逻辑就完成了,这就是ARC为我们管理weak指针的步骤weak_table_t 结构图
图示如下:

weak_table_t中的weak_entries是成员为weak_entry_t的数组,weak_entry_t就是对象与其weak指针数组的对应关系.我们现在申请一个__weak修饰符修饰的变量,然后看一下汇编:

说到底就是两个重要部分:objc_initWeak和objc_destroyWeak,其中,咱们主要进行分析的是:objc_initWeak。我们看一下对应的源码部分:
objc_initWeak
id objc_initWeak(id *location, id newObj) { if (!newObj) { *location = nil; return nil; } return storeWeak<DontHaveOld, DoHaveNew, DoCrashIfDeallocating> (location, (objc_object*)newObj); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
该方法的两个参数:
location和newObj。- location :
__weak指针的地址,存储指针的地址,这样便可以在最后将其指向的对象置为nil。 - newObj : 所引用的对象。即例子中的
obj。
很显然,如果这个weak指针如果要指向一个对象的话,就会调用
storeWeak方法,下面我们主要来看一下这个storeWeak方法的源码实现。storeWeak
storeWeak方法源码如下:// Template parameters. enum HaveOld { DontHaveOld = false, DoHaveOld = true }; enum HaveNew { DontHaveNew = false, DoHaveNew = true }; enum CrashIfDeallocating { DontCrashIfDeallocating = false, DoCrashIfDeallocating = true }; template <HaveOld haveOld, HaveNew haveNew, CrashIfDeallocating crashIfDeallocating> static id storeWeak(id *location, objc_object *newObj) { assert(haveOld || haveNew); if (!haveNew) assert(newObj == nil); Class previouslyInitializedClass = nil; id oldObj; SideTable *oldTable; SideTable *newTable; // Acquire locks for old and new values. // Order by lock address to prevent lock ordering problems. // Retry if the old value changes underneath us. retry: if (haveOld) { // 如果weak ptr之前弱引用过一个obj,则将这个obj所对应的SideTable取出,赋值给oldTable oldObj = *location; oldTable = &SideTables()[oldObj]; } else { oldTable = nil; // 如果weak ptr之前没有弱引用过一个obj,则oldTable = nil } if (haveNew) { // 如果weak ptr要weak引用一个新的obj,则将该obj对应的SideTable取出,赋值给newTable newTable = &SideTables()[newObj]; } else { newTable = nil; // 如果weak ptr不需要引用一个新obj,则newTable = nil } // 加锁操作,防止多线程中竞争冲突 SideTable::lockTwo<haveOld, haveNew>(oldTable, newTable); // location 应该与 oldObj 保持一致,如果不同,说明当前的 location 已经处理过 oldObj 可能是又被其他线程所修改 if (haveOld && *location != oldObj) { SideTable::unlockTwo<haveOld, haveNew>(oldTable, newTable); goto retry; } // Prevent a deadlock between the weak reference machinery // and the +initialize machinery by ensuring that no // weakly-referenced object has an un-+initialized isa. // 防止弱引用间死锁 // 并且通过+initialize初始化构造器保证所有弱引用的isa非空指向 if (haveNew && newObj) { Class cls = newObj->getIsa(); if (cls != previouslyInitializedClass && !((objc_class *)cls)->isInitialized()) // 如果cls还没有初始化,先初始化,再尝试设置weak { SideTable::unlockTwo<haveOld, haveNew>(oldTable, newTable); _class_initialize(_class_getNonMetaClass(cls, (id)newObj)); // If this class is finished with +initialize then we're good. // If this class is still running +initialize on this thread // (i.e. +initialize called storeWeak on an instance of itself) // then we may proceed but it will appear initializing and // not yet initialized to the check above. // Instead set previouslyInitializedClass to recognize it on retry. previouslyInitializedClass = cls; // 这里记录一下previouslyInitializedClass, 