-
【夯实算法基础】最近公共祖先
算法
向上标记法
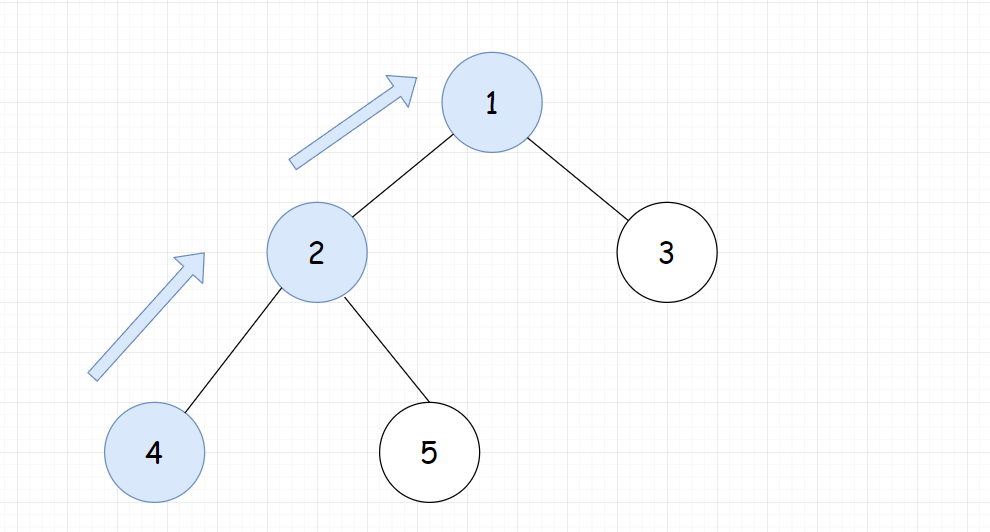
- 从
x向上走到根节点,并标记所有经过的节点 - 从
y向上走到根节点,当第一次遇到已标记节点时,就找到了最近公共祖先
单次查询的复杂度
O(n)图解
树上倍增法
我们每次都是要找两个点的所有的父亲,并且找到两个点最近的父节点,那么可不可以不一个一个寻找,有没有更高效的算法呢,其实就是倍增。
有关倍增可以看我的这篇博客:RMQ 算法(图示)
状态表示:
f[x][k]表示x的2^k辈祖先是谁,即从x向根节点走2^k步到达的节点。特别的,如果该节点不存在,则令f[x][k] = 0。状态计算:
f[x][0]就表示x的父节点f[x][k] = f[f[x][k - 1]][k-1]:表示x的2^(k-1)辈祖先的2^(k-1)辈祖先
这类似于一个动态规划的过程,每一个阶段就是节点的深度。我们可以进行
bfs或dfs求f数组,并且记录每个节点的深度(我们后续求lca需要用到)。以上预处理的复杂度为O(nlogn),每个点都要求一遍f。如何求LCA
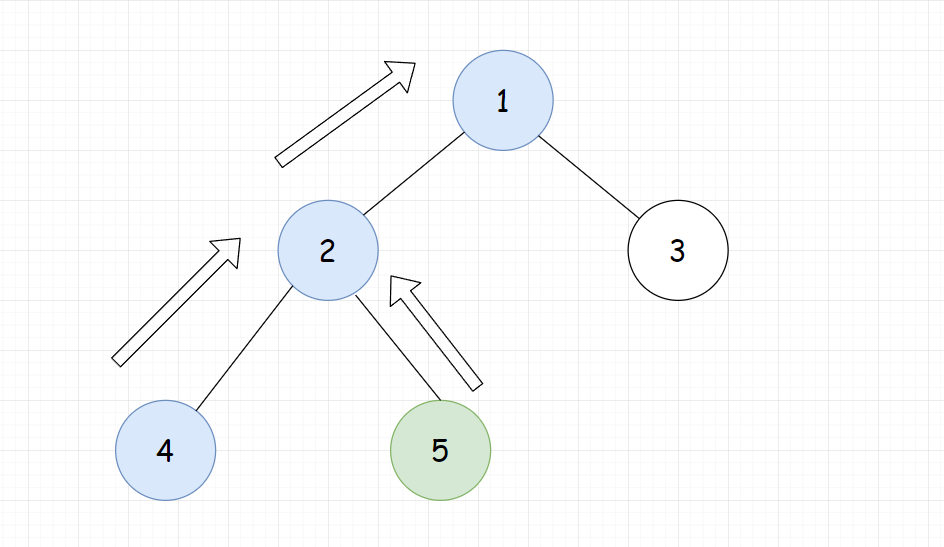
- 设
d[x]表示x的深度,不妨设d[x]>=d[y](否则就交换,计算结果是一样的) - 把两个点调整到同一高度,怎么调整呢,假设x与y之间高度差为
len,可以利用二进制拆分的思想,把len可以转化成一个二进制数,依次尝试让x向上走2^log(n),...,2^1,2^0步,但是我们不需要计算len的二进制数,我们可以从大到小枚举所有的二进制为,只要x的深度比y深,就继续向上走,这样就一定可以到达与y同深度。 - 如果此时x和y相等,就已经找到了
lca

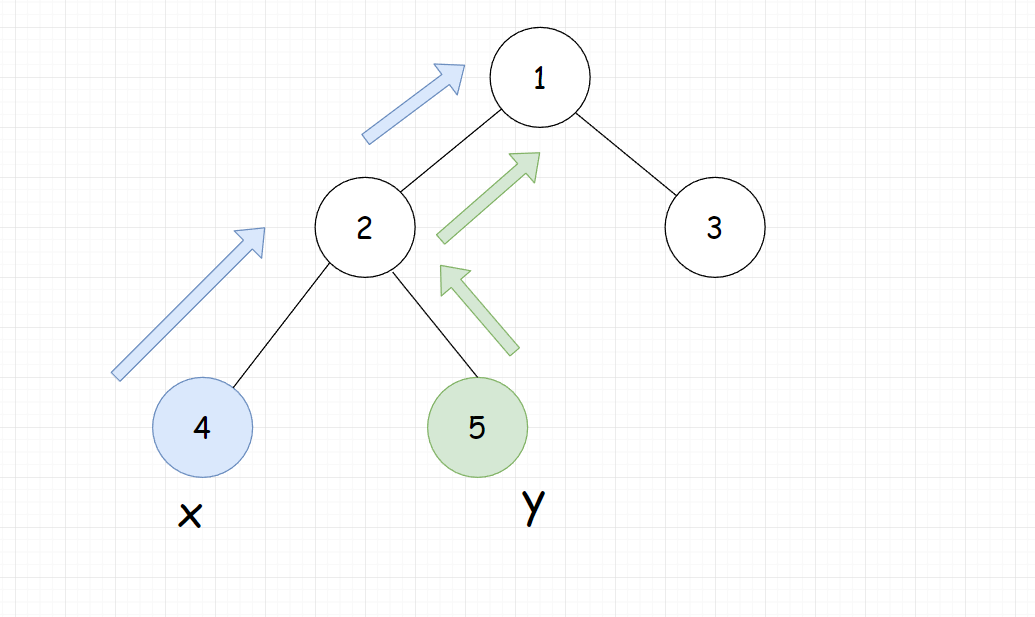
-
如果不是lca,那么说明还需要向上走,这时就是两个点都同时向上依次走
2^log(n),...,2^1,2^0步 ,并且保持深度一致但两个不相会。最后得到的一定最近公共祖先的下一层,那么f[x][0]就是他们的lca了。为啥这里要保证不相会?我们是从大到小来枚举的跳
2^k步,那么第一步就有可能跳到祖先的祖先了,但不是最近公共祖先。比如这里我们同时跳2步,那么就到了1号点,而不是lca(2号点),所以只要
f[x][k]!=f[y][k],说明就还没有跳到最近公共祖先,那么就可以继续往上跳,知道k枚举完为止,那么最后一定到了lca的下一层。其实这里跳了len - 1步,但我们并不知道len是多少,所以还是利用二进制的思想,能向上走就向上走。
🍂 代码
#includeusing namespace std; const int N = 4e4 + 10, M = N * 2; int n; int k; //树的最大深度 int root; int depth[N]; int f[N][20]; int h[N], e[M], ne[M], idx; void add(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx++; } void bfs() { memset(depth, 0x3f, sizeof depth); depth[0] = 0; depth[root] = 