-
数据结构顺序表之单链表
之前我们已经认识了顺序表,今天我们来实现一下链表,这里我将主要代码和思想分享出来,没有进行写一个菜单这样的收尾工作!
前言
我们明明已经有了顺序表了,为什么还要有链表呢?
大家或许已经有了答案,没错,顺序表有缺陷,为了尽量弥补缺陷就有了链表;而既然有链表还有顺序表也就是说顺序表有些地方的优势是链表没有的我们今天只讲一种最简单的链表,
单链表
一、顺序表的缺点
- 中间/头部的插入删除,时间复杂度为O(N)
中间数据的插入删除操作,要将数据整体左移或者右移,这个时间复杂度是O(N)
- 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
realloc分原地扩容和异地扩容,异地扩容风险较大
- 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
在特殊情况下还是会产生大量浪费
由此就需要链表来解决上述问题
二、链表
1、概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
什么意思呢?
就是说:链表每个节点的位置是不连续的,在很多书或者人的脑海中靠箭头连接,这个箭头是凭空想象的,是不存在的,实际在内存中是没有的。
比如说火车:
火车就像一个单链表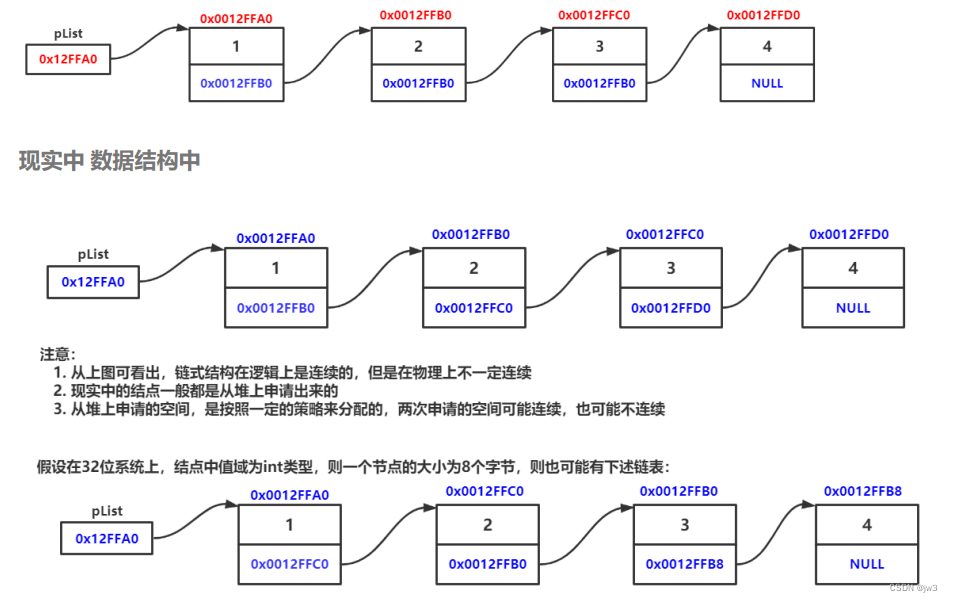
上面的箭头只是为了帮助大家理解链表,小编下面也都是采用逻辑思维的方法画图来解决问题的2、链表的分类
链表一共有多种方式来搭配的:
带头、不带头
单向、双向
循环、不循环我们只讲两种链表:
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
看也猜得出来1是最简单的,2是最难的。但是2包含内容多,实现起来简单很多。今天我们主要讲1,单链表
三、单链表的实现
与顺序表一样,需要3个文件,一个SList.h头文件、一个SList.c源文件、一个test.c源文件
1、SList.h头文件
单链表是不需要初始化函数的,因为单链表开始就是一个结构体指针指向NULL的
#pragma once #include#include #include typedef int SLDataType; typedef struct SListNode { SLDataType* data; struct SListNode* next; }SLT; void SLTPrint(SLT* phead);//打印 void SLTdelete(SLT** pphead);//销毁释放 void SLTpushfront(SLT** pphead, SLDataType x);//头插 void SLTpushback(SLT** pphead, SLDataType x);//尾插 void SLTpopfront(SLT** pphead);//头删 void SLTpopback(SLT** pphead);//尾删 //接下来我们通过查找接口讲后面的接口联系起来 SLT* SLTFind(SLT* pphead, SLDataType x);//查找 void SLTInsert(SLT** pphead, SLT* pos, SLDataType x);//在pos之前面插入 void SLTInsertAfter(SLT** pphead, SLT* pos, SLDataType x);//在pos之后面插入 void SLTErase(SLT** pphead, SLT* pos);//删除pos位置数据 void SLTEraseAfter(SLT** pphead, SLT* pos);//删除pos位置之后的数据 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
上面就是头文件所有的函数声明
这里小编用的是vs2022,可能是编译器刚出没多久,有许多问题,比如这次链表中重命名int之后不能直接进行*10的操作,要强制转换,
其实有点检查过度了。2、test.c源文件
这次小编没有写菜单,只有4个测试函数,大家能够明白原理即可,所以就把测试文件放在函数定义文件前面给大家了
#define _CRT_SECURE_NO_WARNINGS #include"keli.h" void Test1()//测试1 { SLT* plist = NULL; SLTpushfront(&plist, 10);//头插 SLTpushfront(&plist, 20); SLTpushfront(&plist, 30); SLTpushfront(&plist, 40); SLTpushfront(&plist, 50); SLTPrint(plist);//打印 SLTpushback(&plist, 1);//尾插 SLTpushback(&plist, 2); SLTpushback(&plist, 3); SLTpushback(&plist, 4); SLTpushback(&plist, 5); SLTPrint(plist); SLTdelete(&plist); } void Test2()//测试2 { SLT* plist = NULL; SLTpushfront(&plist, 10);//头插 SLTpushfront(&plist, 20); SLTpushfront(&plist, 30); SLTpushfront(&plist, 40); SLTpushfront(&plist, 50); SLTPrint(plist);//打印 SLTpopfront(&plist);//头删 SLTpopfront(&plist); SLTPrint(plist); SLTpopback(&plist);//尾删 SLTpopback(&plist); SLTpopback(&plist); SLTPrint(plist);//打印 SLTdelete(&plist); } void Test3()//测试3 { SLT* plist = NULL; SLTpushfront(&plist, 1);//头插 SLTpushfront(&plist, 2); SLTpushfront(&plist, 3); SLTpushfront(&plist, 