防止改if分支再次进入 goto retry; // 重新获取一遍newObj,这时的newObj应该已经初始化过了 } } // Clean up old value, if any. if (haveOld) { weak_unregister_no_lock(&oldTable->weak_table, oldObj, location); // 如果weak_ptr之前弱引用过别的对象oldObj,则调用weak_unregister_no_lock,在oldObj的weak_entry_t中移除该weak_ptr地址 } // Assign new value, if any. if (haveNew) { // 如果weak_ptr需要弱引用新的对象newObj // (1) 调用weak_register_no_lock方法,将weak ptr的地址记录到newObj对应的weak_entry_t中 newObj = (objc_object *) weak_register_no_lock(&newTable->weak_table, (id)newObj, location, crashIfDeallocating); // weak_register_no_lock returns nil if weak store should be rejected // (2) 更新newObj的isa的weakly_referenced bit标志位(因为类的优化版的isa指针里面有一个标记是否被弱引用的成员变量) // Set is-weakly-referenced bit in refcount table. if (newObj && !newObj->isTaggedPointer()) { newObj->setWeaklyReferenced_nolock(); } // Do not set *location anywhere else. That would introduce a race. // (3)*location 赋值,也就是将weak ptr直接指向了newObj。可以看到,这里并没有将newObj的引用计数+1 *location = (id)newObj; // 将weak ptr指向object } else { // No new value. The storage is not changed. } // 解锁,其他线程可以访问oldTable, newTable了 SideTable::unlockTwo<haveOld, haveNew>(oldTable, newTable); return (id)newObj; // 返回newObj,此时的newObj与刚传入时相比,weakly-referenced bit位置1 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
storeWeak方法的实现代码虽然有些长,但是并不难以理解。下面我们来分析下该方法的实现:storeWeak方法实际上是接收了3个参数,分别是haveOld、haveNew和crashIfDeallocating,这三个参数都是以模板的方式传入的,是三个bool类型的参数。 分别表示weak指针之前是否指向了一个弱引用,weak指针是否需要指向一个新的引用,若果被弱引用的对象正在析构,此时再弱引用该对象是否应该crash。- 该方法维护了
oldTable和newTable分别表示旧的引用弱表和新的弱引用表,它们都是SideTable的hash表。 - 如果
weak指针之前指向了一个弱引用,则会调用weak_unregister_no_lock方法将旧的weak指针地址移除(前提是weak指针会指向一个新的对象)。 - 如果
weak指针需要指向一个新的引用,则会调用weak_register_no_lock方法将新的weak指针地址添加到弱引用表中。 - 调用
setWeaklyReferenced_nolock方法修改weak新引用的对象的bit标志位(优化版isa指针的标记是否被弱引用的成员变量)
我们清楚地知道了向
weak_entry_t中添加新指向的对象时的方法是weak_register_no_lock,现在我们就来看看它的源码。weak_register_no_lock
首先放上函数调用时传的参数接口,便于下方阅读源码:
weak_register_no_lock(&newTable->weak_table, (id)newObj, location, crashIfDeallocating);- 1
- 2
weak_register_no_lock源码如下:id weak_register_no_lock(weak_table_t *weak_table, id referent_id, id *referrer_id, bool crashIfDeallocating) { objc_object *referent = (objc_object *)referent_id; objc_object **referrer = (objc_object **)referrer_id; // 如果referent为nil 或 referent 采用了TaggedPointer计数方式,直接返回,不做任何操作 if (!referent || referent->isTaggedPointer()) return referent_id; // 确保被引用的对象可用(没有在析构,同时应该支持weak引用) bool deallocating; if (!referent->ISA()->hasCustomRR()) { deallocating = referent->rootIsDeallocating(); } else { BOOL (*allowsWeakReference)(objc_object *, SEL) = (BOOL(*)(objc_object *, SEL)) object_getMethodImplementation((id)referent, SEL_allowsWeakReference); if ((IMP)allowsWeakReference == _objc_msgForward) { return nil; } deallocating = ! (*allowsWeakReference)(referent, SEL_allowsWeakReference); } // 正在析构的对象,不能够被弱引用 if (deallocating) { if (crashIfDeallocating) { _objc_fatal("Cannot form weak reference to instance (%p) of " "class %s. It is possible that this object was " "over-released, or is in the process of deallocation.", (void*)referent, object_getClassName((id)referent)); } else { return nil; } } // now remember it and where it is being stored // 在 weak_table中找到referent对应的weak_entry,并将referrer加入到weak_entry中 weak_entry_t *entry; if ((entry = weak_entry_for_referent(weak_table, referent))) { // 如果能找到weak_entry,则讲referrer插入到weak_entry中 append_referrer(entry, referrer); // 将referrer插入到weak_entry_t的引用数组中 } else { // 如果找不到,就新建一个 weak_entry_t new_entry(referent, referrer); weak_grow_maybe(weak_table); weak_entry_insert(weak_table, &new_entry); } // Do not set *referrer. objc_storeWeak() requires that the // value not change. return referent_id; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
该方法需要传进四个参数,它们代表的意义如下:
- weak_table:
weak_table_t结构类型的全局的弱引用表。 - referent_id:
weak指针。 - *referrer_id:
weak指针地址。 - crashIfDeallocating : 若果被弱引用的对象正在析构,此时再弱引用该对象是否应该
crash。
从上面的代码我么可以知道该方法主要的做了如下几个方便的工作:
- 如果
referent为nil或referent采用了TaggedPointer计数方式,直接返回,不做任何操作。 - 如果对象正在析构,则抛出异常。
- 如果对象不能被
weak引用,直接返回nil。 - 如果对象没有再析构且可以被
weak引用,则调用weak_entry_for_referent方法根据弱引用对象的地址从弱引用表中找到对应的weak_entry,如果能够找到则调用append_referrer方法向其中插入weak指针地址。否则新建一个weak_entry。
接下来我们就来看从弱引用表中找相应
weak_entry的方法weak_entry_for_referent的源码实现:weak_entry_for_referent
源码如下:
static weak_entry_t * weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent) { assert(referent); weak_entry_t *weak_entries = weak_table->weak_entries; if (!weak_entries) return nil; size_t begin = hash_pointer(referent) & weak_table->mask; // 这里通过 & weak_table->mask的位操作,来确保index不会越界 size_t index = begin; size_t hash_displacement = 0; while (weak_table->weak_entries[index].referent != referent) { index = (index+1) & weak_table->mask; if (index == begin) bad_weak_table(weak_table->weak_entries); // 触发bad weak table crash hash_displacement++; if (hash_displacement > weak_table->max_hash_displacement) { // 当hash冲突超过了可能的max hash 冲突时,说明元素没有在hash表中,返回nil return nil; } } return &weak_table->weak_entries[index]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
接着我们来看一下向
weak_entry中添加元素的方法append_referrer的源码实现:append_referrer
static void append_referrer(weak_entry_t *entry, objc_object **new_referrer) { if (! entry->out_of_line()) { // 如果weak_entry 尚未使用动态数组,走这里 // Try to insert inline. //尝试插入内联引用的数组 for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) { if (entry->inline_referrers[i] == nil) { entry->inline_referrers[i] = new_referrer; return; } } // 如果inline_referrers的位置已经存满了,则要转型为referrers,做动态数组。 // Couldn't insert inline. Allocate out of line. weak_referrer_t *new_referrers = (weak_referrer_t *) calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t)); // This constructed table is invalid, but grow_refs_and_insert // will fix it and rehash it. for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) { new_referrers[i] = entry->inline_referrers[I]; } entry->referrers = new_referrers; entry->num_refs = WEAK_INLINE_COUNT; entry->out_of_line_ness = REFERRERS_OUT_OF_LINE; entry->mask = WEAK_INLINE_COUNT-1; entry->max_hash_displacement = 0; } // 对于动态数组的附加处理: assert(entry->out_of_line()); // 断言: 此时一定使用的动态数组 if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) { // 如果动态数组中元素个数大于或等于数组位置总空间的3/4,则扩展数组空间为当前长度的一倍 return grow_refs_and_insert(entry, new_referrer); // 扩容,并插入 } // 如果不需要扩容,直接插入到weak_entry中 // 注意,weak_entry是一个哈希表,key:w_hash_pointer(new_referrer) value: new_referrer // 细心的人可能注意到了,这里weak_entry_t 的hash算法和 weak_table_t的hash算法是一样的,同时扩容/减容的算法也是一样的 size_t begin = w_hash_pointer(new_referrer) & (entry->mask); // '& (entry->mask)' 确保了 begin的位置只能大于或等于 数组的长度 size_t index = begin; // 初始的hash index size_t hash_displacement = 0; // 用于记录hash冲突的次数,也就是hash再位移的次数 while (entry->referrers[index] != nil) { hash_displacement++; index = (index+1) & entry->mask; // index + 1, 移到下一个位置,再试一次能否插入。(这里要考虑到entry->mask取值,一定是:0x111, 0x1111, 0x11111, ... ,因为数组每次都是*2增长,即8, 16, 32,对应动态数组空间长度-1的mask,也就是前面的取值。) if (index == begin) bad_weak_table(entry); // index == begin 意味着数组绕了一圈都没有找到合适位置,这时候一定是出了什么问题。 } if (hash_displacement > entry->max_hash_displacement) { // 记录最大的hash冲突次数, max_hash_displacement意味着: 我们尝试至多max_hash_displacement次,肯定能够找到object对应的hash位置 entry->max_hash_displacement = hash_displacement; } // 将ref存入hash数组,同时,更新元素个数num_refs weak_referrer_t &ref = entry->referrers[index]; ref = new_referrer; entry->num_refs++; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
这段代码首先确定是使用定长数组还是动态数组,如果是使用定长数组,则直接将
weak指针地址添加到数组即可,如果定长数组已经用尽,则需要将定长数组中的元素转存到动态数组中。接着我们来看一下
weak指针移除弱引用,需要清除weak_entry时调用的方法:weak_unregister_no_lock,方法里面将旧的weak指针地址移除了。weak_unregister_no_lock
如果
weak指针之前指向了一个弱引用,则会调用weak_unregister_no_lock方法将旧的weak指针地址移除。源码如下:void weak_unregister_no_lock(weak_table_t *weak_table, id referent_id, id *referrer_id) { //对象的地址 objc_object *referent = (objc_object *)referent_id; //weak指针地址 objc_object **referrer = (objc_object **)referrer_id; weak_entry_t *entry; if (!referent) return; if ((entry = weak_entry_for_referent(weak_table, referent))) { // 查找到referent所对应的weak_entry_t remove_referrer(entry, referrer); // 在referent所对应的weak_entry_t的hash数组中,移除referrer // 移除元素之后, 要检查一下weak_entry_t的hash数组是否已经空了 bool empty = true; if (entry->out_of_line() && entry->num_refs != 0) { empty = false; } else { for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) { if (entry->inline_referrers[i]) { empty = false; break; } } } if (empty) { // 如果weak_entry_t的hash数组已经空了,则需要将weak_entry_t从weak_table中移除 weak_entry_remove(weak_table, entry); } } // Do not set *referrer = nil. objc_storeWeak() requires that the // value not change. }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
浅浅总结:
- 首先,它会在
weak_table中找出referent对应的weak_entry_t - 在
weak_entry_t中移除referrer - 移除元素后,判断此时
weak_entry_t中是否还有元素(empty==true?) - 如果此时
weak_entry_t已经没有元素了,则需要将weak_entry_t从weak_table中移除
到这里为止就是对于一个对象做
weak引用时底层做的事情,用weak引用对象后引用计数并不会加1,当对象释放时,所有weak引用它的指针又是如何自动设置为nil的呢?接下来我们就来分析一下dealloc时的源码实现,回答这个问题。