1; queue<int> q; q.push(root); while (q.size()) { int u = q.front(); q.pop(); for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (depth[j] > depth[u] + 1) //没有被搜索过 { depth[j] = depth[u] + 1; //深度加1 f[j][0] = u; q.push(j); for (int t = 1; t <= k; t++) //跳 f[j][t] = f[f[j][t - 1]][t - 1]; } } } } int lca(int a, int b) { if (depth[a] < depth[b]) swap(a, b); for (int i = k; i >= 0; i--) //先都跳到同一层 { if (depth[f[a][i]] >= depth[b]) a = f[a][i]; } if (a == b) return a; for (int i = k; i >= 0; i--) { if (f[a][i] != f[b][i]) //还没有跳到公共祖先 { a = f[a][i]; b = f[b][i]; } } return f[a][0]; } int main() { memset(h, -1, sizeof h); cin >> n; k = (int)(log(n) / log(2)) + 1; for (int i = 1; i <= n; i++) { int a, b; cin >> a >> b; if (b == -1) root = a; else { add(a, b); add(b, a); } } bfs(); int q; cin >> q; while (q--) { int a, b; cin >> a >> b; int p = lca(a, b); if (p == a) puts("1"); else if (p == b) puts("2"); else puts("0"); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
LCA的Tarjan 算法
- 在线做法:读一个询问,处理一个,输出一个
- 离线做法:读完全部询问,再全部处理完,再全部输出
Tarjan是一种离线算法,是对向上标记法的一种优化,我们向上标记的时候是一个一个向上走的,效率低,而tarjian可以优化到O(1)的复杂度。
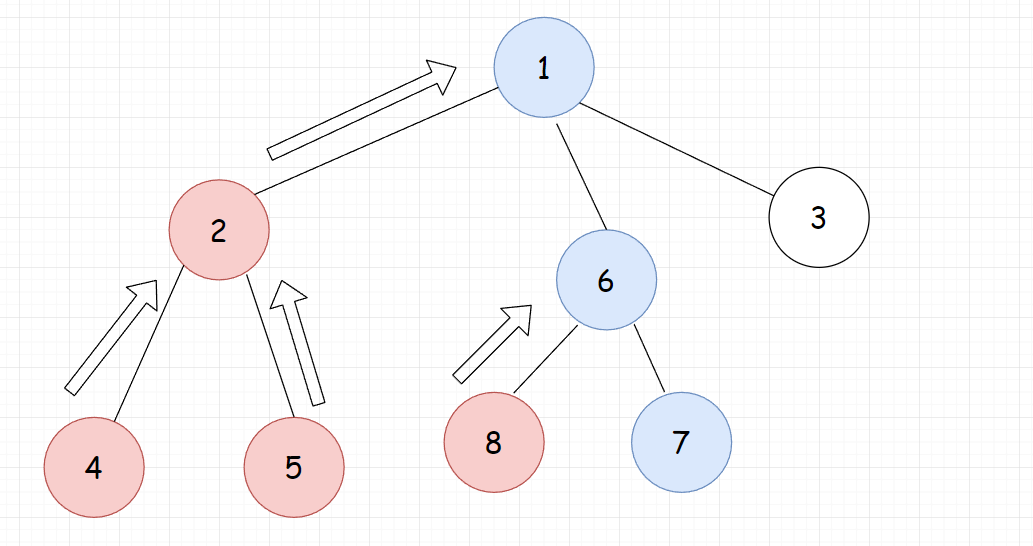
在深度优先遍历时,数种的节点分为三类:
- 2号点: 已经访问完毕并且回溯过的点。
- 1号点:已经开始递归,但还没有回溯的点。也就是正在访问的节点以及他的所有祖先。
- 0号点:尚未访问的点
为什么要这样做呢?我们可以发现,对于1号点而言,所有的二号点的祖先都是1号点,也就是他们的
lca,这也就是树上标记法中一个点向上走遇到的第一个标记的节点。那么怎么快速找到2号点祖先对对应的1号点呢?这里可以云并查集进行优化,1号点的分支中所有的2号点都是以1号点为祖先。当一个节点是2号点后,把它所在的集合合并到它的父节点所在的集合中(此时父节点一定是1号点)这样每个完成回溯的点都有一个指针指向了它的父节点,只需查询y所在集合的代表元素,就等价于从y向上走一直走到一个开始递归但尚未回溯的点,即