4); SLTpushfront(&plist, 5); SLTPrint(plist);//打印 int x = 2; SLT* pos = SLTFind(plist, x); if (pos) { (int)(pos->data) *= 10;//对查找到的值进行修改 } else { printf("找不到\n"); } x = 3; pos = SLTFind(plist, x); if (pos) { SLTInsert(&plist, pos, 100);//在查找值之前插入 SLTInsertAfter(&plist, pos, 200);//在查找值之后插入 } else { printf("找不到\n"); } SLTPrint(plist);//打印 SLTdelete(&plist); } void Test4()//测试4 { SLT* plist = NULL; SLTpushfront(&plist, 1);//头插 SLTpushfront(&plist, 2); SLTpushfront(&plist, 3); SLTpushfront(&plist, 4); SLTpushfront(&plist, 5); SLTPrint(plist);//打印 int x = 3; SLT* pos = SLTFind(plist, x); if (pos) { SLTErase(&plist, pos); } x = 2; pos = SLTFind(plist, 2); if (pos) { SLTEraseAfter(&plist, pos); } SLTPrint(plist);//打印 } int main() { //Test1(); //Test2(); //Test3(); Test4(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
接下来我们重点看看每一个接口任何实现的
3、SList.c
再提一遍,单链表可以不用写初始化函数的,只需要定义出结构体指针初始化为NULL即可
SLT* plist = NULL;
这一段代码就有初始化的作用
1、打印数据
void SLTPrint(SLT* phead)//打印 {//打印的时候不能断言,因为的确存在没有节点的情况 SLT* cur = phead; while (cur) { printf("%d->", cur->data); cur = cur->next;//把下一个节点的位置赋给cur } printf("NULL\n"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这一段代码和之前的顺序表打印函数没什么大的差别,很好理解。主要就是把下一个节点的位置赋给cur,形成循环
2、释放销毁数据
void SLTdelete(SLT** pphead)//销毁释放 { assert(pphead); SLT* cur = *pphead; while (cur) { SLT* next = cur->next;//将下一个节点地址保留 free(cur);//释放该节点空间 cur = next;//将下一个节点地址赋给cur } *pphead = NULL;//释放完所有空间之后让*pphead也就是plist指向NULL }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3、扩容
每次插入数据要进行判断空间够不够,需不需要扩容(单链表扩容可以一次性扩一个结构体指针)
SLT* SLTCheck(SLDataType x)//扩容 { SLT* newnode = (SLT*)malloc(sizeof(SLT));//一次扩容一个结构体大小,包括数据和结构体指针 if (newnode == NULL) { perror("malloc fail"); exit(-1); } else { newnode->data = x;//将扩容结构体的data赋值为x,也就是我们插入的数据 newnode->next = NULL;//将结构体指针置空 } return newnode;//返回扩容结构体的地址 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4、头插数据
void SLTpushfront(SLT** pphead, SLDataType x)//头插 { assert(pphead); SLT* newnode = SLTCheck(x);//判断需不需要扩容,只有插入时才会出现空间不够 newnode->next = *pphead;//这里本来*pphead也就是最开始指向第一个数据的指针,由扩容的结构体指针维护 //也就是让扩容指针指向原来第一个节点(现在的第二个节点) *pphead = newnode;//让最开始的指针指向扩容节点,这样扩容节点就是第一个数据了 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5、尾插数据
尾插数据存在原来没有一个数据的情况,这种情况相当于头插数据,但是请不要使用头插数据,这样会变得麻烦
void SLTpushback(SLT** pphead, SLDataType x)//尾插 { assert(pphead); SLT* newnode = SLTCheck(x);//判断需不需要扩容 if (*pphead == NULL)//如果一个数据都没有 { *pphead = newnode;//直接把扩容地址赋给最开始的指针维护 } else { SLT* cur = *pphead; while (cur->next != NULL)//这里特别注意,我们如果是判断cur不等于NULL的话现在的末尾数据会和尾插数据断开 //也就是链表断开了,没有连续起来 { cur = cur->next;//将下一个节点的地址赋给cur,形成循环,直到cur->next也就是cur的下一个节点是NULL截止 } cur->next = newnode;//将扩容节点插入到NULL处,这里大家不用担心newnode最后没有指向NULL,我们上面扩容已经处理了 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6、头删数据
