-
多系统架构设计思考
第一个考虑的情况是下游有很多应用系统。
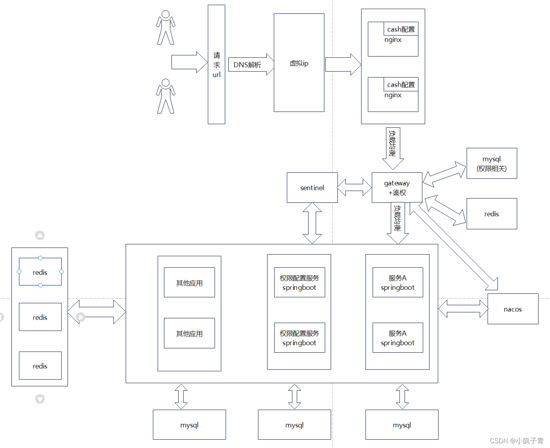
这种方式假定用户在平台里拥有一个唯一的id,其在各个系统中的访问权限需要进行配置,权限是在什么时候分配的?
用户第一次注册平台的时候,需要生产其默认权限(全平台默认权限),当其注册完成首次登录某个平台A的时候可能需要获取一些个人的信息,这时候平台A应该如何获取这些必要的个人信息?当某些信息被更新了,平台A可能也需要获得更新的信息,这时候他该如何获得这些信息?所以仅仅是用户登录更新信息就可能引发并发问题。所以应该采用主动通知的方式,当某个用户注册/中心系统更新个人信息则将该用户的信息往其他系统进行推送更新,当所有系统需要对用户主信息更新的时候统一调用某个中心端信息更新接口。
可以用rabitMq来叙述这些思想:

为了避免修改服务器的压力,可以考虑对于中心信息的修改设置修改时间限定或者修改频率限制,目前看微信、豆瓣、csdn之类的重要信息的修改他们都有时限限制或者次数限制,不知道他们是出于什么考虑的。
当用户登录的时候,不仅仅涉及到登录密码的验证,同时还涉及到登录权限的返回,以方便前端根据不同的权限显示界面模块。
假设某个用户试图访问平台A,但是该用户在平台A上没有登录过,则会跳转至登录页面,跳转的时候我们可以将某个隐藏参数param1带往登录页面,当用户登录的时候在查询权限的时候根据param1来返回用户在平台A上的权限列表,然后通过重定向定位到对应的页面,这样平台A的登录功能就完成了。

因为该系统的权限中心是一个中心,所以可以实现类似于sso的单点登录功能。
从这个设计架构来看,从单体往多系统演化的时候需要在设计初期就将用户权限数据库和业务数据库相分离,目前系统还没有引入日志的功能,可以考虑如下方式引入。

可以将日志数据表都设置为一类数据表,这种方式可以通过引入日志模块来实现代码的复用,同时对于日志的查询系统也可以采用代码复用的方式来查看操作日志。也许还可以换一种方式来生成和处理日志。
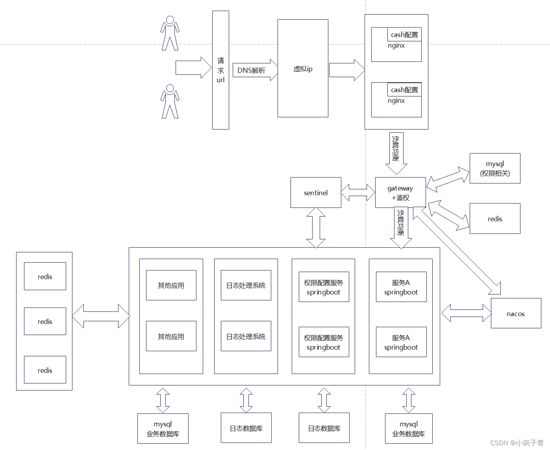
所有系统的日志操作都按照一定的格式发送到某个队列中,然后由日志处理系统统一将日志信息记录到某类数据库中,日志处理系统可以根据不同的系统来区分查询日志。
我认为前期单体架构设计数据库日志的时候可以多参考一些日志平台收集日志的必备字段来进行设计,这样为以后往日志平台的转换提供方便。
以上为低并发多系统架构的思考,接下来思考多并发多系统架构。
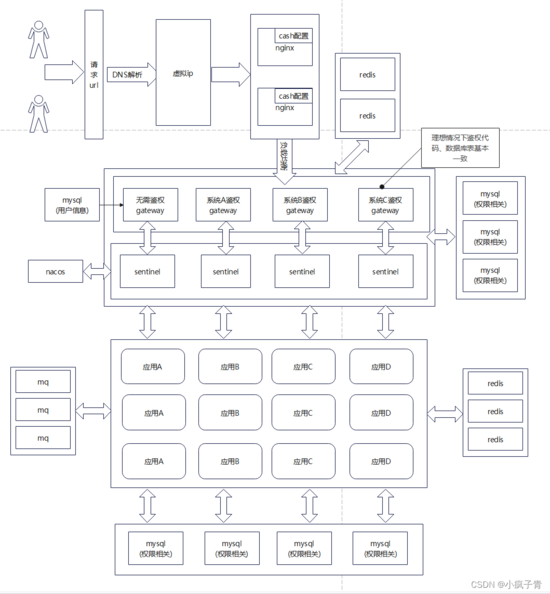
顾名思义就是说,应用本身还要进行应用拆分,鉴权前移也可以算是应用拆分。
单从架构上来看,鉴权中心也会成为系统瓶颈,这时候可以从访问不同系统的角度入手,不同的系统有一个与之对应的鉴权中心,架构图可以演变为如下的样子。