lca(x,y)如下图:红色点表示2号点,蓝色点表示1号点,白色点表示0号点
🐴 代码
#includeusing namespace std; #define x first #define y second const int N = 2e4 + 10, M = N * 2; typedef pair<int, int> PII; int n, m; int p[N]; //并查集 int dist[N]; //存每个点到根节点的距离 int s[N]; //存每个点的状态 int st[N]; // 每个点的状态 int ans[N]; //存每一个询问的答案 vector<PII> query[N]; //存询问的每个点的另一个点以及询问编号,first是另一个点,second是查询编号 int h[N], ne[M], w[M], e[M], idx; void add(int a, int b, int c) { e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++; } int find(int x) { if (p[x] != x) p[x] = find(p[x]); return p[x]; } void dfs(int u, int fa) { for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (j == fa) continue; dist[j] = dist[u] + w[i]; dfs(j, u); } } void tarjan(int u) { st[u] = 1; //正在搜索的分支 for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (st[j]) continue; tarjan(j); p[j] = u; // 所有已经是2号点的祖先都是u } for (int i = 0; i < query[u].size(); i++) { int v = query[u][i].x; int id = query[u][i].y; int anc = find(v); // lca if (st[v] == 2) { ans[id] = dist[u] + dist[v] - dist[anc] * 2; } } st[u] = 2; } int main() { memset(h, -1, sizeof h); cin >> n >> m; for (int i = 1; i <= n; i++) //初始化并查集 p[i] = i; for (int i = 0; i < n - 1; i++) { int a, b, c; cin >> a >> b >> c; add(a, b, c); add(b, a, c); } for (int i = 1; i <= m; i++) { int a, b; cin >> a >> b; if (a == b) continue; query[a].push_back({b, i}); query[b].push_back({a, i}); } dfs(1, -1); //求距离 tarjan(1); //随便选一个点作为根节点 for (int i = 1; i <= m; i++) cout << ans[i] << "\n"; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
