-
【RocketMQ】消息的高可用与负载均衡
消息生产的高可用机制
在创建Topic的时候,把Topic的多个Message Queue创建在多个Broker组上(相同Broker名称,不同brokerId的机器组成一个Broker组),这样当一个Broker组的Master不可用后,其他组的Master仍然可用,Producer仍然可以发送消息。
RocketMQ目前不支持把Slave自动转成Master,如果机器资源不足,需要把Slave转成Master,则要手动停止Slave角色的Broker,更改配置文件,将brokerId设置为0,用新的配置文件启动Broker。
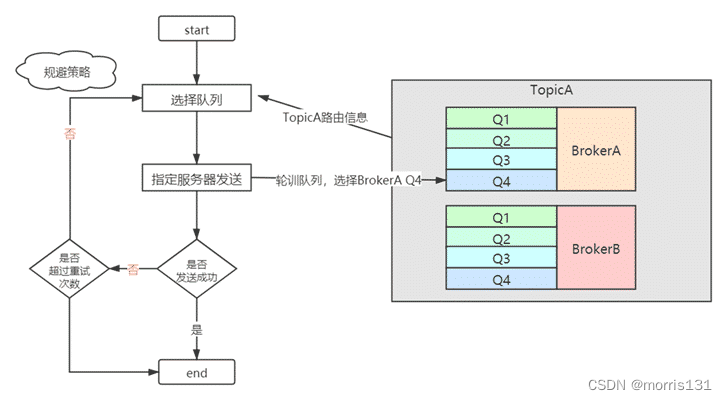
发送消息时选择队列的过程如下:
- TopicA创建在双主中,BrokerA和BrokerB中,每一个Broker中有4个队列
- 选择队列时,默认是使用轮询的方式,比如发送一条消息A时,选择BrokerA中的Q4
- 如果发送成功,消息A发结束。
- 如果消息发送失败,默认会采用重试机制
- retryTimesWhenSendFailed:同步发送模式下内部尝试发送消息的最大次数,默认值是2,总共发送3次
- retryTimesWhenSendAsyncFailed:异步发送模式下内部尝试发送消息的最大次数,默认值是2,总共发送3次
- 如果发生了消息发送失败,这里有一个规避策略:
- 默认不启用Broker故障延迟机制(规避策略):如果是BrokerA宕机,上一次路由选择的是BrokerA中的Q4,那么再次重发的队列选择是BrokerA中的Q1。但是这里的问题就是消息发送很大可能再次失败,引发再次重复失败,带来不必要的性能损耗。
注意,这里的规避仅仅只针对消息重试,例如在一次消息发送过程中如果遇到消息发送失败,规避broekr-a,但是在下一次消息发送时,即再次调用 DefaultMQProducer的send方法发送消息时,还是会选择broker-a的队列进行发送,只有继续发送失败后,重试时再次规避broker-a。
为什么会默认这么设计?
- 某一时间段,从NameServer中读到的路由中包含了不可用的主机
- 不正常的路由信息也是只是一个短暂的时间而已。
生产者每隔30s更新一次路由信息,而NameServer认为broker不可用需要经过120s。
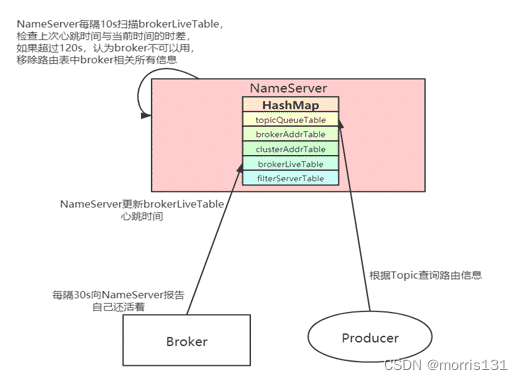
所以生产者要发送时认为broker不正常(从NameServer拿到)和实际Broker不正常有延迟。
- 启用Broker故障延迟机制:代码如下
producer.setSendLatencyFaultEnable(true);- 1
开启延迟规避机制,一旦消息发送失败(不是重试的)会将broker-a“悲观”地认为在接下来的一段时间内该Broker不可用,在为未来某一段时间内所有的客户端不会向该Broker发送消息。这个延迟时间就是通过notAvailableDuration、latencyMax共同计算的,就首先先计算本次消息发送失败所耗的时延,然后对应latencyMax中哪个区间,即计算在latencyMax的下标,然后返回notAvailableDuration同一个下标对应的延迟值。