dealloc
当对象的引用计数为
0时,底层会调用_objc_rootDealloc方法对对象进行释放,而在_objc_rootDealloc方法里面会调用rootDealloc方法。如下是rootDealloc方法的代码实现:inline void objc_object::rootDealloc() { if (isTaggedPointer()) return; // fixme necessary? if (fastpath(isa.nonpointer && !isa.weakly_referenced && !isa.has_assoc && !isa.has_cxx_dtor && !isa.has_sidetable_rc)) { assert(!sidetable_present()); free(this); } else { object_dispose((id)this); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 首先判断对象是否是
Tagged Pointer,如果是则直接返回。 - 如果对象是采用了优化的isa计数方式,且同时满足对象没有被weak引用
!isa.weakly_referenced、没有关联对象!isa.has_assoc、没有自定义的C++析构方法!isa.has_cxx_dtor、没有用到SideTable来引用计数!isa.has_sidetable_rc则直接快速释放。 - 如果不能满足2中的条件,则会调用
object_dispose方法。
接着我们来分析一下
object_dispose方法的源码实现:object_dispose
object_dispose方法很简单,主要是内部调用了objc_destructInstance方法,源码如下:void *objc_destructInstance(id obj) { if (obj) { // Read all of the flags at once for performance. bool cxx = obj->hasCxxDtor(); bool assoc = obj->hasAssociatedObjects(); // This order is important. if (cxx) object_cxxDestruct(obj); if (assoc) _object_remove_assocations(obj); obj->clearDeallocating(); } return obj; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上面这一段代码很清晰,如果有自定义的
C++析构方法,则调用C++析构函数。如果有关联对象,则移除关联对象并将其自身从Association Manager的map中移除。调用clearDeallocating方法清除对象的相关引用。接着我们来分析清除对象的相关引用的方法
clearDeallocating。clearDeallocating
源码如下:
inline void objc_object::clearDeallocating() { if (slowpath(!isa.nonpointer)) { // Slow path for raw pointer isa. sidetable_clearDeallocating(); } else if (slowpath(isa.weakly_referenced || isa.has_sidetable_rc)) { // Slow path for non-pointer isa with weak refs and/or side table data. clearDeallocating_slow(); } assert(!sidetable_present()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
clearDeallocating中有两个分支,先判断对象是否采用了优化isa引用计数,如果没有的话则需要调用sidetable_clearDeallocating方法清理对象存储在SideTable中的引用计数数据。如果对象采用了优化isa引用计数,则判断是否有使用SideTable的辅助引用计数(isa.has_sidetable_rc)或者有weak引用(isa.weakly_referenced),符合这两种情况中一种的,调用clearDeallocating_slow方法。下面就介绍一下
sidetable_clearDeallocating方法和clearDeallocating_slow方法:sidetable_clearDeallocating
void objc_object::sidetable_clearDeallocating() { SideTable& table = SideTables()[this]; // clear any weak table items // clear extra retain count and deallocating bit // (fixme warn or abort if extra retain count == 0 ?) //清除所有弱表项 //清除额外的保留计数和释放位 //(如果额外保留计数==0,则修复警告或中止) table.lock(); RefcountMap::iterator it = table.refcnts.find(this); if (it != table.refcnts.end()) { if (it->second & SIDE_TABLE_WEAKLY_REFERENCED) { weak_clear_no_lock(&table.weak_table, (id)this); } table.refcnts.erase(it); } table.unlock(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
clearDeallocating_slow