如果仍然有瓶颈,则可以考虑根据不同的用户id映射到不同的数据表中,即对表进行横向拆分。
通过以上我有这样的一个想法,可以将用户信息表、权限相关表、业务相关表、日志相关表进行拆分,这样完整的权限模块的代码在以后的所有项目中均可以实现完全复用(因为用户权限完全可以只通过用户id和其他关联表进行定位),如果能够足够的抽象,用户信息表实际上也可以做到完全抽象,例如只存放用户id、用户姓名、用户身份证号、用户电话、用户邮箱之类的信息。
这样鉴权压力可以缓解掉,接下来是下游系统如果高并发应该怎么处理?
如果访问量比较低的情况下,我们可以通过数据表加乐观锁的方式来解决数据一致性的问题,但是在并发情况下,mysql因为事务的原因会成为系统瓶颈,这时候应该如何处理?
1)使用redis锁机制,具体流程如下所示

我的构想是有两个字段,一个用于存放在销售出的数量变量A,另一个用于存放实际数量B。两个字段分别加锁,在用户下单情况下,只观察变量A和B,确保变量A和B的原子性,在消减数据时,需要修改数据B和消减数据A。
其他情况如a业务调用了b业务,但是他并不关心b业务做了什么,例如日志系统,就属于这种方式,可以将日志系统拆分出来。
其他情况如a业务调用了b业务,用户关心最终结果,但是a和b不会涉及数据一致性问题,这时候也可以采用消息队列的方式来进行;
为什么一定要去思考架构的演化过程,网上架构都有,思考了能干什么?
1)通过思考发现仅仅是一个简单的系统框架,在还不涉及高并发的情况下,要做到高可用都有很多地方需要注意,更何况在实际运行时还会出现很多状况,所以做任何项目前期都不应该太过乐观,需要做充足的准备;
2)通过对架构的思考会发现多面试中提及的数据一致性问题,在实际场景中很容易出现,不应该仅仅只是简简单单的认为那些只是背诵甲骨文;
3)从我从事的几个项目经历看,程序员是否有架构的思想对后续项目的公共化构建也有很大的影响,我很喜欢观察表设计模式,尤其是观察那些做事轻松又能保质完成任务的项目经理设计的表,通过我的观察我发现他们数据库设计的时候是一定会做业务上的拆分的,最基本拆分成权限业务、基础业务、日志业务,通过对架构的思考我发现他这样做的设计权限后台代码实际上是可以直接复用的,而且当请求增多的时候,这种分库的模式相对于数据库一体的方式可以缓解数据库的瓶颈问题。我也查看过一本项目管理的书,书上也是说如果不知道架构怎么设计,那么请首先确保对数据进行业务拆分。
4)还需要考虑的是代码模块的拆分,为的是实现代码的复用,maven项目管理是一个很好的工具,可以对代码进行分模块构建,我在某一家公司上班的时候,我就发现他们一个项目模块划分的很细,commom、model、mapper、service、controller直接分成了5个模块,我就去问其他同事为什么要划分这么细?他说他也不知道。当我到下一个公司入职的时候,公司在创建项目初期没有去考虑module拆分,后续当项目需要进行复用的时候又去做一次模块的拆分,还要测试对原来项目是否有影响,这些都属于额外的工作,但是module拆分的太细也会有问题,maven打包的时候每一次都需要确保调用的模块有install过,所以我的建议是commom、model、mapper进行拆分,service和controller不做拆分放在一起,如果有哪位朋友有不同意见欢迎留言。
-
相关阅读:
用Redis实现延迟队列,我研究了两种方案,发现并不简单
[附源码]计算机毕业设计JAVAjsp心理测评系统
普冉PY32系列(十四) 从XL2400迁移到XL2400P
WCH USB转多串口芯片相关型号
B-Spline for SLAM
JavaWeb中篇Filter-Transaction-Listener笔记
C++ 顺序表和单链表的二路归并思想(详解+示例代码)
程序员转行做运营,曾被逼得每天想离职,最后...
C语言中的位域
Elasticsearch集群部署及Head插件安装
- 原文地址:https://blog.csdn.net/Q54665642ljf/article/details/126081736