树上差分
在前缀和与差分中,我们定义了一个序列的前缀和与差分序列,并通过差分技巧,把“区间”的增减转化为“左端点加1,右端点减一”。根据“差分序列的前缀和是原序列”这一与哪里,在树上可以进行类似的简化,其中“区间操作”对应为”路径操作“,”前缀和“队友为”子树和“。
😮 题目 :352. 闇の連鎖

🤗 思路
根据题意,主要边构成了一颗树,附加边则是非树边。把一条附加边(x,y)添加到主要边构成的树中,会与树上x,y之间的路径一起形成一个环。如果第一步选择切断x,y之间路径的某条边,那么第二步就必须切断附加边(x,y),才能令Dark被斩为不连通的两部分。所以每条附加边(x,y)都把x,y之间的路径上的每条边覆盖了一次。我们只需要统计出每条边被覆盖了多少次。这里有三种可能:
- 覆盖0次,那么切断这条边就已经不连通了,所以可以选择附加边的任何一条边
- 覆盖1次,那么切断这条边后切断附加边的方案就唯一了
- 覆盖2次及以上,那么切断这条边后,无论且哪条附加边都不法实现不连通。
现在我们需要解决的问题为:给定一张无向图和一颗生成树,求每条树边被非树边覆盖了多少次。
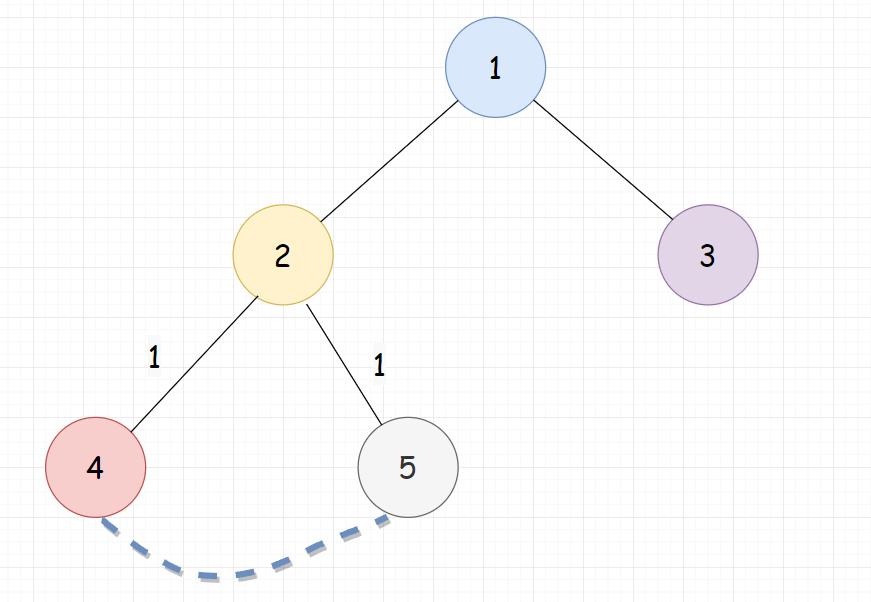
如下图所示,加了(4,5)这条边后,(2,4)和(2,5)这两条边都被覆盖了一次
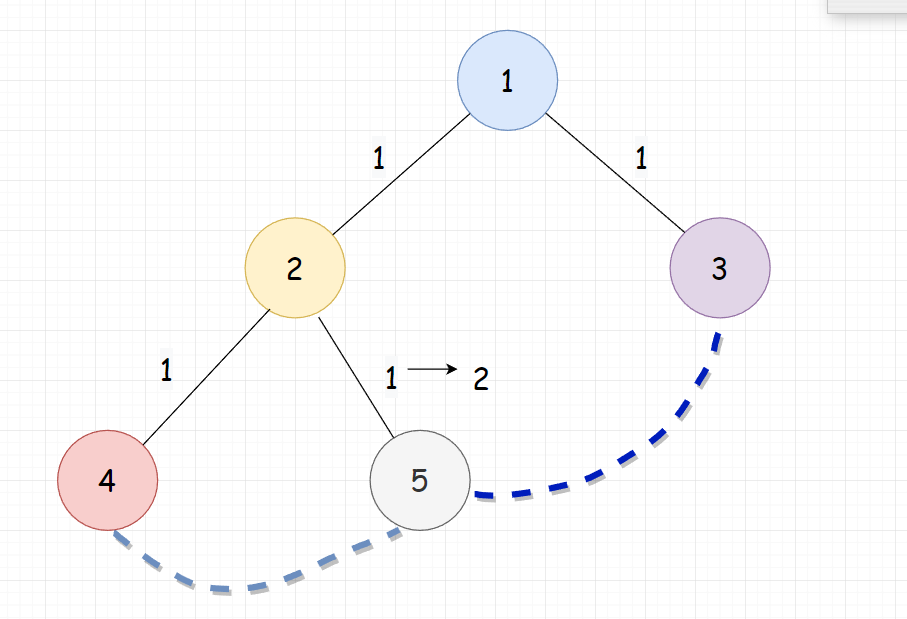
加了(3,5)这条边后,(2,5)被覆盖了两次,(1,2),(1,3)被覆盖了一次
我们现在要做的就是如何解决记录覆盖的问题,这里我们就可以用到树上差分,我们给树上每个点一个初始为0的权值,然后对每条非树边(x,y),令节点x的权值加1,节点y的权值加1,节点
lca(x,y)的权值减2。最后我们对这个图进行dfs。求出以每个点为根的子树中各节点的权值之和。时间复杂度O(n+m)代码
#includeusing namespace std; typedef long long ll; const int N = 1e5 + 10, M = 4e5 + 10, INF = 0x3f3f3f3f; int n, m; int ans; int t; //树的最大深度 int h[N], e[M], ne[M], w[M], idx; int d[N]; int p[N]; //并查集数组 int depth[N]; //深度 int fa[N][20]; // i的2^j的祖先是谁 void add(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx++; } void bfs() { memset(depth, 0x3f, sizeof depth); depth[0] = 0; depth[1] = 1; queue<int> q; q.push(1); while (q.size()) { int u = q.front(); q.pop(); for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (depth[j] > depth[u] + 1) { depth[j] = depth[u] + 1; q.push(j); fa[j][0] = u; for (int k = 1; k <= t; k++) fa[j][k] = fa[fa[j][k - 1]][k - 1]; } } } } int lca(int a, int b) { if (depth[a] < depth[b]) swap(a, b); for (int i = t; i >= 0; i--) { if (depth[fa[a][i]] >= depth[b]) a = fa[a][i]; } if (a == b) return a; for (int i = t; i >= 0; i--) { if (fa[a][i] != fa[b][i]) { a = fa[a][i]; b = fa[b][i]; } } return fa[a][0]; } int dfs(int u, int fa) { int sum = d[u]; for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (j == fa) continue; int c = dfs(j, u); sum += c; if (c == 0) ans += m; else if (c == 1) ans++; } return sum; } int main() { cin >> n >> m; memset(h, -1, sizeof h); t = (int)(log(n) / log(2)) + 1; for (int i = 0; i < n - 1; i++) { int a, b; cin >> a >> b; add(a, b); add(b, a); } bfs(); for (int i = 0; i < m; i++) { int a, b; cin >> a >> b; int p = lca(a, b); d[a]++, d[b]++, d[p] -= 2; } dfs(1, -1); cout << ans; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
⭐️ 有疑问欢迎评论区留言哦
🍭 帮到您的话欢迎点个赞再走啊

- 从
-
相关阅读:
超详细!新手必看!STM32-通用定时器简介与知识点概括
gitlab+docker+harbor+k8s+jenkins部署简单应用
RT-Thread 项目工程搭建和配置--(Env Kconfig)
Java_IO流03:处理流之一:缓冲流
Java 实例-如何编译 Java 文件
处理器管理
Python学习笔记(21)-Python框架21-PyQt框架使用(简介+配置+主窗体创建)
随机森林----评论情感分析系统
AndroidStudio打包报错记录(commons-logging,keystore password was incorrect)
基于springboot框架的快递代取跑腿服务系统
- 原文地址:https://blog.csdn.net/weixin_53029342/article/details/126068524