void SLTpopfront(SLT** pphead)//头删 { assert(pphead); SLT* cur = *pphead; *pphead = cur->next;//直接让最开始的指针指向第二个节点 free(cur);//释放第一个节点(因为我们是一个节点一个节点开辟的,使用可以一个节点一个节点的释放) cur = NULL;//置空或者不置空都可以,最好养成习惯 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7、尾删数据
尾删数据的时候要注意原来数据没有或者只有一个数据的情况
void SLTpopback(SLT** pphead)//尾删 { assert(pphead); assert(*pphead);//如果原来没有数据,直接暴力断言 if ((*pphead)->next == NULL)//如果只有一个数据,因为一个数据的next就是NULL { free(*pphead);//直接释放掉该指针 *pphead = NULL; } else//如果有多个数据也就是多个节点 { SLT* cur = *pphead; SLT* prev = NULL; while (cur->next != NULL)//还是next不等于NULL,不然容易断开链表 { prev = cur;//如果cur下一个节点不是NULL就赋给prev,然后cur移动到下一个节点位置,进行循环 cur = cur->next; } prev->next = NULL;//出循环就表示cur->next是NULL了,将prev->next也就是现在的cur赋值为NULL //也就是让倒数第二个结构体指针指向NULL free(cur);//释放最后一个节点 cur = NULL; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
8、查找与相关操作
因为查找数据是可以和剩下接口一起使用的,所以写在一起
SLT* SLTFind(SLT* pphead, SLDataType x)//查找 {//找到该节点就返回节点地址 assert(pphead); SLT* cur = pphead; while (cur) { if (cur->data == x) { return cur; } cur = cur->next; } return NULL;//找不到返回空 } void SLTInsert(SLT** pphead, SLT* pos, SLDataType x)//在pos之前面插入 {//pos就是查找到数据的地址 assert(pphead && pos); if ((*pphead)->next == NULL)//如果只有一个节点 { SLTpushfront(pphead, x);//那么pos之前插入就是头插 } else { SLT* newnode = SLTCheck(x); SLT* cur = *pphead; while (cur->next != pos)//同上一样,防止链表中间断开 { cur = cur->next; assert(cur);//断言一下,防止找不到传过来的节点 } cur->next = newnode;//插入与上同理 newnode->next = pos; } } void SLTInsertAfter(SLT** pphead, SLT* pos, SLDataType x)//在pos之后面插入 { assert(pphead && pos); if ((*pphead)->next == NULL) { SLTpushfront(pphead, x); } SLT* newnode = SLTCheck(x); SLT* cur = *pphead; while (cur != pos) { cur = cur->next; assert(cur); } newnode->next = pos->next; pos->next = newnode; } void SLTErase(SLT** pphead, SLT* pos)//删除pos位置数据 { assert(pphead && pos); if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } SLT* cur = *pphead; SLT* prev = NULL; while (cur != pos) { prev = cur; cur = cur->next; } prev->next = cur->next; free(cur); cur = NULL; } void SLTEraseAfter(SLT** pphead, SLT* pos)//删除pos位置之后的数据 { assert(pphead && pos); SLT* cur = *pphead; SLT* prev = NULL; while (prev!=pos) { prev = cur; cur = cur->next; } prev->next = cur->next; free(cur); cur = NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
总结
因为单链表理解了的话写起来还是比较简单的,如果大家认为听起来有点吃力就把c语言结构体、指针、动态内存多看几遍就会了。下一期我们就直接学习最难的链表结构了,希望各位读者有所准备哦,我们下期见!
-
相关阅读:
java线索二叉树(含线索二叉树代码展示)
css的继承性
半个月时间把MySQL重新巩固了一遍,梳理了一篇几万字 “超硬核” 文章!
【Unity】3D贪吃蛇游戏制作/WebGL本地测试及项目部署
华为云云耀云服务器L实例评测 |云服务器性能评测
微信小程序分包和预加载分包
使用HbuilderX运行uniapp中小程序项目
投资失败+转岗降薪,2年逆袭月薪30K,我的船终于靠了岸
Vue双向绑定的原理
力扣题解22-25
- 原文地址:https://blog.csdn.net/kdjjdjdjjejje128/article/details/126053889