比如:在发送失败后,在接下来的固定时间(比如5分钟)内,发生错误的BrokeA中的队列将不再参加队列负载,发送时只选择BrokerB服务器上的队列。
如果所有的Broker都触发了故障规避,并且Broker只是那一瞬间压力大,那岂不是明明存在可用的Broker,但经过你这样规避,反倒是没有Broker可用了,那岂不是更糟糕了。所以RocketMQ默认不启用Broker故障延迟机制。消息消费的高可用机制
主从的高可用原理
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave读,当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave读。有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序。这就达到了消费端的高可用性。
Master不可用这个很容易理解,那什么是Master繁忙呢?这个繁忙其实是RocketMQ服务器的内存不够导致的。
源码分析:org.apache.rocketmq.store.DefaultMessageStore#getMessage方法
... ... // 未读消息的大小 long diff = maxOffsetPy - maxPhyOffsetPulling; // 长驻内存的大小 long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE * (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0)); // 设置从slave拉取 getResult.setSuggestPullingFromSlave(diff > memory); ... ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当前需要拉取的消息已经超过常驻内存的大小,表示主服务器繁忙,此时才建议从从服务器拉取。
消息消费的重试
消费端如果发生消息失败,没有提交成功,消息默认情况下会进入重试队列中。
注意重试队列的名字其实是跟消费群组有关,不是主题,因为一个主题可以有多个群组消费,所以要注意。

顺序消息的重试
对于顺序消息,当消费者消费消息失败后,RocketMQ会自动不断进行消息重试(每次间隔时间为1秒),这时,应用会出现消息消费被阻塞的情况。因此,在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生。
所以玩顺序消息时。consume消费消息失败时,不能返回RECONSUME_LATER,这样会导致乱序,应该返回SUSPEND_CURRENT_QUEUE_A_MOMENT,意思是先等一会,一会儿再处理这批消息,而不是放到重试队列里。
无序消息的重试
对于无序消息(普通、定时、延时、事务消息),当消费者消费消息失败时,您可以通过设置返回状态达到消息重试的结果。无序消息的重试只针对集群消费方式生效;广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息。
重试次数
