-
mysql之的执行计划
一、什么是执行计划?
使用 EXPLAIN 关键字可以模拟优化器执行SQL查询语句,从而知道MYSQL是如何处理你的sql语句的。
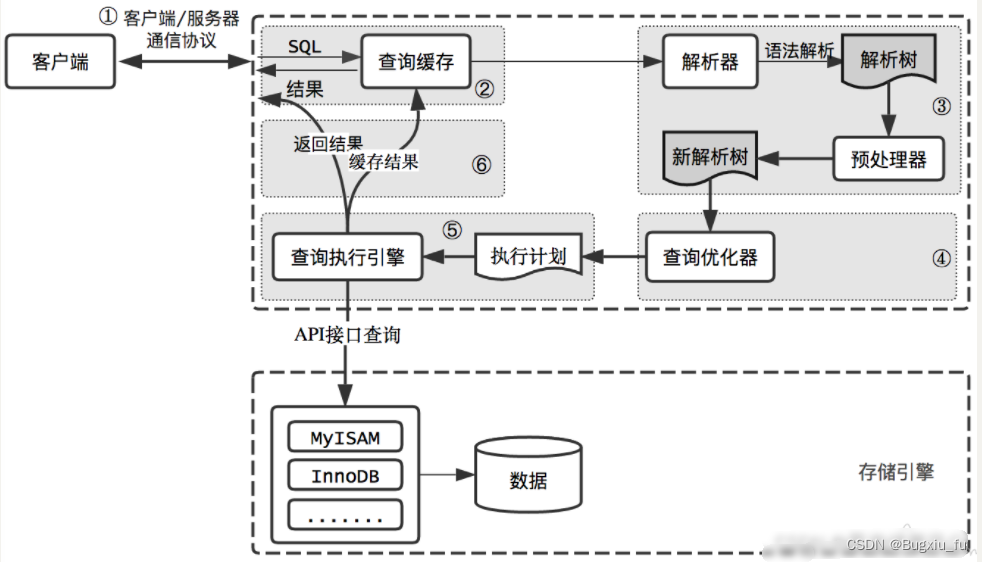
执行计划流程(最好配合图理解)
浏览器(客户端)发送一个请求,执行数据库查询之前,找到连接池(循环使用),跟数据库驱动进行连接,获取连接之后找到mysql服务的,然后连接池找到查询缓存,然后进行解析,找到解析树解析,预处理完了之后生成新的解析树,新解析树后查询优化器,执行sql之后,通过引擎找到数据文件读取数据返回给缓存,最后才返回给用户。
一些优化器:(了解)
CBO:基于成本的优化器,看走那一个索引,根据成本值统计索引。
RBO: 基于规则的优化器,有索引使用索引。那么所有带有索引的表在任何情况下都会走索引
二、执行计划的值与参数
代码
- explain
- (select * from t_users id=1
- union
- select * from t_users id=2);
运行结果

- select_type:类别,主要用于区别普通查询,联合查询,子查询等的复杂查询(union)
-
simple:简单的select查询,不包含子查询或者union
-
primary:查询中包含任何复杂的子部分,最外层查询则被标记
-
derived:from列表中用到子查询,将表中当成查询的条件,也计算子查询
-
union:包含在 from 子句的子查询中,出现子查询时,会生成临时表
- paritiions:如果表数据量大的话,设置分区条件。
- possible_keys:可能使用的key(索引)
- key:实际上使用的索引
- key_len:使用的键长度(字节数)
- ref:显示哪个字段或常数与key一起被使用
- rows:遍历多少数据才能找到
- type:是较为重要的一个指标,结果值从最好到最坏依次是(性能)
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > index_subquery > range > index > all注:(红色标注的表示系统走了索引)
-
system: 表中只有一行记录(等于系统表);
-
const表示通过索引一次就找到了;
-
eq_ref: 维一记录;
-
ref: 非唯一索引扫描;
-
range: 只检索给定范围的行
-
all:全表扫描
-
index:索引覆盖(扫描全部)
-
null:执行时甚至不用访问表或索引;
- Extra:表示不合适在其他列中显示但十分重要的额外信息
-
Using index:覆盖索引以避免访问表。
-
Using temporary:排序临时表
-
Using where:检索后过滤
怎么对myql进行性能优化?
服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
如果一列进行索引的时候,尽量避免使用null值,因为它的值比较复杂,不容易创建索引。
-
相关阅读:
接口日志,统一记录(AOP+自定义注解)
基于springboot外委员工后台管理系统毕业设计源码101157
IO 原理
ELK配置记录
【mq】从零开始实现 mq-07-负载均衡 load balance
NSSCTF第12页(1)
静态代理和动态代理
算法 杨辉三角求解 java打印杨辉三角 多路递归打印杨辉三角 递归优化杨辉三角 记忆法优化递归 帕斯卡三角形 算法(十二)
SpringBoot整合dubbo(二)
网络安全-对称加密和非对称加密基础
- 原文地址:https://blog.csdn.net/Bugxiu_fu/article/details/126071160