NEVER_INLINE void objc_object::clearDeallocating_slow() { assert(isa.nonpointer && (isa.weakly_referenced || isa.has_sidetable_rc)); SideTable& table = SideTables()[this]; // 在全局的SideTables中,以this指针为key,找到对应的SideTable table.lock(); if (isa.weakly_referenced) { // 如果obj被弱引用 weak_clear_no_lock(&table.weak_table, (id)this); // 在SideTable的weak_table中对this进行清理工作 } if (isa.has_sidetable_rc) { // 如果采用了SideTable做引用计数 table.refcnts.erase(this); // 在SideTable的引用计数中移除this } table.unlock(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这里我们关心的是
weak_clear_no_lock方法。上面两个方法都调用了weak_clear_no_lock来做weak_table的清理工作。weak_clear_no_lock
源码如下:
void weak_clear_no_lock(weak_table_t *weak_table, id referent_id) { objc_object *referent = (objc_object *)referent_id; weak_entry_t *entry = weak_entry_for_referent(weak_table, referent); // 找到referent在weak_table中对应的weak_entry_t if (entry == nil) { /// XXX shouldn't happen, but does with mismatched CF/objc //printf("XXX no entry for clear deallocating %p\n", referent); return; } // zero out references weak_referrer_t *referrers; size_t count; // 找出weak引用referent的weak 指针地址数组以及数组长度 if (entry->out_of_line()) { referrers = entry->referrers; count = TABLE_SIZE(entry); } else { referrers = entry->inline_referrers; count = WEAK_INLINE_COUNT; } for (size_t i = 0; i < count; ++i) { objc_object **referrer = referrers[i]; // 取出每个weak ptr的地址 if (referrer) { if (*referrer == referent) { // 如果weak ptr确实weak引用了referent,则将weak ptr设置为nil,这也就是为什么weak 指针会自动设置为nil的原因 *referrer = nil; } else if (*referrer) { // 如果所存储的weak ptr没有weak 引用referent,这可能是由于runtime代码的逻辑错误引起的,报错 _objc_inform("__weak variable at %p holds %p instead of %p. " "This is probably incorrect use of " "objc_storeWeak() and objc_loadWeak(). " "Break on objc_weak_error to debug.\n", referrer, (void*)*referrer, (void*)referent); objc_weak_error(); } } } weak_entry_remove(weak_table, entry); // 由于referent要被释放了,因此referent的weak_entry_t也要移除出weak_table }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
注意里面有一个关键的部分:
if (*referrer == referent) { // 如果weak ptr确实weak引用了referent,则将weak ptr设置为nil,这也就是为什么weak 指针会自动设置为nil的原因 *referrer = nil; }- 1
- 2
- 3
这个部分就是真正实现我们
weak指针指向的对象被释放时,将weak指针指向置为nil的操作的实现。objc_destroyWeak
最后我们来看一下这个当weak指针销毁的时候调用的方法:
objc_destroyWeak,源码如下:void objc_destroyWeak(id *location) { (void)storeWeak<DoHaveOld, DontHaveNew, DontCrashIfDeallocating> (location, nil); }- 1
- 2
- 3
- 4
- 5
- 6
源码非常简单地调用了
storeWeak方法,storeWeak方法的源码我们之前已经分析过了,详情见上方源码注释。该处调用storeWeak方法之后,由于没有指向新的对象,若我们的weak指针原来已经指向一个对象的话就会到:weak_unregister_no_lock中来将旧的weak指针地址移除掉置为nil,关于weak_unregister_no_lock的具体源码实现详情见上方讲解。总结
1、
weak的原理在于底层维护了一张weak_table_t结构的hash表,key是所指对象的地址,value是weak指针的地址数组。
2、weak关键字的作用是弱引用,所引用对象的计数器不会加1,并在引用对象被释放的时候自动被设置为nil。
3、对象释放时,调用clearDeallocating函数根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录。
4、文章中介绍了SideTable、weak_table_t、weak_entry_t这样三个结构,它们之间的关系如下图所示:再次用大佬博客中的很全面的一张图解释整个
weak_table_t相关的关系:
-
相关阅读:
《微服务实战》 第二十九章 分布式事务框架seata AT模式
.NET C# 程序自动更新组件
OpenCV实现图像 开闭运算
Docker基础与常用命令
33-Java多线程
【Java基础】数组
创意电子学小知识:串联和并联
【知识网络分析】研究者合作网络(co-investigator)
【Python】关于自定义对象的Json序列化和反序列化
【python】python进行debug操作
- 原文地址:https://blog.csdn.net/m0_52192682/article/details/125948436