第几次重试 与上次重试的间隔时间 第几次重试 与上次重试的间隔时间 1 10 秒 9 7 分钟 2 30 秒 10 8 分钟 3 1 分钟 11 9 分钟 4 2 分钟 12 10 分钟 5 3 分钟 13 20 分钟 6 4 分钟 14 30 分钟 7 5 分钟 15 1 小时 8 6 分钟 16 2 小时 如果消息重试16次后仍然失败,消息将不再投递。如果严格按照上述重试时间间隔计算,某条消息在一直消费失败的前提下,将会在接下来的4小时46分钟之内进行16次重试,超过这个时间范围消息将不再重试投递。
注意:一条消息无论重试多少次,这些重试消息的Message ID不会改变。
重试配置
集群消费方式下,消息消费失败后期望消息重试,需要在消息监听器接口的实现中明确进行配置(三种方式任选一种):
- 返回RECONSUME_LATER(推荐)
- 返回null
- 抛出异常
集群消费方式下,消息失败后期望消息不重试,需要捕获消费逻辑中可能抛出的异常,最终返回CONSUME_SUCCESS,此后这条消息将不会再重试。
自定义消息最大重试次数
RocketMQ允许Consumer启动的时候设置最大重试次数,重试时间间隔将按照如下策略:
- 最大重试次数小于等于16次,则重试时间间隔同上表描述。
- 最大重试次数大于16次,超过16次的重试时间间隔均为每次2小时。
通过属性maxReconsumeTimes设置消息的最大重试次数:
consumer.setMaxReconsumeTimes(16); // 最大重试次数- 1
消息最大重试次数的设置对相同Group ID下的所有Consumer实例有效。
如果只对相同Group ID下两个Consumer实例中的其中一个设置了MaxReconsumeTimes,那么该配置对两个Consumer实例均生效。
配置采用覆盖的方式生效,即最后启动的Consumer实例会覆盖之前的启动实例的配置。
死信队列
当一条消息初次消费失败,RocketMQ会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,RocketMQ不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。在RocketMQ中,这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。
死信特性
死信消息具有以下特性:
- 不会再被消费者正常消费。
- 有效期与正常消息相同,均为3天,3天后会被自动删除。
因此,请在死信消息产生后的3天内及时处理。
死信队列具有以下特性:
- 不会再被消费者正常消费。
- 一个死信队列对应一个Group ID, 而不是对应单个消费者实例。
- 如果一个 Group ID未产生死信消息,RocketMQ不会为其创建相应的死信队列。
- 一个死信队列包含了对应Group ID产生的所有死信消息,不论该消息属于哪个Topic。
查看死信消息
在控制台查询出现死信队列的主题信息:
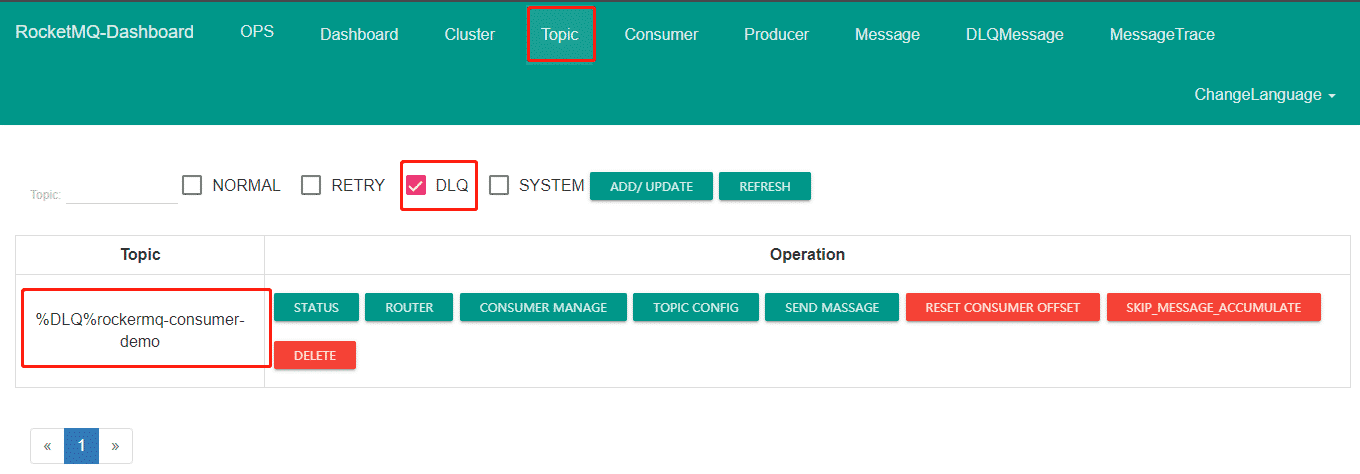
死信队列和重试队列都只有在有对应的消息时才会自动创建。
在消息界面根据主题查询死信消息:
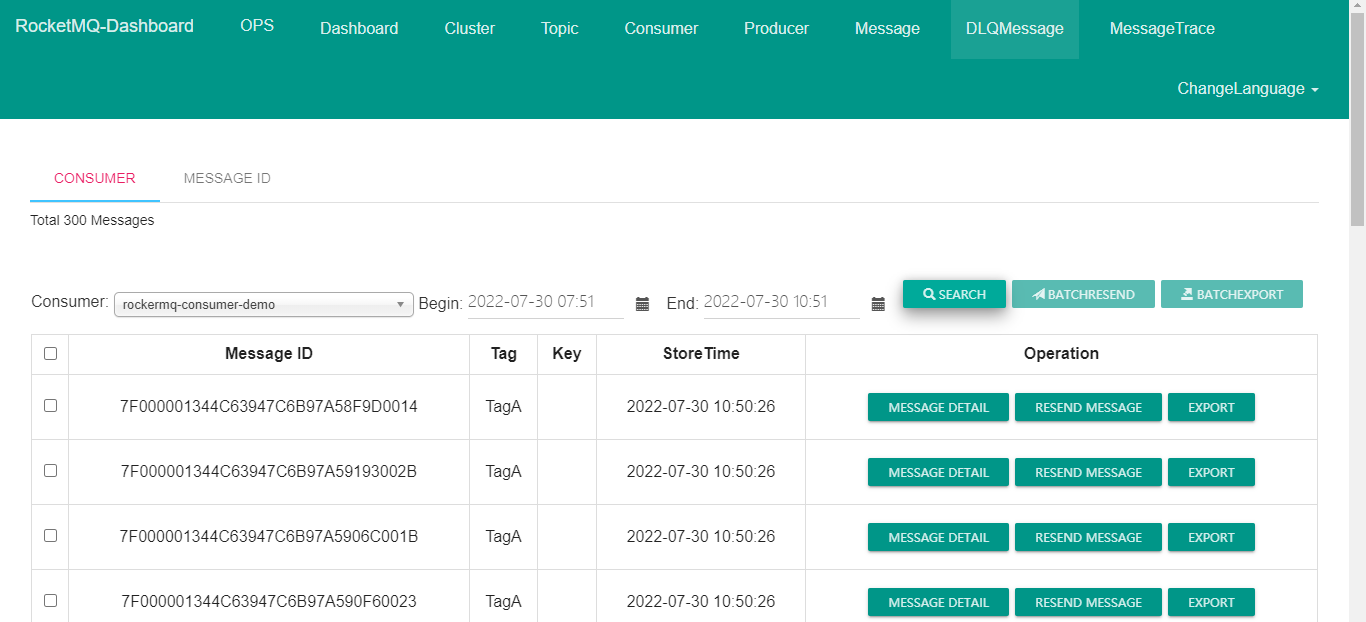
可以选择重新发送消息。
一条消息进入死信队列,意味着某些因素导致消费者无法正常消费该消息,因此,通常需要您对其进行特殊处理。排查可疑因素并解决问题后,可以在RocketMQ控制台重新发送该消息,让消费者重新消费一次。
负载均衡
Producer负载均衡
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下,如下图:
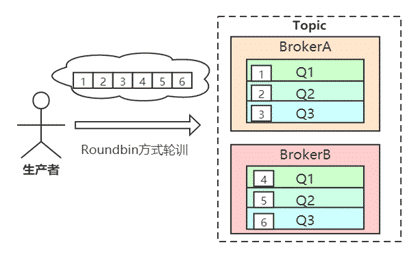
发布方会把第一条消息发送至Queue 0,然后第二条消息发送至Queue 1,以此类推。
Consumer负载均衡
集群模式
在集群消费模式下,每条消息只需要投递到订阅这个topic的Consumer Group下的一个实例即可。RocketMQ采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。
而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均分配queue给每个实例。
默认的分配算法是AllocateMessageQueueAveragely,还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊每一条queue,只是以环状轮流分queue的形式
如下图:
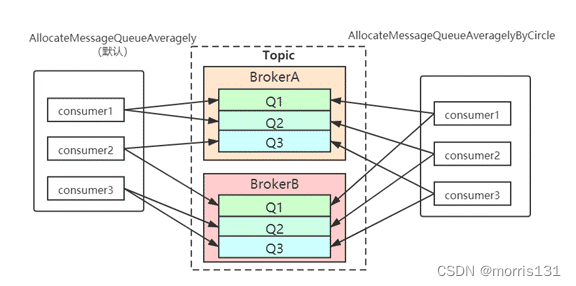
需要注意的是,集群模式下,queue都是只允许分配只一个实例,这是由于如果多个实例同时消费一个queue的消息,由于拉取哪些消息是consumer主动控制的,那样会导致同一个消息在不同的实例下被消费多次,所以算法上都是一个queue只分给一个consumer实例,一个consumer实例可以允许同时分到不同的queue。
通过增加consumer实例去分摊queue的消费,可以起到水平扩展的消费能力的作用。而有实例下线的时候,会重新触发负载均衡,这时候原来分配到的queue将分配到其他实例上继续消费。
但是如果consumer实例的数量比message queue的总数量还多的话,多出来的consumer实例将无法分到queue,也就无法消费到消息,也就无法起到分摊负载的作用了。所以需要控制让queue的总数量大于等于consumer的数量。
广播模式
由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。
在实现上,其中一个不同就是在consumer分配queue的时候,所有consumer都分到所有的queue。
-
相关阅读:
操作系统【OS】进程的控制结构PCB
HTTPS
笔试强训2
分享让PPT变高级的两个小技巧
(二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
Dockerfile关键词
数据结构-快速排序-C语言实现
【常用的 SVN 命令及简要示例】
一个完整的初学者指南Django-part2
基于EQ36软件的地球化学反应过程模拟实践
- 原文地址:https://blog.csdn.net/u022812849/article/details/126069670